
لقد أحدث إصدار Kimi K2.5 من Moonshot AI معيارًا جديدًا للنماذج مفتوحة المصدر. بمليار معلمة وبنية مزيج الخبراء (MoE)، فإنه ينافس عمالقة النماذج الخاصة مثل GPT-4o. ومع ذلك، فإن حجمه الهائل يجعله صعب التشغيل.
بالنسبة للمطورين والباحثين، يوفر تشغيل K2.5 محليًا خصوصية لا تضاهى، وصفر زمن انتقال (شبكي)، وتوفير في تكاليف رموز API. ولكن على عكس النماذج الأصغر بحجم 7B أو 70B، لا يمكنك تحميل هذا النموذج على جهاز كمبيوتر محمول قياسي للألعاب.
يستكشف هذا الدليل كيفية الاستفادة من تقنيات التكميم الرائدة لـ Unsloth لتناسب هذا النموذج الضخم على أجهزة (نوعًا ما) يمكن الوصول إليها باستخدام llama.cpp، وكيفية دمجها في سير عمل التطوير الخاص بك باستخدام Apidog.
لماذا يصعب تشغيل Kimi K2.5 (تحدي MoE)
Kimi K2.5 ليس مجرد "ضخم"؛ إنه معقد من الناحية المعمارية. يستخدم بنية مزج الخبراء (MoE) مع عدد أكبر بكثير من الخبراء مقارنة بالنماذج المفتوحة النموذجية مثل Mixtral 8x7B.
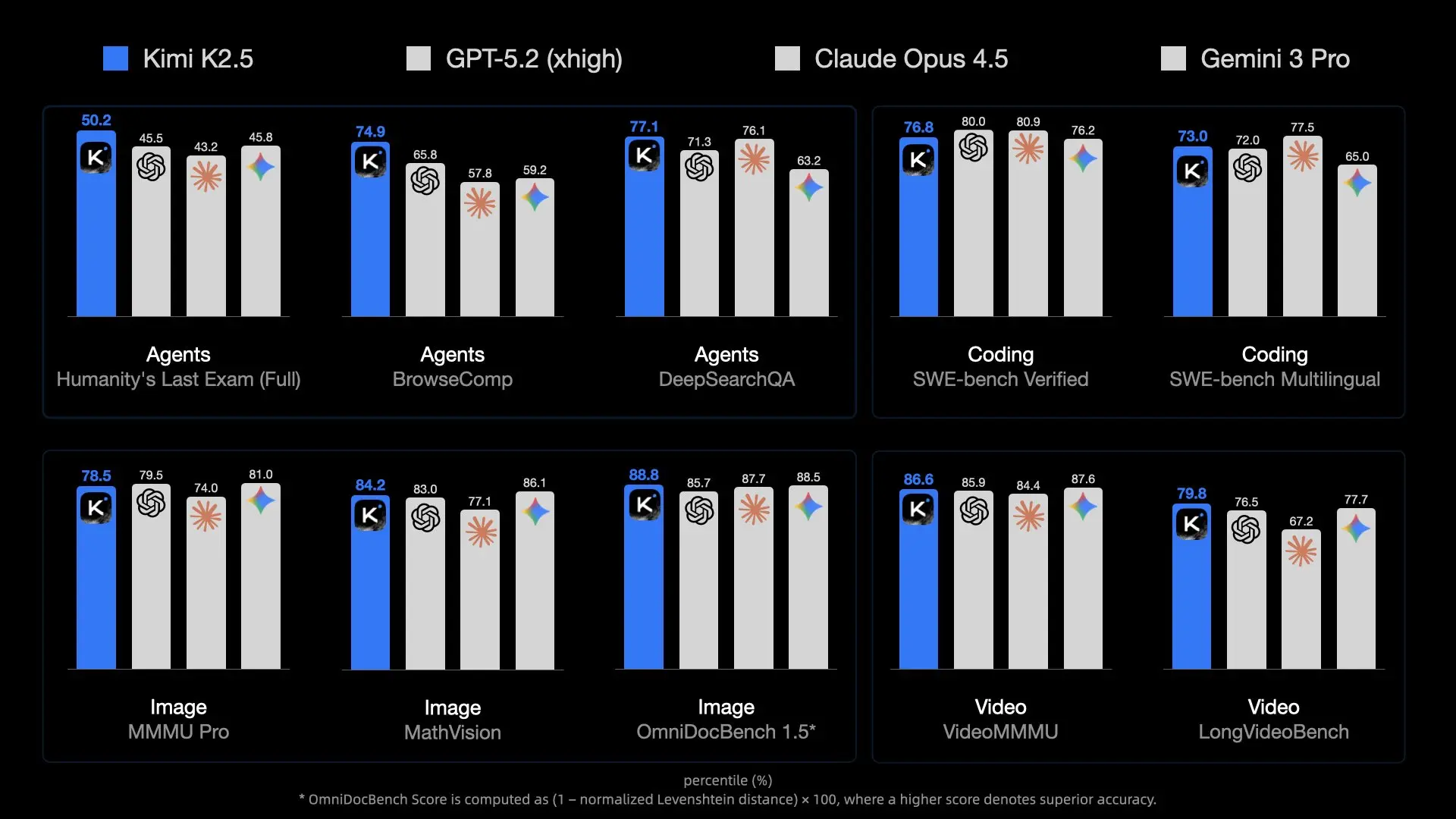
مشكلة الحجم
- إجمالي المعلمات: ~1 تريليون. بدقة FP16 القياسية، سيتطلب هذا ~2 تيرابايت من VRAM.
- المعلمات النشطة: بينما يستخدم الاستدلال فقط مجموعة فرعية من المعلمات لكل رمز (بفضل MoE)، لا يزال يتعين عليك الاحتفاظ بالنموذج بأكمله في الذاكرة لتوجيه الرموز بشكل صحيح.
- عرض النطاق الترددي للذاكرة: ليس العنق الحقيقي هو السعة فقط؛ بل هو السرعة. نقل 240 جيجابايت من البيانات عبر قنوات الذاكرة لكل إنشاء رمز واحد يمثل ضغطًا هائلاً على أجهزة المستهلكين.
هذا هو السبب في أن التكميم (تقليل عدد البتات لكل وزن) أمر غير قابل للتفاوض. بدون ضغط Unsloth الشديد بمقدار 1.58 بت، سيكون تشغيل هذا مقتصرًا تمامًا على مجموعات الحوسبة الفائقة.
متطلبات الأجهزة: هل يمكنك تشغيله؟
تكميم "1.58 بت" هو السحر الذي يجعل هذا ممكنًا، حيث يضغط حجم النموذج بنسبة ~60% دون تدمير الذكاء.
الحد الأدنى من المواصفات (تكميم 1.58 بت)
- مساحة القرص: >240 جيجابايت (يوصى بشدة بـ NVMe SSD)
- RAM + VRAM: >240 جيجابايت مجتمعة
- المثال 1: 2x RTX 3090 (48 جيجابايت VRAM) + 256 جيجابايت RAM للنظام (ممكن، بطيء)
- المثال 2: Mac Studio M2 Ultra مع 192 جيجابايت RAM (غير كافٍ، من المرجح أن يتعطل أو يتبادل بشكل كبير)
- المثال 3: خادم بذاكرة وصول عشوائي (RAM) سعة 512 جيجابايت (يعمل بشكل جيد على وحدة المعالجة المركزية)
- الحوسبة: وحدة معالجة مركزية تدعم AVX2 أو وحدات معالجة رسوميات NVIDIA
المواصفات الموصى بها (الأداء)
للحصول على سرعات قابلة للاستخدام (>10 رموز/ثانية):
- VRAM: قدر الإمكان. نقل الطبقات إلى وحدة معالجة الرسوميات يعزز السرعة بشكل كبير.
- النظام: 4x وحدات معالجة رسوميات H100/H200 (للمؤسسات) أو محطة عمل بذاكرة وصول عشوائي DDR5 سعة 512 جيجابايت (للمستهلك/الاحترافي).
ملاحظة
الحل: Unsloth Dynamic GGUF
أصدرت Unsloth إصدارات GGUF ديناميكية من Kimi K2.5. تتيح لك هذه الملفات تحميل النموذج إلى llama.cpp، والذي يمكنه تقسيم عبء العمل بذكاء بين وحدة المعالجة المركزية (RAM) ووحدة معالجة الرسوميات (VRAM).
ما هو التكميم الديناميكي؟
يطبق التكميم القياسي نفس الضغط على كل طبقة. نهج "الديناميكي" من Unsloth أكثر ذكاءً:
- الطبقات الحرجة (الانتباه/التوجيه): يتم الاحتفاظ بها بدقة أعلى (مثل 4 بت أو 6 بت) للحفاظ على الذكاء.
- الطبقات الأمامية (Feed-Forward): يتم ضغطها بقوة إلى 1.58 بت أو 2 بت لتوفير المساحة.
يسمح هذا النهج الهجين لنموذج 1T بالعمل بحجم ~240 جيجابايت مع الاحتفاظ بقدرات التفكير التي تتفوق على نماذج 70B الأصغر التي تعمل بدقة كاملة.
- 1.58 بت (UD-TQ1_0): ~240 جيجابايت. أصغر إصدار قابل للتطبيق.
- 2 بت (UD-Q2_K_XL): ~375 جيجابايت. تفكير أفضل، يتطلب ذاكرة وصول عشوائي (RAM) أكبر بكثير.
- 4 بت (UD-Q4_K_XL): ~630 جيجابايت. أداء قريب من الدقة الكاملة، مخصص لأجهزة الشركات فقط.
دليل التثبيت خطوة بخطوة
سنستخدم llama.cpp لأنه يوفر محرك الاستدلال الأكثر كفاءة لأعباء عمل وحدة المعالجة المركزية/وحدة معالجة الرسوميات المقسمة.
الخطوة 1: تثبيت llama.cpp
تحتاج إلى بناء llama.cpp من المصدر لضمان حصولك على أحدث دعم لـ Kimi K2.5.
Mac/Linux:
# تثبيت التبعيات
sudo apt-get update && sudo apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
# استنساخ المستودع
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
# بناء مع دعم CUDA (إذا كان لديك وحدات معالجة رسوميات NVIDIA)
cmake -B build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON
# أو بناء لوحدة المعالجة المركزية/Mac Metal (افتراضي)
# cmake -B build
# تجميع
cmake --build build --config Release -j --clean-first --target llama-cli llama-server
الخطوة 2: تنزيل النموذج
سنقوم بتنزيل إصدار Unsloth GGUF. يوصى بإصدار 1.58 بت لمعظم إعدادات "المختبر المنزلي".
يمكنك استخدام huggingface-cli أو llama-cli مباشرة.
الخيار أ: تنزيل مباشر باستخدام llama-cli
# إنشاء دليل للنموذج
mkdir -p models/kimi-k2.5
# تنزيل وتشغيل (سيقوم هذا بتخزين النموذج مؤقتًا)
./build/bin/llama-cli \
-hf unsloth/Kimi-K2.5-GGUF:UD-TQ1_0 \
--model-url unsloth/Kimi-K2.5-GGUF \
--print-token-count 0
الخيار ب: تنزيل يدوي (أفضل للإدارة)
pip install huggingface_hub
# تنزيل تكميم محدد
huggingface-cli download unsloth/Kimi-K2.5-GGUF \
--include "*UD-TQ1_0*" \
--local-dir models/kimi-k2.5
الخطوة 3: تشغيل الاستدلال
الآن، لنقم بتشغيل النموذج. نحتاج إلى تعيين معلمات عينة محددة أوصت بها Moonshot AI للحصول على الأداء الأمثل (temp 1.0، min-p 0.01).
./build/bin/llama-cli \
-m models/kimi-k2.5/Kimi-K2.5-UD-TQ1_0-00001-of-00005.gguf \
--temp 1.0 \
--min-p 0.01 \
--top-p 0.95 \
--ctx-size 16384 \
--threads 16 \
--prompt "User: Write a Python script to scrape a website.\nAssistant:"
المعلمات الرئيسية:
--fit on: يقوم تلقائيًا بتحميل الطبقات إلى وحدة معالجة الرسوميات لتناسب VRAM المتاحة (حاسم للإعدادات الهجينة).--ctx-size: يدعم K2.5 ما يصل إلى 256k، ولكن 16k أكثر أمانًا للحفاظ على الذاكرة.
التشغيل كخادم API محلي
لدمج Kimi K2.5 مع تطبيقاتك أو Apidog، قم بتشغيله كخادم متوافق مع OpenAI.
./build/bin/llama-server \
-m models/kimi-k2.5/Kimi-K2.5-UD-TQ1_0-00001-of-00005.gguf \
--port 8001 \
--alias "kimi-k2.5-local" \
--temp 1.0 \
--min-p 0.01 \
--ctx-size 16384 \
--host 0.0.0.0
واجهة برمجة التطبيقات المحلية الخاصة بك نشطة الآن على http://127.0.0.1:8001/v1.
ربط Apidog بـ Kimi K2.5 المحلي الخاص بك
يعد Apidog الأداة المثالية لاختبار LLM المحلي الخاص بك. يتيح لك إنشاء الطلبات بصريًا، وإدارة سجل المحادثات، وتصحيح أخطاء استخدام الرموز دون كتابة برامج curl النصية.
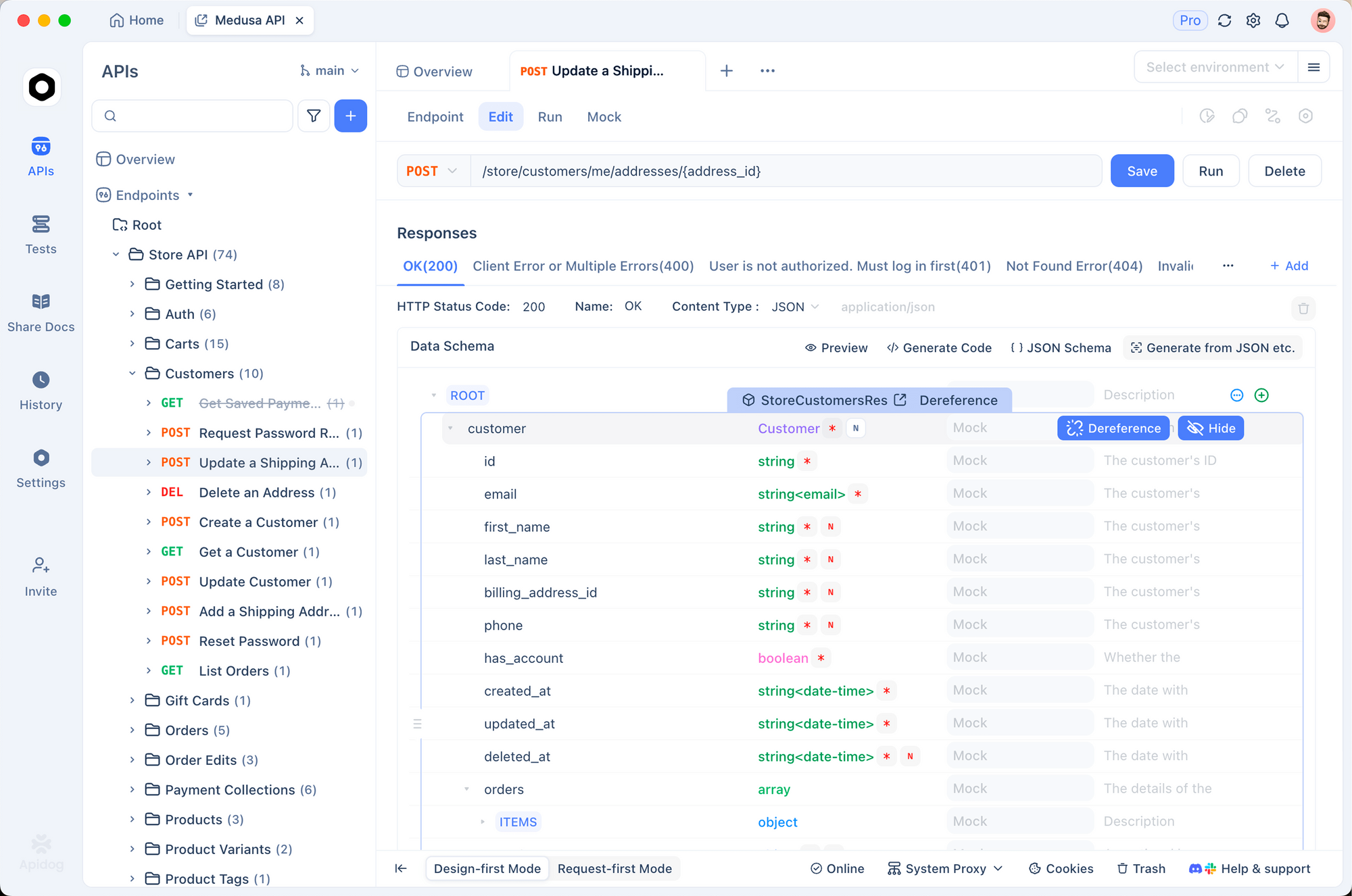
1. إنشاء طلب جديد
افتح Apidog وأنشئ مشروع HTTP جديدًا. أنشئ طلب POST إلى:http://127.0.0.1:8001/v1/chat/completions
2. تكوين الرؤوس
أضف الرؤوس التالية:
Content-Type:application/jsonAuthorization:Bearer not-needed(عادةً ما تتجاهل الخوادم المحلية المفتاح، لكنها ممارسة جيدة)
3. تعيين الجسم
استخدم التنسيق المتوافق مع OpenAI:
{
"model": "kimi-k2.5-local",
"messages": [
{
"role": "system",
"content": "أنت كيمي، تعمل محليًا."
},
{
"role": "user",
"content": "اشرح الحوسبة الكمومية في جملة واحدة."
}
],
"temperature": 1.0,
"max_tokens": 1024
}
4. إرسال والتحقق
انقر فوق إرسال. يجب أن ترى استجابة التدفق.
لماذا تستخدم Apidog؟
- تتبع زمن الانتقال: شاهد بالضبط المدة التي يستغرقها النموذج المحلي للاستجابة (الوقت حتى أول رمز).
- إدارة السجل: يحتفظ Apidog بجلسات الدردشة الخاصة بك، حتى تتمكن من اختبار قدرات المحادثة متعددة الأدوار للنموذج المحلي بسهولة.
- توليد الكود: بمجرد أن يعمل طلبك، انقر فوق "توليد كود" في Apidog للحصول على مقتطف Python/JS لاستخدام هذا الخادم المحلي في تطبيقك.
استكشاف الأخطاء وإصلاحها وضبط الأداء بالتفصيل
تشغيل نموذج 1T يدفع أجهزة المستهلكين إلى نقطة الانهيار. فيما يلي نصائح متقدمة للحفاظ على استقراره.
"فشل تحميل النموذج: نفاد الذاكرة"
هذا هو الخطأ الأكثر شيوعًا.
- تقليل السياق: خفض
--ctx-sizeإلى 4096 أو 8192. - إغلاق التطبيقات: أغلق Chrome وVS Code وDocker. تحتاج إلى كل بايت من ذاكرة الوصول العشوائي.
- استخدام تحميل القرص (الملاذ الأخير): يمكن لـ
llama.cppتعيين أجزاء النموذج على القرص، لكن الاستدلال سينخفض إلى <1 رمز/ثانية.
"إخراج غير مرغوب فيه" أو نص متكرر
Kimi K2.5 حساس لأخذ العينات. تأكد من أنك تستخدم:
درجة الحرارة (Temperature): 1.0 (مرتفع بشكل مدهش، ولكنه موصى به لهذا النموذج)الحد الأدنى لـ P (Min-P): 0.01 (يساعد على قطع الرموز ذات الاحتمالية المنخفضة)أعلى P (Top-P): 0.95
سرعة توليد بطيئة
إذا كنت تحصل على 0.5 رمز/ثانية، فمن المحتمل أن تكون مقيدًا بعرض النطاق الترددي لذاكرة RAM النظام أو سرعة وحدة المعالجة المركزية.
- التحسين: تأكد من أن
--threadsيتطابق مع نوى وحدة المعالجة المركزية الفعلية (وليس مؤشرات الترابط المنطقية). - تحميل GPU: حتى تحميل 10 طبقات إلى وحدة معالجة رسوميات صغيرة يمكن أن يحسن وقت معالجة الطلب بشكل كبير.
- دعم NUMA: إذا كنت تستخدم خادمًا مزدوج المقابس، فقم بتمكين الوعي بـ NUMA في علامات بناء
llama.cppلتحسين الوصول إلى الذاكرة.
التعامل مع الأعطال
إذا تم تحميل النموذج ولكنه تعطل أثناء التوليد:
- التحقق من ملف التبادل (Swap): تأكد من تمكين ملف تبادل ضخم (100 جيجابايت+). حتى لو كان لديك 256 جيجابايت من ذاكرة الوصول العشوائي، يمكن أن تؤدي الارتفاعات العابرة إلى قتل العملية.
- تعطيل تحميل ذاكرة التخزين المؤقت KV: احتفظ بذاكرة التخزين المؤقت KV على وحدة المعالجة المركزية إذا كانت VRAM ضيقة (
--no-kv-offload).
هل أنت مستعد للبناء؟
سواء تمكنت من تشغيل Kimi K2.5 محليًا أو قررت الالتزام بواجهة برمجة التطبيقات، يوفر Apidog النظام الأساسي الموحد لاختبار ووثيقة ومراقبة عمليات دمج الذكاء الاصطناعي الخاصة بك. قم بتنزيل Apidog مجانًا وابدأ التجربة اليوم.