
يستمر مجال الذكاء الاصطناعي في التطور بسرعة، مقدمًا نماذج مبتكرة تعيد تعريف الحدود الحاسوبية. ومن بين هذه التطورات، يبرز MiniMax-M1 كإنجاز رائد، محتلًا مكانته كأول نموذج استدلال بالاهتمام الهجين واسع النطاق مفتوح الوزن في العالم. تم تطوير هذا النموذج بواسطة MiniMax، ويعد بتحويل طريقة تعاملنا مع مهام الاستدلال المعقدة، مقدمًا نافذة سياق إدخال مذهلة تبلغ مليون رمز ونافذة سياق إخراج تبلغ 80,000 رمز.
فهم البنية الأساسية لـ MiniMax-M1
يتميز MiniMax-M1 ببنيته الفريدة من نوعها من مزيج الخبراء الهجين (MoE)، جنبًا إلى جنب مع آلية اهتمام سريعة البرق. يبني هذا التصميم على الأساس الذي وضعه سلفه، MiniMax-Text-01، والذي يتميز بـ 456 مليار معلمة مذهلة، مع تنشيط 45.9 مليار لكل رمز. يتيح نهج MoE للنموذج تنشيط مجموعة فرعية فقط من معلماته بناءً على المدخلات، مما يحسن الكفاءة الحاسوبية ويمكّن من قابلية التوسع. وفي الوقت نفسه، تعزز آلية الاهتمام الهجين قدرة النموذج على معالجة بيانات السياق الطويل، مما يجعله مثاليًا للمهام التي تتطلب فهمًا عميقًا على مدى تسلسلات ممتدة.

يؤدي دمج هذه المكونات إلى نموذج يوازن بين الأداء واستخدام الموارد بفعالية. من خلال إشراك الخبراء بشكل انتقائي ضمن إطار MoE، يقلل MiniMax-M1 من الحمل الحسابي المرتبط عادةً بالنماذج واسعة النطاق. علاوة على ذلك، تعمل آلية الاهتمام السريع على تسريع معالجة أوزان الاهتمام، مما يضمن أن النموذج يحافظ على إنتاجية عالية حتى مع نافذة سياقه الواسعة.
كفاءة التدريب: دور التعلم المعزز
أحد الجوانب الأكثر إثارة للإعجاب في MiniMax-M1 هو عملية تدريبه، التي تستفيد من التعلم المعزز واسع النطاق (RL) بكفاءة غير مسبوقة. تم تدريب النموذج بتكلفة 534,700 دولار فقط، وهو رقم يؤكد إطار عمل توسيع نطاق التعلم المعزز المبتكر الذي طورته MiniMax. يقدم هذا الإطار CISPO (Clipped Importance Sampling with Policy Optimization)، وهي خوارزمية جديدة تقوم بقص أوزان أخذ العينات الهامة بدلاً من تحديثات الرمز. يتفوق هذا النهج على متغيرات التعلم المعزز التقليدية، مما يوفر عملية تدريب أكثر استقرارًا وفعالية.

بالإضافة إلى ذلك، يلعب تصميم الاهتمام الهجين دورًا حاسمًا في تعزيز كفاءة التعلم المعزز. من خلال معالجة التحديات الفريدة المرتبطة بتوسيع نطاق التعلم المعزز ضمن بنية هجينة، يحقق MiniMax-M1 مستوى من الأداء ينافس النماذج ذات الوزن المغلق، على الرغم من طبيعته مفتوحة المصدر. لا تقلل منهجية التدريب هذه التكاليف فحسب، بل تحدد أيضًا معيارًا جديدًا لتطوير نماذج الذكاء الاصطناعي عالية الأداء بموارد محدودة.
مقاييس الأداء: تقييم أداء MiniMax-M1
لتقييم قدرات MiniMax-M1، أجرى المطورون اختبارات أداء واسعة النطاق عبر مجموعة من المهام، بما في ذلك الرياضيات على مستوى المنافسة، والترميز، وهندسة البرمجيات، واستخدام الأدوات الوكيلية، وفهم السياق الطويل. تسلط النتائج الضوء على تفوق النموذج على النماذج مفتوحة الوزن الأخرى مثل DeepSeek-R1 و Qwen3-235B-A22B.
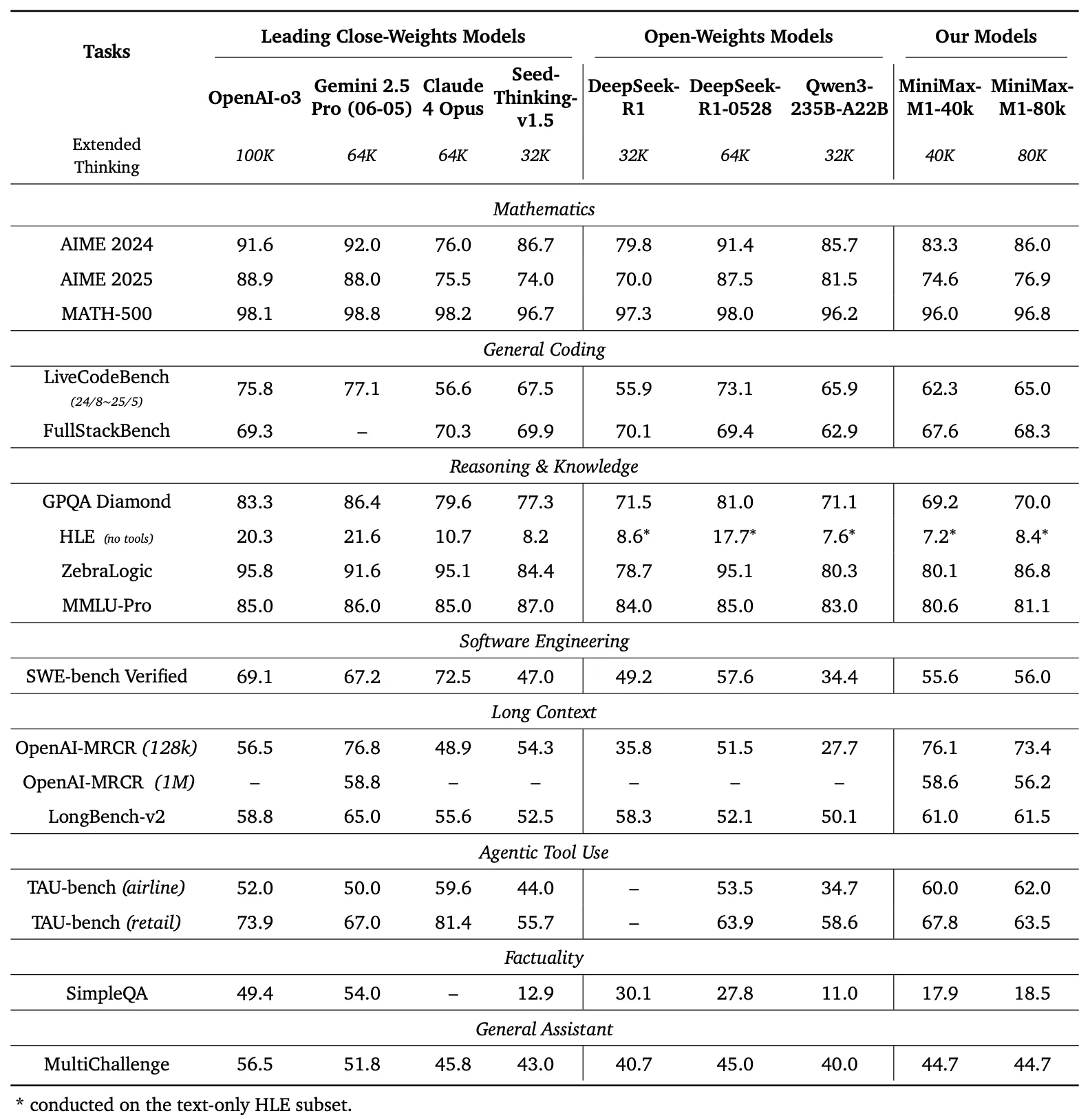
مقارنة المعايير
يقارن اللوحة اليسرى من الشكل 1 أداء MiniMax-M1 مقابل النماذج التجارية ومفتوحة الوزن الرائدة عبر العديد من المعايير

- AIME 2024: يحقق MiniMax-M1 دقة 86.0%، متجاوزًا OpenAI o3 (88.0%) و Claude 4 Opus (80.0%)، مما يدل على براعته في الاستدلال الرياضي.
- LiveCodeBench: بنتيجة 65.0%، يتفوق MiniMax-M1 على DeepSeek-R1-0528 (56.0%) ويطابق أداء Seed-Thinking v1.5 (65.0%)، مما يشير إلى قدرات ترميز قوية.
- SW-E Bench Verified: يحقق النموذج 62.8%، متفوقًا على Qwen3-235B-A22B (60.0%) في مهام هندسة البرمجيات.
- TAU-bench: يسجل MiniMax-M1 دقة 73.4%، متجاوزًا Gemini 2.5 Pro (70.0%) في استخدام الأدوات الوكيلية.
- MRCR (4-needle): بدقة 74.4%، يتصدر على النماذج الأخرى في مهام فهم السياق الطويل.
تؤكد هذه النتائج على تعدد استخدامات MiniMax-M1 وقدرته على المنافسة مع النماذج الاحتكارية، مما يجعله أصلًا قيمًا للمجتمعات مفتوحة المصدر.

يظهر MiniMax-M1 زيادة خطية في FLOPs (عمليات النقطة العائمة) مع امتداد طول التوليد من 32 ألف إلى 128 ألف رمز. تضمن هذه القابلية للتوسع أن النموذج يحافظ على الكفاءة والأداء حتى مع المخرجات الممتدة، وهو عامل حاسم للتطبيقات التي تتطلب استجابات مفصلة وطويلة.
الاستدلال بالسياق الطويل: حدود جديدة
أكثر ميزة مميزة في MiniMax-M1 هي نافذة السياق فائقة الطول، التي تدعم ما يصل إلى مليون رمز إدخال و 80,000 رمز إخراج. تتيح هذه القدرة للنموذج معالجة كميات هائلة من البيانات - ما يعادل رواية كاملة أو سلسلة من الكتب - في تمريرة واحدة، متجاوزة بكثير حد 128,000 رمز لنماذج مثل GPT-4 من OpenAI. يقدم النموذج وضعين للاستدلال - ميزانيات فكرية 40 ألف و 80 ألف - لتلبية احتياجات السيناريوهات المتنوعة وتمكين النشر المرن.

تعزز نافذة السياق الممتدة هذه أداء النموذج في مهام السياق الطويل، مثل تلخيص المستندات الطويلة، وإجراء محادثات متعددة الأدوار، أو تحليل مجموعات البيانات المعقدة. من خلال الاحتفاظ بالمعلومات السياقية على مدى ملايين الرموز، يوفر MiniMax-M1 أساسًا قويًا للتطبيقات في البحث، والتحليل القانوني، وتوليد المحتوى، حيث يكون الحفاظ على التماسك على مدى تسلسلات طويلة أمرًا بالغ الأهمية.
استخدام الأدوات الوكيلية والتطبيقات العملية
بالإضافة إلى نافذة سياقه المذهلة، يتفوق MiniMax-M1 في استخدام الأدوات الوكيلية، وهو مجال تتفاعل فيه نماذج الذكاء الاصطناعي مع أدوات خارجية لحل المشكلات. قدرة النموذج على الاندماج مع منصات مثل MiniMax Chat وتوليد تطبيقات ويب وظيفية - مثل اختبارات سرعة الكتابة ومولدات المتاهة - تثبت فائدته العملية. تعرض هذه التطبيقات، التي تم بناؤها بأقل قدر من الإعداد وبدون إضافات، قدرة النموذج على إنتاج كود جاهز للإنتاج.

على سبيل المثال، يمكن للنموذج توليد تطبيق ويب نظيف ووظيفي لتتبع الكلمات في الدقيقة (WPM) في الوقت الفعلي أو إنشاء مولد متاهة جذاب بصريًا مع تصور خوارزمية A*. تضع هذه القدرات MiniMax-M1 كأداة قوية للمطورين الذين يسعون إلى أتمتة سير عمل تطوير البرمجيات أو إنشاء تجارب مستخدم تفاعلية.
إمكانية الوصول مفتوحة المصدر وتأثير المجتمع
يمثل إصدار MiniMax-M1 بموجب ترخيص Apache 2.0 علامة فارقة هامة للمجتمع مفتوح المصدر. يتوفر النموذج على GitHub و Hugging Face، ويدعو المطورين والباحثين والشركات لاستكشافه وتعديله ونشره دون قيود احتكارية. تعزز هذه الانفتاح الابتكار، مما يتيح إنشاء حلول مخصصة مصممة لتلبية احتياجات محددة.
كما تضفي إمكانية الوصول إلى النموذج طابعًا ديمقراطيًا على الوصول إلى تقنية الذكاء الاصطناعي المتقدمة، مما يسمح للمنظمات الصغيرة والمطورين المستقلين بالمنافسة مع الكيانات الأكبر. من خلال توفير وثائق مفصلة وتقرير فني، تضمن MiniMax أن المستخدمين يمكنهم تكرار وتوسيع قدرات النموذج، مما يزيد من تسريع التطورات في نظام الذكاء الاصطناعي البيئي.
التنفيذ التقني: النشر والتحسين
يتطلب نشر MiniMax-M1 دراسة متأنية للموارد الحاسوبية وتقنيات التحسين. يوصي التقرير الفني باستخدام vLLM (Virtual Large Language Model) للنشر في الإنتاج، والذي يحسن سرعة الاستدلال واستخدام الذاكرة. تستفيد هذه الأداة من بنية النموذج الهجينة لتوزيع الحمل الحسابي بكفاءة، مما يضمن التشغيل السلس حتى مع المدخلات واسعة النطاق.
يمكن للمطورين ضبط MiniMax-M1 بدقة لمهام محددة عن طريق تعديل ميزانية التفكير (40 ألف أو 80 ألف) بناءً على متطلباتهم. بالإضافة إلى ذلك، يتيح إطار عمل تدريب التعلم المعزز الفعال للنموذج مزيدًا من التخصيص من خلال التعلم المعزز، مما يتيح التكيف مع التطبيقات المتخصصة مثل الترجمة في الوقت الفعلي أو دعم العملاء الآلي.
الخلاصة: احتضان ثورة MiniMax-M1
يمثل MiniMax-M1 قفزة كبيرة إلى الأمام في عالم نماذج الاستدلال بالاهتمام الهجين واسعة النطاق مفتوحة الوزن. نافذة سياقه المذهلة، عملية تدريبه الفعالة، وأدائه المتفوق في المعايير تضعه في مكانة رائدة في مشهد الذكاء الاصطناعي. من خلال تقديم هذه التكنولوجيا كمورد مفتوح المصدر، تمكّن MiniMax المطورين والباحثين من استكشاف إمكانيات جديدة، من هندسة البرمجيات المتقدمة إلى تحليل السياق الطويل.
مع استمرار نمو مجتمع الذكاء الاصطناعي، يعمل MiniMax-M1 كشهادة على قوة الابتكار والتعاون. لأولئك المستعدين لاستكشاف إمكاناته، يوفر تنزيل Apidog مجانًا نقطة دخول عملية لتجربة هذا النموذج التحويلي. الرحلة مع MiniMax-M1 بدأت للتو، وتأثيره سيشكل بلا شك مستقبل الذكاء الاصطناعي.
