
يبحث المطورون وعشاق الذكاء الاصطناعي باستمرار عن نماذج فعالة تعمل بشكل جيد دون الحاجة إلى موارد ضخمة. تقدم جوجل Gemma 3 270M، وهو نموذج لغوي مدمج يضم 270 مليون معلمة. يتميز هذا النموذج بكونه الأصغر في عائلة Gemma 3، وقد تم تحسينه للمهام على الجهاز. يمكنك الحصول على قدرات في توليد النصوص، والإجابة على الأسئلة، وتلخيص النصوص، والاستدلال، كل ذلك مع الحفاظ على العمليات محلية.
يدعم Gemma 3 270M طول سياق يبلغ 32,000 رمز، مما يسمح له بالتعامل مع المدخلات الكبيرة بفعالية. بالإضافة إلى ذلك، فإنه يدمج تقنيات التكميم مثل Q4_0 Quantization Aware Training (QAT)، مما يقلل من احتياجات الموارد دون التضحية بالجودة. ونتيجة لذلك، يمكنك تحقيق أداء قريب من نماذج الدقة الكاملة ولكن بمتطلبات ذاكرة وحوسبة أقل.
ومع ذلك، فإن ما يجعل Gemma 3 270M جذابًا بشكل خاص يكمن في سهولة الوصول إليه. يمكنك تشغيله على أجهزة قياسية، بما في ذلك أجهزة الكمبيوتر المحمولة أو حتى الأجهزة المحمولة، مما يعزز الخصوصية والتطبيقات ذات زمن الاستجابة المنخفض. بعد ذلك، فكر في كيفية ملاءمة هذا النموذج لاتجاهات تطوير الذكاء الاصطناعي الأوسع، حيث تدفع الكفاءة الابتكار.
فهم بنية Gemma 3 270M
تبني جوجل Gemma 3 270M على بنية قائمة على المحولات (transformer-based architecture)، وتتميز بـ 170 مليون معلمة للتضمينات (embeddings) مع مفردات تضم 256,000 رمز، و 100 مليون لكتل المحولات (transformer blocks). يتيح هذا الإعداد دعمًا متعدد اللغات ومعالجة المهام المتخصصة. تستفيد من تقنيات مثل تكميم INT4، وتضمينات الموضع الدوراني (rotary position embeddings)، وانتباه استعلام المجموعة (group query attention)، مما يعزز سرعة الاستدلال والخفة.
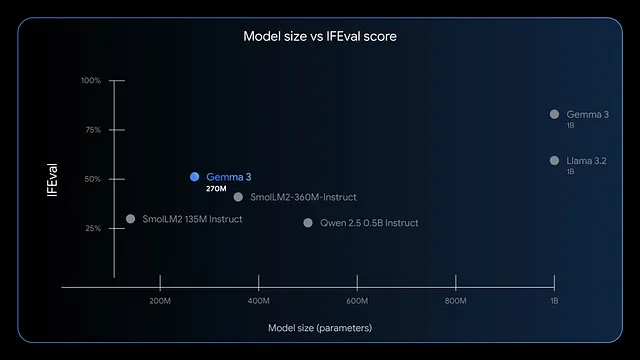
علاوة على ذلك، يتفوق النموذج في اتباع التعليمات واستخراج البيانات. تظهر المعايير درجات F1 عالية في IFEval، مما يشير إلى أداء قوي في مهام التقييم. مقارنة بالنماذج الأكبر مثل GPT-4 أو Phi-3 Mini، يعطي Gemma 3 270M الأولوية للكفاءة، حيث يستخدم أقل من 200 ميجابايت في وضع 4 بت على أجهزة مثل Apple M4 Max.
وبالتالي، يمكنك نشره لسيناريوهات تتطلب استجابات سريعة، مثل تحليل المشاعر في الوقت الفعلي أو استخراج الكيانات في الرعاية الصحية. ومع ذلك، فإن حجمه الصغير لا يحد من الإبداع؛ يمكنك تطبيقه على الكتابة الإبداعية أو فحوصات الامتثال المالي. للمضي قدمًا، قم بتقييم مزايا تشغيل هذا النموذج محليًا.
فوائد تشغيل Gemma 3 270M محليًا
تعزز الخصوصية عن طريق الاحتفاظ بالبيانات على جهازك، وتجنب عمليات النقل السحابية التي قد تعرضها للخطر. يقلل Gemma 3 270M من زمن الاستجابة، حيث يقدم الاستجابات في أجزاء من الثانية بدلاً من الثواني. علاوة على ذلك، فإنه يقلل التكاليف حيث تتجنب رسوم الاشتراك لواجهات برمجة التطبيقات المستندة إلى السحابة.
بالإضافة إلى ذلك، تبرز كفاءة النموذج في استهلاك الطاقة. يستهلك 0.75% فقط من بطارية Pixel 9 Pro لـ 25 محادثة في وضع INT4 المكمم. هذه السمة تناسب الحوسبة المتنقلة وحوسبة الحافة، حيث تهم الطاقة. يمكنك أيضًا تخصيص النموذج بسهولة من خلال الضبط الدقيق باستخدام أدوات مثل LoRA، مما يتطلب الحد الأدنى من البيانات.
ومع ذلك، فإن التنفيذ المحلي يمكّن الفرق الصغيرة أو المطورين الأفراد. يمكنك التجربة بحرية، وتكرار التطبيقات مثل توجيه استعلامات التجارة الإلكترونية أو هيكلة النصوص القانونية. أثناء المضي قدمًا، تحقق مما إذا كان نظامك يلبي المتطلبات.
متطلبات النظام لاستدلال Gemma 3 270M
يتطلب Gemma 3 270M أجهزة متواضعة، مما يجعله متاحًا. لاستدلال يعتمد على وحدة المعالجة المركزية (CPU) فقط، تحتاج إلى 4 جيجابايت على الأقل من ذاكرة الوصول العشوائي (RAM) ومعالج حديث مثل Intel Core i5 أو ما يعادله. ومع ذلك، فإن تسريع وحدة معالجة الرسوميات (GPU) يحسن السرعة؛ تكفي بطاقة NVIDIA بذاكرة فيديو (VRAM) تبلغ 2 جيجابايت للإصدارات المكممة.
على وجه التحديد، في وضع 4 بت، يتناسب النموذج ضمن ذاكرة تبلغ 200 ميجابايت، مما يسمح بتشغيله على الأجهزة ذات الموارد المحدودة. يستفيد مستخدمو Apple silicon من MLX-LM، حيث يحققون أكثر من 650 رمزًا في الثانية على M4 Max. للضبط الدقيق، خصص 8 جيجابايت من ذاكرة الوصول العشوائي ووحدة معالجة رسوميات (GPU) بذاكرة فيديو (VRAM) تبلغ 4 جيجابايت للتعامل مع مجموعات البيانات الصغيرة بكفاءة.
الأهم من ذلك، أن أنظمة التشغيل مثل Windows أو macOS أو Linux تعمل، ولكن تأكد من وجود Python 3.10+ لتوافق المكتبات. تتطلب التخزين حوالي 1 جيجابايت لملفات النموذج. مع توفر هذه المتطلبات، يمكنك التثبيت والتشغيل دون مشاكل. الآن، استكشف طرق التثبيت.
اختيار الأداة المناسبة لتشغيل Gemma 3 270M محليًا
تدعم العديد من الأطر Gemma 3 270M، ويقدم كل منها نقاط قوة فريدة. يوفر Hugging Face Transformers مرونة للبرمجة النصية والتكامل في Python. يقدم LM Studio واجهة سهلة الاستخدام لإدارة النماذج.
بالإضافة إلى ذلك، يتيح llama.cpp استدلالًا فعالًا يعتمد على C++، وهو مثالي للتحسينات منخفضة المستوى. بالنسبة لأجهزة Apple، يعمل MLX على تحسين الأداء على شرائح M-series. تختار بناءً على خبرتك؛ يفضل المبتدئون LM Studio، بينما يميل المطورون نحو Transformers.
وبالتالي، تعمل هذه الأدوات على إضفاء الطابع الديمقراطي على الوصول. في الأقسام التالية، اتبع الأدلة خطوة بخطوة للطرق الشائعة.
دليل خطوة بخطوة: تشغيل Gemma 3 270M باستخدام Hugging Face Transformers
تبدأ بتثبيت المكتبات الضرورية. افتح الطرفية ونفّذ:
pip install transformers torch
يجلب هذا الأمر Transformers و PyTorch. بعد ذلك، استورد المكونات في نص Python البرمجي:
from transformers import AutoTokenizer, AutoModelForCausalLM
حمّل النموذج والمُحلل اللغوي (tokenizer):
model_name = "google/gemma-3-270m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
يقوم device_map="auto" بوضع النموذج على وحدة معالجة الرسوميات (GPU) إذا كانت متاحة. جهّز مدخلاتك:
input_text = "Explain quantum computing in simple terms."
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
ولّد المخرجات:
outputs = model.generate(**inputs, max_new_tokens=200)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
ينتج هذا شرحًا متماسكًا. للتحسين، أضف التكميم:
from transformers import BitsAndBytesConfig
quant_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config)
يقلل التكميم من استخدام الذاكرة. يمكنك معالجة الأخطاء عن طريق التأكد من تسجيل الدخول إلى Hugging Face للنماذج المقيدة:
from huggingface_hub import login
login(token="your_hf_token")
احصل على الرمز المميز من حسابك في Hugging Face. باستخدام هذا الإعداد، يمكنك إجراء الاستدلالات بشكل متكرر. ومع ذلك، للمستخدمين غير المتخصصين في Python، فكر في LM Studio بعد ذلك.
دليل خطوة بخطوة: تشغيل Gemma 3 270M باستخدام LM Studio
يوفر LM Studio واجهة سهلة الاستخدام. قم بتنزيله من lmstudio.ai وقم بتثبيته.
شغل التطبيق، ثم ابحث عن "gemma-3-270m" في مركز النماذج (model hub).
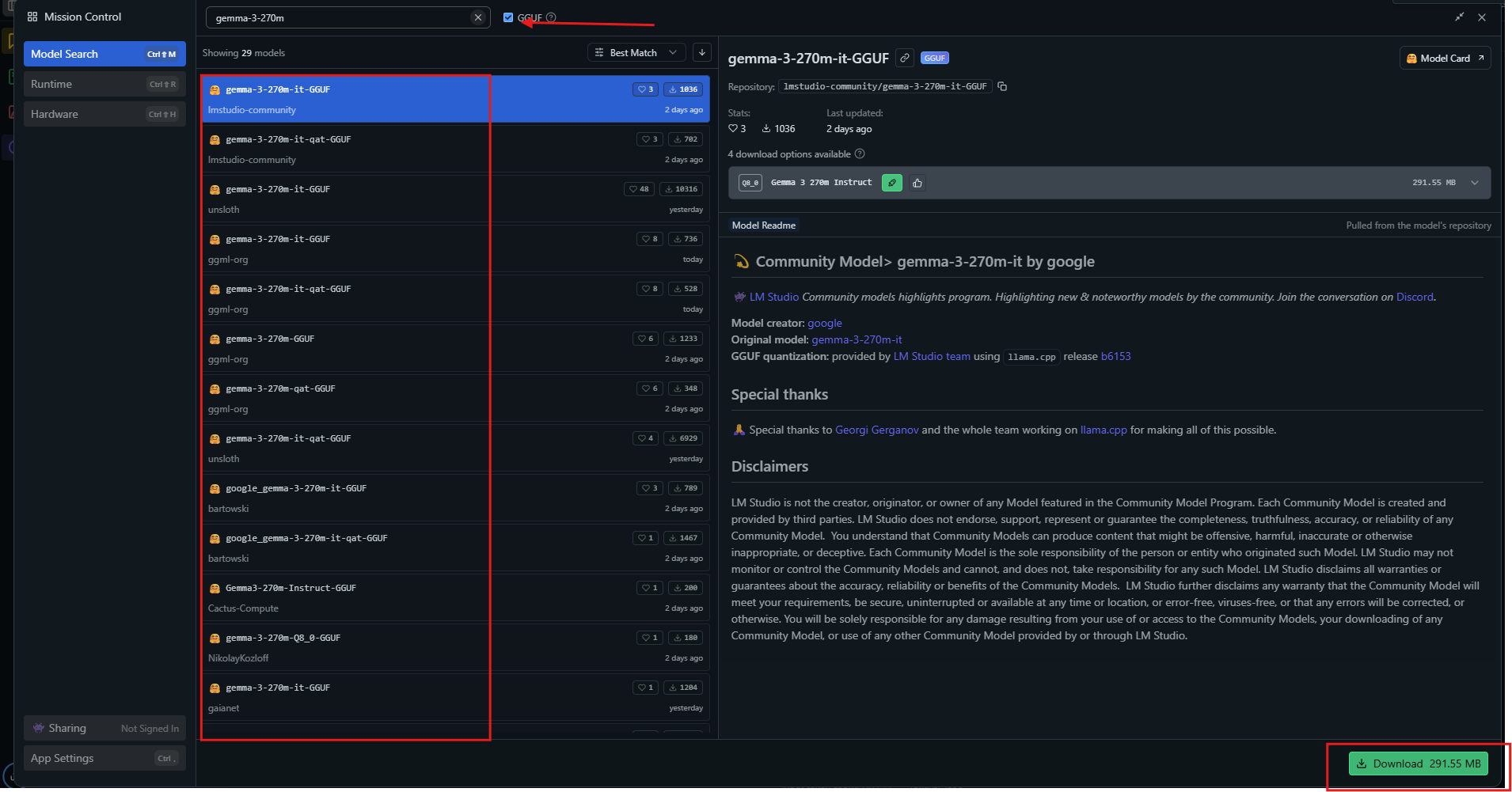
اختر نسخة مكممة مثل Q4_0 وقم بتنزيلها. بمجرد أن تصبح جاهزًا، حمّل النموذج من الشريط الجانبي. اضبط الإعدادات: اضبط السياق على 32 ألف، ودرجة الحرارة على 1.0.
أدخل موجهًا في نافذة الدردشة واضغط على إرسال. يعرض LM Studio الاستجابات مع سرعات الرموز. قم بتصدير الدردشات أو الضبط الدقيق عبر الأدوات المدمجة.
للاستخدام المتقدم، قم بتمكين تفريغ وحدة معالجة الرسوميات (GPU offloading) في الإعدادات. يختار LM Studio تلقائيًا المصادر المثلى، مما يضمن التوافق. تناسب هذه الطريقة المتعلمين البصريين. بالإضافة إلى ذلك، استكشف llama.cpp لتحسينات الأداء.
دليل خطوة بخطوة: تشغيل Gemma 3 270M باستخدام llama.cpp
يقدم llama.cpp استدلالًا عالي الكفاءة. استنسخ المستودع:
git clone https://github.com/ggerganov/llama.cpp
ابنه:
make -j
نزّل ملفات GGUF من Hugging Face:
huggingface-cli download unsloth/gemma-3-270m-it-GGUF --include "*.gguf"
شغل الاستدلال:
./llama-cli -m gemma-3-270m-it-Q4_K_M.gguf -p "Build a simple AI app."
حدد معلمات مثل --n-gpu-layers 999 للاستخدام الكامل لوحدة معالجة الرسوميات (GPU). يدعم llama.cpp مستويات التكميم، موازنًا بين السرعة والدقة. يمكنك التجميع باستخدام CUDA لوحدات معالجة الرسوميات من NVIDIA:
make GGML_CUDA=1
هذا يسرع المعالجة. يتفوق llama.cpp في الأنظمة المدمجة. الآن، طبق النموذج في أمثلة عملية.
أمثلة عملية لاستخدام Gemma 3 270M محليًا
يمكنك إنشاء محلل مشاعر. أدخل مراجعات العملاء، ويصنفها النموذج على أنها إيجابية أو سلبية. قم ببرمجتها في Python:
prompt = "Classify: This product is amazing!"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0]))
يخرج Gemma 3 270M "إيجابي". وسّع ذلك ليشمل التلخيص:
text = "Long article here..."
prompt = f"Summarize: {text}"
# Generate summary
يكثف المحتوى بفعالية. للإجابة على الأسئلة، استعلم:
"ما الذي يسبب تغير المناخ؟"
يشرح النموذج الغازات الدفيئة. في الرعاية الصحية، استخرج الكيانات من الملاحظات. تظهر هذه الاستخدامات تعدد الاستخدامات. علاوة على ذلك، قم بالضبط الدقيق للتخصص.
الضبط الدقيق لـ Gemma 3 270M محليًا
الضبط الدقيق يكيف النموذج. استخدم مكتبة PEFT من Hugging Face:
pip install peft
حمّل بتكوين LoRA:
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(r=16, lora_alpha=32, target_modules=["q_proj", "v_proj"])
model = get_peft_model(model, lora_config)
جهّز مجموعة بيانات، ثم درّب:
from transformers import Trainer, TrainingArguments
trainer = Trainer(model=model, args=TrainingArguments(output_dir="./results"))
trainer.train()
يتطلب LoRA بيانات قليلة، وينتهي بسرعة على الأجهزة المتواضعة. احفظ وأعد تحميل المحول (adapter). هذا يعزز الأداء في المهام المخصصة مثل التنبؤ بحركات الشطرنج. ومع ذلك، راقب مشكلة التجهيز الزائد (overfitting).
نصائح لتحسين أداء Gemma 3 270M
يمكنك زيادة السرعة إلى أقصى حد عن طريق التكميم إلى 4 بت أو 8 بت. استخدم التجميع (batching) لعمليات استدلال متعددة. اضبط درجة الحرارة (temperature) على 1.0، و top_k=64، و top_p=0.95 كما هو موصى به.
على وحدات معالجة الرسوميات (GPUs)، قم بتمكين الدقة المختلطة. للسياقات الطويلة، أدر ذاكرة التخزين المؤقت KV بعناية. راقب ذاكرة الفيديو (VRAM) باستخدام أدوات مثل nvidia-smi. قم بتحديث المكتبات بانتظام للحصول على التحسينات.
وبالتالي، تحقق هذه التعديلات أكثر من 130 رمزًا في الثانية على الأجهزة المناسبة. تجنب الأخطاء الشائعة مثل رموز BOS المزدوجة في الموجهات. بالممارسة، يمكنك تحقيق تشغيل فعال.
الخاتمة
أنت الآن تمتلك المعرفة اللازمة لتشغيل Gemma 3 270M محليًا. من الإعداد إلى التحسين، كل خطوة تبني القدرة. جرب، وضبط بدقة، وانشر لتحقيق إمكاناته. النماذج الصغيرة مثل هذه تحدث تأثيرات كبيرة في إمكانية الوصول إلى الذكاء الاصطناعي.