
تطلق علي بابا نموذج Qwen3-Max، وهو نموذج لغوي كبير رائد يدفع حدود قدرات الذكاء الاصطناعي. ينبثق هذا النموذج من سلسلة Qwen، المعروفة بتقدمها في نماذج الأساس المفتوحة التي تهدف إلى الذكاء الاصطناعي العام. يمكن للمطورين والباحثين الآن الوصول إلى أداة تتفوق في المهام المعقدة، من تحديات البرمجة إلى الاستدلال متعدد الأوجه. ومع قيام الفرق بدمج Qwen3-Max عبر واجهة برمجة التطبيقات (API) الخاصة به للتطبيقات الواقعية، يصبح الاختبار الفعال ضروريًا.
يتوسع Qwen3-Max ليشمل أكثر من تريليون معلمة، وقد تم تدريبه على 36 تريليون رمز مميز - ضعف ما تم تدريب Qwen2.5 عليه. يتعامل مع المهام الوكيلية ويتبع التعليمات بدقة. على الرغم من أنه يبدأ بدون أوضاع تفكير صريحة، إلا أن الميزات القادمة ستضيف تحسينات في الاستدلال.
يدعم النموذج أكثر من 100 لغة، مما يوسع نطاق استخدامه عالميًا. توفر علي بابا وصولاً إلى واجهة برمجة التطبيقات (API) على سحابتها، مما يبسط عملية النشر.
المواصفات الفنية لـ Qwen3-Max
تصمم علي بابا Qwen3-Max مع التركيز على قابلية التوسع والكفاءة. يضم النموذج أكثر من تريليون معلمة، مما يضعه ضمن أكبر نماذج الذكاء الاصطناعي المتاحة عبر واجهة برمجة التطبيقات (API). يتيح هذا الحجم الهائل للنظام معالجة كميات هائلة من البيانات أثناء التدريب المسبق، مما يؤدي إلى قدرات قوية في التعرف على الأنماط والتوليد. يقوم المهندسون بتدريب Qwen3-Max على مجموعة بيانات تتجاوز 36 تريليون رمز مميز، مما يضاعف الحجم المستخدم في الأجيال السابقة مثل Qwen2.5.

يتميز Qwen3-Max بنافذة سياق تبلغ 262,144 رمزًا مميزًا، بحد أقصى للإدخال يبلغ 258,048 رمزًا مميزًا وحد أقصى للإخراج يبلغ 65,536 رمزًا مميزًا. يتيح هذا السياق الواسع للنموذج التعامل مع المستندات الطويلة والمحادثات الممتدة وتسلسلات حل المشكلات المعقدة دون فقدان الترابط. يستفيد المطورون من هذا في تطبيقات مثل تحليل المستندات أو الحوارات متعددة الأدوار. ومع ذلك، قد تفرض واجهة الدردشة قيودًا واضحة، لكن النموذج الأساسي يدعم السعة الكاملة من خلال استدعاءات واجهة برمجة التطبيقات.
يعمل Qwen3-Max كنموذج توجيهي غير تفكيري في إصداره الأولي، مع إعطاء الأولوية لتوليد الاستجابات المباشرة. تخطط علي بابا لتقديم ميزات استدلالية، بما في ذلك استخدام الأدوات ونشر الوضع الثقيل، والتي تعد بتحقيق درجات قياسية شبه مثالية. تعتمد البنية على سلسلة Qwen3، وتتضمن تحسينات في اتباع التعليمات، وتقليل الهلوسة، ودعم متعدد اللغات معزز. للنشر، تسهل أطر العمل مثل vLLM و SGLang الخدمة الفعالة، ودعم التوازي الموتر عبر وحدات معالجة الرسوميات المتعددة.
فيما يتعلق بمتطلبات الأجهزة، يتطلب Qwen3-Max موارد حوسبة كبيرة. يتطلب تشغيله محليًا إعدادات عالية الأداء، لكن الوصول إلى واجهة برمجة التطبيقات يخفف من هذا من خلال الاستفادة من البنية التحتية السحابية لعلي بابا. يتبع التسعير هيكلًا متدرجًا يعتمد على حجم الرموز المميزة: لـ 0-32 ألف رمز، تبلغ تكلفة الإدخال 1.2 دولار لكل مليون، والإخراج 6 دولارات لكل مليون؛ لـ 32 ألف - 128 ألف، 2.4 دولار و 12 دولارًا؛ ولـ 128 ألف - 252 ألف، 3 دولارات و 15 دولارًا. يحصل المستخدمون الجدد على حصة مجانية تبلغ مليون رمز مميز صالحة لمدة 90 يومًا، مما يشجع على التجربة.
بالإضافة إلى ذلك، يتكامل Qwen3-Max مع واجهات برمجة التطبيقات المتوافقة مع OpenAI، مما يبسط عملية الانتقال من مقدمي الخدمات الآخرين. يمتد هذا التوافق ليشمل التخزين المؤقت للسياق، الذي يحسن الاستعلامات المتكررة ويقلل التكاليف في بيئات الإنتاج. ومع ذلك، للعمليات المستقرة، يختار المستخدمون بين أحدث الإصدارات وإصدارات اللقطات لإدارة حدود المعدل بفعالية.
تحليل أداء المعايير
يُظهر Qwen3-Max نتائج استثنائية عبر العديد من المعايير، مما يعزز مكانته كرائد في أداء الذكاء الاصطناعي. تُقيّم علي بابا النموذج على اختبارات صارمة تركز على البرمجة والرياضيات والاستدلال العام. على سبيل المثال، في SuperGPQA، يحقق Qwen3-Max-Instruct درجة 65.1، متجاوزًا Claude Opus 4 الذي حقق 56.5 و DeepSeek-V3.1 الذي حقق 43.9.
علاوة على ذلك، في AIME25، وهو معيار رياضي صعب، يحقق Qwen3-Max درجة 81.6، متقدمًا بشكل كبير على Qwen3-235B-A22B الذي حقق 70.3 وغيره. يسلط هذا الضوء على براعته في حل المشكلات الرياضية المتقدمة، حيث تثبت الدقة والاستنتاج المنطقي أهميتهما الحاسمة. بالانتقال إلى تقييمات البرمجة، يحقق LiveCodeBench v6 درجة 74.8 لـ Qwen3-Max، متفوقًا على المنافسين مثل Non-thinking الذي حقق 52.3.
علاوة على ذلك، يحقق Qwen3-Max في Tau2-Bench (الموثق) 69.6، بينما يسجل SWE-Bench الموثق 72.5، وكلاهما يتصدر المجموعة. تنبع هذه الدرجات من تحديات البرمجة الواقعية، حيث يحل النموذج المشكلات من مستودعات GitHub بفعالية. تعزو علي بابا هذا إلى التوسع الحسابي المستمر والبيانات الضخمة للتدريب المسبق.
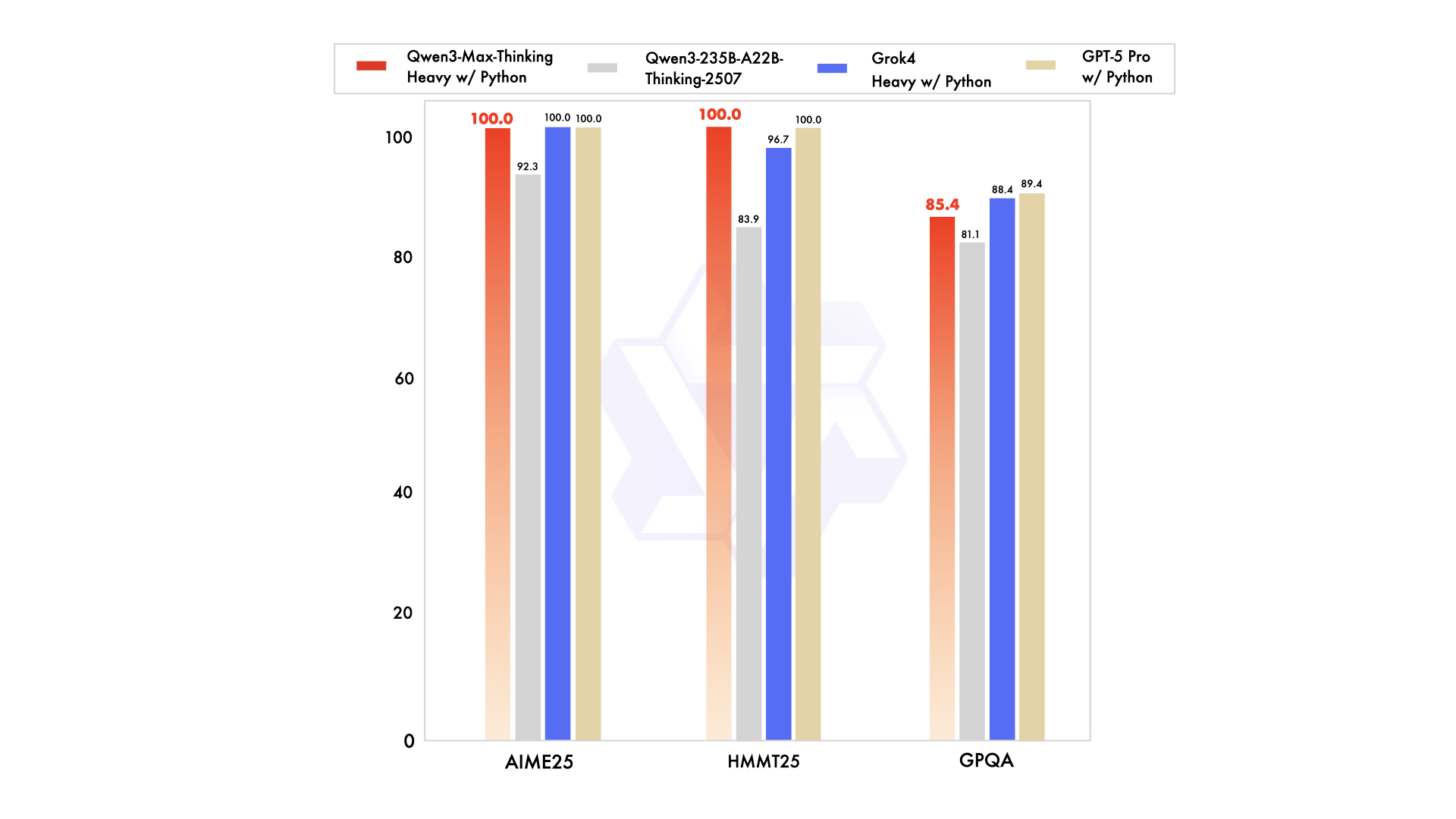
بالإضافة إلى ذلك، يتفوق Qwen3-Max في معايير الوكلاء مثل Arena-Hard v2 و LiveBench، حيث يحتل باستمرار مرتبة أعلى من Claude Opus 4 و DeepSeek-V3.1. تكشف اختبارات المجتمع عن أدلة قصصية على سلوك شبيه بالاستدلال في المهام الأصعب، مما ينتج استجابات منظمة على الرغم من قاعدته غير الاستدلالية. ومع ذلك، تؤكد المعايير الرسمية موثوقيته، مع معدلات نجاح 100% في مجالات مثل الهلوسة والمعرفة العامة والأخلاق.
يلاحظ المحللون أن زيادة ميزانيات التفكير، عند تفعيلها، تعزز الأداء في مجالات الرياضيات والبرمجة والعلوم. توفر هذه الميزة التي يتحكم فيها المستخدم، والمتاحة في تطبيق Qwen، تحكمًا دقيقًا في عمق الاستدلال. بشكل عام، تؤكد هذه المقاييس كفاءة Qwen3-Max، حيث يحتل المرتبة 63 في المائة للسرعة و 34 في المائة للتسعير بين أقرانه.
مقارنات مع نماذج الذكاء الاصطناعي الرائدة
يتنافس Qwen3-Max مباشرة مع نماذج رائدة مثل GPT-5 و Claude 4 Opus و DeepSeek-V3.1. في مهام البرمجة، يتفوق Qwen3-Max على DeepSeek-V3.1 في تطوير الواجهة الأمامية وتحويلات Java، على الرغم من أن تحسينات Python لا تزال متواضعة. تسلط ملاحظات المجتمع على منصات مثل Reddit الضوء على إمكاناته لمضاهاة أو تجاوز GPT-5 Pro قبل نهاية العام.
بالإضافة إلى ذلك، يتفوق Qwen3-Max على Claude Opus 4 في SuperGPQA و AIME25، مما يدل على قدرات رياضية وعامة أقوى. يوفر مقياس التريليون معلمة للنموذج ميزة في تغطية المعرفة طويلة الذيل، مما يقلل من الهلوسة مقارنة بأسلافه. ومع ذلك، توفر أوضاع الاستدلال في Claude مزايا في سيناريوهات معينة، والتي سيعالجها Qwen3-Max بالتحديثات القادمة.
في المهام متعددة اللغات، يدعم Qwen3-Max أكثر من 100 لغة، منافسًا Gemini-2.5-Pro و Grok-3. تُظهر المعايير نتائج تنافسية ضد هذه النماذج، خاصة في اتباع التعليمات واستخدام الأدوات. من حيث التسعير، يثبت Qwen3-Max أنه أكثر فعالية من حيث التكلفة، مع أسعار متدرجة تقل عن الخيارات المميزة من OpenAI و Anthropic.
علاوة على ذلك، مقارنة بالنماذج ذات الوزن المفتوح مثل Qwen3-235B-A22B، يعزز متغير Max المهارات الوكيلية دون الحاجة إلى تفكير عميق، محققًا درجات أعلى في SWE-Bench و Tau2-Bench. هذا يضعه كنموذج هجين بين نقاط القوة مفتوحة المصدر ومغلقة المصدر، على الرغم من أن طبيعته مغلقة المصدر تثير نقاشات حول إمكانية الوصول.
الميزات والقدرات الرئيسية
يتفوق Qwen3-Max في اتباع التعليمات للروبوتات الدردشة والكتابة. يضمن تقليل الهلوسة الموثوقية في التصنيف والأخلاق.
تتعامل الميزات الوكيلية مع العمليات متعددة الخطوات عبر استدعاء أداة Qwen-Agent. الاستجابات السريعة تناسب التطبيقات في الوقت الفعلي.
يدعم استدعاء الوظائف المتوافق مع OpenAI. يساعد السياق الطويل في تحليل البيانات؛ تعزز المعلمات الإبداع.
بصفته غير استدلالي، يتكيف مع التفكير المنظم. ميزانيات التفكير المستقبلية تضبط أداء المجال.
تكامل واستخدام واجهة برمجة التطبيقات مع Apidog
يصل المطورون إلى Qwen3-Max بشكل أساسي عبر واجهة برمجة تطبيقات Alibaba Cloud، التي تدعم نقاط نهاية متوافقة مع OpenAI. يتيح هذا الإعداد التكامل المباشر في التطبيقات باستخدام المكتبات القياسية. على سبيل المثال، يستدعي المستخدمون واجهة برمجة التطبيقات بطلبات مثل "لماذا السماء زرقاء؟" لتوليد الاستجابات.
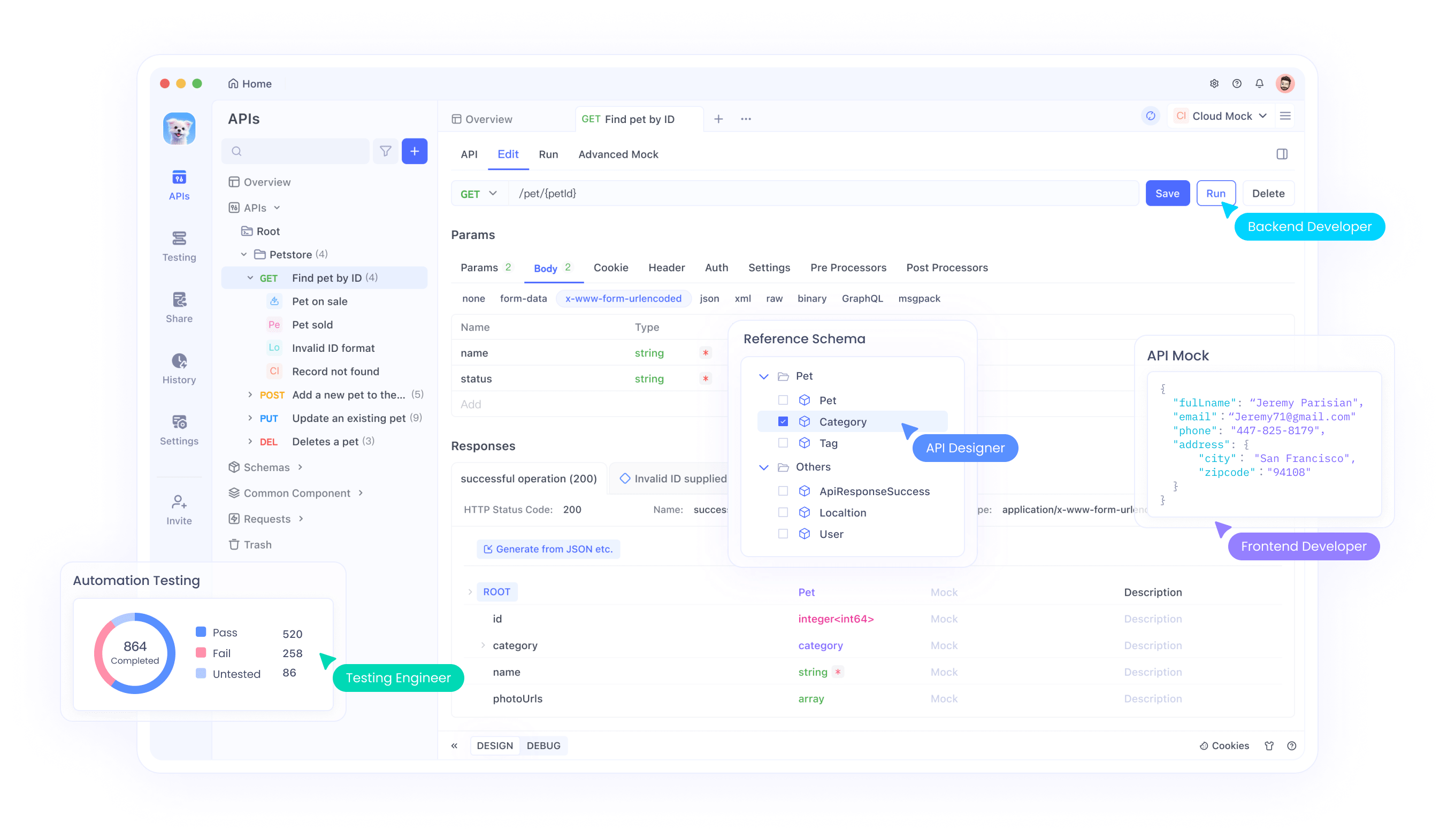
يلعب Apidog دورًا حاسمًا هنا، حيث يوفر منصة بديهية لاختبار وإدارة واجهة برمجة التطبيقات. يستخدم المهندسون Apidog لمحاكاة الطلبات ومراقبة الاستجابات وتصحيح أخطاء التكامل مع Qwen3-Max. تعمل ميزات الأداة، مثل تسلسل الطلبات والمتغيرات البيئية، على تبسيط سير العمل عند التعامل مع أحجام كبيرة من الرموز المميزة.
علاوة على ذلك، يدعم Apidog التعاون، مما يسمح للفرق بمشاركة مجموعات واجهة برمجة التطبيقات لمشاريع Qwen3-Max. للبدء، قم بتنزيل Apidog مجانًا واستورد مواصفات واجهة برمجة تطبيقات Qwen من وثائق علي بابا. يضمن هذا الاختبار الفعال لميزات مثل التخزين المؤقت للسياق، والذي يقلل من زمن الاستجابة في المهام المتكررة.
بالإضافة إلى ذلك، تعمل عمليات التكامل مع مزودي الخدمة مثل OpenRouter و Vercel AI Gateway على توسيع الخيارات. يسهل Apidog التبديل بين هذه الخيارات، مما يضمن التوافق ومراقبة الأداء عبر الأنظمة البيئية.
حالات استخدام Qwen3-Max
تطبق المنظمات Qwen3-Max في سيناريوهات متنوعة، مستفيدة من قدراته للابتكار. في تطوير البرمجيات، يساعد النموذج في توليد الكود وتصحيح الأخطاء، وحل مشكلات GitHub بدقة عالية على SWE-Bench. يدمجه المطورون عبر واجهة برمجة التطبيقات لأتمتة طلبات السحب أو إعادة هيكلة الكود القديم.
علاوة على ذلك، في التعليم، يحل Qwen3-Max مشكلات الرياضيات المتقدمة، مما يساعد المعلمين في شرح المفاهيم من معايير AIME25. يتيح دعمه متعدد اللغات لمنصات التعلم العالمية تقديم المحتوى باللغات الأم.
في بيئات الشركات، تعمل الميزات الوكيلية على تشغيل أدوات الأتمتة، مثل روبوتات الدردشة لخدمة العملاء أو مسارات تحليل البيانات. يستخدمه مقدمو الرعاية الصحية لدعم اتخاذ القرارات الأخلاقية، مستفيدين من الدرجات الكاملة في معايير الأخلاق.
علاوة على ذلك، تستخدم الصناعات الإبداعية Qwen3-Max للكتابة وتوليد المحتوى، حيث يضمن تقليل الهلوسة مخرجات عالية الجودة. تدمجه منصات التجارة الإلكترونية للتوصيات المخصصة، ومعالجة السياقات الطويلة من سجلات المستخدمين.
ومع ذلك، في البحث، يستكشف العلماء إمكاناته الاستدلالية للمحاكاة واختبار الفرضيات، متوقعين تحسينات في أوضاع التفكير.
الخاتمة
يُحدث Qwen3-Max تحولًا في مشهد الذكاء الاصطناعي بقوته التي تتجاوز تريليون معلمة وهيمنته في المعايير. يستغل المطورون قوته من خلال واجهات برمجة التطبيقات، المعززة بأدوات مثل Apidog للتكامل الفعال. ومع قيام علي بابا بتحسين النموذج، فإنه يعد بابتكارات أكبر في البرمجة والاستدلال وما بعدهما. تتبنى الفرق Qwen3-Max اليوم للبقاء تنافسية في مجال يتطور باستمرار.