
اليوم هو يوم عظيم آخر لمجتمع الذكاء الاصطناعي مفتوح المصدر، الذي يزدهر بشكل خاص في هذه اللحظات، حيث يقوم بتفكيك واختبار والبناء على أحدث التقنيات بشغف. في يوليو 2025، أطلق فريق Qwen من Alibaba حدثًا من هذا النوع بإطلاق سلسلة Qwen3، وهي عائلة جديدة قوية من النماذج التي تستعد لإعادة تعريف معايير الأداء. في صميم هذا الإصدار يكمن متغير رائع وعالي التخصص: Qwen3-235B-A22B-Thinking-2507.
هذا النموذج ليس مجرد تحديث تدريجي آخر؛ إنه يمثل خطوة مدروسة واستراتيجية نحو إنشاء أنظمة ذكاء اصطناعي ذات قدرات استدلال عميقة. اسمه وحده إعلان عن النوايا، يشير إلى التركيز على المنطق والتخطيط وحل المشكلات متعدد الخطوات. يقدم هذا المقال غوصًا عميقًا في بنية Qwen3-Thinking وهدفه وتأثيره المحتمل، ويفحص مكانه ضمن النظام البيئي الأوسع لـ Qwen3 وما يعنيه لمستقبل تطوير الذكاء الاصطناعي.
هل تريد منصة متكاملة وشاملة لفريق المطورين لديك للعمل معًا بأقصى إنتاجية؟
Apidog يلبي جميع متطلباتك، ويحل محل Postman بسعر أقل بكثير!
زر
عائلة Qwen3: هجوم متعدد الأوجه على أحدث التقنيات
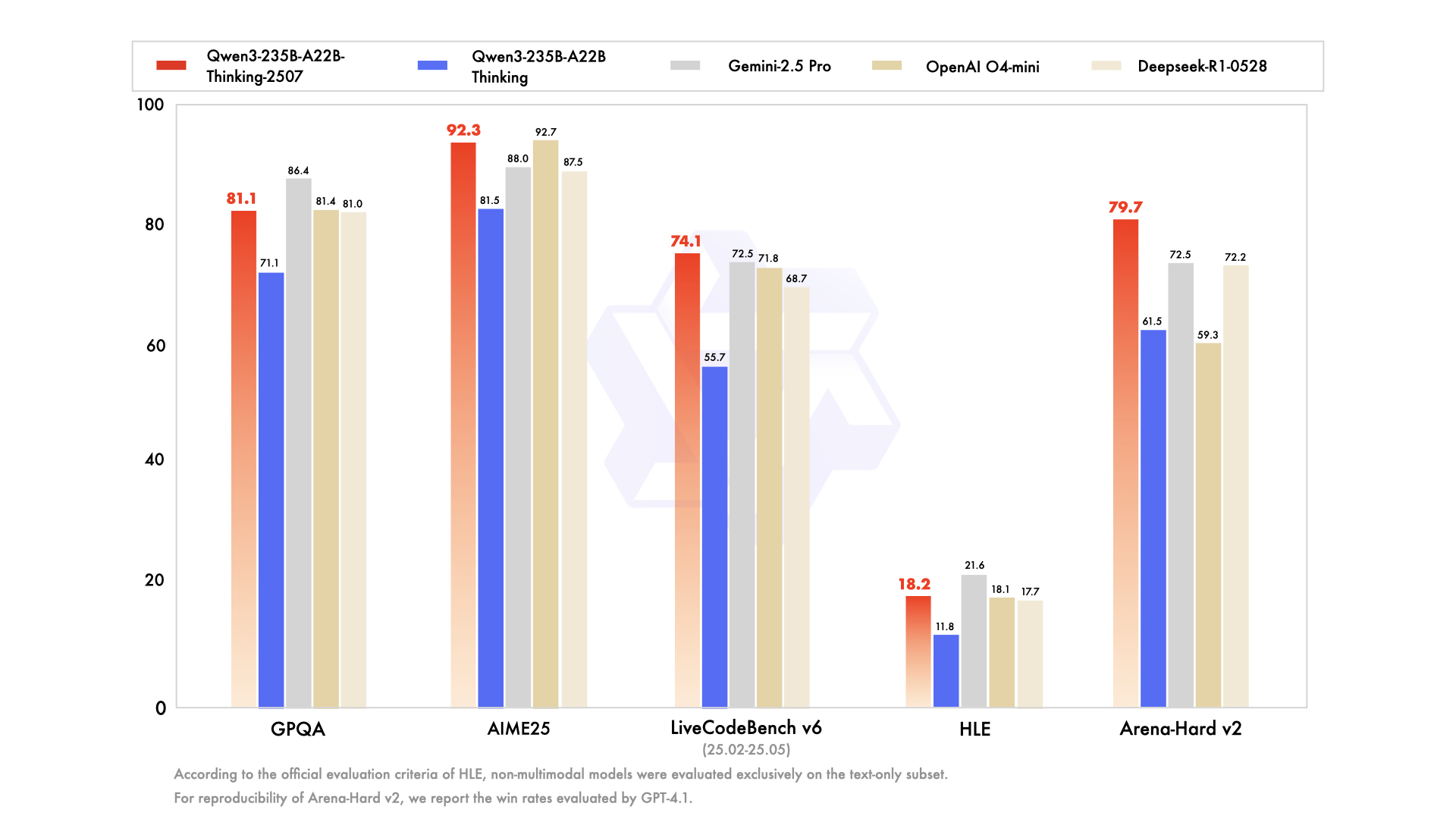
لفهم نموذج Thinking، يجب أولاً تقدير سياق ولادته. لم يأتِ بمعزل عن غيره، بل كجزء من عائلة نماذج Qwen3 الشاملة والمتنوعة استراتيجيًا. لقد حظيت سلسلة Qwen بالفعل بمتابعة جماهيرية ضخمة، مع تاريخ من التنزيلات التي بلغت مئات الملايين، وعززت مجتمعًا نابضًا بالحياة أنشأ أكثر من 100,000 نموذج مشتق على منصات مثل Hugging Face.
تتضمن سلسلة Qwen3 عدة متغيرات رئيسية، كل منها مصمم خصيصًا لمجالات مختلفة:
- Qwen3-Instruct: نموذج متعدد الأغراض لاتباع التعليمات، مصمم لمجموعة واسعة من التطبيقات الحوارية والموجهة للمهام. يُعرف متغير
Qwen3-235B-A22B-Instruct-2507، على سبيل المثال، بمواءمته المحسنة مع تفضيلات المستخدم في المهام المفتوحة وتغطيته المعرفية الواسعة. - Qwen3-Coder: سلسلة من النماذج المصممة خصيصًا للبرمجة الوكيلية (agentic coding). أقواها، وهو نموذج ضخم بـ 480 مليار معلمة، يضع معيارًا جديدًا لتوليد الشفرة مفتوحة المصدر وأتمتة تطوير البرمجيات. يأتي حتى مع أداة سطر أوامر، Qwen Code، لتسخير قدراته الوكيلية بشكل أفضل.
- Qwen3-Thinking: محور تحليلنا، متخصص في المهام المعرفية المعقدة التي تتجاوز مجرد اتباع التعليمات أو توليد الشفرة.
يوضح هذا النهج العائلي استراتيجية متطورة: فبدلاً من نموذج واحد متكامل يحاول أن يكون متعدد الاستخدامات، توفر Alibaba مجموعة من الأدوات المتخصصة، مما يتيح للمطورين اختيار الأساس الصحيح لاحتياجاتهم الخاصة.
لنتحدث عن جزء "التفكير" في Qwen3-235B-A22B-Thinking-2507
اسم النموذج، Qwen3-235B-A22B-Thinking-2507، مليء بالمعلومات التي تكشف عن بنيته الأساسية وفلسفة تصميمه. دعونا نفككه جزءًا تلو الآخر.
Qwen3: يشير هذا إلى أن النموذج ينتمي إلى الجيل الثالث من سلسلة Qwen، مبنيًا على المعرفة والتقدم الذي أحرزته النماذج السابقة.235B-A22B(مزيج الخبراء - MoE): هذه هي التفاصيل المعمارية الأكثر أهمية. النموذج ليس شبكة كثيفة بـ 235 مليار معلمة، حيث يتم استخدام كل معلمة لكل عملية حسابية. بدلاً من ذلك، يستخدم بنية مزيج الخبراء (MoE).Thinking: يشير هذا اللاحقة إلى تخصص النموذج، الذي تم ضبطه بدقة على بيانات تكافئ الاستنتاج المنطقي والتحليل خطوة بخطوة.2507: هذا هو وسم إصدار، من المرجح أنه يرمز إلى يوليو 2025، مشيرًا إلى تاريخ إصدار النموذج أو اكتمال تدريبه.
تعد بنية MoE مفتاح الجمع بين القوة والكفاءة في هذا النموذج. يمكن اعتبارها فريقًا كبيرًا من "الخبراء" المتخصصين — شبكات عصبية أصغر — تدار بواسطة "شبكة تحكم" أو "موجه". لأي رمز إدخال معين، يختار الموجه ديناميكيًا مجموعة فرعية صغيرة من الخبراء الأكثر صلة لمعالجة المعلومات.
في حالة Qwen3-235B-A22B، التفاصيل هي:
- إجمالي المعلمات (
235B): يمثل هذا المستودع الهائل للمعرفة الموزعة عبر جميع الخبراء المتاحين. يحتوي النموذج على إجمالي 128 خبيرًا متميزًا. - المعلمات النشطة (
A22B): لأي تمريرة استدلال واحدة، تختار شبكة التحكم 8 خبراء لتنشيطهم. الحجم المجمع لهؤلاء الخبراء النشطين يبلغ حوالي 22 مليار معلمة.
فوائد هذا النهج هائلة. فهو يسمح للنموذج بامتلاك المعرفة الواسعة والدقيقة والقدرات التي يتمتع بها نموذج بـ 235 مليار معلمة، مع تكلفة حسابية وسرعة استدلال أقرب إلى نموذج كثيف أصغر بكثير بـ 22 مليار معلمة. هذا يجعل نشر وتشغيل مثل هذا النموذج الكبير أكثر جدوى دون التضحية بعمق معرفته.
المواصفات الفنية وملف الأداء
بعيدًا عن البنية عالية المستوى، ترسم المواصفات التفصيلية للنموذج صورة أوضح لقدراته.
- بنية النموذج: مزيج الخبراء (MoE)
- إجمالي المعلمات: ~235 مليار
- المعلمات النشطة: ~22 مليار لكل رمز (token)
- عدد الخبراء: 128
- الخبراء المنشطون لكل رمز: 8
- طول السياق: يدعم النموذج نافذة سياق بحجم 128,000 رمز. هذا تحسن هائل يسمح له بمعالجة النصوص الطويلة جدًا، قواعد الأكواد الكاملة، أو سجلات المحادثات الطويلة والاستدلال عليها دون فقدان المعلومات الهامة من بداية الإدخال.
- أداة الترميز (Tokenizer): يستخدم أداة ترميز مخصصة لترميز أزواج البايت (BPE) مع مفردات تزيد عن 150,000 رمز. يشير حجم المفردات الكبير هذا إلى تدريبه القوي متعدد اللغات، مما يسمح له بترميز النصوص بكفاءة من مجموعة واسعة من اللغات، بما في ذلك الإنجليزية والصينية والألمانية والإسبانية والعديد من اللغات الأخرى، بالإضافة إلى لغات البرمجة.
- بيانات التدريب: بينما التركيب الدقيق لمجموعة بيانات التدريب خاص بالشركة، فمن المؤكد أن نموذج
Thinkingقد تم تدريبه على مزيج متخصص من البيانات المصممة لتعزيز الاستدلال. ستتجاوز مجموعة البيانات هذه النصوص القياسية على الويب وستشمل على الأرجح: - الأوراق الأكاديمية والعلمية: كميات كبيرة من النصوص من مصادر مثل arXiv وPubMed ومستودعات الأبحاث الأخرى لاستيعاب الاستدلال العلمي والرياضي المعقد.
- مجموعات البيانات المنطقية والرياضية: مجموعات بيانات مثل GSM8K (رياضيات الصف الدراسي) ومجموعة بيانات MATH، التي تحتوي على مسائل كلامية تتطلب حلولاً خطوة بخطوة.
- مشاكل البرمجة والأكواد: مجموعات بيانات مثل HumanEval وMBPP، التي تختبر الاستدلال المنطقي من خلال توليد الأكواد.
- النصوص الفلسفية والقانونية: وثائق تتطلب فهم حجج منطقية كثيفة ومجردة ومنظمة للغاية.
- بيانات سلسلة التفكير (CoT): أمثلة تم إنشاؤها اصطناعيًا أو تم تنظيمها بواسطة البشر حيث يتم إظهار النموذج صراحة كيفية "التفكير خطوة بخطوة" للوصول إلى إجابة.
هذا المزيج المنسق من البيانات هو ما يميز نموذج Thinking عن نظيره Instruct. فهو لم يتم تدريبه ليكون مفيدًا فحسب؛ بل تم تدريبه ليكون دقيقًا وصارمًا.
قوة "التفكير": تركيز على الإدراك المعقد
تكمن وعد نموذج Qwen3-Thinking في قدرته على معالجة المشكلات التي كانت تاريخياً تمثل تحديات كبيرة لنماذج اللغة الكبيرة. هذه هي المهام التي لا يكفي فيها مطابقة الأنماط البسيطة أو استرجاع المعلومات. يشير تخصص "التفكير" إلى الكفاءة في مجالات مثل:
- الاستدلال متعدد الخطوات: حل المشكلات التي تتطلب تقسيم الاستعلام إلى تسلسل من الخطوات المنطقية. على سبيل المثال، حساب الآثار المالية لقرار عمل بناءً على متغيرات سوق متعددة أو تخطيط مسار قذيفة معينة بناءً على مجموعة من القيود الفيزيائية.
- الاستنتاج المنطقي: تحليل مجموعة من المقدمات واستخلاص نتيجة صحيحة. يمكن أن يشمل ذلك حل لغز شبكة منطقية، أو تحديد المغالطات المنطقية في نص، أو تحديد عواقب مجموعة من القواعد في سياق قانوني أو تعاقدي.
- التخطيط الاستراتيجي: وضع تسلسل من الإجراءات لتحقيق هدف ما. هذا له تطبيقات في الألعاب المعقدة (مثل الشطرنج أو الغو)، ومحاكاة استراتيجيات الأعمال، وتحسين سلسلة التوريد، وإدارة المشاريع الآلية.
- الاستدلال السببي: محاولة تحديد علاقات السبب والنتيجة داخل نظام معقد موصوف في النص، وهو حجر الزاوية في الاستدلال العلمي والتحليلي الذي غالبًا ما تواجهه النماذج صعوبة فيه.
- التفكير المجرد: فهم ومعالجة المفاهيم المجردة والتشبيهات. هذا ضروري لحل المشكلات الإبداعي والذكاء الحقيقي على مستوى الإنسان، حيث يتجاوز الحقائق الملموسة إلى العلاقات بينها.
تم تصميم النموذج للتفوق في المعايير التي تقيس هذه القدرات المعرفية المتقدمة بشكل خاص، مثل MMLU (فهم اللغة متعدد المهام الضخم) للمعرفة العامة وحل المشكلات، ومجموعتي بيانات GSM8K وMATH المذكورتين سابقًا للاستدلال الرياضي.
إمكانية الوصول، التكميم، ومشاركة المجتمع
لا تكون قوة النموذج ذات معنى إلا إذا أمكن الوصول إليه واستخدامه. وفاءً لالتزامها بالمصادر المفتوحة، أتاحت Alibaba عائلة Qwen3، بما في ذلك متغير Thinking، على نطاق واسع على منصات مثل Hugging Face وModelScope.
إدراكًا للموارد الحاسوبية الكبيرة المطلوبة لتشغيل نموذج بهذا الحجم، تتوفر أيضًا إصدارات مكممة. يعد نموذج Qwen3-235B-A22B-Thinking-2507-FP8 مثالاً رئيسيًا. FP8 (النقطة العائمة 8 بت) هي تقنية تكميم متطورة تقلل بشكل كبير من استهلاك الذاكرة للنموذج وتزيد من سرعة الاستدلال.
دعنا نفصل التأثير:
- يتطلب نموذج بـ 235 مليار معلمة بدقة 16 بت قياسية (BF16/FP16) أكثر من 470 جيجابايت من ذاكرة الفيديو (VRAM)، وهو مقدار باهظ لجميع مجموعات خوادم المؤسسات الكبيرة باستثناء الأكبر.
- ومع ذلك، يقلل الإصدار المكمم FP8 هذا المتطلب إلى أقل من 250 جيجابايت. وعلى الرغم من أنه لا يزال كبيرًا، إلا أن هذا يجعل النموذج في نطاق الإمكانية للمؤسسات البحثية، والشركات الناشئة، وحتى الأفراد الذين لديهم محطات عمل متعددة وحدات معالجة الرسومات (GPU) مجهزة بأجهزة استهلاكية أو احترافية عالية الجودة.
هذا يجعل الاستدلال المتقدم متاحًا لجمهور أوسع بكثير. بالنسبة لمستخدمي المؤسسات الذين يفضلون الخدمات المدارة، يتم دمج النماذج أيضًا في منصات Alibaba السحابية. يضمن الوصول إلى واجهة برمجة التطبيقات (API) عبر Model Studio والدمج في مساعد الذكاء الاصطناعي الرائد من Alibaba، Quark، إمكانية الاستفادة من التكنولوجيا بأي حجم.
الخاتمة: أداة جديدة لفئة جديدة من المشكلات
إن إصدار Qwen3-235B-A22B-Thinking-2507 هو أكثر من مجرد نقطة أخرى على الرسم البياني المتصاعد لأداء نماذج الذكاء الاصطناعي. إنه بيان حول الاتجاه المستقبلي لتطوير الذكاء الاصطناعي: تحول من النماذج المتكاملة ذات الأغراض العامة نحو نظام بيئي متنوع من الأدوات القوية والمتخصصة. من خلال توظيف بنية مزيج الخبراء الفعالة، قدمت Alibaba نموذجًا يمتلك المعرفة الهائلة لشبكة بـ 235 مليار معلمة وودية حسابية نسبية لنموذج بـ 22 مليار معلمة.
من خلال الضبط الدقيق لهذا النموذج خصيصًا لـ "التفكير"، يوفر فريق Qwen للعالم أداة مخصصة لحل أصعب التحديات التحليلية والاستدلالية. لديها القدرة على تسريع الاكتشاف العلمي من خلال مساعدة الباحثين على تحليل البيانات المعقدة، وتمكين الشركات من اتخاذ قرارات استراتيجية أفضل، وتكون بمثابة طبقة أساسية لجيل جديد من التطبيقات الذكية التي يمكنها التخطيط والاستنتاج والاستدلال بتطور غير مسبوق. مع بدء مجتمع المصادر المفتوحة في استكشاف أعماقه بالكامل، من المقرر أن يصبح Qwen3-Thinking لبنة بناء حاسمة في السعي المستمر نحو ذكاء اصطناعي أكثر قدرة وذكاءً حقيقيًا.
هل تريد منصة متكاملة وشاملة لفريق المطورين لديك للعمل معًا بأقصى إنتاجية؟
Apidog يلبي جميع متطلباتك، ويحل محل Postman بسعر أقل بكثير!
زر