
أصدر فريق Qwen في Alibaba Cloud إضافتين قويتين جديدتين إلى مجموعة نماذج اللغة الكبيرة (LLM) الخاصة بهم: Qwen3-4B-Instruct-2507 و Qwen3-4B-Thinking-2507. تقدم هذه النماذج تطورات كبيرة في الاستدلال، واتباع التعليمات، وفهم السياقات الطويلة، مع دعم أصلي لطول سياق يصل إلى 256 ألف رمز. صُممت هذه النماذج للمطورين والباحثين وعشاق الذكاء الاصطناعي، وتقدم قدرات قوية للمهام التي تتراوح من البرمجة إلى حل المشكلات المعقدة. بالإضافة إلى ذلك، يمكن لأدوات مثل Apidog، وهي منصة مجانية لإدارة واجهات برمجة التطبيقات (API)، تبسيط اختبار هذه النماذج ودمجها في تطبيقاتك.
زر
فهم نماذج Qwen3-4B
تمثل سلسلة Qwen3 أحدث تطور في عائلة نماذج اللغة الكبيرة من Alibaba Cloud، وهي خليفة لسلسلة Qwen2.5. على وجه التحديد، تم تصميم Qwen3-4B-Instruct-2507 و Qwen3-4B-Thinking-2507 لحالات استخدام متميزة: الأول يتفوق في الحوارات العامة واتباع التعليمات، بينما تم تحسين الأخير لمهام الاستدلال المعقدة. يدعم كلا النموذجين طول سياق أصلي يبلغ 262,144 رمزًا، مما يمكنهما من معالجة مجموعات بيانات واسعة، أو مستندات طويلة، أو محادثات متعددة الأدوار بسهولة. علاوة على ذلك، فإن توافقهما مع أطر عمل مثل Hugging Face Transformers وأدوات النشر مثل Apidog يجعلهما متاحين للتطبيقات المحلية والقائمة على السحابة.
Qwen3-4B-Instruct-2507: مُحسّن للكفاءة
يعمل نموذج Qwen3-4B-Instruct-2507 في وضع "غير تفكيري" (non-thinking mode)، مع التركيز على الاستجابات الفعالة وعالية الجودة للمهام العامة. تم ضبط هذا النموذج بدقة لتعزيز اتباع التعليمات، والاستدلال المنطقي، وفهم النصوص، والقدرات متعددة اللغات. ومن الجدير بالذكر أنه لا يُنشئ كتل <think></think>، مما يجعله مثاليًا للسيناريوهات التي تُفضل فيها الإجابات السريعة والمباشرة على الاستدلال خطوة بخطوة.
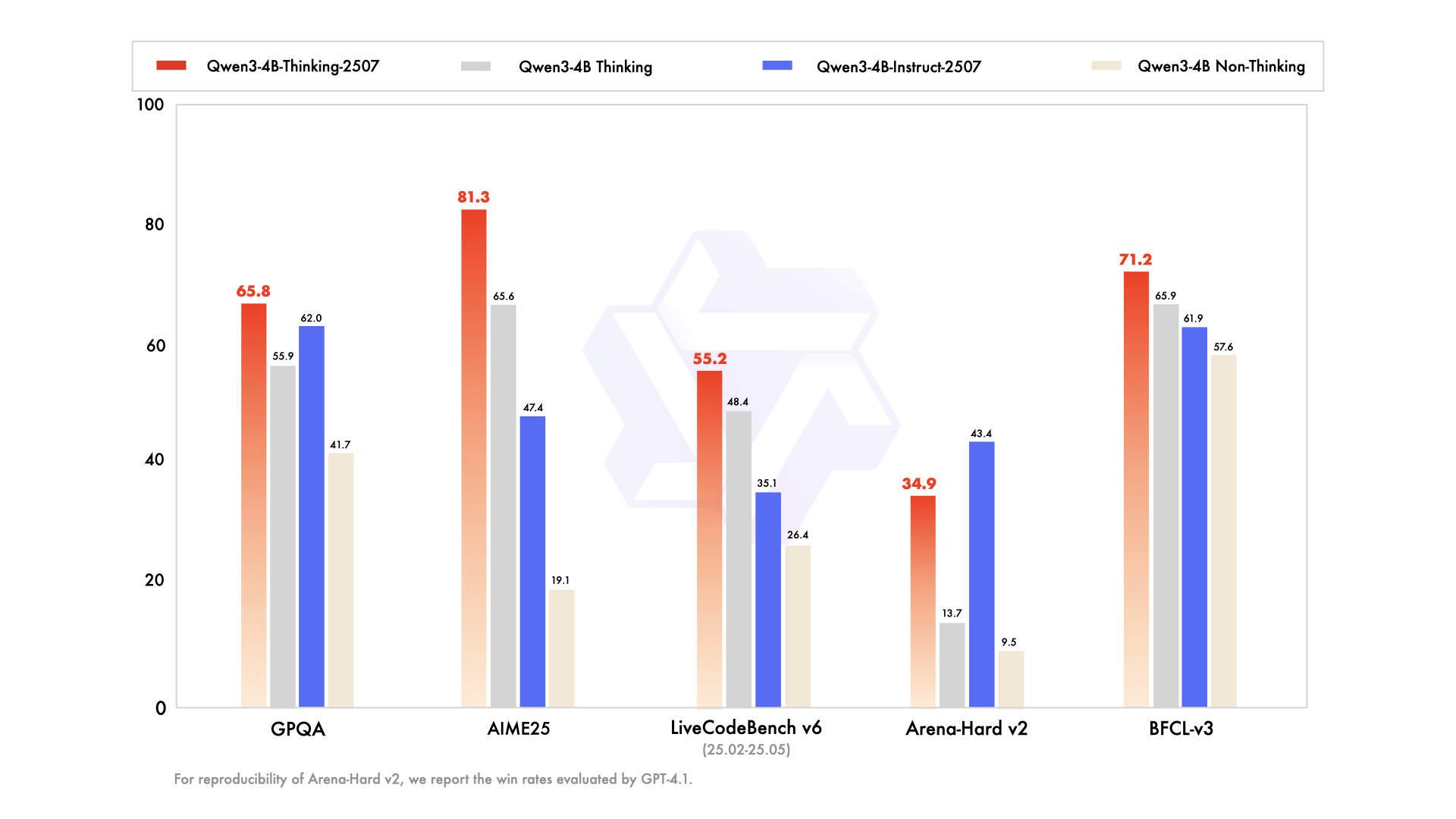
تشمل التحسينات الرئيسية ما يلي:
- قدرات عامة محسّنة: يُظهر النموذج أداءً فائقًا في الرياضيات والعلوم والبرمجة واستخدام الأدوات، مما يجعله متعدد الاستخدامات للتطبيقات التقنية.
- دعم متعدد اللغات: يغطي أكثر من 100 لغة ولهجة، مما يضمن أداءً قويًا في التطبيقات العالمية.
- فهم السياق الطويل: مع طول سياق يبلغ 256 ألف رمز، فإنه يتعامل مع المدخلات الموسعة، مثل المستندات القانونية أو قواعد الأكواد الطويلة، دون اقتطاع.
- التوافق مع تفضيلات المستخدم: يقدم النموذج استجابات أكثر طبيعية وجاذبية، ويتفوق في الكتابة الإبداعية والحوارات متعددة الأدوار.
بالنسبة للمطورين الذين يدمجون هذا النموذج في واجهات برمجة التطبيقات (APIs)، يوفر Apidog واجهة سهلة الاستخدام لاختبار وإدارة نقاط نهاية API، مما يضمن نشرًا سلسًا. هذه الكفاءة تجعل Qwen3-4B-Instruct-2507 خيارًا مفضلاً للتطبيقات التي تتطلب استجابات سريعة ودقيقة.
Qwen3-4B-Thinking-2507: مصمم للاستدلال العميق
على النقيض من ذلك، تم تصميم Qwen3-4B-Thinking-2507 للمهام التي تتطلب استدلالًا مكثفًا، مثل حل المشكلات المنطقية، والرياضيات، والمعايير الأكاديمية. يعمل هذا النموذج حصريًا في وضع "التفكير" (thinking mode)، حيث يدمج تلقائيًا عمليات "سلسلة الأفكار" (CoT) لتفكيك المشكلات المعقدة. قد يتضمن إخراجه علامة إغلاق </think> بدون علامة فتح <think>، حيث أن قالب الدردشة الافتراضي يدمج سلوك التفكير.
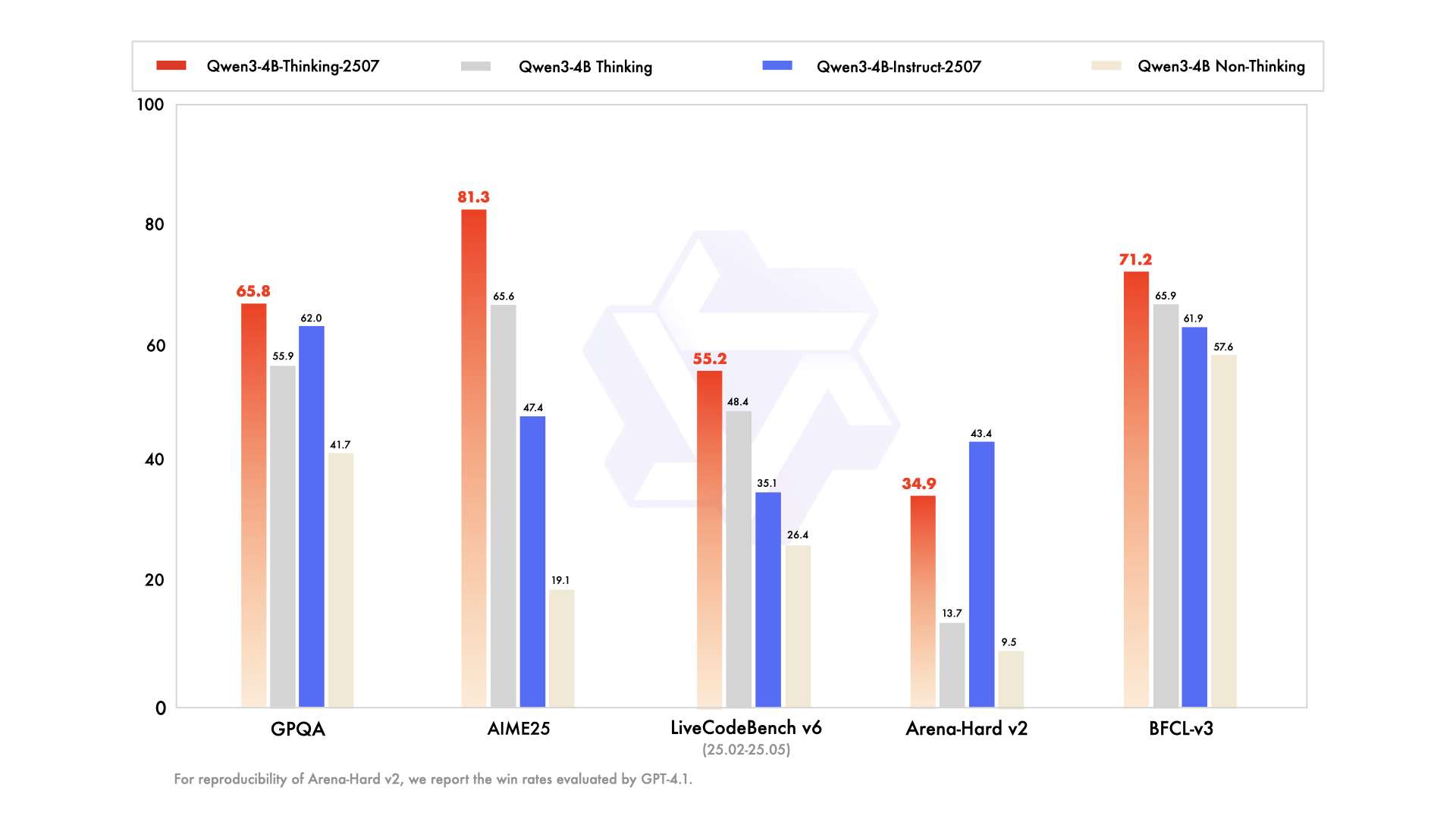
تشمل التحسينات الرئيسية ما يلي:
- قدرات استدلال متقدمة: يحقق النموذج نتائج رائدة بين نماذج التفكير مفتوحة المصدر، خاصة في مجالات العلوم والتكنولوجيا والهندسة والرياضيات (STEM) والبرمجة.
- عمق تفكير متزايد: يتفوق في المهام التي تتطلب استدلالًا بمستوى الخبراء البشريين، مع طول تفكير ممتد للتحليل الشامل.
- طول سياق 256 ألف رمز: مثل نظيره Instruct، يدعم نوافذ سياق ضخمة، وهو مثالي لمعالجة مجموعات البيانات الكبيرة أو الاستعلامات المعقدة.
- تكامل الأدوات: يستفيد النموذج من أدوات مثل Qwen-Agent لسير عمل وكيل مبسط، مما يعزز فائدته في الأنظمة الآلية.
بالنسبة للمطورين الذين يعملون مع تطبيقات مكثفة الاستدلال، يمكن لـ Apidog تسهيل اختبار واجهة برمجة التطبيقات (API)، مما يضمن توافق مخرجات النموذج مع النتائج المتوقعة. هذا النموذج مناسب بشكل خاص لبيئات البحث وسيناريوهات حل المشكلات المعقدة.
المواصفات التقنية والهندسة المعمارية
يُعدّ كلا النموذجين Qwen3-4B جزءًا من عائلة Qwen3، التي تتضمن هياكل كثيفة وهياكل "مزيج الخبراء" (MoE). يشير التعيين "4B" إلى معالمه البالغة 4 مليارات، مما يحقق توازنًا بين الكفاءة الحسابية والأداء. وبالتالي، يمكن الوصول إلى هذه النماذج على الأجهزة الاستهلاكية، على عكس النماذج الأكبر مثل Qwen3-235B-A22B، التي تتطلب موارد كبيرة.
أبرز ملامح الهندسة المعمارية
- تصميم النموذج الكثيف: على عكس نماذج MoE، تستخدم نماذج Qwen3-4B بنية كثيفة، مما يضمن أداءً ثابتًا عبر المهام دون الحاجة إلى تنشيط معلمات انتقائية.
- YaRN لتوسيع السياق: تستفيد النماذج من YaRN لتوسيع طول سياقها من 32,768 إلى 262,144 رمزًا، مما يتيح معالجة السياق الطويل دون تدهور كبير في الأداء.
- مسار التدريب: استخدم فريق Qwen عملية تدريب من أربع مراحل، بما في ذلك البدء البارد لسلسلة الأفكار الطويلة، والتعلم المعزز القائم على الاستدلال، ودمج وضع التفكير، والتعلم المعزز العام. يعزز هذا النهج قدرات الاستدلال والحوار على حد سواء.
- دعم التكميم: يدعم كلا النموذجين تكميم FP8، مما يقلل متطلبات الذاكرة مع الحفاظ على الدقة. على سبيل المثال، يتوفر Qwen3-4B-Thinking-2507-FP8 للبيئات محدودة الموارد.
متطلبات الأجهزة
لتشغيل هذه النماذج بكفاءة، ضع في اعتبارك ما يلي:
- ذاكرة وحدة معالجة الرسومات (GPU Memory): يوصى بحد أدنى 8 جيجابايت من ذاكرة الوصول العشوائي للفيديو (VRAM) للنماذج المكممة بـ FP8، بينما قد تتطلب نماذج bfloat16 16 جيجابايت أو أكثر.
- ذاكرة الوصول العشوائي (RAM): للحصول على الأداء الأمثل، 16 جيجابايت من الذاكرة الموحدة (VRAM + RAM) كافية لمعظم المهام.
- أطر عمل الاستدلال (Inference Frameworks): كلا النموذجين متوافقان مع Hugging Face Transformers (الإصدار ≥4.51.0)، وvLLM (≥0.8.5)، وSGLang (≥0.4.6.post1). تدعم الأدوات المحلية مثل Ollama وLMStudio أيضًا Qwen3.
بالنسبة للمطورين الذين ينشرون هذه النماذج، يبسط Apidog العملية من خلال توفير أدوات لمراقبة واختبار أداء واجهة برمجة التطبيقات (API)، مما يضمن التكامل الفعال مع أطر عمل الاستدلال.
التكامل مع Hugging Face و ModelScope
تتوفر نماذج Qwen3-4B على كل من Hugging Face و ModelScope، مما يوفر مرونة للمطورين. فيما يلي، نقدم مقتطفًا برمجيًا لتوضيح كيفية استخدام Qwen3-4B-Instruct-2507 مع Hugging Face Transformers.

from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Instruct-2507"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Write a Python function to calculate Fibonacci numbers."messages = [{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=16384)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()content = tokenizer.decode(output_ids, skip_special_tokens=True)print("Generated Code:\n", content)بالنسبة لـ Qwen3-4B-Thinking-2507، يلزم تحليل إضافي للتعامل مع محتوى التفكير:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Thinking-2507"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Solve the equation 2x^2 + 3x - 5 = 0."messages = [{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
try:index = len(output_ids) - output_ids[::-1].index(151668) # tokenexcept ValueError:index = 0thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")print("Thinking Process:\n", thinking_content)print("Solution:\n", content)توضح هذه المقتطفات سهولة دمج نماذج Qwen في سير عمل بايثون. بالنسبة لعمليات النشر القائمة على واجهة برمجة التطبيقات (API)، يمكن لـ Apidog المساعدة في اختبار نقاط النهاية هذه، مما يضمن أداءً موثوقًا به.
تحسين الأداء وأفضل الممارسات
لتحقيق أقصى قدر من أداء نماذج Qwen3-4B، ضع في اعتبارك التوصيات التالية:
- معلمات أخذ العينات (Sampling Parameters): بالنسبة لـ Qwen3-4B-Instruct-2507، استخدم
temperature=0.7،top_p=0.8،top_k=20، وmin_p=0. بالنسبة لـ Qwen3-4B-Thinking-2507، استخدمtemperature=0.6،top_p=0.95،top_k=20، وmin_p=0. تجنب فك التشفير الجشع لمنع تدهور الأداء. - إدارة طول السياق: إذا واجهت مشكلات نفاد الذاكرة، قلل طول السياق إلى 32,768 رمزًا. ومع ذلك، لمهام الاستدلال، حافظ على طول سياق يزيد عن 131,072 رمزًا.
- عقوبة الوجود (Presence Penalty): اضبط
presence_penaltyبين 0 و 2 لتقليل التكرار، ولكن تجنب القيم العالية لمنع اختلاط اللغات. - أطر عمل الاستدلال (Inference Frameworks): استخدم vLLM أو SGLang للاستدلال عالي الإنتاجية، واستفد من Apidog لمراقبة أداء واجهة برمجة التطبيقات (API).
مقارنة Qwen3-4B-Instruct-2507 و Qwen3-4B-Thinking-2507
بينما يتشارك النموذجان نفس بنية المعلمات البالغة 4 مليارات، تختلف فلسفات تصميمهما:
- Qwen3-4B-Instruct-2507: يركز على السرعة والكفاءة، مما يجعله مناسبًا لروبوتات الدردشة، ودعم العملاء، والتطبيقات العامة.
- Qwen3-4B-Thinking-2507: يركز على الاستدلال العميق، وهو مثالي للبحث الأكاديمي، وحل المشكلات المعقدة، والمهام التي تتطلب عمليات سلسلة الأفكار.
يمكن للمطورين التبديل بين الأوضاع باستخدام أوامر /think و /no_think، مما يتيح المرونة بناءً على متطلبات المهمة. يمكن لـ Apidog المساعدة في اختبار تبديل الأوضاع هذه في التطبيقات القائمة على واجهة برمجة التطبيقات (API).
دعم المجتمع والنظام البيئي
تستفيد نماذج Qwen3-4B من نظام بيئي قوي، بدعم من Hugging Face و ModelScope، وأدوات مثل Ollama و LMStudio و llama.cpp. تشجع طبيعة هذه النماذج مفتوحة المصدر، المرخصة بموجب Apache 2.0، مساهمات المجتمع والضبط الدقيق. على سبيل المثال، يوفر Unsloth أدوات لضبط دقيق أسرع بمرتين مع ذاكرة وصول عشوائي للفيديو (VRAM) أقل بنسبة 70%، مما يجعل هذه النماذج متاحة لجمهور أوسع.
الخاتمة
تمثل نماذج Qwen3-4B-Instruct-2507 و Qwen3-4B-Thinking-2507 قفزة كبيرة في سلسلة Qwen من Alibaba Cloud، حيث تقدم قدرات لا مثيل لها في اتباع التعليمات، والاستدلال، ومعالجة السياقات الطويلة. مع طول سياق يبلغ 256 ألف رمز، ودعم متعدد اللغات، والتوافق مع أدوات مثل Apidog، تمكّن هذه النماذج المطورين من بناء تطبيقات ذكية وقابلة للتطوير. سواء كنت تقوم بإنشاء تعليمات برمجية، أو حل معادلات، أو إنشاء روبوتات دردشة متعددة اللغات، فإن هذه النماذج تقدم أداءً استثنائيًا. ابدأ في استكشاف إمكاناتها اليوم، واستخدم Apidog لتبسيط عمليات دمج واجهة برمجة التطبيقات (API) الخاصة بك لتجربة تطوير سلسة.
زر