
Qwen، مبادرة النموذج التأسيسي المفتوح من Alibaba، تدفع باستمرار حدود الذكاء الاصطناعي من خلال التكرارات والإصدارات السريعة. يتطلع المطورون والباحثون بشغف إلى كل تحديث، حيث غالبًا ما تضع نماذج Qwen معايير جديدة في الأداء والتنوع. مؤخرًا، أطلقت Qwen ثلاثة نماذج مبتكرة: Qwen-Image-Edit-2509، و Qwen3-TTS-Flash، و Qwen3-Omni. تعزز هذه الإصدارات القدرات في تحرير الصور، وتوليف الكلام من النص، والمعالجة الشاملة للوسائط المتعددة، على التوالي.
علاوة على ذلك، تأتي هذه النماذج في لحظة محورية في تطوير الذكاء الاصطناعي، حيث يصبح التكامل متعدد الوسائط ضروريًا للتطبيقات العملية. يلبي Qwen-Image-Edit-2509 الطلب على التعديلات المرئية الدقيقة، بينما يعالج Qwen3-TTS-Flash مشكلات زمن الاستجابة في توليد الصوت. في الوقت نفسه، يوحد تقديم Qwen3-Omni المدخلات المتنوعة في إطار عمل متماسك. معًا، يظهرون التزام Qwen بالذكاء الاصطناعي عالي الأداء وسهل الوصول إليه. ومع ذلك، يتطلب فهم أسسها التقنية فحصًا دقيقًا. تحلل هذه المقالة كل نموذج، مسلطة الضوء على الميزات، والهندسة المعمارية، والمعايير، والتأثيرات المحتملة.
Qwen-Image-Edit-2509: رفع دقة تحرير الصور
يمثل Qwen-Image-Edit-2509 تقدمًا كبيرًا في معالجة الصور المدعومة بالذكاء الاصطناعي. أعاد المهندسون في Qwen بناء هذا النموذج لتلبية احتياجات المبدعين والمصممين والمطورين الذين يحتاجون إلى تحكم دقيق في المحتوى المرئي. على عكس الإصدارات السابقة، يدعم هذا الإصدار تحرير الصور المتعددة، مما يمكّن المستخدمين من دمج عناصر مثل شخص مع منتج أو مشهد بسهولة. ونتيجة لذلك، فإنه يزيل العيوب الشائعة مثل الخلطات غير المتطابقة، وينتج مخرجات متماسكة.

يتفوق النموذج في اتساق الصورة الواحدة. فهو يحافظ على هويات الوجه عبر الوضعيات والأنماط والفلاتر، مما يثبت قيمته للتطبيقات في الإعلان والتخصيص. بالنسبة لصور المنتجات، يحافظ Qwen-Image-Edit-2509 على سلامة الكائن، مما يضمن أن التعديلات لا تشوه السمات الرئيسية. بالإضافة إلى ذلك، فإنه يتعامل مع عناصر النص بشكل شامل، مما يسمح بتعديلات على المحتوى والخطوط والألوان وحتى الأنسجة. ينبع هذا التنوع من آليات ControlNet المدمجة، التي تدمج خرائط العمق واكتشاف الحواف والنقاط الرئيسية للتوجيه الدقيق.
من الناحية التقنية، يعتمد Qwen-Image-Edit-2509 على بنية Qwen-Image الأساسية ولكنه يدمج تقنيات تدريب متقدمة. قام المطورون بتدريبه باستخدام طرق ربط الصور لتسهيل مدخلات الصور المتعددة. على سبيل المثال، يدمج الجمع بين "شخص + شخص" أو "شخص + مشهد" تدفقات البيانات المتسلسلة، مما يعزز قدرة النموذج على دمج المرئيات المتباينة. علاوة على ذلك، تدمج البنية عمليات تعتمد على الانتشار، حيث يتم إزالة الضوضاء تدريجيًا لتوليد صور محسنة. يسمح هذا النهج، الشائع في متغيرات الانتشار المستقر، بالتوليد الشرطي بناءً على مطالبات المستخدم.
فيما يتعلق بالمعايير، يُظهر Qwen-Image-Edit-2509 أداءً فائقًا في مقاييس الاتساق. تُظهر التقييمات الداخلية أنه يتفوق على المنافسين في الحفاظ على الوجه، مع درجات تشابه تتجاوز 95% عبر التعديلات المتنوعة. تكشف معايير اتساق المنتج عن الحد الأدنى من التشويه، مما يجعله مثاليًا للتجارة الإلكترونية. ومع ذلك، تظل البيانات الكمية من المصادر الخارجية محدودة بسبب إصداره الأخير. ومع ذلك، تسلط عروض المستخدمين على منصات مثل Hugging Face الضوء على تفوقه على نماذج مثل Stable Diffusion XL في مزج العناصر المتعددة.
تتعدد تطبيقات Qwen-Image-Edit-2509. يستخدمه المسوقون لإنشاء إعلانات مخصصة عن طريق تعديل مواضع المنتجات بسلاسة. يستخدمه المصممون للنماذج الأولية السريعة، وتغيير المشاهد دون تنقيح يدوي. علاوة على ذلك، في الألعاب، يسهل توليد الأصول الديناميكية. يتضمن أحد الأمثلة التوضيحية تحويل زي شخص: صورة إدخال لامرأة ترتدي ملابس غير رسمية، مدمجة مع مرجع لفستان أسود، تنتج مخرجًا حيث يتناسب الفستان بشكل طبيعي، مع الحفاظ على الوضعية والإضاءة. هذه القدرة، كما هو موضح في العروض المرئية، تؤكد فائدتها العملية.


بالانتقال إلى التنفيذ، يصل المطورون إلى Qwen-Image-Edit-2509 عبر مستودعات GitHub و مساحات Hugging Face. يتضمن التثبيت عادةً استنساخ المستودع وإعداد التبعيات مثل PyTorch. قد يبدو نص الاستخدام الأساسي كالتالي:
import torch
from qwen_image_edit import QwenImageEdit
model = QwenImageEdit.from_pretrained("Qwen/Qwen-Image-Edit-2509")
input_image = load_image("person.jpg")
reference_image = load_image("dress.jpg")
output = model.edit_multi(input_image, reference_image, prompt="Apply the black dress to the person")
output.save("edited.jpg")
يمكّن هذا الكود من التكرارات السريعة. ومع ذلك، يجب على المستخدمين مراعاة المتطلبات الحسابية، حيث يتطلب الاستدلال تسريع GPU للحصول على السرعة المثلى.
على الرغم من نقاط قوته، يواجه Qwen-Image-Edit-2509 تحديات. يمكن أن تستهلك التعديلات عالية الدقة ذاكرة كبيرة، وتؤدي المطالبات المعقدة أحيانًا إلى عدم الاتساق. ومع ذلك، تساهم المساهمات المجتمعية المستمرة عبر قنوات المصادر المفتوحة في التخفيف من هذه المشكلات. بشكل عام، يعيد هذا النموذج تعريف تحرير الصور من خلال الجمع بين الدقة وسهولة الوصول.
Qwen3-TTS-Flash: تسريع توليف الكلام من النص
يبرز Qwen3-TTS-Flash كقوة دافعة في تقنية تحويل النص إلى كلام (TTS)، مع إعطاء الأولوية للسرعة والطبيعية. صمم مهندسو Qwen هذا النموذج لتقديم أصوات شبيهة بالبشر بأقل زمن استجابة، معالجةً للاختناقات في التطبيقات في الوقت الفعلي. على وجه التحديد، يحقق زمن استجابة للحزمة الأولى يبلغ 97 مللي ثانية فقط في البيئات ذات الخيط الواحد، مما يتيح تفاعلات سلسة في روبوتات الدردشة والمساعدين الافتراضيين.
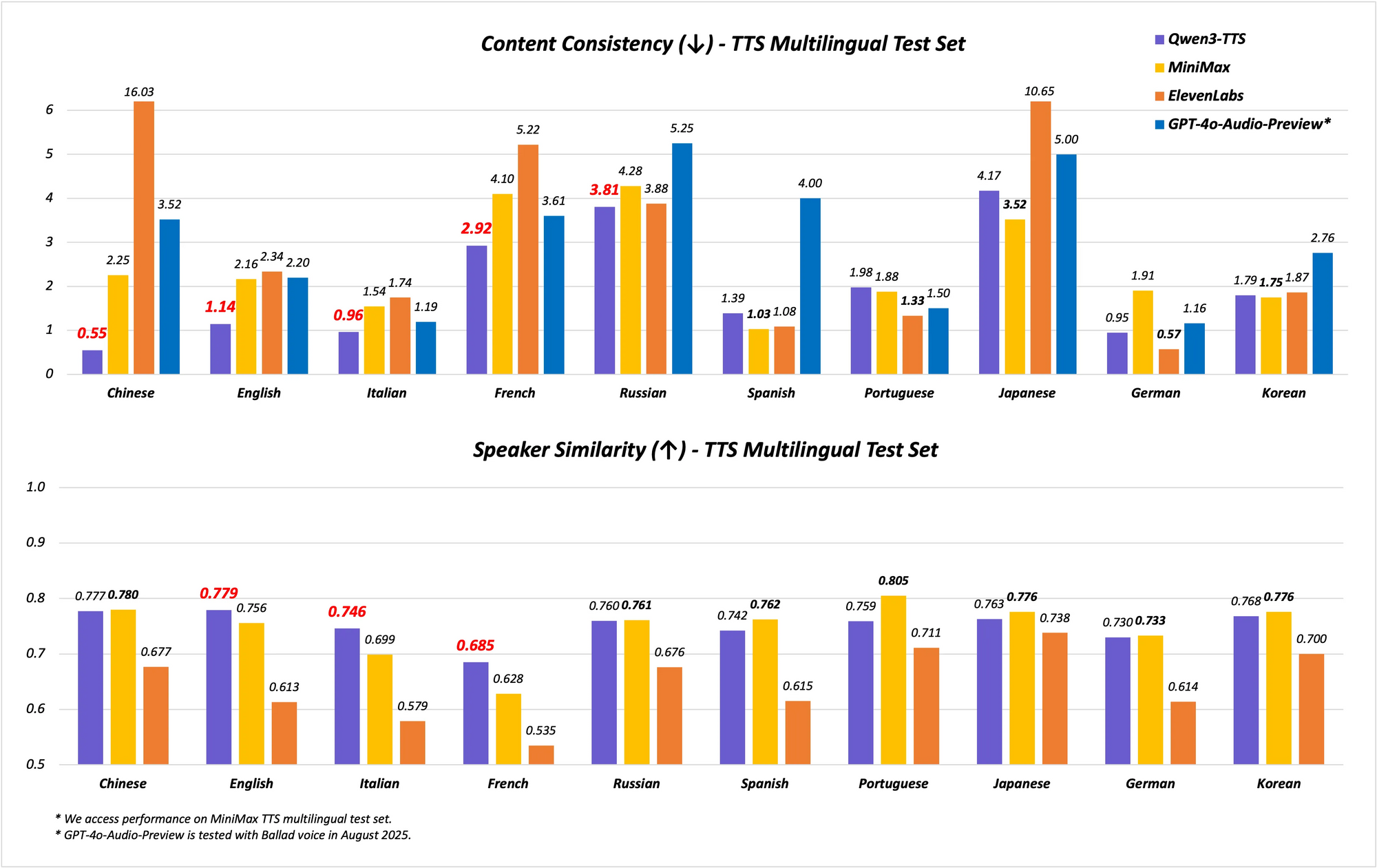
يدعم النموذج قدرات متعددة اللغات واللهجات، ويغطي 10 لغات بـ 17 صوتًا معبرًا. يتفوق في استقرار اللغتين الصينية والإنجليزية، محققًا أداءً متطورًا (SOTA) على معايير مثل مجموعة اختبار Seed-TTS-Eval. هنا، يتجاوز نماذج مثل SeedTTS و MiniMax و GPT-4o-Audio-Preview في مقاييس الاستقرار. علاوة على ذلك، في التقييمات متعددة اللغات على مجموعة اختبار MiniMax TTS، يسجل Qwen3-TTS-Flash أدنى معدل خطأ في الكلمات (WER) للغات الصينية والإنجليزية والإيطالية والفرنسية.
يدعم Qwen3-TTS-Flash اللهجات، مما يميزه عن غيره. يتعامل مع تسع لهجات صينية، بما في ذلك الكانتونية، والهوكين، والسيتشوانية، وبكين، ونانجينغ، وتيانجين، وشنشي. تتيح هذه الميزة كلامًا دقيقًا ثقافيًا، وهو أمر ضروري في الأسواق المتنوعة. بالإضافة إلى ذلك، يقوم النموذج بتكييف النغمات تلقائيًا، مستفيدًا من بيانات التدريب واسعة النطاق لمطابقة المشاعر المدخلة. يعزز التعامل القوي مع النصوص الموثوقية، حيث يستخرج المعلومات الرئيسية من التنسيقات المعقدة مثل التواريخ والأرقام والاختصارات.
من الناحية المعمارية، يستخدم Qwen3-TTS-Flash إطار عمل مشفر-مفكك قائم على المحولات، ومحسن للاستدلال منخفض زمن الاستجابة. يستخدم تمثيلات متعددة للكتب الرمزية لنمذجة صوتية أكثر ثراءً، مما يحسن التعبير. تضمن التدريب مجموعات بيانات واسعة تشمل 119 لغة للنص و 19 لفهم الكلام، على الرغم من أن الإخراج يركز على 10 لغات. يتيح هذا الإعداد التوليد عبر اللغات، حيث تنتج المدخلات بلغة واحدة مخرجات بلغة أخرى بسلاسة.

توضح المعايير براعته. في اختبارات الاستقرار، يسجل Qwen3-TTS-Flash درجات أعلى في تشابه النبرة والطبيعية مقارنة بـ ElevenLabs و GPT-4o. على سبيل المثال:
| المعيار | Qwen3-TTS-Flash | MiniMax | GPT-4o-Audio-Preview |
|---|---|---|---|
| استقرار اللغة الصينية | SOTA (الأفضل في فئته) | أقل | أقل |
| معدل خطأ الكلمات الإنجليزية (WER) | الأدنى | أعلى | أعلى |
| تشابه النبرة متعدد اللغات | SOTA (الأفضل في فئته) | أقل | أقل |
تنبع هذه النتائج من تقييمات صارمة، مما يضعه في مكانة رائدة في مجال TTS.
في العروض التوضيحية، يولد Qwen3-TTS-Flash كلامًا معبرًا، مثل وصف "لاتيه العسل واللافندر" بحماس أو التعامل مع الحوارات باللهجات. تكشف نصوص الفيديو عن قدرته على معالجة المدخلات متعددة اللغات، مثل "أنا سعيد جدًا اليوم. أعرف تلك الفتاة من الصين"، والتي تُقدم بأصوات لهجة. تشمل التطبيقات أنظمة الاستجابة الصوتية التفاعلية (IVR)، وشخصيات الألعاب غير القابلة للعب (NPCs)، وإنشاء المحتوى، حيث يضاعف زمن الاستجابة المنخفض الكفاءة.
يتطلب التنفيذ الوصول إلى النموذج عبر واجهات برمجة التطبيقات (APIs) أو عروض Hugging Face التوضيحية. مثال على استدعاء Python:
from qwen_tts import QwenTTSFlash
model = QwenTTSFlash.from_pretrained("Qwen/Qwen3-TTS-Flash")
audio = model.synthesize(text="Hello, world!", voice="expressive_english", dialect="sichuanese")
audio.save("output.wav")
تسرع هذه البساطة عملية التطوير. ومع ذلك، قد تختلف دقة اللهجة مع المدخلات النادرة، مما يستلزم ضبطًا دقيقًا.
يغير Qwen3-TTS-Flash تقنية TTS من خلال الموازنة بين السرعة والجودة والتنوع، مما يجعله لا غنى عنه لأنظمة الذكاء الاصطناعي الحديثة.
تقديم Qwen3-Omni: القوة المتعددة الوسائط الموحدة
يمثل تقديم Qwen3-Omni علامة فارقة في الذكاء الاصطناعي متعدد الوسائط، حيث يدمج Qwen النص والصورة والصوت والفيديو في نموذج واحد شامل. يتجنب هذا التوحيد الأصلي المقايضات بين الوسائط، مما يتيح استدلالًا أعمق عبر الوسائط. يعالج النموذج 119 لغة للنص، و 19 لإدخال الكلام، و 10 لإخراج الكلام، مع زمن استجابة مذهل يبلغ 211 مللي ثانية للاستجابات.
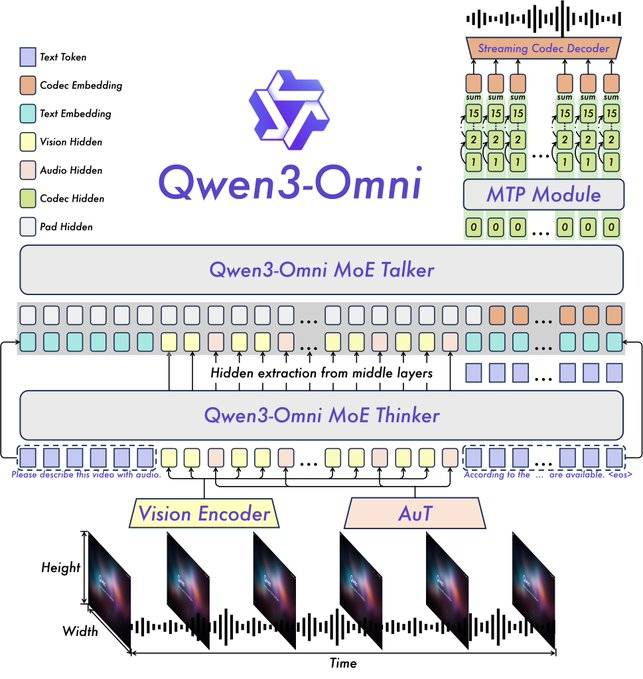
تشمل الميزات الرئيسية أداء SOTA على 22 من أصل 36 معيارًا صوتيًا وسمعيًا بصريًا، ومطالبات نظام قابلة للتخصيص، واستدعاء أدوات مدمج، ونموذج تسمية توضيحية مفتوح المصدر بمعدلات هلوسة منخفضة. قامت Qwen بفتح المصدر لمتغيرات مثل Qwen3-Omni-30B-A3B-Instruct لاتباع التعليمات و Qwen3-Omni-30B-A3B-Thinking لتعزيز الاستدلال.
تعتمد البنية على إطار عمل Thinker-Talker من Qwen2.5-Omni، مع ترقيات مثل استبدال مشفر الصوت Whisper بمحول صوت (AuT) لتمثيل أفضل. يعزز التعامل مع الكلام متعدد الكتب الرمزية مخرجات الصوت، بينما يدعم السياق الموسع أكثر من 30 دقيقة من الصوت. يسمح هذا بالاستدلال متعدد الوسائط بالكامل، حيث توفر مدخلات الفيديو معلومات لاستجابات الصوت.
تؤكد المعايير هيمنته. يحقق أداءً عامًا متطورًا (SOTA) على 32 معيارًا، متفوقًا في فهم الصوت وتوليده. على سبيل المثال، في المهام السمعية البصرية، يتفوق على نماذج مثل GPT-4o في زمن الاستجابة والدقة. جدول مقارنة:
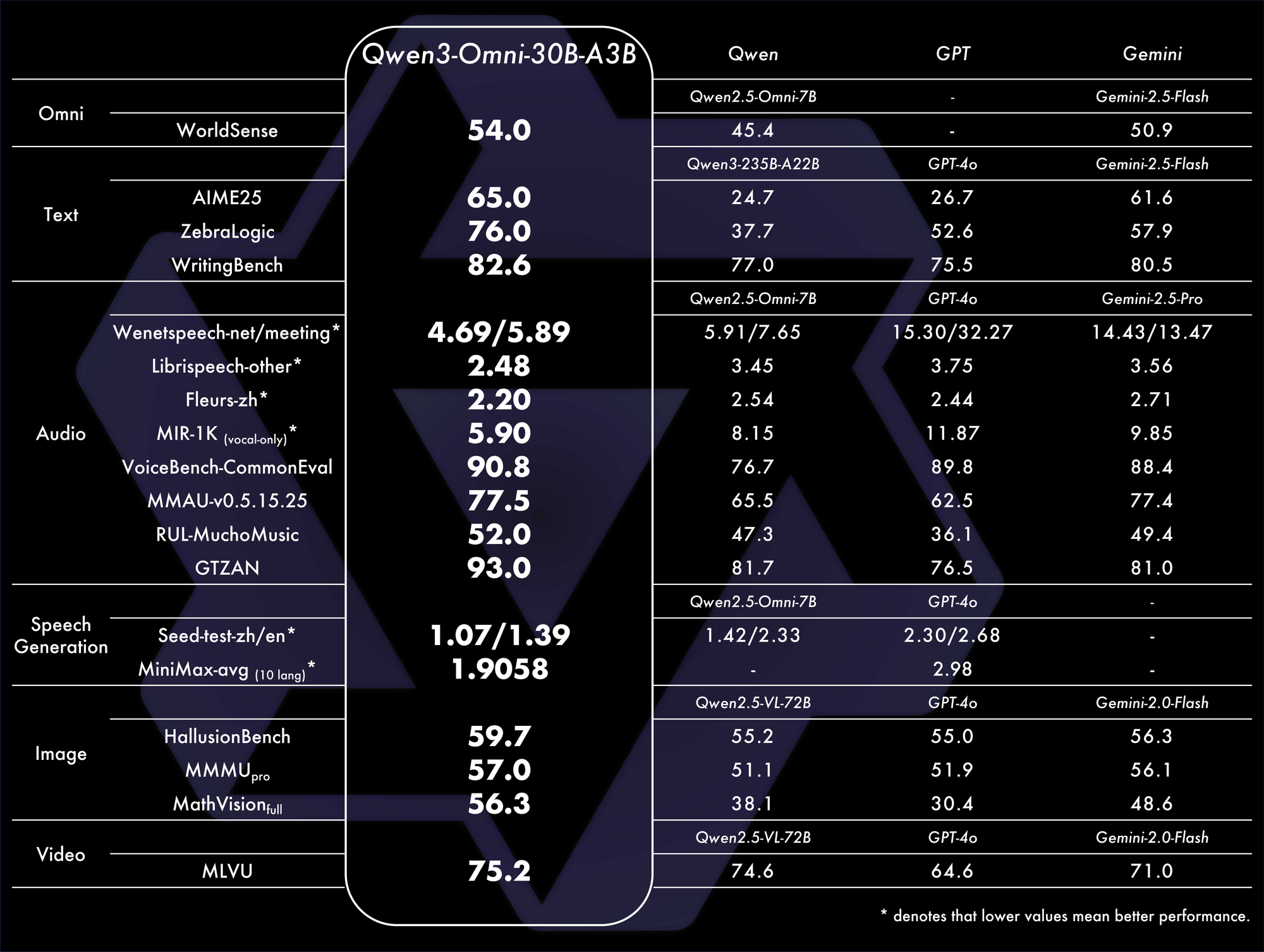
تسلط هذه المقاييس الضوء على كفاءته في سيناريوهات العالم الحقيقي.
تتراوح التطبيقات من الدردشة الصوتية وتحليل الفيديو إلى الوكلاء متعددي الوسائط. على سبيل المثال، يقوم بتحليل مقطع فيديو وتوليد ملخصات منطوقة، وهو مثالي لأدوات الوصول. تعرض العروض التوضيحية على Qwen Chat تفاعلات الصوت والفيديو، حيث يستعلم المستخدمون عن الصور أو الصوتيات شفهيًا.
من GitHub، يصف ملف README النموذج بأنه قادر على توليد الكلام في الوقت الفعلي من مدخلات متنوعة. يتضمن الإعداد ما يلي:
from qwen_omni import Qwen3Omni
model = Qwen3Omni.from_pretrained("Qwen/Qwen3-Omni-30B-A3B-Instruct")
response = model.process(inputs={"text": "Describe this", "image": "img.jpg", "audio": "clip.wav"})
print(response.text)
response.audio.save("reply.wav")
يسهل هذا النهج المعياري التخصيص. تشمل التحديات المتطلبات الحسابية العالية لمعالجة الفيديو، لكن التحسينات مثل التكميم تساعد.
يعمل تقديم Qwen3-Omni على دمج الوسائط، مما يعزز النظم البيئية المبتكرة للذكاء الاصطناعي.
أوجه التآزر بين نماذج Qwen الجديدة والآثار المستقبلية
تتكامل نماذج Qwen-Image-Edit-2509 و Qwen3-TTS-Flash و Qwen3-Omni مع بعضها البعض، مما يتيح سير عمل متكامل. على سبيل المثال، يمكن تحرير صورة باستخدام Qwen-Image-Edit-2509، ووصفها عبر Qwen3-Omni، وتحويل الوصف إلى صوت باستخدام Qwen3-TTS-Flash. يعزز هذا التكامل الفائدة في إنشاء المحتوى والأتمتة.
علاوة على ذلك، تدعو طبيعتها مفتوحة المصدر إلى تحسينات مجتمعية. يمكن للمطورين الذين يستخدمون Apidog اختبار واجهات برمجة التطبيقات بكفاءة، مما يضمن عمليات تكامل قوية.
ومع ذلك، تنشأ اعتبارات أخلاقية، مثل إساءة الاستخدام في التزييف العميق (deepfakes). تخفف Qwen من هذا من خلال الضمانات.
في الختام، تعيد إصدارات Qwen تعريف مشهد الذكاء الاصطناعي. من خلال دفع الحدود التقنية، فإنها تمكن المستخدمين من تحقيق المزيد. ومع تزايد التبني، ستقود هذه النماذج الموجة التالية من الابتكار.