
فريق Qwen من علي بابا قد تجاوز مرة أخرى حدود الذكاء الاصطناعي بإطلاق نموذج Qwen2.5-VL-32B-Instruct، وهو نموذج مبتكر للرؤية واللغة (VLM) يعد بأن يكون أكثر ذكاءً وأخف وزناً.
تم الإعلان عنه في 24 مارس 2025، يحقق هذا النموذج البالغ 32 مليار معلمة توازناً مثالياً بين الأداء والكفاءة، مما يجعله الخيار المثالي للمطورين والباحثين. بناءً على نجاح سلسلة Qwen2.5-VL، يقدم هذا الإصدار الجديد تحسينات كبيرة في التفكير الرياضي، وتوافق التفضيلات الإنسانية، ومهام الرؤية، كل ذلك بينما يحافظ على حجم مقبول للتنفيذ المحلي.
بالنسبة للمطورين المتحمسين لدمج هذا النموذج القوي في مشاريعهم، فإن استكشاف أدوات واجهة برمجة التطبيقات الروبوتية أمر أساسي. ولهذا السبب نوصي بتنزيل Apidog مجاناً - وهو منصة تطوير واجهة برمجة تطبيقات سهلة الاستخدام تُبسط اختبار ودمج نماذج مثل Qwen في تطبيقاتك. مع Apidog، يمكنك التفاعل بسلاسة مع واجهة برمجة تطبيقات Qwen، تسريع سير العمل، وإطلاق العنان للإمكانات الكاملة لهذا VLM المبتكر. قم بتنزيل Apidog اليوم وابدأ في بناء تطبيقات أكثر ذكاءً!
تتيح لك هذه الأداة API اختبار وتصحيح نقاط الاتصال الخاصة بنموذجك بسهولة. قم بتنزيل Apidog مجاناً اليوم وقم بتحسين سير عملك أثناء استكشاف قدرات Mistral Small 3.1!
Qwen2.5-VL-32B: نموذج رؤية ولغة أكثر ذكاءً
ما الذي يجعل Qwen2.5-VL-32B فريداً؟
يبرز Qwen2.5-VL-32B كنموذج رؤية ولغة مكون من 32 مليار معلمة مصمم للتغلب على قيود النماذج الأكبر والأصغر في عائلة Qwen. بينما تقدم نماذج 72 مليار معلمة مثل Qwen2.5-VL-72B قدرات قوية، إلا أنها غالباً ما تتطلب موارد حوسبة كبيرة، مما يجعلها غير عملية للتنفيذ المحلي. وعلى العكس، قد تفتقر نماذج 7 مليارات معلمة، على الرغم من خفتها، إلى العمق المطلوب للمهام المعقدة. يغطي Qwen2.5-VL-32B هذه الفجوة من خلال تقديم أداء عالي مع بصمة أقل قابلية للإدارة.
يبني هذا النموذج على سلسلة Qwen2.5-VL، التي حققت شهرة واسعة لقدراتها متعددة الوسائط. ومع ذلك، يقدم Qwen2.5-VL-32B تحسينات حاسمة، بما في ذلك التحسين من خلال التعلم المعزز (RL). يحسن هذا النهج توافق النموذج مع تفضيلات البشر، مما يضمن مخرجات أكثر تفصيلاً وسهولة في الاستخدام. بالإضافة إلى ذلك، يظهر النموذج تحسينات في التفكير الرياضي، وهي ميزة حيوية للمهام التي تشمل حل المشكلات المعقدة وتحليل البيانات.

التحسينات الفنية الرئيسية
يستفيد Qwen2.5-VL-32B من التعلم المعزز لتحسين نمط إخراجه، مما يجعل الردود أكثر اتساقاً وتفصيلاً وتنسيقاً لتحسين التفاعل مع البشر. علاوة على ذلك، شهدت قدرات النموذج في التفكير الرياضي تحسينات كبيرة، كما يتضح من أدائه في الاختبارات مثل MathVista و MMMU. تنبع هذه التحسينات من عمليات التدريب الدقيقة التي تعطي الأولوية للدقة والاستدلال المنطقي، خاصة في السياقات متعددة الوسائط حيث يتداخل النص والبيانات المرئية.
يتفوق النموذج أيضًا في فهم الصور بشكل دقيق والتفكير، مما يمكّنه من التحليل الدقيق للمحتوى المرئي، مثل الرسوم البيانية والمخططات والمستندات. تضع هذه الإمكانية Qwen2.5-VL-32B كمرشح قوي للتطبيقات التي تتطلب استدلال منطق مرئي متقدم والتعرف على المحتوى.
معايير أداء Qwen2.5-VL-32B: التفوق على النماذج الأكبر
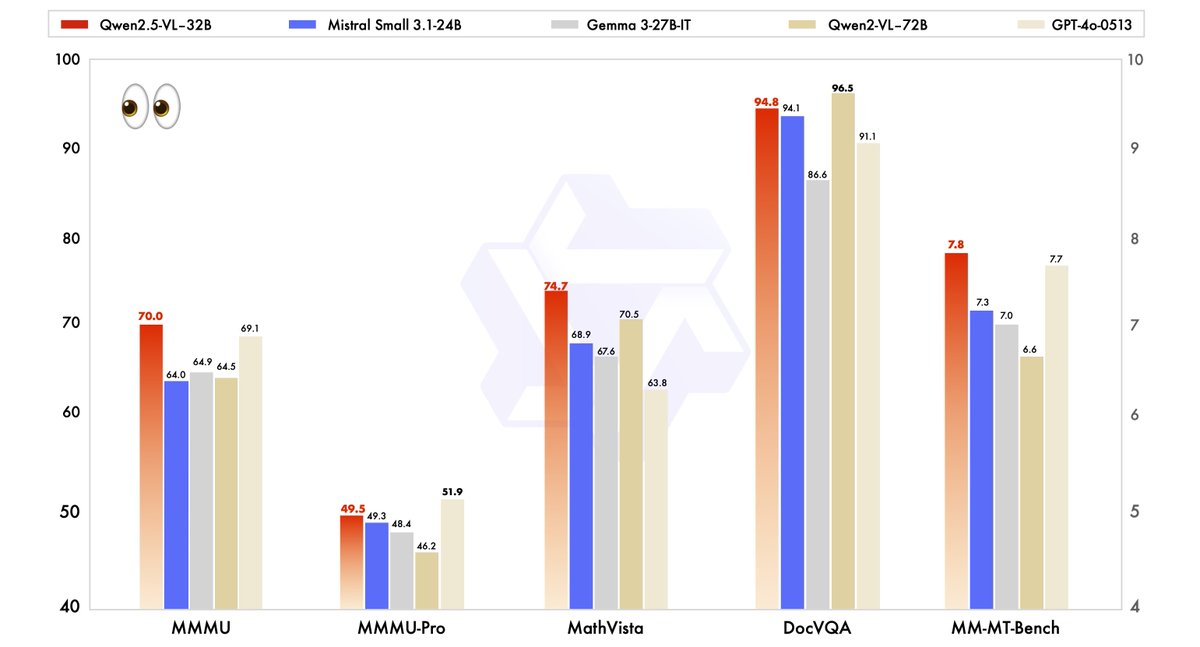
تم تقييم أداء Qwen2.5-VL-32B بدقة مقارنة بالنماذج الحديثة، بما في ذلك شقيقه الأكبر Qwen2.5-VL-72B، فضلاً عن المنافسين مثل Mistral-Small-3.1–24B و Gemma-3–27B-IT. تسلط النتائج الضوء على تفوق النموذج في عدة مجالات رئيسية.
- MMMU (فهم اللغة متعددة المهام): حقق Qwen2.5-VL-32B درجة 70.0، متجاوزاً Qwen2.5-VL-72B الذي حصل على 64.5. تختبر هذه المعايير التفكير المعقد المتعدد الخطوات عبر مهام متنوعة، مما يبرز القدرات المعرفية المحسنة للنموذج.
- MathVista: مع درجة 74.7، يتفوق Qwen2.5-VL-32B على Qwen2.5-VL-72B الذي حصل على 70.5، مما يبرز قوته في مهام التفكير الرياضي والمرئي.
- MM-MT-Bench: تظهر هذه المعايير الخاصة بتجربة المستخدم Qwen2.5-VL-32B تتفوق بوضوح على سابقتها، مما يعكس تحسين توافق التفضيلات البشرية.
- المهام المعتمدة على النص (مثل: MMLU، MATH، HumanEval): ينافس النموذج بشكل فعال مع النماذج الأكبر مثل GPT-4o-Mini، محققاً درجات 78.4 في MMLU، و82.2 في MATH، و91.5 في HumanEval، على الرغم من عدد معالمه الأصغر.
تظهر هذه المعايير أن Qwen2.5-VL-32B لا يتجاوز فقط أداء النماذج الأكبر، بل غالباً ما يتفوق عليها، كل ذلك مع متطلبات أقل من الموارد الحوسبية. تجعل هذه الموازنة بين القوة والكفاءة خياراً جذاباً للمطورين والباحثين الذين يعملون مع أجهزة حاسوبية محدودة.
لماذا الحجم مهم: ميزة 32B
يحقق حجم Qwen2.5-VL-32B البالغ 32 مليار معلمة نقطة توازن مثالية للتنفيذ المحلي. على العكس من نماذج 72B، التي تتطلب موارد GPU واسعة، يدمج هذا النموذج الأخف وزناً بسلاسة مع محركات الاستنتاج مثل SGLang و vLLM، كما لوحظ في نتائج الويب ذات الصلة. تضمن هذه التوافقات نشرًا أسرع واستخدامًا أقل للذاكرة، مما يجعلها متاحة لشريحة أوسع من المستخدمين، من الشركات الناشئة إلى المؤسسات الكبيرة.
علاوة على ذلك، فإن تحسين النموذج من حيث السرعة والكفاءة لا يضر بقدراته. تبقى قدرته على التعامل مع المهام متعددة الوسائط - مثل التعرف على الكائنات، وتحليل المخططات، ومعالجة المخرجات المنظمة مثل الفواتير والجداول - قوية، مما يضعه كأداة متعددة الاستخدامات للتطبيقات الواقعية.

تشغيل Qwen2.5-VL-32B محلياً باستخدام MLX
لتشغيل هذا النموذج القوي محليًا على جهاز ماك الخاص بك مع شريحة Apple Silicon، اتبع هذه الخطوات:
متطلبات النظام
- جهاز ماك مع شريحة Apple Silicon (M1 أو M2 أو M3)
- 32 جيجابايت على الأقل من الذاكرة العشوائية (64 جيجابايت موصى بها)
- 60 جيجابايت أو أكثر من مساحة التخزين الحرة
- macOS Sonoma أو إصدار أحدث
خطوات التثبيت
- تثبيت الاعتماديات الخاصة بـ Python
pip install mlx mlx-llm transformers pillow
- تحميل النموذج
git lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct
- تحويل النموذج إلى تنسيق MLX
python -m mlx_llm.convert --model-name Qwen/Qwen2.5-VL-32B-Instruct --mlx-path ./qwen2.5-vl-32b-mlx
- إنشاء سكربت بسيط للتفاعل مع النموذج
import mlx.core as mx
from mlx_llm import load, generate
from PIL import Image
# تحميل النموذج
model, tokenizer = load("./qwen2.5-vl-32b-mlx")
# تحميل صورة
image = Image.open("path/to/your/image.jpg")
# إنشاء موجه مع الصورة
prompt = "ماذا ترى في هذه الصورة؟"
outputs = generate(model, tokenizer, prompt=prompt, image=image, max_tokens=512)
print(outputs)
التطبيقات العملية: الاستفادة من Qwen2.5-VL-32B
مهام الرؤية وما بعدها
تفتح القدرات البصرية المتقدمة لـ Qwen2.5-VL-32B أبوابًا لمجموعة واسعة من التطبيقات. على سبيل المثال، يمكن أن يعمل كعميل بصري، يتفاعل ديناميكياً مع واجهات الكمبيوتر أو الهاتف لأداء مهام مثل التنقل أو استخراج البيانات. تعزز قدرته على فهم الفيديوهات الطويلة (حتى ساعة واحدة) وتحديد الأجزاء ذات الصلة من فائدته في تحليل الفيديو والتحديد الزمني.
في تحليل المستندات، يتفوق النموذج في معالجة المحتوى متعدد المشاهد ومتعدد اللغات، بما في ذلك النصوص المكتوبة بخط اليد، والجداول، والرسوم البيانية، والصيغ الكيميائية. مما يجعله ذو قيمة عالية للصناعات مثل المالية والتعليم والرعاية الصحية، حيث يكون الاستخراج الدقيق للبيانات المنظمة أمرًا حيويًا.
الاستدلال النصي والرياضي
بجانب مهام الرؤية، يبرز Qwen2.5-VL-32B في التطبيقات المعتمدة على النص، خصوصاً تلك التي تشمل الاستدلال الرياضي والترميز. درجاته العالية في المعايير مثل MATH وHumanEval تدل على كفاءته في حل المسائل الجبرية المعقدة، وتفسير الرسوم البيانية للدوال، وإنشاء مقاطع شفرة دقيقة. يؤدي هذا التأهل المزدوج في الرؤية والنص إلى وضع Qwen2.5-VL-32B كحل شامل لتحديات الذكاء الاصطناعي متعددة الوسائط.

أين يمكنك استخدام Qwen2.5-VL-32B
المصدر المفتوح والوصول إلى واجهة برمجة التطبيقات
يتوفر Qwen2.5-VL-32B بموجب ترخيص Apache 2.0، مما يجعله مصدراً مفتوحاً ومتاحة للمطورين في جميع أنحاء العالم. يمكنك الوصول إلى النموذج من خلال عدة منصات:
- Hugging Face: يستضيف النموذج على Hugging Face، حيث يمكنك تنزيله للاستخدام المحلي أو دمجه عبر مكتبة Transformers.
- ModelScope: توفر منصة ModelScope التابعة لعلي بابا طريقًا آخر للوصول إلى النموذج ونشره.
لتسهيل الاندماج، يمكن للمطورين استخدام واجهة برمجة تطبيقات Qwen، التي تبسط التفاعل مع النموذج. سواء كنت تبني تطبيقًا مخصصًا أو تجرب مهام متعددة الوسائط، تضمن واجهة برمجة التطبيقات Qwen اتصالاً فعالاً وأداءً قوياً.
النشر مع محركات الاستدلال
يدعم Qwen2.5-VL-32B النشر مع محركات الاستدلال مثل SGLang و vLLM. تعمل هذه الأدوات على تحسين النموذج لسرعة الاستدلال، مما يقلل من التأخير والذاكرة المستخدمة. من خلال الاستفادة من هذه المحركات، يمكن للمطورين نشر النموذج على الأجهزة المحلية أو منصات السحابة، وتخصيصها لحالات الاستخدام المحددة.
للبدأ، قم بتثبيت المكتبات المطلوبة (مثل transformers، vllm) واتبع التعليمات على صفحة GitHub الخاصة بـ Qwen أو وثائق Hugging Face. تضمن هذه العملية تكاملًا سلسًا، مما يسمح لك بالاستفادة من الإمكانات الكاملة للنموذج.
تحسين الأداء المحلي
عند تشغيل Qwen2.5-VL-32B محليًا، ضع في اعتبارك نصائح التحسين هذه:
- التكميم: أضف العلامة
--quantizeأثناء التحويل لتقليل متطلبات الذاكرة - إدارة طول السياق: حدد رموز الإدخال للحصول على ردود أسرع
- إغلاق التطبيقات الثقيلة على الموارد عند تشغيل النموذج
- المعالجة الجماعية: للعديد من الصور، عالجها في مجموعات بدلاً من معالجتها فرديًا
الخاتمة: لماذا يعتبر Qwen2.5-VL-32B مهماً
يمثل Qwen2.5-VL-32B مرحلة مهمة في تطور نماذج الرؤية واللغة. من خلال الجمع بين التفكير الأكثر ذكاءً، ومتطلبات الموارد الأخف، والأداء القوي، يلبي هذا النموذج الذي يتكون من 32 مليار معلمة احتياجات المطورين والباحثين على حد سواء. تموضعه كمنافس رئيسي في التفكير الرياضي، توافق التفضيلات البشرية، ومهام الرؤية تجعله الخيار الأفضل للنشر المحلي والتطبيقات الواقعية.
سواء كنت تبني أدوات تعليمية، أنظمة ذكاء أعمال، أو حلول دعم العملاء، يوفر Qwen2.5-VL-32B التنوع والكفاءة التي تحتاجها. مع الوصول من خلال المنصات مفتوحة المصدر وواجهة برمجة التطبيقات Qwen، أصبح دمج هذا النموذج في مشاريعك أسهل من أي وقت مضى. مع استمرار فريق Qwen في الابتكار، يمكننا توقع المزيد من التطورات المثيرة في مستقبل الذكاء الاصطناعي متعدد الوسائط.
تتيح لك هذه الأداة API اختبار وتصحيح نقاط الاتصال الخاصة بنموذجك بسهولة. قم بتنزيل Apidog مجاناً اليوم وقم بتحسين سير عملك أثناء استكشاف قدرات Mistral Small 3.1!