
تُحدث نماذج اللغات الكبيرة (LLMs) مثل Qwen3 ثورة في مشهد الذكاء الاصطناعي بقدراتها الرائعة في البرمجة، الاستنتاج، وفهم اللغة الطبيعية. تم تطوير Qwen3 بواسطة فريق Qwen في Alibaba، وتقدم نماذج مقننة تتيح النشر المحلي الفعال، مما يجعلها متاحة للمطورين والباحثين والمتحمسين لتشغيل هذه النماذج القوية على أجهزتهم الخاصة. سواء كنت تستخدم Ollama، LM Studio، أو vLLM، سيرشدك هذا الدليل خلال عملية إعداد وتشغيل نماذج Qwen3 المقننة محليًا.
في هذا الدليل التقني، سنستكشف عملية الإعداد، اختيار النموذج، طرق النشر، وتكامل واجهة برمجة التطبيقات (API). لنبدأ.
ما هي نماذج Qwen3 المقننة؟
Qwen3 هو أحدث جيل من نماذج اللغات الكبيرة (LLMs) من Alibaba، مصمم لأداء عالٍ عبر مهام مثل البرمجة، الرياضيات، والاستنتاج العام. النماذج المقننة، مثل تلك الموجودة بتنسيقات BF16، FP8، GGUF، AWQ، و GPTQ، تقلل من متطلبات الحوسبة والذاكرة، مما يجعلها مثالية للنشر المحلي على الأجهزة الاستهلاكية.
تشمل عائلة Qwen3 نماذج متنوعة:
- Qwen3-235B-A22B (MoE): نموذج خليط من الخبراء بتنسيقات BF16، FP8، GGUF، و GPTQ-int4.
- Qwen3-30B-A3B (MoE): متغير آخر من MoE مع خيارات تقنين مماثلة.
- Qwen3-32B, 14B, 8B, 4B, 1.7B, 0.6B (Dense): نماذج كثيفة متوفرة بتنسيقات BF16، FP8، GGUF، AWQ، و GPTQ-int8.
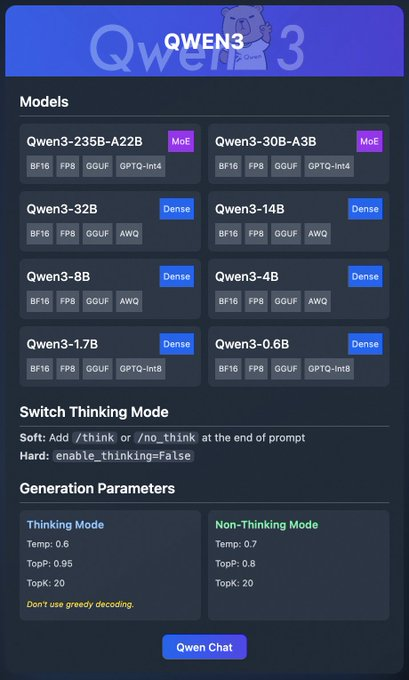
تدعم هذه النماذج النشر المرن من خلال منصات مثل Ollama، LM Studio، و vLLM، والتي سنتناولها بالتفصيل. بالإضافة إلى ذلك، يقدم Qwen3 ميزات مثل "وضع التفكير"، والذي يمكن تبديله لتحسين الاستنتاج، ومعلمات التوليد لضبط جودة المخرجات.
الآن بعد أن فهمنا الأساسيات، دعنا ننتقل إلى المتطلبات الأساسية لتشغيل Qwen3 محليًا.
المتطلبات الأساسية لتشغيل Qwen3 محليًا
قبل نشر نماذج Qwen3 المقننة، تأكد من أن نظامك يفي بالمتطلبات التالية:
الأجهزة:
- وحدة معالجة مركزية (CPU) أو وحدة معالجة رسومات (GPU) حديثة (يوصى بوحدات معالجة الرسومات NVIDIA لـ vLLM).
- ذاكرة وصول عشوائي (RAM) لا تقل عن 16 جيجابايت للنماذج الأصغر مثل Qwen3-4B؛ 32 جيجابايت أو أكثر للنماذج الأكبر مثل Qwen3-32B.
- مساحة تخزين كافية (على سبيل المثال، قد يتطلب Qwen3-235B-A22B GGUF حوالي 150 جيجابايت).
البرامج:
- نظام تشغيل متوافق (Windows، macOS، أو Linux).
- Python 3.8+ لـ vLLM وتفاعلات API.
- Docker (اختياري، لـ vLLM).
- Git لاستنساخ المستودعات.
التبعيات:
- قم بتثبيت المكتبات المطلوبة مثل
torch،transformers، وvllm(لـ vLLM). - قم بتنزيل ملفات Ollama أو LM Studio الثنائية من مواقعها الرسمية.
مع توفر هذه المتطلبات الأساسية، دعنا ننتقل إلى تنزيل نماذج Qwen3 المقننة.
الخطوة 1: تنزيل نماذج Qwen3 المقننة
أولاً، تحتاج إلى تنزيل النماذج المقننة من مصادر موثوقة. يوفر فريق Qwen نماذج Qwen3 على Hugging Face و ModelScope
- Hugging Face: مجموعة Qwen3
- ModelScope: مجموعة Qwen3
كيفية التنزيل من Hugging Face
- قم بزيارة مجموعة Qwen3 على Hugging Face.
- اختر نموذجًا، مثل Qwen3-4B بتنسيق GGUF للنشر الخفيف.
- انقر على زر "Download" أو استخدم أمر
git cloneلجلب ملفات النموذج:
git clone https://huggingface.co/Qwen/Qwen3-4B-GGUF
- قم بتخزين ملفات النموذج في دليل، مثل
/models/qwen3-4b-gguf.
كيفية التنزيل من ModelScope
- انتقل إلى مجموعة Qwen3 على ModelScope.
- اختر النموذج وتنسيق التقنين المطلوب (مثل AWQ أو GPTQ).
- قم بتنزيل الملفات يدويًا أو استخدم واجهة برمجة التطبيقات الخاصة بهم للوصول البرمجي.
بمجرد تنزيل النماذج، دعنا نستكشف كيفية نشرها باستخدام Ollama.
الخطوة 2: نشر Qwen3 باستخدام Ollama
Ollama يوفر طريقة سهلة الاستخدام لتشغيل نماذج اللغات الكبيرة (LLMs) محليًا بأقل قدر من الإعداد. يدعم تنسيق GGUF الخاص بـ Qwen3، مما يجعله مثاليًا للمبتدئين.
تثبيت Ollama
- قم بزيارة الموقع الرسمي لـ Ollama وقم بتنزيل الملف الثنائي لنظام التشغيل الخاص بك.
- قم بتثبيت Ollama عن طريق تشغيل المثبت أو اتباع تعليمات سطر الأوامر:
curl -fsSL https://ollama.com/install.sh | sh
- تحقق من التثبيت:
ollama --version
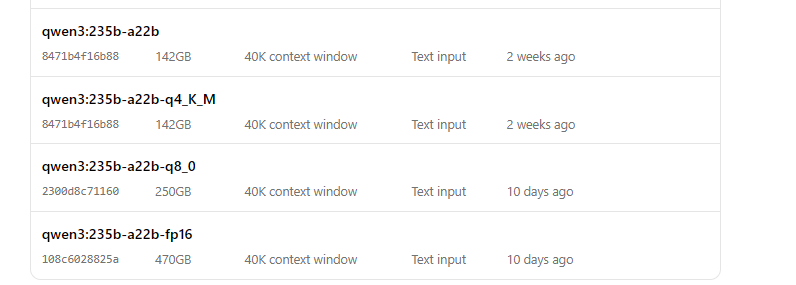
تشغيل Qwen3 باستخدام Ollama
- ابدأ النموذج:
ollama run qwen3:235b-a22b-q8_0- بمجرد تشغيل النموذج، يمكنك التفاعل معه عبر سطر الأوامر:
>>> Hello, how can I assist you today?
يوفر Ollama أيضًا نقطة نهاية API محلية (عادةً http://localhost:11434) للوصول البرمجي، والتي سنختبرها لاحقًا باستخدام Apidog.
بعد ذلك، دعنا نستكشف كيفية استخدام LM Studio لتشغيل Qwen3.
الخطوة 3: نشر Qwen3 باستخدام LM Studio
LM Studio أداة شائعة أخرى لتشغيل نماذج اللغات الكبيرة (LLMs) محليًا، وتقدم واجهة رسومية لإدارة النماذج.
تثبيت LM Studio
- قم بتنزيل LM Studio من موقعه الرسمي.
- قم بتثبيت التطبيق باتباع التعليمات التي تظهر على الشاشة.
- قم بتشغيل LM Studio وتأكد من أنه يعمل.
تحميل Qwen3 في LM Studio
في LM Studio، انتقل إلى قسم "Local Models" (النماذج المحلية).
انقر على "Add Model" (إضافة نموذج) وابحث عن النموذج لتنزيله:
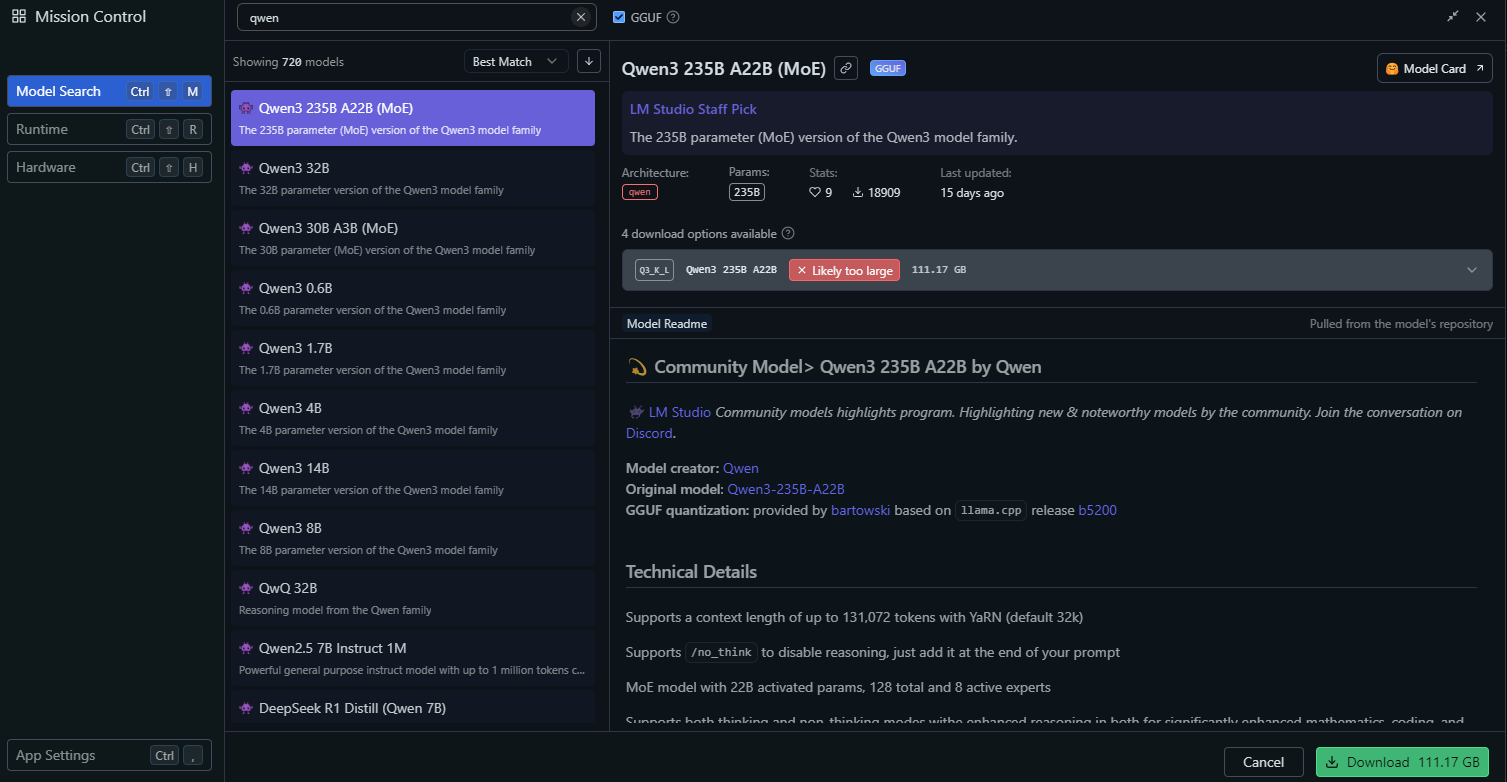
قم بتكوين إعدادات النموذج، مثل:
- Temperature (درجة الحرارة): 0.6
- Top-P: 0.95
- Top-K: 20
تطابق هذه الإعدادات معلمات وضع التفكير الموصى بها لـ Qwen3.
ابدأ تشغيل خادم النموذج بالنقر على "Start Server" (بدء الخادم). سيوفر LM Studio نقطة نهاية API محلية (على سبيل المثال، http://localhost:1234).
التفاعل مع Qwen3 في LM Studio
- استخدم واجهة الدردشة المدمجة في LM Studio لاختبار النموذج.
- بدلاً من ذلك، يمكنك الوصول إلى النموذج عبر نقطة نهاية API الخاصة به، والتي سنستكشفها في قسم اختبار API.
مع إعداد LM Studio، دعنا ننتقل إلى طريقة نشر أكثر تقدمًا باستخدام vLLM.
الخطوة 4: نشر Qwen3 باستخدام vLLM
vLLM هو حل تقديم عالي الأداء محسّن لنماذج اللغات الكبيرة (LLMs)، ويدعم نماذج Qwen3 المقننة بتنسيقات FP8 و AWQ. إنه مثالي للمطورين الذين يبنون تطبيقات قوية.
تثبيت vLLM
- تأكد من تثبيت Python 3.8+ على نظامك.
- قم بتثبيت vLLM باستخدام pip:
pip install vllm
- تحقق من التثبيت:
python -c "import vllm; print(vllm.__version__)"
تشغيل Qwen3 باستخدام vLLM
ابدأ تشغيل خادم vLLM باستخدام نموذج Qwen3 الخاص بك
# Load and run the model:
vllm serve "Qwen/Qwen3-235B-A22B"العلامة --enable-thinking=False تعطل وضع التفكير في Qwen3.
بمجرد بدء تشغيل الخادم، سيوفر نقطة نهاية API على http://localhost:8000.
تكوين vLLM للحصول على الأداء الأمثل
يدعم vLLM تكوينات متقدمة، مثل:
- Tensor Parallelism (موازاة الموترات): اضبط
--tensor-parallel-sizeبناءً على إعداد وحدة معالجة الرسومات (GPU) الخاصة بك. - Context Length (طول السياق): يدعم Qwen3 ما يصل إلى 32,768 رمزًا، والذي يمكن تعيينه عبر
--max-model-len 32768. - Generation Parameters (معلمات التوليد): استخدم API لتعيين
temperature،top_p، وtop_k(على سبيل المثال، 0.7، 0.8، 20 لوضع عدم التفكير).
مع تشغيل vLLM، دعنا نختبر نقطة نهاية API باستخدام Apidog.
الخطوة 5: اختبار Qwen3 API باستخدام Apidog
Apidog أداة قوية لاختبار نقاط نهاية API، مما يجعلها مثالية للتفاعل مع نموذج Qwen3 المنشور محليًا.
إعداد Apidog
- قم بتنزيل وتثبيت Apidog من الموقع الرسمي.
- قم بتشغيل Apidog وإنشاء مشروع جديد.
اختبار Ollama API
- أنشئ طلب API جديدًا في Apidog.
- عيّن نقطة النهاية إلى
http://localhost:11434/api/generate. - قم بتكوين الطلب:
- Method (الأسلوب): POST
- Body (الجسم) (JSON):
{
"model": "qwen3-4b",
"prompt": "Hello, how can I assist you today?",
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20
}
- أرسل الطلب وتحقق من الاستجابة.
اختبار vLLM API
- أنشئ طلب API آخر في Apidog.
- عيّن نقطة النهاية إلى
http://localhost:8000/v1/completions. - قم بتكوين الطلب:
- Method (الأسلوب): POST
- Body (الجسم) (JSON):
{
"model": "qwen3-4b-awq",
"prompt": "Write a Python script to calculate factorial.",
"max_tokens": 512,
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20
}
- أرسل الطلب وتحقق من المخرجات.
يجعل Apidog من السهل التحقق من نشر Qwen3 الخاص بك والتأكد من أن API يعمل بشكل صحيح. الآن، دعنا نضبط أداء النموذج.
الخطوة 6: ضبط أداء Qwen3
لتحسين أداء Qwen3، اضبط الإعدادات التالية بناءً على حالة الاستخدام الخاصة بك:
وضع التفكير
يدعم Qwen3 "وضع التفكير" لتعزيز الاستنتاج، كما هو موضح في صورة منشور X. يمكنك التحكم فيه بطريقتين:
- تبديل ناعم: أضف
/thinkأو/no_thinkإلى طلبك.
- مثال:
Solve this math problem /think.
- تبديل صارم: عطل التفكير تمامًا في vLLM باستخدام
--enable-thinking=False.
معلمات التوليد
اضبط معلمات التوليد للحصول على جودة مخرجات أفضل:
- Temperature (درجة الحرارة): استخدم 0.6 لوضع التفكير أو 0.7 لوضع عدم التفكير.
- Top-P: اضبطه على 0.95 (تفكير) أو 0.8 (عدم تفكير).
- Top-K: استخدم 20 لكلا الوضعين.
- تجنب فك التشفير الجشع (greedy decoding)، كما أوصى به فريق Qwen.
قم بتجربة هذه الإعدادات لتحقيق التوازن المطلوب بين الإبداع والدقة.
استكشاف الأخطاء الشائعة وإصلاحها
أثناء نشر Qwen3، قد تواجه بعض المشكلات. فيما يلي حلول للمشاكل الشائعة:
فشل تحميل النموذج في Ollama:
- تأكد من أن مسار ملف GGUF في
Modelfileصحيح. - تحقق مما إذا كان نظامك يحتوي على ذاكرة كافية لتحميل النموذج.
خطأ موازاة الموترات في vLLM:
- إذا رأيت خطأ مثل "output_size is not divisible by weight quantization block_n"، قم بتقليل
--tensor-parallel-size(على سبيل المثال، إلى 4).
فشل طلب API في Apidog:
- تحقق من أن الخادم (Ollama، LM Studio، أو vLLM) قيد التشغيل.
- تحقق مرة أخرى من عنوان URL لنقطة النهاية وحمولة الطلب.
من خلال معالجة هذه المشكلات، يمكنك ضمان تجربة نشر سلسة.
الخلاصة
يعد تشغيل نماذج Qwen3 المقننة محليًا عملية مباشرة باستخدام أدوات مثل Ollama، LM Studio، و vLLM. سواء كنت مطورًا يبني تطبيقات أو باحثًا يجرب نماذج اللغات الكبيرة (LLMs)، يقدم Qwen3 المرونة والأداء الذي تحتاجه. باتباع هذا الدليل، تعلمت كيفية تنزيل النماذج من Hugging Face و ModelScope، ونشرها باستخدام أطر عمل مختلفة، واختبار نقاط نهاية API الخاصة بها باستخدام Apidog.
ابدأ استكشاف Qwen3 اليوم واطلق العنان لقوة نماذج اللغات الكبيرة المحلية لمشاريعك!