
في عالم الذكاء الاصطناعي الذي يتطور بسرعة، تم تحقيق علامة بارزة جديدة مع إصدار Qwen 2.5 Omni 7B. هذا النموذج الثوري من Alibaba Cloud يمثل قفزة كبيرة إلى الأمام في الذكاء الاصطناعي متعدد الأنماط، حيث يجمع بين القدرة على معالجة وفهم أشكال متعددة من المدخلات أثناء إنشاء مخرجات نصية وصوتية. دعونا نتعمق في ما يجعل هذا النموذج مميزًا حقًا وكيف يعيد تشكيل فهمنا لقدرات الذكاء الاصطناعي.
المعنى الحقيقي لـ "Omni" ضمن Qwen 2.5 Omni 7B
مصطلح "Omni" في Qwen 2.5 Omni 7B ليس مجرد علامة تجارية ذكية - بل هو وصف أساسي لقدرات النموذج. على عكس العديد من النماذج متعددة الأنماط التي تتفوق في نوع أو نوعين من البيانات، تم تصميم Qwen 2.5 Omni 7B من الأساس ليتمكن من إدراك وفهم:
- النص (اللغة المكتوبة)
- الصور (المعلومات المرئية)
- الصوت (الأصوات واللغة المنطوقة)
- الفيديو (المحتوى المرئي المتحرك مع بُعد زمني)
Voice Chat + Video Chat! Just in Qwen Chat (https://t.co/FmQ0B9tiE7)! You can now chat with Qwen just like making a phone call or making a video call! Check the demo in https://t.co/42iDe4j1Hs
— Qwen (@Alibaba_Qwen) March 26, 2025
What's more, we opensource the model behind all this, Qwen2.5-Omni-7B, under the… pic.twitter.com/LHQOQrl9Ha
ما هو أكثر إثارة للإعجاب هو أن هذا النموذج لا يستقبل فقط هذه المدخلات المتنوعة - بل يمكنه أيضًا الاستجابة بمخرجات نصية وصوتية طبيعية بشكل متدفق. تمثل هذه القدرة "أي إلى أي" تقدمًا كبيرًا نحو تفاعلات ذكاء اصطناعي أكثر طبيعية وشبيهة بالبشر.
العمارة المبتكرة لـ Qwen 2.5 Omni 7B: الشرح
المفكر-المتحدث: نموذج جديد
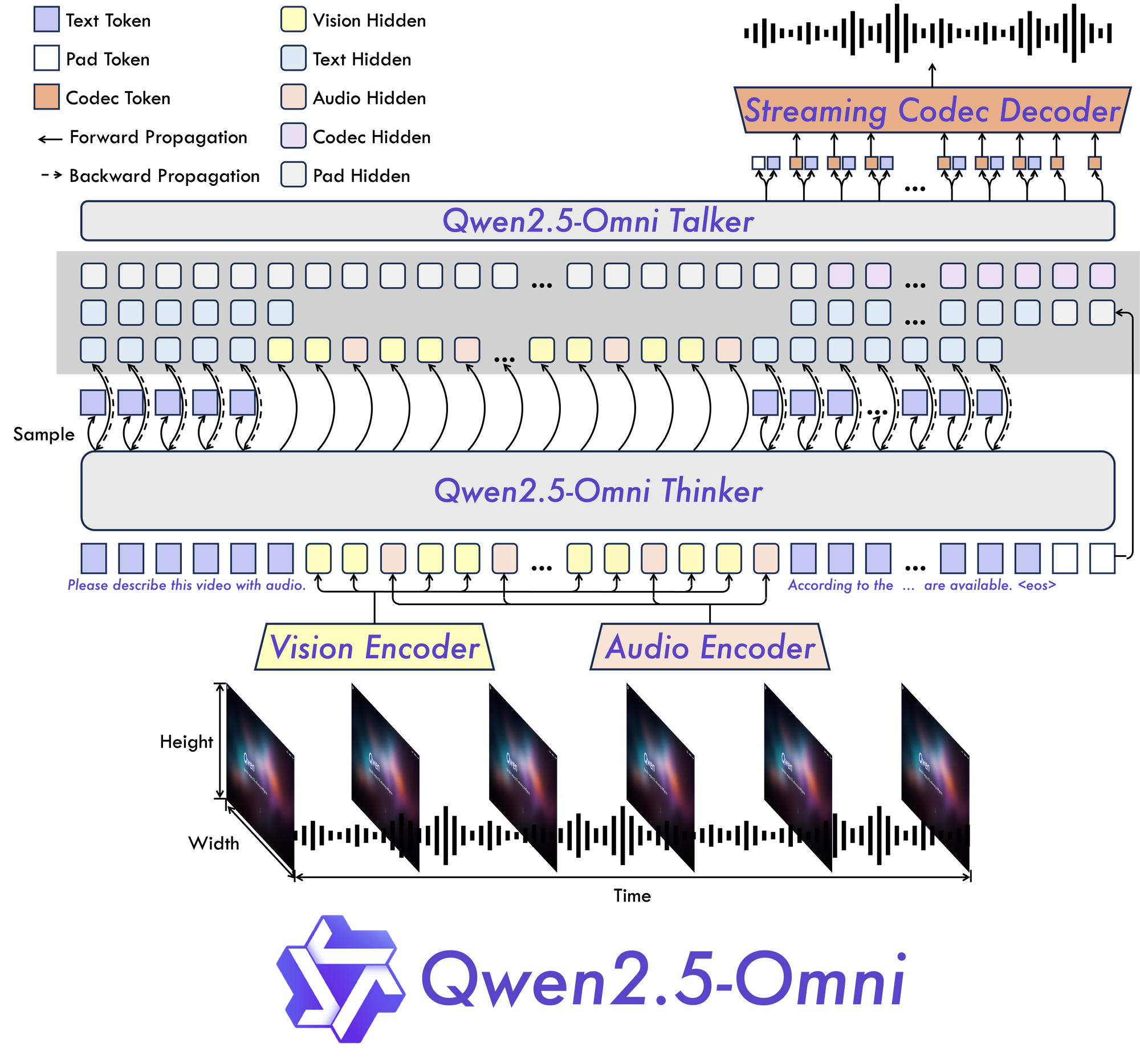
في قلب Qwen 2.5 Omni 7B توجد بنية "المفكر-المتحدث" الأساسية. يقوم هذا التصميم الجديد بإنشاء نموذج مصمم خصيصًا ليكون متعدد الأنماط من النهاية إلى النهاية، مما يتيح معالجة سلسة عبر أنواع مختلفة من المعلومات.
كما يشير الاسم، تفصل هذه البنية بين معالجة المعلومات الإدراكية (التفكير) وإنتاج المخرجات (التحدث). تتيح هذه الفجوة للنموذج إدارة التعقيدات المتأصلة في البيانات متعددة الأنماط وإنتاج الاستجابات المناسبة بأشكال متعددة.
TMRoPE: حل تحدي المحاذاة الزمنية
أحد الابتكارات الأكثر أهمية في Qwen 2.5 Omni 7B هو آلية Time-aligned Multimodal RoPE (TMRoPE). يعالج هذا الاختراق أحد الجوانب الأكثر تحديًا في الذكاء الاصطناعي متعدد الأنماط: مزامنة البيانات الزمنية من مصادر مختلفة.
عند معالجة الفيديو والصوت في وقت واحد، يحتاج النموذج إلى فهم كيفية توافق الأحداث المرئية مع الأصوات أو الكلام المقابل. على سبيل المثال، يتطلب مطابقة حركات شفاه الشخص مع كلماتهم المنطوقة محاذاة زمنية دقيقة. تقدم TMRoPE الإطار المتطور لتحقيق هذه المزامنة، مما يمكّن النموذج من بناء فهم متماسك للمدخلات متعددة الأنماط التي تتكشف بمرور الوقت.
مصمم للتفاعل في الوقت الحقيقي
تم بناء Qwen 2.5 Omni 7B مع وضع التطبيقات الزمنية الحقيقية في الاعتبار. تدعم البنية بثاً منخفض الكمون، مما يتيح معالجة المدخلات المجزأة وإنتاج المخرجات على الفور. يجعل هذا أمرًا مثاليًا للتطبيقات التي تتطلب تفاعلات سريعة، مثل المساعدات الصوتية، وتحليل الفيديو المباشر، أو خدمات الترجمة في الوقت الحقيقي.
أداء Qwen 2.5 Omni 7B: المعايير تتحدث عن نفسها
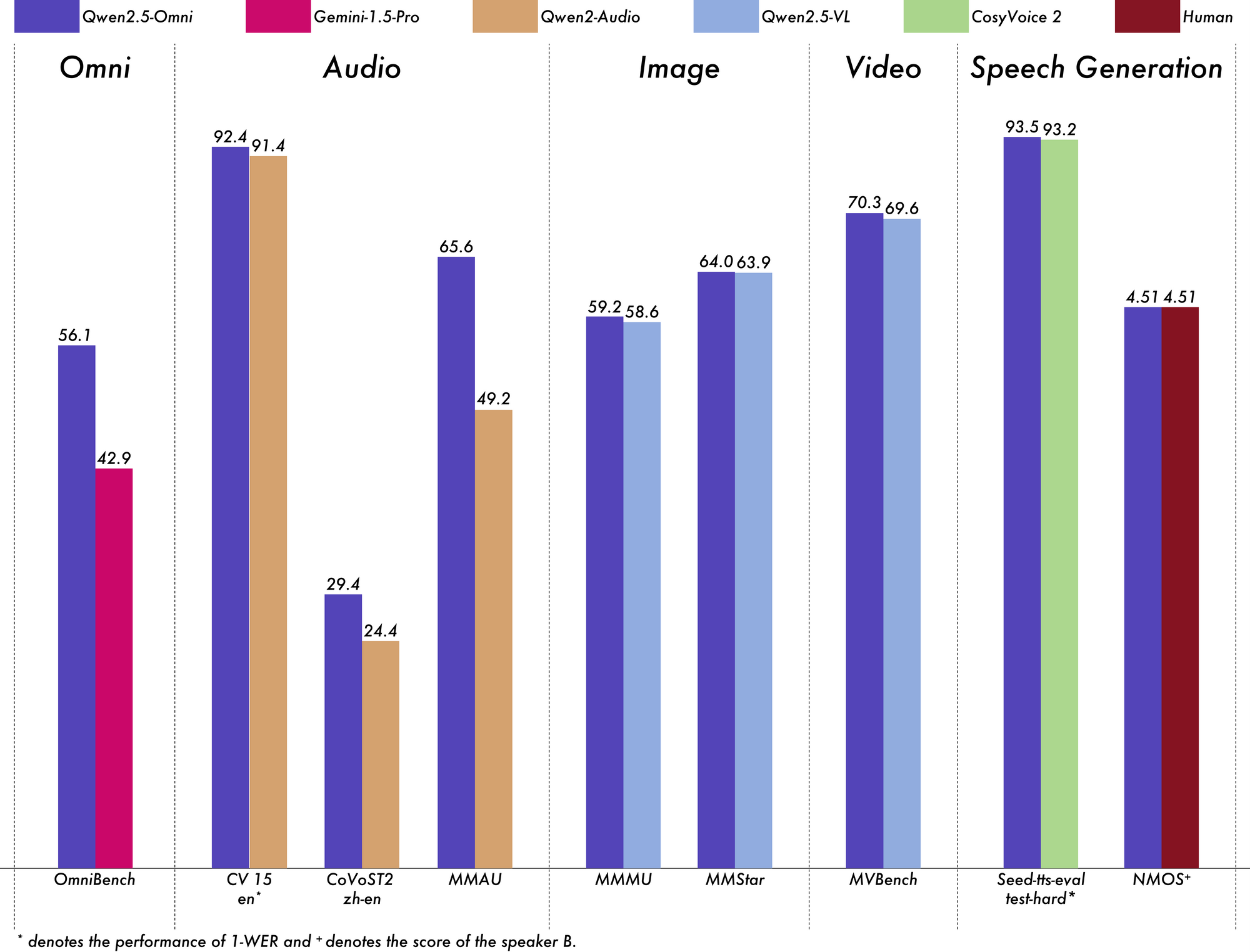
الاختبار الحقيقي لأي نموذج للذكاء الاصطناعي هو أداؤه عبر معايير صارمة، وQwen 2.5 Omni 7B يقدم نتائج مثيرة للإعجاب عبر جميع المعايير.
الريادة في الفهم متعدد الأنماط
في معيار OmniBench للفهم العام متعدد الأنماط، يحقق Qwen 2.5 Omni 7B درجة متوسطة قدرها 56.13%. يتفوق هذا بدرجة أكبر على نماذج أخرى مثل Gemini-1.5-Pro (42.91%) وMIO-Instruct (33.80%). أداؤه الاستثنائي في فئات OmniBench المحددة يستحق الإشارة بشكل خاص:
- مهام الكلام: 55.25%
- مهام أحداث الصوت: 60.00%
- مهام الموسيقى: 52.83%
تظهر هذه الأداء الشامل قدرة النموذج على دمج والتفكير عبر مجموعة متنوعة من الأنماط.
التفوق في معالجة الصوت
بالنسبة لمهام الصوت إلى نص، يظهر Qwen 2.5 Omni 7B نتائج قريبة من الحالة الراهنة في التعرف على الكلام الآلي (ASR). في مجموعة بيانات Librispeech، يحقق معدلات خطأ الكلمات (WER) تتراوح بين 1.6% إلى 3.5%، مقارنة بالنماذج المتخصصة مثل Whisper-large-v3.
في التعرف على أحداث الصوت على مجموعة بيانات Meld، يحقق أداءً الأفضل في فئته مع درجة 0.570. يتفوق النموذج أيضًا في فهم الموسيقى، حيث سجل 0.88 في معيار GiantSteps Tempo.
فهم قوي للصورة
عندما يتعلق الأمر بمهام الصورة إلى نص، يحقق Qwen 2.5 Omni 7B درجة 59.2 في معيار MMMU، وهو قريب بشكل ملحوظ من درجة 60.0 لـ GPT-4o-mini. في مهمة Grounding RefCOCO، يصل إلى دقة 90.5%، متفوقًا على Gemini 1.5 Pro الذي حقق 73.2%.
فهم الفيديو المثير للإعجاب
بالنسبة لمهام الفيديو إلى نص بدون ترجمات، يسجل النموذج 64.3 في Video-MME، مما يعادل تقريبًا أداء النماذج المتخصصة في الفيديو. عندما تضاف الترجمات، يرتفع الأداء إلى 72.4، مما يظهر قدرة النموذج على دمج مصادر المعلومات المتعددة بشكل فعال.
توليد خطاب طبيعي
لا يفهم Qwen 2.5 Omni 7B فحسب – بل يتحدث أيضًا. بالنسبة لتوليد الكلام، يحقق درجات مشابهة للمؤدي تتراوح بين 0.754 إلى 0.752، مما يجعله مقارنة مع نماذج النص إلى صوت المخصصة مثل Seed-TTS_RL. وهذا يظهر قدرته على توليد خطاب يبدو طبيعيًا ويحافظ على خصائص صوت المتحدث الأصلي.
الحفاظ على قدرات نصية قوية
على الرغم من تركيزه متعدد الأنماط، إلا أن Qwen 2.5 Omni 7B لا يزال يقدم أداءً رائعًا في المهام النصية فقط. يحقق نتائج قوية في التفكير الرياضي (درجة GSM8K: 88.7%) وتوليد الشفرات. في حين أن هناك تراجعًا صغيرًا مقارنةً بنموذج Qwen2.5-7B النصي فقط (الذي سجل 91.6% في GSM8K)، فإن هذا التراجع الطفيف هو تنازل معقول للحصول على مثل هذه القدرات الشاملة متعددة الأنماط.
تطبيقات العالم الحقيقي لـ Qwen 2.5 Omni 7B:
Qwen 2.5 Omni is NUTS!
— Jeff Boudier 🤗 (@jeffboudier) March 26, 2025
I can't believe a 7B model
can take text, images, audio, video as input
give text and audio as output
and work so well!
Open source Apache 2.0
Try it, link below!
You really cooked @Alibaba_Qwen ! pic.twitter.com/pn0dnwOqjY
فتحت مرونة Qwen 2.5 Omni 7B مجموعة واسعة من التطبيقات العملية عبر العديد من المجالات.
زيادة واجهات الاتصال
إن قدراته المتميزة في البث ذو الكمون المنخفض تجعل منه نموذجًا مثاليًا لتطبيقات الدردشة الصوتية والفيديو في الوقت الحقيقي. تخيل مساعدات افتراضية يمكنها رؤية وسماع والتحدث بشكل طبيعي، وفهم كل من الإشارات اللفظية وغير اللفظية أثناء الاستجابة بخطاب طبيعي.
تحليل محتوى متقدم
تؤهل قدرة النموذج على معالجة وفهم أنماط متعددة كنموذج قوي لتحليل المحتوى الشامل. يمكنه استخراج الرؤى من الوثائق متعددة الوسائط، مما يتيح له التعرف تلقائيًا على المعلومات الرئيسية من النصوص والصور والصوت والفيديو في وقت واحد.
واجهات صوتية سهلة الاستخدام
مع أدائه القوي في تنفيذ التعليمات الصوتية من البداية إلى النهاية، يتيح Qwen 2.5 Omni 7B تفاعلات أكثر طبيعية وبيدين خاليتين مع التكنولوجيا. قد يحدث هذا ثورة في ميزات الوصول للمستخدمين ذوي الإعاقات أو في الحالات التي يكون فيها التشغيل بدون استخدام اليدين أمرًا أساسيًا.
توليد محتوى إبداعي
تفتح قدرة النموذج على توليد كل من النصوص والخطاب الطبيعي آفاقًا جديدة لإنشاء المحتوى. من توليد السرد تلقائيًا للفيديو إلى إنشاء مواد تعليمية تفاعلية تستجيب لاستفسارات الطلاب بشرح مناسب، التطبيقات لا حصر لها.
خدمة عملاء متعددة الأنماط
يمكن أن تستفيد الشركات من Qwen 2.5 Omni 7B لتشغيل أنظمة خدمة العملاء التي يمكنها تحليل استفسارات العملاء من قنوات متعددة – المكالمات الصوتية، محادثات الفيديو، الرسائل المكتوبة – والاستجابة بشكل طبيعي ومناسب لكل منها.
الاعتبارات العملية والقيود
بينما يمثل Qwen 2.5 Omni 7B تقدمًا كبيرًا في الذكاء الاصطناعي متعدد الأنماط، هناك بعض الاعتبارات العملية التي يجب وضعها في الاعتبار عند العمل معه.
متطلبات الأجهزة
تأتي القدرات الشاملة للنموذج مع مطالب حسابية كبيرة. يتطلب معالجة فيديو قصير نسبيًا مدته 15 ثانية بدقة FP32 حوالي 93.56 جيجابايت من ذاكرة GPU. حتى مع دقة BF16، لا يزال الفيديو المدته 60 ثانية يحتاج إلى حوالي 60.19 جيجابايت.
قد تحد هذه المتطلبات من وصول المستخدمين الذين ليس لديهم إمكانية الوصول إلى الأجهزة المتطورة. ومع ذلك، يدعم النموذج مجموعة متنوعة من التحسينات مثل Flash Attention 2، والتي يمكن أن تساعد في تحسين الأداء على الأجهزة المتوافقة.
تخصيص نوع الصوت
المثير للاهتمام، أن Qwen 2.5 Omni 7B يدعم أنواع صوت متعددة لمخرجاته الصوتية. حاليًا، يقدم خيارين للصوت:
- تشيلسي: صوت أنثوي يوصف بأنه "عسل، حريري" مع "دفء لطيف وصفاء لامع"
- إيثان: صوت ذكوري يتميز بأنه "مشرق، متفائل" مع "طاقة معدية وفاعلية ودودة"
يضيف هذا التكامل بعدًا آخر لمرونة النموذج في التطبيقات العملية.
الاعتبارات التقنية للدمج
عند تنفيذ Qwen 2.5 Omni 7B، تحتاج بعض التفاصيل التقنية إلى الانتباه:
- يتطلب النموذج أنماط تحفيز محددة لمخرجات الصوت
- تعديلات متسقة لمعلمات
use_audio_in_videoضرورية للمحادثات التكرارية المناسبة - تعتمد توافقية عنوان URL للفيديو على إصدارات مكتبة محددة (torchvision ≥ 0.19.0 لدعم HTTPS)
- النموذج غير متاح حاليًا من خلال واجهة Hugging Face Inference API بسبب القيود في دعم النماذج "أي إلى أي"
مستقبل الذكاء الاصطناعي متعدد الأنماط
يمثل Qwen 2.5 Omni 7B أكثر من مجرد نموذج ذكاء اصطناعي آخر - إنه لمحة عن مستقبل الذكاء الاصطناعي. من خلال الجمع بين عدة أنماط حسية في بنية موحدة ومن الجهة إلى الجهة، يقرّبنا أكثر من أنظمة الذكاء الاصطناعي التي يمكن أن تدرك وتفاعل مع العالم بشكل يشبه البشر.
إن دمج TMRoPE لمحاذاة زمنية يحل تحديًا أساسيًا في المعالجة متعددة الأنماط، في حين توفر بنية المفكر-المتحدث إطارًا لتجميع المدخلات المختلفة بشكل فعال وتوليد المخرجات المناسبة. إن أدائه القوي عبر المعايير يُظهر أن النماذج متعددة الأنماط الموحدة قادرة على المنافسة وأحيانًا تجاوز نماذج الأحادية المتخصصة.
مع ازدياد إمكانية الوصول إلى الموارد الحوسبية وتحسين تقنيات نشر النموذج بكفاءة، يمكننا توقع رؤية اعتمادات أوسع على ذكاء اصطناعي متعدد الأنماط حقيقي مثل Qwen 2.5 Omni 7B. تمتد التطبيقات عبر كل صناعة تقريبًا - من الرعاية الصحية والتربية إلى الترفيه وخدمات العملاء.
الخلاصة
يعتبر Qwen 2.5 Omni 7B إنجازًا رائعًا في تطور الذكاء الاصطناعي متعدد الأنماط. لقد أثبتت قدراته الشاملة "Omni"، وبنيته المبتكرة، وأداءه المثير للإعجاب عبر الأنماط أنه نموذج رائد لجيل المستقبل من أنظمة الذكاء الاصطناعي.
من خلال الجمع بين القدرة على الرؤية، والسماع، والقراءة، والتحدث في نموذج موحد، يزيل Qwen 2.5 Omni 7B الحواجز التقليدية بين قدرات الذكاء الاصطناعي المختلفة. تمثل هذه الخطوة تقدمًا كبيرًا نحو إنشاء أنظمة ذكاء اصطناعي يمكنها التفاعل مع البشر وفهم العالم بطريقة أكثر طبيعية وبديهية.
بينما توجد قيود عملية يجب أخذها في الاعتبار، بما في ذلك متطلبات الأجهزة، فإن إنجازات النموذج تشير إلى مستقبل مثير حيث يمكن للذكاء الاصطناعي معالجة والرد بسلاسة على العالم الغني والمتعدد الأنماط الذي نعيش فيه. مع استمرار تطور هذه التقنيات وإمكانية الوصول إليها، يمكننا توقع تحول كيفية تفاعلنا مع التكنولوجيا عبر عدد لا يحصى من التطبيقات والمجالات.
لا يعتبر Qwen 2.5 Omni 7B مجرد إنجاز تقني - بل هو لمحة عن مستقبل حيث تبدأ الحدود بين أشكال التواصل المختلفة في الذوبان، مما يخلق طرقًا أكثر طبيعية وبديهية للتفاعل بين البشر والذكاء الاصطناعي.