
يُعد Qwen-Image، وهو نموذج أساسي للصور متطور من نوع MMDiT بحجم 20 مليار معلمة من فريق Qwen التابع لـ Alibaba Cloud، إعادة تعريف لإمكانيات الإبداع البصري المدفوع بالذكاء الاصطناعي. تم إطلاق هذا النموذج في 4 أغسطس 2025، ويقدم قدرات لا مثيل لها في إنشاء صور عالية الجودة، وعرض نصوص معقدة متعددة اللغات، وإجراء تعديلات دقيقة على الصور. سواء كنت تصمم مرئيات تسويقية ديناميكية أو تحلل بيانات صور معقدة، فإن Qwen-Image يزود المطورين بأدوات قوية لتحويل الأفكار إلى واقع.
زر
ما هو Qwen-Image؟ نظرة عامة تقنية
يُعد Qwen-Image، وهو جزء من سلسلة Qwen التابعة لـ Alibaba Cloud، نموذج محوّل انتشار متعدد الوسائط (MMDiT) يضم 20 مليار معلمة، مصممًا لإنشاء الصور وتحريرها. على عكس النماذج التقليدية التي تركز فقط على إنشاء المرئيات، يدمج Qwen-Image عرض النصوص المتقدم وفهم الصور، مما يجعله أداة متعددة الاستخدامات للمهام الإبداعية والتحليلية. النموذج، مفتوح المصدر بموجب ترخيص Apache 2.0، يمكن الوصول إليه عبر منصات مثل GitHub وHugging Face وModelScope، مما يسمح للمطورين بدمجه في سير عمل متنوعة.

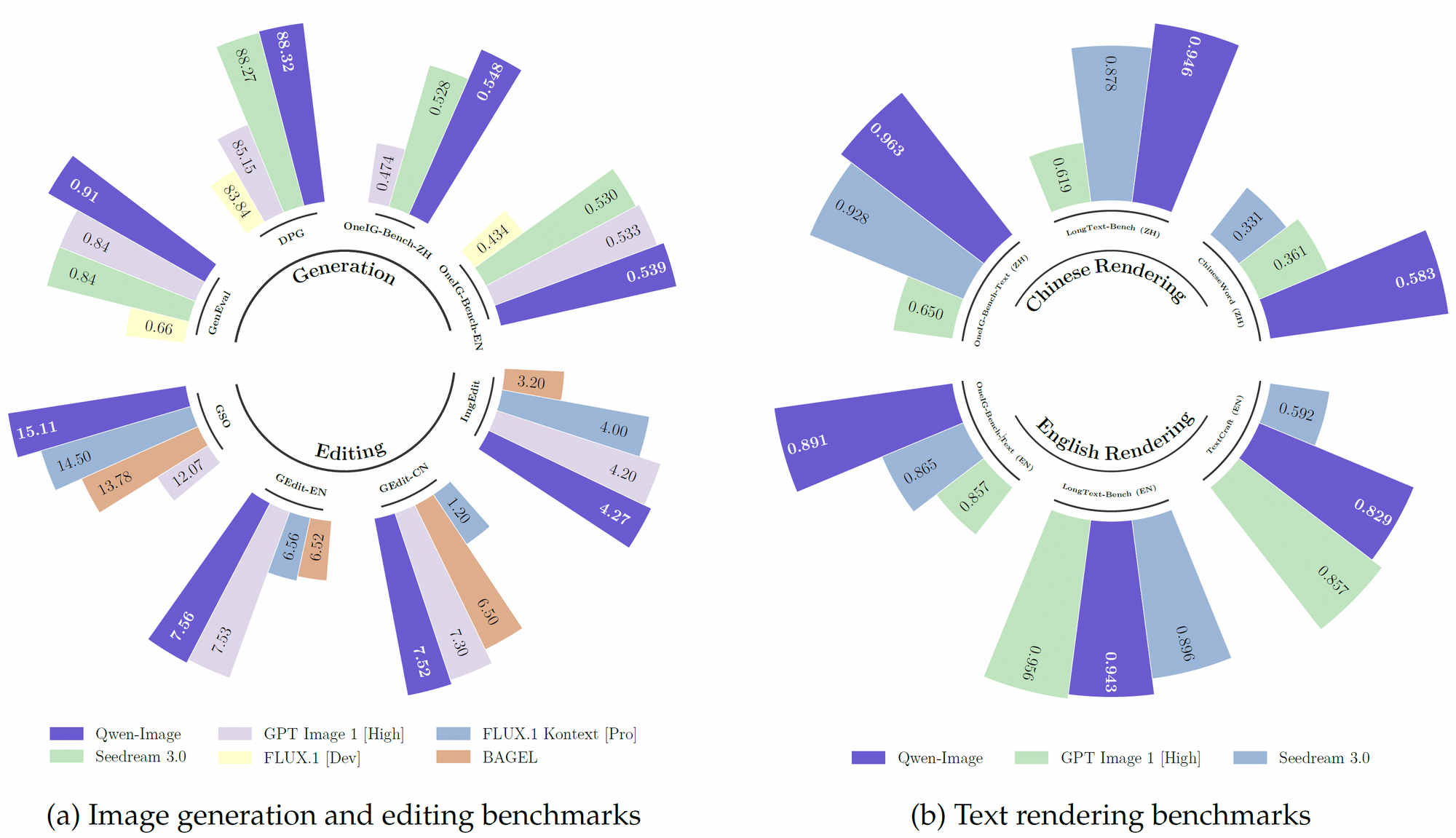
علاوة على ذلك، يستفيد Qwen-Image من مجموعة بيانات تدريب مسبق قوية، تتضمن أكثر من 30 تريليون رمز عبر 119 لغة، مع التركيز على اللغتين الصينية والإنجليزية. تتيح مجموعة البيانات الشاملة هذه، جنبًا إلى جنب مع تقنيات التعلم المعزز، للنموذج التعامل مع المهام المعقدة مثل عرض النصوص متعددة اللغات والتلاعب الدقيق بالكائنات. وبالتالي، فإنه يتفوق على العديد من النماذج الحالية في المعايير مثل GenEval وDPG وLongText-Bench.
الميزات الرئيسية لـ Qwen-Image
عرض نصوص فائق للمرئيات متعددة اللغات
يتفوق Qwen-Image في عرض النصوص المعقدة داخل الصور، وهي ميزة تميزه عن المنافسين. يدعم كلاً من اللغات الأبجدية (مثل الإنجليزية) والنصوص اللوغوغرافية (مثل الصينية)، مما يضمن تكامل النص بدقة عالية. على سبيل المثال، يمكن للنموذج إنشاء ملصق فيلم بتخطيطات نصية دقيقة، مثل عنوان "إطلاق العنان للخيال" (Imagination Unleashed) وعناوين فرعية في صفوف متعددة، مع الحفاظ على التناسق الطباعي. تنبع هذه القدرة من تدريبه على مجموعات بيانات متنوعة، بما في ذلك LongText-Bench وChineseWord، حيث يحقق أداءً متطورًا.
علاوة على ذلك، يتعامل Qwen-Image مع التخطيطات متعددة الأسطر ودلالات مستوى الفقرة بدقة ملحوظة. في سيناريو اختبار، قام بعرض قصيدة مكتوبة بخط اليد على ورق مصفر داخل صورة بدقة، على الرغم من أن النص يشغل أقل من عُشر المساحة المرئية. هذه الدقة تجعله مثاليًا لتطبيقات مثل اللافتات الرقمية، وتصميم الملصقات، وتصور المستندات.
قدرات تحرير الصور المتقدمة
بالإضافة إلى عرض النصوص، يقدم Qwen-Image ميزات متطورة لتحرير الصور. يدعم عمليات مثل نقل الأنماط، وإدراج الكائنات، وتحسين التفاصيل، والتلاعب بوضعيات الجسم البشري. على سبيل المثال، يمكن للمستخدمين توجيه النموذج لـ "إضافة سماء مشمسة إلى هذه الصورة" أو "تغيير هذه اللوحة إلى نمط فان جوخ"، ويقدم Qwen-Image نتائج متناسقة. يضمن نموذج التدريب متعدد المهام المحسّن الخاص به أن تحافظ التعديلات على المعنى الدلالي والواقعية البصرية.
بالإضافة إلى ذلك، فإن قدرة النموذج على تحرير النصوص داخل الصور جديرة بالملاحظة بشكل خاص. يمكن للمطورين تعديل النصوص على اللافتات أو الملصقات دون تعطيل السياق البصري المحيط، وهي ميزة قيمة للإعلان وإنشاء المحتوى. تدعم هذه القدرات الفهم البصري العميق لـ Qwen-Image، والذي يسمح له بتفسير عناصر الصورة والتلاعب بها بدقة.
فهم بصري شامل
لا يقتصر Qwen-Image على الإنشاء أو التحرير فحسب، بل يفهم أيضًا. يدعم النموذج مجموعة من مهام فهم الصور، بما في ذلك اكتشاف الكائنات، والتجزئة الدلالية، وتقدير العمق، واكتشاف الحواف (Canny)، وتوليف المناظر الجديدة، والوضوح الفائق. تعتمد هذه المهام على قدرته على معالجة المدخلات عالية الدقة واستخراج التفاصيل الدقيقة. على سبيل المثال، يمكن لـ Qwen-Image إنشاء مربعات إحاطة للكائنات الموصوفة بلغة طبيعية، مثل "اكتشف كلب الهاسكي في مشهد المترو"، مما يجعله أداة قوية للتحليلات البصرية.
علاوة على ذلك، يعزز دعمه للغات متعددة قابليته للاستخدام في التطبيقات العالمية. من خلال التكامل مع أدوات مثل Qwen-Plus Prompt Enhancement Tool، يمكن للمطورين تحسين المطالبات للحصول على أداء أفضل متعدد اللغات، مما يضمن نتائج دقيقة عبر سياقات لغوية متنوعة.
التميز في الأداء عبر المعايير
يتفوق Qwen-Image باستمرار على المنافسين في العديد من المعايير العامة، بما في ذلك GenEval وDPG وOneIG-Bench وGEdit وImgEdit وGSO. يتضح أداؤه المتفوق في عرض النصوص، خاصة للغة الصينية، في معايير مثل TextCraft، حيث يتجاوز النماذج الحالية المتطورة. بالإضافة إلى ذلك، تدعم قدراته العامة في إنشاء الصور مجموعة واسعة من الأساليب الفنية، من المشاهد الواقعية إلى جماليات الأنمي، مما يجعله خيارًا متعدد الاستخدامات للمحترفين المبدعين.
البنية التقنية لـ Qwen-Image
محوّل الانتشار متعدد الوسائط (MMDiT)
في جوهره، يستخدم Qwen-Image بنية محوّل انتشار متعدد الوسائط (MMDiT)، والتي تجمع بين نقاط قوة نماذج الانتشار والمحولات. يتيح هذا النهج الهجين للنموذج معالجة المدخلات البصرية والنصية بكفاءة. تعمل عملية الانتشار على تحسين المدخلات المشوشة بشكل متكرر إلى صور متماسكة، بينما يتعامل مكون المحوّل مع العلاقات المعقدة بين النص والعناصر المرئية.
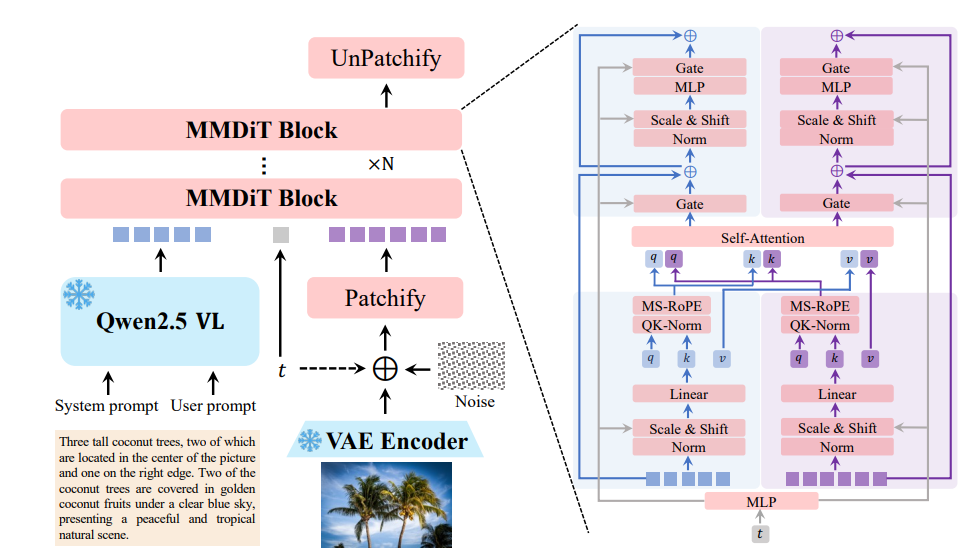
تم تحسين معلمات النموذج البالغة 20 مليارًا لتحقيق الكفاءة، مما يسمح له بالعمل على أجهزة المستهلكين بذاكرة وصول عشوائي للفيديو (VRAM) لا تتجاوز 4 جيجابايت عند استخدام تقنيات مثل تكميم FP8 وتفريغ الطبقات طبقة تلو الأخرى. تجعل هذه إمكانية الوصول Qwen-Image مناسبًا لكل من المطورين في الشركات والأفراد.
التدريب المسبق والضبط الدقيق
يُعد مجموعة بيانات التدريب المسبق لـ Qwen-Image حجر الزاوية في أدائه. تمتد مجموعة البيانات على أكثر من 30 تريليون رمز، وتتضمن بيانات الويب، والمستندات الشبيهة بملفات PDF، والبيانات الاصطناعية التي تم إنشاؤها بواسطة نماذج مثل Qwen2.5-VL وQwen2.5-Coder. تتم عملية التدريب المسبق في ثلاث مراحل:

- المرحلة 1 (S1): يتم تدريب النموذج مسبقًا على 30 تريليون رمز بطول سياق يبلغ 4 آلاف رمز، مما يؤسس مهارات اللغة والرؤية الأساسية.
- المرحلة 2: يعزز التعلم المعزز قدرات النموذج على الاستدلال والمهام المحددة.
- المرحلة 3: يعمل الضبط الدقيق باستخدام مجموعات بيانات منسقة على تحسين التوافق مع تفضيلات المستخدم والمهام المحددة مثل عرض النصوص وتحرير الصور.
يضمن هذا النهج متعدد المراحل أن يكون Qwen-Image قويًا وقابلًا للتكيف، وقادرًا على التعامل مع مهام متنوعة بدقة عالية.
التكامل مع أدوات التطوير
يتكامل Qwen-Image بسلاسة مع أطر عمل التطوير الشائعة مثل Diffusers وDiffSynth-Studio. على سبيل المثال، يمكن للمطورين استخدام كود بايثون التالي لإنشاء صور باستخدام Qwen-Image:
from diffusers import DiffusionPipeline
import torch
model_name = "Qwen/Qwen-Image"
torch_dtype = torch.bfloat16 if torch.cuda.is_available() else torch.float32
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
prompt = "A coffee shop entrance with a chalkboard sign reading 'Qwen Coffee 😊 $2 per cup.'"
image = pipe(prompt).images[0]
image.save("qwen_coffee.png")
يوضح مقتطف الكود هذا كيف يمكن للمطورين الاستفادة من قدرات Qwen-Image لإنشاء مرئيات عالية الجودة بأقل قدر من الإعداد. تعمل أدوات مثل Apidog على تبسيط تكامل واجهة برمجة التطبيقات بشكل أكبر، مما يتيح النماذج الأولية والنشر السريع.
تطبيقات عملية لـ Qwen-Image
إنشاء المحتوى الإبداعي
إن قدرة Qwen-Image على إنشاء مشاهد واقعية للصور، ولوحات انطباعية، ومرئيات بأسلوب الأنمي تجعله أداة قوية للفنانين والمصممين. على سبيل المثال، يمكن لمصمم جرافيك إنشاء ملصق فيلم بتخطيطات نصية ديناميكية وصور نابضة بالحياة، كما هو موضح في حالة اختبار حيث أنتج Qwen-Image ملصقًا لـ "إطلاق العنان للخيال" (Imagination Unleashed) مع جهاز كمبيوتر مستقبلي يبعث مخلوقات غريبة.

الإعلان والتسويق
في الإعلان، تتيح قدرات Qwen-Image على عرض النصوص وتحريرها إنشاء حملات جذابة بصريًا. يمكن للمسوقين إنشاء ملصقات بوضع نص دقيق أو تعديل المرئيات الموجودة لتحديث الرسائل الترويجية، مما يضمن اتساق العلامة التجارية والتناسق البصري.

التحليلات البصرية والأتمتة
بالنسبة للصناعات مثل التجارة الإلكترونية والأنظمة المستقلة، تقدم مهام فهم الصور في Qwen-Image—مثل اكتشاف الكائنات والتجزئة الدلالية—قيمة كبيرة. يمكن لمنصات البيع بالتجزئة استخدام النموذج لوضع علامات تلقائية على المنتجات في الصور، بينما يمكن للمركبات المستقلة الاستفادة من تقدير العمق الخاص به للملاحة.
أدوات تعليمية
تدعم قدرة Qwen-Image على إنشاء مرئيات تعليمية، مثل الرسوم البيانية ذات التعليقات النصية الدقيقة، منصات التعلم الإلكتروني. على سبيل المثال، يمكنه إنشاء رسم توضيحي مفصل لمفهوم علمي بمكونات معنونة، مما يعزز مشاركة الطلاب وفهمهم.

مقارنة Qwen-Image بالمنافسين
عند مقارنته بنماذج مثل DALL-E 3 وStable Diffusion، يبرز Qwen-Image لقدرته على عرض النصوص متعددة اللغات وإمكانيات التحرير المتقدمة. بينما يتفوق DALL-E 3 في إنشاء الصور الإبداعية، فإنه يواجه صعوبات مع تخطيطات النصوص المعقدة، خاصة بالنسبة للنصوص اللوغوغرافية. أما Stable Diffusion، على الرغم من تنوعه، يفتقر إلى الفهم البصري العميق الذي تقدمه مجموعة مهام فهم الصور في Qwen-Image.
بالإضافة إلى ذلك، تمنح طبيعة Qwen-Image مفتوحة المصدر وتوافقه مع الأجهزة ذات الذاكرة المنخفضة ميزة للمطورين ذوي الموارد المحدودة. كما أن أداءه في المعايير مثل TextCraft وGEdit يعزز مكانته كنموذج رائد في الذكاء الاصطناعي متعدد الوسائط.
التحديات والقيود
على الرغم من نقاط قوته، يواجه Qwen-Image تحديات. يثير اعتماد النموذج على مجموعات بيانات واسعة النطاق مخاوف بشأن خصوصية البيانات والمصادر الأخلاقية، على الرغم من أن Alibaba Cloud تلتزم بإرشادات صارمة. بالإضافة إلى ذلك، بينما يدعم النموذج أكثر من 100 لغة، قد يختلف أداؤه للهجات الأقل تمثيلاً، مما يتطلب مزيدًا من الضبط الدقيق.
علاوة على ذلك، يمكن أن تكون المتطلبات الحسابية للنموذج ذي الـ 20 مليار معلمة كبيرة بدون تقنيات التحسين مثل تكميم FP8. يجب على المطورين الموازنة بين الأداء وقيود الموارد عند نشر Qwen-Image في بيئات الإنتاج.
الآفاق المستقبلية لـ Qwen-Image
بالنظر إلى المستقبل، يستعد Qwen-Image للتطور بشكل أكبر. يخطط فريق Qwen لإصدار نسخة من النموذج مخصصة للتحرير، مما يعزز قدراته للتطبيقات الاحترافية. سيعمل التكامل مع الأطر الناشئة مثل vLLM والدعم المستمر لـ LoRA وسير عمل الضبط الدقيق على توسيع إمكانية الوصول إليه.
علاوة على ذلك، تشير التطورات في التعلم المعزز، كما هو الحال في نماذج مثل Qwen3، إلى أن Qwen-Image يمكن أن يدمج قدرات استدلال أعمق، مما يتيح مهام استدلال بصري أكثر تعقيدًا. مع استمرار مجتمع الذكاء الاصطناعي في المساهمة في تطويره، يمتلك Qwen-Image القدرة على إعادة تعريف الإنشاء والفهم البصري.
البدء مع Qwen-Image
للبدء في استخدام Qwen-Image، يمكن للمطورين الوصول إلى أوزان النموذج على GitHub أو Hugging Face. توفر المدونة الرسمية على qwenlm.github.io تعليمات إعداد مفصلة وحالات استخدام. للحصول على تجربة عملية، قم بزيارة Qwen Chat وحدد "إنشاء الصور" لاختبار قدرات النموذج.
لتكامل واجهة برمجة التطبيقات، تعمل أدوات مثل Apidog على تبسيط العملية من خلال توفير واجهة سهلة الاستخدام لاختبار ونشر ميزات Qwen-Image. قم بتنزيل Apidog مجانًا لتبسيط سير عمل التطوير الخاص بك.
زر
الخلاصة: لماذا يُعد Qwen-Image مهمًا
يمثل Qwen-Image قفزة نوعية في الذكاء الاصطناعي متعدد الوسائط، حيث يجمع بين عرض النصوص المتقدم، وتحرير الصور الدقيق، والفهم البصري القوي. إن توفره كمصدر مفتوح، وتدريبه المسبق الشامل، وتوافقه مع أدوات التطوير يجعله خيارًا متعدد الاستخدامات للمبدعين والمطورين والباحثين. من خلال معالجة التحديات مثل الدعم متعدد اللغات وكفاءة الموارد، يضع Qwen-Image معيارًا جديدًا للإبداع البصري المدفوع بالذكاء الاصطناعي.
مع استمرار تطور الذكاء الاصطناعي، ستلعب نماذج مثل Qwen-Image دورًا محوريًا في سد الفجوة بين اللغة والصور، مما يفتح إمكانيات جديدة للتطبيقات الإبداعية والتحليلية. سواء كنت تبني حملة تسويقية، أو تحلل البيانات المرئية، أو تنشئ محتوى تعليميًا، فإن Qwen-Image يقدم الأدوات اللازمة لتحويل رؤيتك إلى واقع.
زر