
مقدمة عن Llama 3.1 Instruct 405B
Llama 3.1 من ميتا Instruct 405B يمثل قفزة كبيرة إلى الأمام في مجال نماذج اللغة الكبيرة (LLMs). كما يوحي الاسم، تتميز هذه العملاقة بوجود 405 مليار معلمة، مما يجعلها واحدة من أكبر نماذج الذكاء الاصطناعي المتاحة للجمهور حتى الآن. هذه السعة الضخمة تترجم إلى قدرات معززة عبر مجموعة واسعة من المهام، من فهم وتوليد اللغة الطبيعية إلى التفكير المعقد وحل المشاكل.
أحد أبرز ميزات Llama 3.1 405B هو نافذة السياق الموسعة بمقدار 128,000 توكن. هذا الزيادة الكبيرة عن النسخ السابقة تسمح للنموذج بمعالجة وتوليد نصوص أطول بكثير، مما يفتح آفاق جديدة لتطبيقات مثل إنشاء محتوى طويل، تحليل الوثائق بعمق، وتفاعلات محادثة ممتدة.
يتميز النموذج في مجالات مثل:
- تلخيص النصوص والدقة
- التفكير والتحليل المتناغم
- القدرات متعددة اللغات (تدعم 8 لغات)
- توليد وفهم الشفرات البرمجية
- إمكانات التخصيص الدقيقة حسب المهام
مع طبيعته مفتوحة المصدر، يستعد Llama 3.1 405B لت democratize الوصول إلى تقنيات الذكاء الاصطناعي المتطورة، مما يمكن الباحثين والمطورين والشركات من Harness قوتها لتطبيقات متنوعة.
مقارنة مقدمي واجهة برمجة التطبيقات Llama 3.1
تقدم العديد من مقدمي الخدمات السحابية الوصول إلى نماذج Llama 3.1 من خلال واجهات برمجة التطبيقات الخاصة بهم. دعنا نقارن بعض من الخيارات البارزة:
| المزود | التسعير (لكل مليون توكن) | سرعة الإخراج | الكمون | الميزات الرئيسية |
|---|---|---|---|---|
| Together.ai | $7.50 (معدل مختلط) | 70 توكن/ثانية | متوسط | سرعة إخراج مثيرة للإعجاب |
| Fireworks | $3.00 (معدل مختلط) | جيد | 0.57 ثانية (منخفضة جداً) | أكثر الأسعار تنافسية |
| Microsoft Azure | يختلف حسب مستوى الاستخدام | متوسط | 0.00 ثانية (قريبة من الفورية) | أقل كمون |
| Replicate | $9.50 (توكينات الإخراج) | 29 توكن/ثانية | أعلى من بعض المنافسين | نموذج تسعير بسيط |
| Anakin AI | $9.90/شهر (نموذج مجاني) | غير محدد | غير محدد | بناء تطبيقات ذكاء اصطناعي بدون كود |
- Together.ai: توفر سرعة إخراج مثيرة للإعجاب تبلغ 70 توكن/ثانية، مما يجعلها مثالية للتطبيقات التي تتطلب استجابات سريعة. تسعيرها تنافسي عند 7.50 دولار لكل مليون توكن، مما يحقق توازنًا بين الأداء والتكلفة.
- Fireworks: تبرز بأكثر الأسعار تنافسية عند 3.00 دولارات لكل مليون توكن وكمون منخفض جداً (0.57 ثانية). مما يجعلها اختيارًا ممتازًا للمشاريع الحساسة من حيث التكلفة التي تتطلب أيضًا أوقات استجابة سريعة.
- Microsoft Azure: تتفاخر بأقل كمون (قريب من الفورية) بين المزودين، وهو أمر حاسم للتطبيقات التي تعمل في الوقت الحقيقي. ومع ذلك، فإن هيكل تسعيرها يختلف حسب مستويات الاستخدام، مما قد يجعل من الصعب تقدير التكاليف.
- Replicate: تقدم نموذج تسعير بسيط بمقدار 9.50 دولار لكل مليون توكنات إخراج. بينما سرعة الإخراج لديها (29 توكن/ثانية) أقل من Together.ai، إلا أنها لا تزال توفر أداءً جيدًا للعديد من حالات الاستخدام.
- Anakin AI: يختلف نهج Anakin AI بشكل كبير عن الآخرين، حيث يركز على الوصول والتخصيص بدلاً من مقاييس الأداء الخام. تدعم نماذج ذكاء اصطناعي متعددة، بما في ذلك GPT-3.5 و GPT-4 و Claude 2 و 3، مما يوفر مرونة عبر مهام الذكاء الاصطناعي المختلفة. تبدأ بنموذج مجاني مع خطط تبدأ من 9.90 دولارًا شهريًا.
كيفية إجراء استدعاءات واجهة برمجة التطبيقات لنماذج Llama 3.1 باستخدام Apidog
لاستغلال قوة Llama 3.1، ستحتاج إلى إجراء استدعاءات واجهة برمجة التطبيقات لمزودك المختار. بينما قد يختلف الإجراء الدقيق قليلاً بين المزودين، تظل المبادئ العامة كما هي.
إليك دليل خطوة بخطوة حول كيفية إجراء استدعاءات واجهة برمجة التطبيقات باستخدام Apidog:
- افتح Apidog: قم بتشغيل Apidog وأنشئ طلبًا جديدًا.
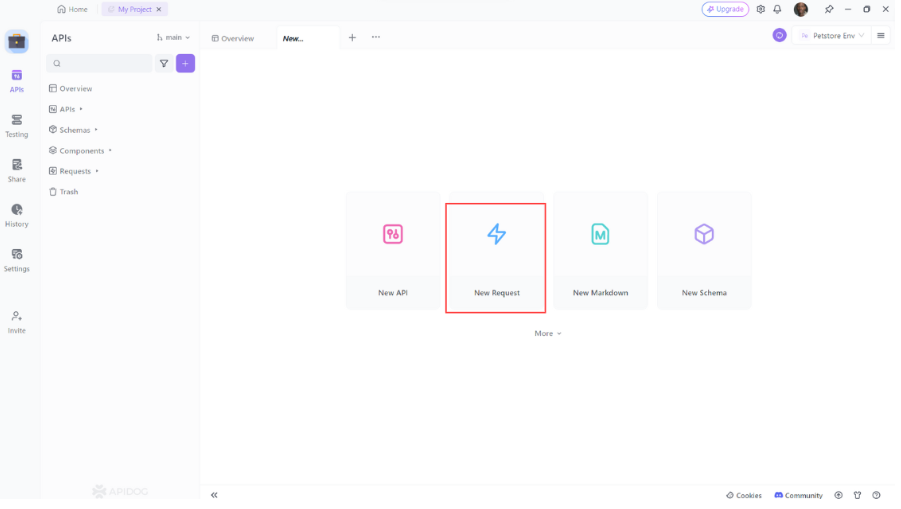
2. اختر طريقة HTTP: اختر "GET" كطريقة الطلب أو "Post"
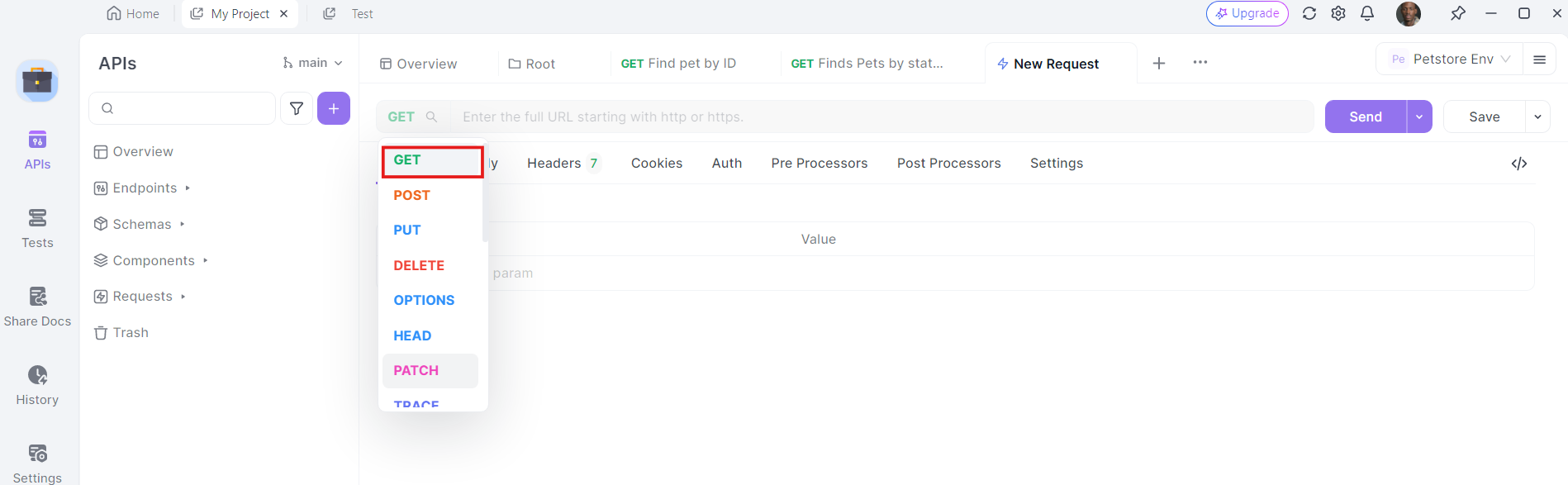
3. أدخل عنوان URL: في حقل عنوان URL، أدخل نقطة النهاية التي تريد إرسال طلب GET إليها.
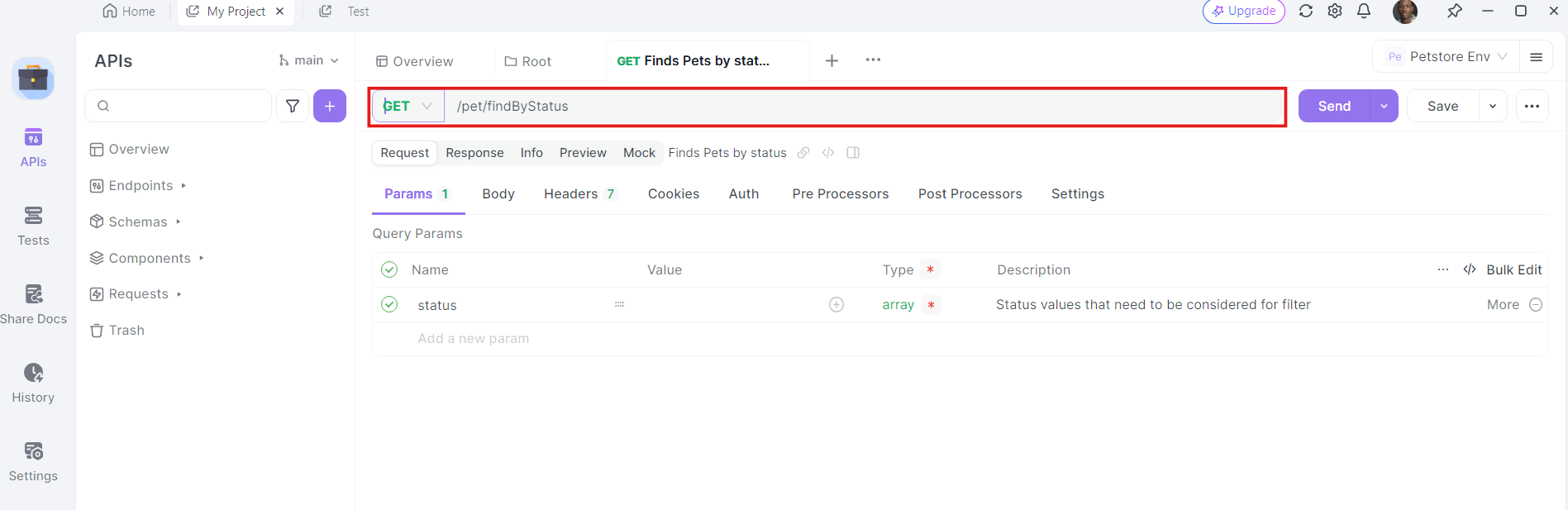
4. أضف رؤوس: الآن، حان الوقت لإضافة الرؤوس اللازمة. انقر على علامة "الرؤوس" في apidog. هنا، يمكنك تحديد أي رؤوس يتطلبها واجهة برمجة التطبيقات. تشمل الرؤوس الشائعة لطلبات GET Authorization و Accept و User-Agent.
على سبيل المثال:
- Authorization:
Bearer YOUR_ACCESS_TOKEN - Accept:
application/json
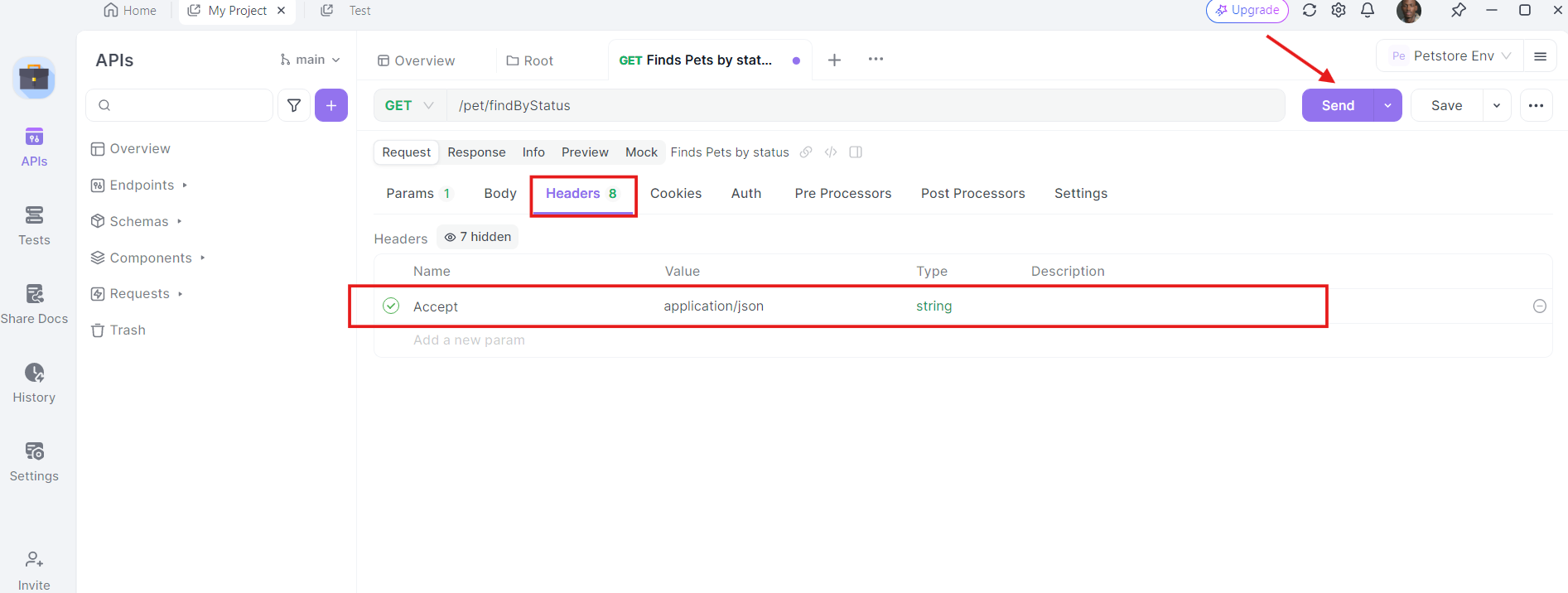
5. أرسل الطلب وافحص الاستجابة: مع وجود عنوان URL ومعلمات الاستعلام والرؤوس في مكانها، يمكنك الآن إرسال طلب واجهة برمجة التطبيقات. انقر على زر "إرسال" وسينفذ apidog الطلب. سترى الاستجابة معروضة في قسم الاستجابة.
بمجرد إرسال الطلب، سيعرض Apidog الاستجابة من الخادم. يمكنك عرض رمز الحالة والرؤوس وجسم الاستجابة. هذا لا يقدر بثمن في تصحيح الأخطاء والتحقق من أن استدعاءات واجهة برمجة التطبيقات تعمل كما هو متوقع.
أفضل الممارسات لاستخدام واجهة برمجة التطبيقات Llama 3.1
عند العمل مع واجهة برمجة التطبيقات Llama 3.1، تذكر هذه الممارسات الجيدة:
- تنفيذ البث المباشر: للحصول على استجابات أطول، قد ترغب في تنفيذ البث للحصول على النص المولد في أجزاء في الوقت الحقيقي. يمكن أن يحسن ذلك تجربة المستخدم للتطبيقات التي تتطلب تغذية راجعة فورية.
- احترام حدود السعر: كن على دراية واحترم الحدود السعري المحددة من قبل مزود واجهة برمجة التطبيقات الخاص بك لتجنب انقطاع الخدمة.
- تنفيذ التخزين المؤقت: بالنسبة للمطالبات أو الاستعلامات المستخدمة بشكل متكرر، نفذ نظام تخزين مؤقت لتقليل استدعاءات واجهة برمجة التطبيقات وتحسين أوقات الاستجابة.
- مراقبة الاستخدام: تابع استخدام واجهة برمجة التطبيقات الخاصة بك لإدارة التكاليف وضمان دخولك ضمن الحصة المخصصة لك.
- الأمان: لا تكشف أبدًا عن مفتاح واجهة برمجة التطبيقات الخاصة بك في التعليمات البرمجية الخاصة بالعميل. اجعل دائمًا استدعاءات واجهة برمجة التطبيقات من بيئة خادم آمنة.
- تصفية المحتوى: نفذ تصفية المحتوى على كل من المطالبات المدخلة والناتجة المولدة لضمان الاستخدام المناسب للنموذج.
- التخصيص الدقيق: ضع في اعتبارك تخصيص النموذج وفقًا للبيانات الخاصة بالنطاق إذا كنت تعمل على تطبيقات متخصصة.
- التحكم في الإصدارات: اتابع إصدار نموذج Llama 3.1 المحدد الذي تستخدمه، حيث قد تؤثر التحديثات على سلوك النموذج ومخرجاته.
حالات الاستخدام في العالم الحقيقي
دعنا نلقي نظرة على بعض حالات الاستخدام في العالم الحقيقي حيث يمكن أن يكون دمج Llama 3.1 مع واجهة برمجة التطبيقات نقطة تحول:
1. تحليل المشاعر
إذا كنت تدير مشروعًا لتحليل المشاعر، يمكن أن تساعدك Llama 3.1 في تصنيف النصوص على أنها إيجابية أو سلبية أو محايدة. من خلال دمجها مع واجهة برمجة التطبيقات، يمكنك أتمتة تحليل كميات كبيرة من البيانات، مثل مراجعات العملاء أو المنشورات على وسائل التواصل الاجتماعي.
2. الدردشات الآلية
هل تقوم ببناء دردشة آلية؟ يمكن أن تعزز قدرات معالجة اللغة الطبيعية في Llama 3.1 فهم دردشتك الآلية واستجابتها. من خلال استخدام واجهة برمجة التطبيقات، يمكنك دمجها بسلاسة مع إطار الدردشة الآلية الخاص بك وتوفير تفاعلات في الوقت الحقيقي.
3. التعرف على الصور
في مشاريع رؤية الكمبيوتر، يمكن أن يقوم Llama 3.1 بأداء مهام التعرف على الصور. من خلال الاستفادة من واجهة برمجة التطبيقات، يمكنك تحميل الصور، والحصول على تصنيفات في الوقت الحقيقي، ودمج النتائج في تطبيقك.
حل مشكلات شائعة
في بعض الأحيان لا تسير الأمور كما هو مخطط لها. إليك بعض المشكلات الشائعة التي قد تواجهها وكيفية حلها:
1. أخطاء المصادقة
إذا كنت تتلقى أخطاء مصادقة، تحقق من مفتاح واجهة برمجة التطبيقات الخاصة بك وتأكد من أنه مكون بشكل صحيح في Apidog.
2. مشكلات الشبكة
يمكن أن تؤدي مشكلات الشبكة إلى فشل استدعاءات واجهة برمجة التطبيقات. تأكد من أن اتصال الإنترنت لديك مستقر وحاول مرة أخرى. إذا استمرت المشكلة، تحقق من صفحة حالة مزود واجهة برمجة التطبيقات للتأكد من عدم وجود انقطاعات.
3. تحديد الحد الأقصى للسرعة
عادةً ما يفرض مزودو واجهة برمجة التطبيقات حدودًا على الطلبات لتجنب إساءة الاستخدام. إذا تجاوزت الحد، ستحتاج إلى الانتظار قبل إجراء المزيد من الطلبات. ضع في اعتبارك تنفيذ منطق التحقق مع زيادة متدرجة للتعامل مع تحديد السرعة بشكل سلس.
تصميم المطالبات باستخدام Llama 3.1 405B
للحصول على أفضل النتائج من Llama 3.1 405B، ستحتاج إلى تجربة مجموعة متنوعة من المطالبات والمعلمات. ضع في اعتبارك عوامل مثل:
- تصميم المطالبات: اكتب مطالبات واضحة ومحددة لتوجيه مخرجات النموذج.
- درجة الحرارة: اضبط هذه المعلمة للتحكم في عشوائية الإخراج.
- الحد الأقصى للتوكنات: ضع حدًا مناسبًا لطول النص المولد.
خاتمة
تمثل Llama 3.1 405B تقدمًا كبيرًا في مجال نماذج اللغة الكبيرة، حيث تقدم قدرات غير مسبوقة في حزمة مفتوحة المصدر. من خلال الاستفادة من قوة هذا النموذج عبر واجهات برمجة التطبيقات المقدمة من مزودي الخدمات السحابية المختلفين، يمكن للمطورين والشركات فتح إمكانيات جديدة في التطبيقات المدفوعة بالذكاء الاصطناعي.
مستقبل الذكاء الاصطناعي مفتوح، ومع أدوات مثل Llama 3.1 تحت تصرفنا، فإن الإمكانيات محدودة فقط بخيالنا وذكائنا. بينما تستكشف وتختبر هذا النموذج القوي، فإنك لا تستخدم أداة فحسب – بل تشارك في الثورة المستمرة للذكاء الاصطناعي، مما يساعد على تشكيل المستقبل لكيفية تفاعلنا والاستفادة من الذكاء الآلي.