
إذا كنت قد تمنت يومًا أن تتمكن من طرح أسئلة مباشرة على ملف PDF أو دليل تقني، فهذه الدليل مخصص لك. اليوم، سنقوم بإنشاء نظام توليد معزز بالاسترجاع (RAG) باستخدام DeepSeek R1، وهي أداة مفتوحة المصدر للتفكير العميق، وOllama، الإطار الخفيف لتشغيل نماذج الذكاء الاصطناعي المحلية.
هل أنت جاهز لتعزيز اختبار واجهة برمجة التطبيقات الخاصة بك؟ لا تنسَ الاطلاع على Apidog! تعمل Apidog كمنصة شاملة لإنشاء وإدارة وتشغيل الاختبارات والخوادم الوهمية، مما يتيح لك تحديد نقاط الاختناق والحفاظ على موثوقية واجهات برمجة التطبيقات الخاصة بك.
بدلاً من التعامل مع أدوات متعددة أو كتابة نصوص مطولة، يمكنك أتمتة الأجزاء الأساسية من سير العمل الخاص بك، وتحقيق تدفقات CI/CD سلسة، وتقضي المزيد من الوقت في تحسين ميزات منتجك.
إذا كان ذلك يبدو شيئًا يمكن أن يبسط حياتك، جرب Apidog!
في هذه المقالة، سنستكشف كيف يمكن لـ DeepSeek R1—وهو نموذج ينافس o1 من OpenAI في الأداء لكنه يكلف أقل بنسبة 95%—تعزيز أنظمة RAG الخاصة بك. دعونا نحلل لماذا يتوجه المطورون نحو هذه التقنية وكيف يمكنك بناء خط أنابيب RAG الخاص بك باستخدامها.
ما تكلفة نظام RAG المحلي هذا؟
| المكون | التكلفة |
|---|---|
| DeepSeek R1 1.5B | مجاني |
| Ollama | مجاني |
| حاسوب بذاكرة 16GB RAM | $0 |
تتميز نموذج DeepSeek R1 1.5B هنا لأنه:
- استرجاع مركز: فقط 3 قطع مستندات تغذي كل إجابة
- تحفيز صارم: "لا أعرف" تمنع الهلاوس
- تنفيذ محلي: صفر زمن تأخير مقابل واجهات برمجة التطبيقات السحابية
ما تحتاجه
قبل أن نبدأ بالبرمجة، دعنا نعد أدواتنا:
1. Ollama
تتيح لك Ollama تشغيل نماذج مثل DeepSeek R1 محليًا.
- قم بالتنزيل: https://ollama.com/
- قم بالتثبيت، ثم افتح طرفية الأوامر الخاصة بك وتشغيل:
ollama run deepseek-r1 # للنموذج 7B (الإعداد الافتراضي)
2. متغيرات نموذج DeepSeek R1
يتوفر DeepSeek R1 بأحجام تتراوح من 1.5B إلى 671B من المعلمات. في هذه العرض التوضيحي، سنستخدم نموذج 1.5B—مثالي لـ RAG خفيف الوزن:
ollama run deepseek-r1:1.5b
نصيحة محترف: تقدم النماذج الأكبر مثل 70B تفكيرًا أفضل ولكنه يتطلب ذاكرة RAM أكبر. ابدأ صغيرًا، ثم قم بتوسيع النطاق!

بناء خط أنابيب RAG: جولة برمجية
الخطوة 1: استيراد المكتبات
سنستخدم:
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
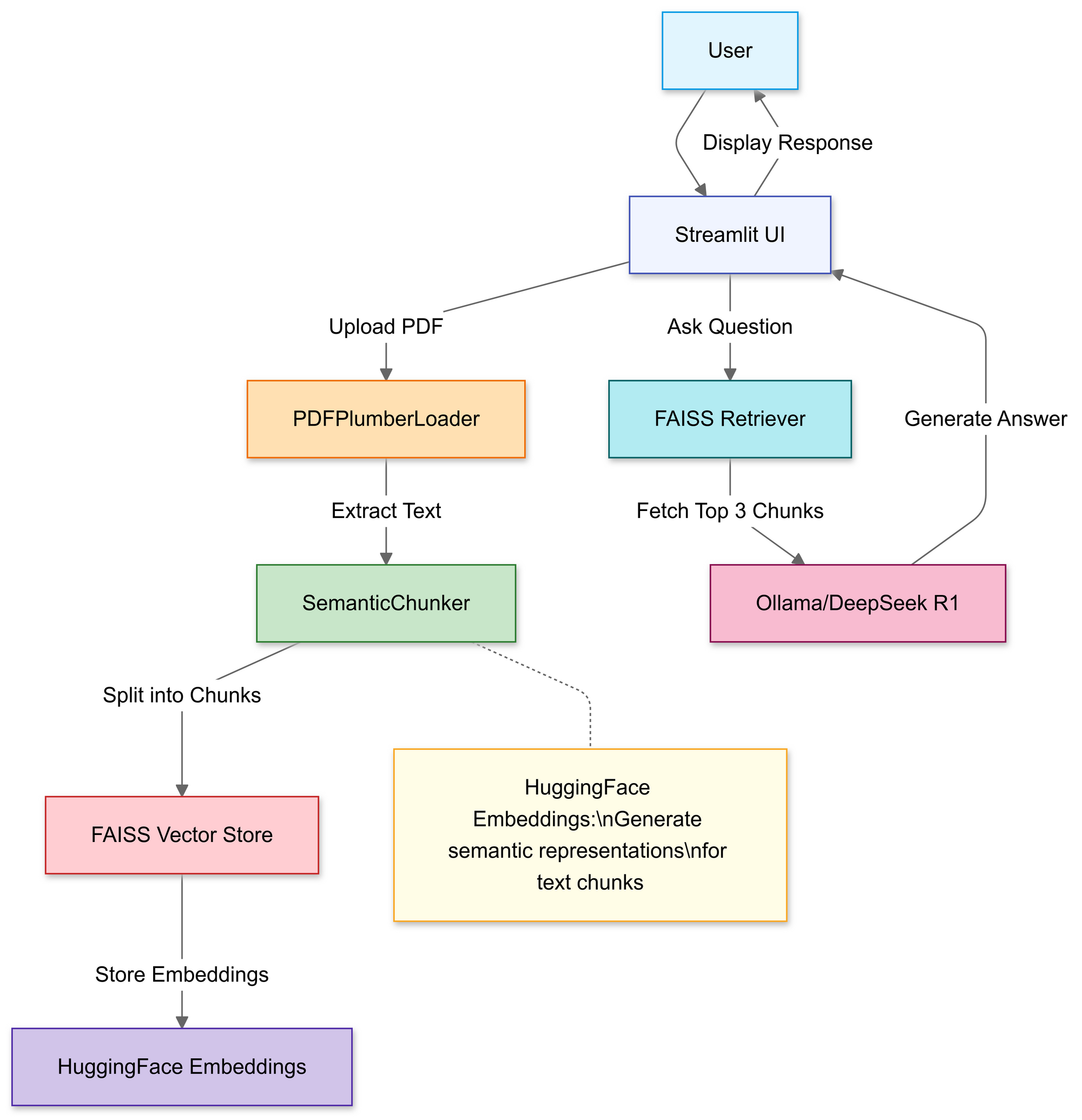
الخطوة 2: رفع ومعالجة ملفات PDF
في هذا القسم، ستستخدم مُحمِّل الملفات الخاص بـ Streamlit للسماح للمستخدمين باختيار ملف PDF محلي.
# مُحمِّل الملفات لستريمليت
uploaded_file = st.file_uploader("قم بتحميل ملف PDF", type="pdf")
if uploaded_file:
# حفظ PDF مؤقتًا
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# تحميل نص PDF
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
بمجرد التحميل، تقوم دالة PDFPlumberLoader باستخراج النص من PDF، مما يجعله جاهزًا للمرحلة التالية من الخط. هذه الطريقة مريحة لأنها تتولى قراءة محتوى الملف دون الحاجة إلى تحليل يدوي مطول.
الخطوة 3: تقسيم المستندات بشكل استراتيجي
نريد استخدام RecursiveCharacterTextSplitter، حيث يقوم الكود بتقسيم نص PDF الأصلي إلى قطع أصغر (دفقات). دعونا نشرح مفاهيم تقسيم النص بشكل جيد مقابل تقسيم النص بشكل سيء هنا:
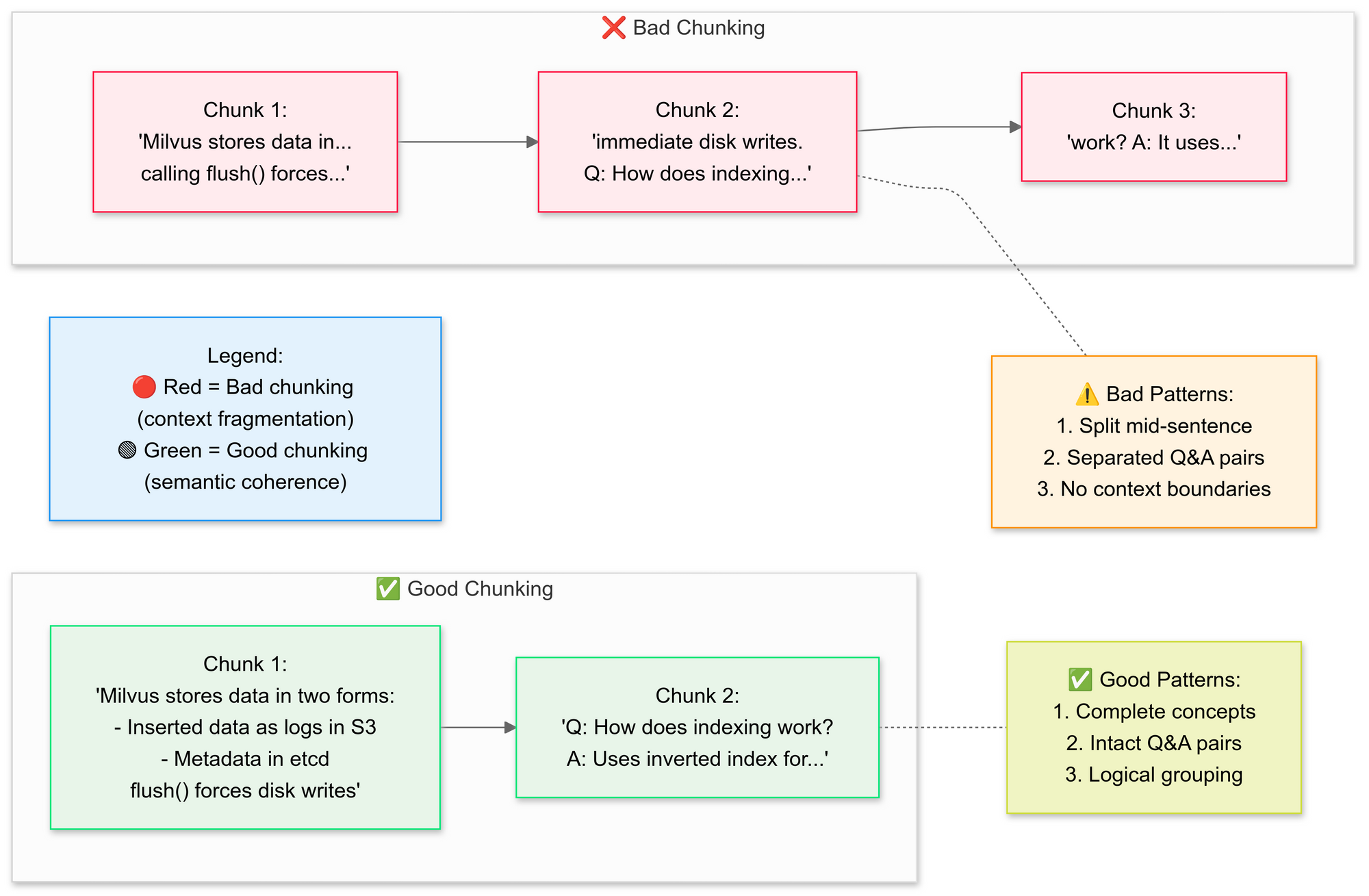
لماذا التقسيم الدلالي؟
- يجمع بين الجمل ذات الصلة (على سبيل المثال، "كيف يقوم Milvus بتخزين البيانات" تبقى سليمة)
- يتجنب تقسيم الجداول أو المخططات
# تقسيم النص إلى قطع دلالية
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
تحتفظ هذه الخطوة بالسياق من خلال تداخل الشرائح قليلاً، مما يساعد نموذج اللغة على تقديم إجابات أكثر دقة. كما أن القطع الصغيرة والمعرفة المحددة تجعل عمليات البحث أكثر كفاءة وملاءمة.
الخطوة 4: إنشاء قاعدة معرفة قابلة للبحث
بعد التقسيم، ينشئ الخط أنظمة تركيبية للقطع ويخزنها في فهرس FAISS.
# توليد التركيبات
embeddings = HuggingFaceEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings)
# ربط المسترجع
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # استرجاع أفضل 3 قطع
هذا يحول النص إلى تمثيل عددي يسهل الاستعلام عنه. يتم تشغيل الاستعلامات لاحقًا ضد هذا الفهرس للعثور على القطع الأكثر ملاءمة من الناحية السياقية.
الخطوة 5: تهيئة DeepSeek R1
هنا، تقوم بتأسيس سلسلة استرجاع QA باستخدام Deepseek R1 1.5B كنموذج لغة محلي.
llm = Ollama(model="deepseek-r1:1.5b") # نموذجنا بــ 1.5B معلمة
# إعداد نموذج التحفيز
prompt = """
1. استخدم فقط السياق أدناه.
2. إذا كنت غير متأكد، قل "لا أعرف".
3. حافظ على الإجابات تحت 4 جمل.
السياق: {context}
السؤال: {question}
الإجابة:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
هذا النموذج يجبر النموذج على أن تكون الإجابات مستندة إلى محتوى PDF الخاص بك. من خلال ربط نموذج اللغة بمسترجع مرتبط بفهرس FAISS، ستبحث أي استعلامات يتم تنفيذها عبر السلسلة عن السياق من محتوى PDF، مما يجعل الإجابات مستندة إلى المواد المصدرية.
الخطوة 6: تجميع سلسلة RAG
بعد ذلك، يمكنك ربط خطوات الرفع، والتقسيم، والاسترجاع في خط أنابيب متكامل.
# السلسلة 1: توليد الإجابات
llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)
# السلسلة 2: دمج قطع المستندات
document_prompt = PromptTemplate(
template="السياق:\nالمحتوى:{page_content}\nالمصدر:{source}",
input_variables=["page_content", "source"]
)
# خط أنابيب RAG النهائي
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt
),
retriever=retriever
)
هذا هو جوهر تصميم RAG (توليد معزز بالاسترجاع)، مما يوفر لنموذج اللغة الكبير سياقًا مثبتًا بدلاً من الاعتماد فقط على تدريبه الداخلي.
الخطوة 7: إطلاق واجهة الويب
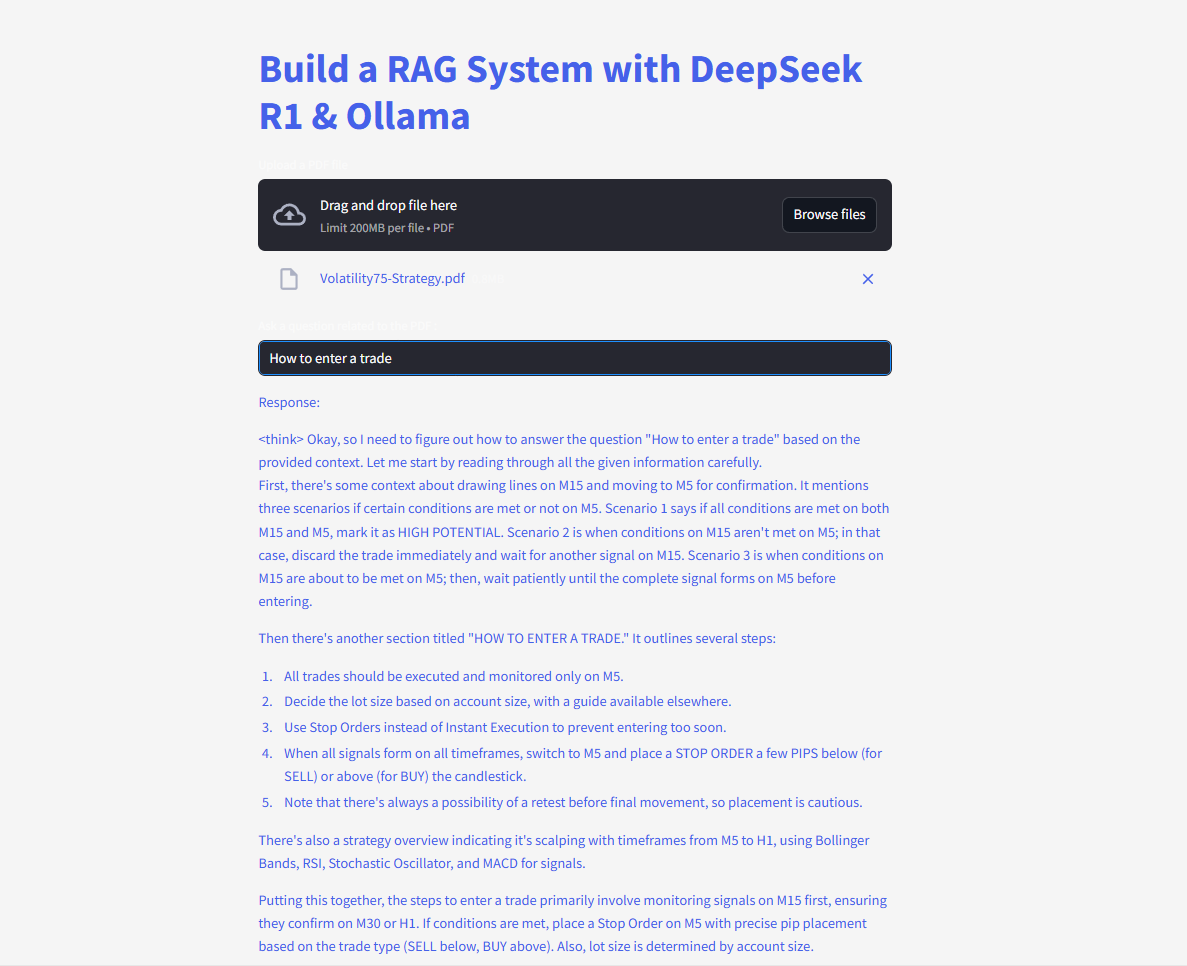
في النهاية، يستخدم الكود دالة إدخال النص ودالة الكتابة من Streamlit حتى يتمكن المستخدمون من كتابة الأسئلة ورؤية الردود على الفور.
# واجهة مستخدم ستريمليت
user_input = st.text_input("اسأل PDF الخاص بك سؤالًا:")
if user_input:
with st.spinner("يفكر..."):
response = qa(user_input)["result"]
st.write(response)
بمجرد أن يدخل المستخدم استعلامًا، تسترجع السلسلة أفضل القطع المتطابقة، وتغذيها إلى نموذج اللغة، وتعرض إجابة. مع تثبيت مكتبة langchain بشكل صحيح، يجب أن يعمل الكود الآن دون إثارة خطأ الوحدة المفقودة.
اطرح الأسئلة وقدّمها واحصل على إجابات فورية!
إليك الكود الكامل:
مستقبل RAG مع DeepSeek
مع ميزات مثل التحقق الذاتي والتفكير متعدد الخطوات قيد التطوير، يعتبر DeepSeek R1 معتمدًا لفتح المزيد من تطبيقات RAG المتقدمة. تخيل الذكاء الاصطناعي الذي لا يجيب فقط على الأسئلة بل يناقش منطقته الخاصة—بشكل مستقل.