
صمم مهندسو Mistral AI نموذج Magistral Small 1.2 كنموذج يضم 24 مليار معلمة ويعطي الأولوية لكفاءة الاستدلال. يعتمد هذا الإصدار مباشرة على Mistral Small 1.1. طبق المهندسون الضبط الدقيق الموجه باستخدام آثار من Magistral Medium، متبوعًا بمراحل التعلم المعزز. ونتيجة لذلك، يتفوق النموذج في المنطق متعدد الخطوات دون متطلبات حسابية مفرطة.
فهم تطور عائلة نماذج Magistral
أساس البنية والمواصفات الفنية
يعتمد Magistral Small 1.2 على الأساس القوي لـ Magistral 1.1، ويدمج قدرات استدلال متقدمة من خلال الضبط الدقيق الموجه (SFT) من آثار Magistral Medium جنبًا إلى جنب مع تحسين التعلم المعزز (RL). بناءً على Magistral 1.1، مع قدرات استدلال إضافية، وخضوعه لـ SFT من آثار Magistral Medium وRL، فهو نموذج استدلال صغير وفعال يضم 24 مليار معلمة.

علاوة على ذلك، يتيح التصميم المعماري سيناريوهات نشر فعالة. يمكن نشر Magistral Small محليًا، ليتناسب مع بطاقة RTX 4090 واحدة أو جهاز MacBook بذاكرة وصول عشوائي (RAM) سعة 32 جيجابايت بمجرد تكميمه. تجعل هذه الإمكانية النموذج مناسبًا لكل من بيئات الشركات والمطورين الأفراد.
التحسينات التقنية الرئيسية في الإصدار 1.2
يقدم الانتقال من الإصدار 1.1 إلى 1.2 العديد من التحسينات الهامة التي تؤثر بشكل كبير على أداء النموذج وسهولة استخدامه. والأهم من ذلك، أن هذه التحديثات تعالج القيود الأساسية بينما توسع حدود القدرات.
طفرة التكامل متعدد الوسائط
أصبحت هذه النماذج، المزودة الآن بترميز رؤية، تتعامل مع النصوص والصور بسلاسة. يمثل هذا التكامل نقلة نوعية من الاستدلال القائم على النص فقط إلى فهم شامل متعدد الوسائط. تتيح بنية ترميز الرؤية للنماذج معالجة المعلومات المرئية مع الحفاظ على قدراتها في استدلال النصوص.
نتائج تحسين الأداء
تحسينات بنسبة 15% في معايير الرياضيات والبرمجة مثل AIME 24/25 و LiveCodeBench v5/v6. تترجم مكاسب الأداء هذه مباشرة إلى تطبيقات عملية، وتفيد بشكل خاص المطورين الذين يعملون في الحسابات الرياضية وتطوير الخوارزميات وسيناريوهات حل المشكلات المعقدة.
تحليل شامل للميزات
قدرات الاستدلال المتقدمة
تتضمن بنية الاستدلال رموز تفكير متخصصة تنظم عملية الاستدلال الداخلية للنموذج. يستخدم التنفيذ رمزي [THINK] و [/THINK] لتغليف محتوى الاستدلال، مما يخلق شفافية في عملية اتخاذ القرار للنموذج مع منع الارتباك أثناء معالجة المطالبات.
علاوة على ذلك، يعمل نظام الاستدلال من خلال سلاسل ممتدة من الاستنتاج المنطقي قبل توليد الاستجابات النهائية. يتيح هذا النهج للنموذج معالجة المشكلات المعقدة التي تتطلب تحليلًا متعدد الخطوات واشتقاقات رياضية واستنتاجات منطقية.
البنية التحتية لدعم اللغات المتعددة
تظهر النماذج دعمًا شاملاً للغات عبر عائلات لغوية متنوعة. تشمل اللغات المدعومة مناطق أوروبية وآسيوية وشرق أوسطية وجنوب آسيوية، بما في ذلك الإنجليزية والفرنسية والألمانية واليونانية والهندية والإندونيسية والإيطالية واليابانية والكورية والماليزية والنيبالية والبولندية والبرتغالية والرومانية والروسية والصربية والإسبانية والتركية والأوكرانية والفيتنامية والعربية والبنغالية والصينية والفارسية.
بالإضافة إلى ذلك، تضمن هذه القدرة اللغوية الشاملة إمكانية الوصول العالمية وتمكن المطورين من إنشاء تطبيقات تخدم الأسواق الدولية دون الحاجة إلى تطبيقات نموذجية منفصلة للغات مختلفة.
بنية معالجة الرؤية
يتيح دمج ترميز الرؤية تحليلًا واستدلالًا متطورين للصور. يعالج النموذج المحتوى المرئي ويجمعه مع المعلومات النصية لتوليد استجابات شاملة. تمتد هذه القدرة إلى ما هو أبعد من مجرد التعرف على الصور البسيط لتشمل الفهم السياقي والاستدلال المكاني وحل المشكلات البصرية.
معايير الأداء والتحليل المقارن
أداء الاستدلال الرياضي
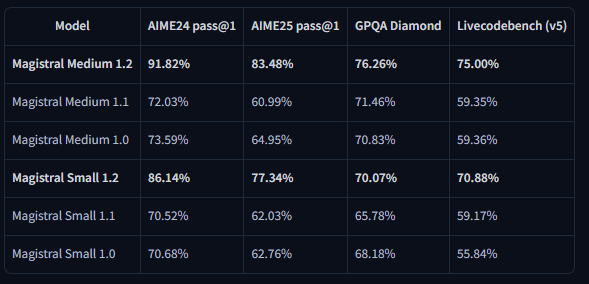
تظهر نتائج المعايير تحسينات كبيرة عبر مقاييس التقييم الرئيسية. يحقق Magistral Small 1.2 نسبة 86.14% في AIME24 pass@1 و 77.34% في AIME25 pass@1، مما يمثل تقدمًا كبيرًا على أداء الإصدار 1.1 الذي كان 70.52% و 62.03% على التوالي.
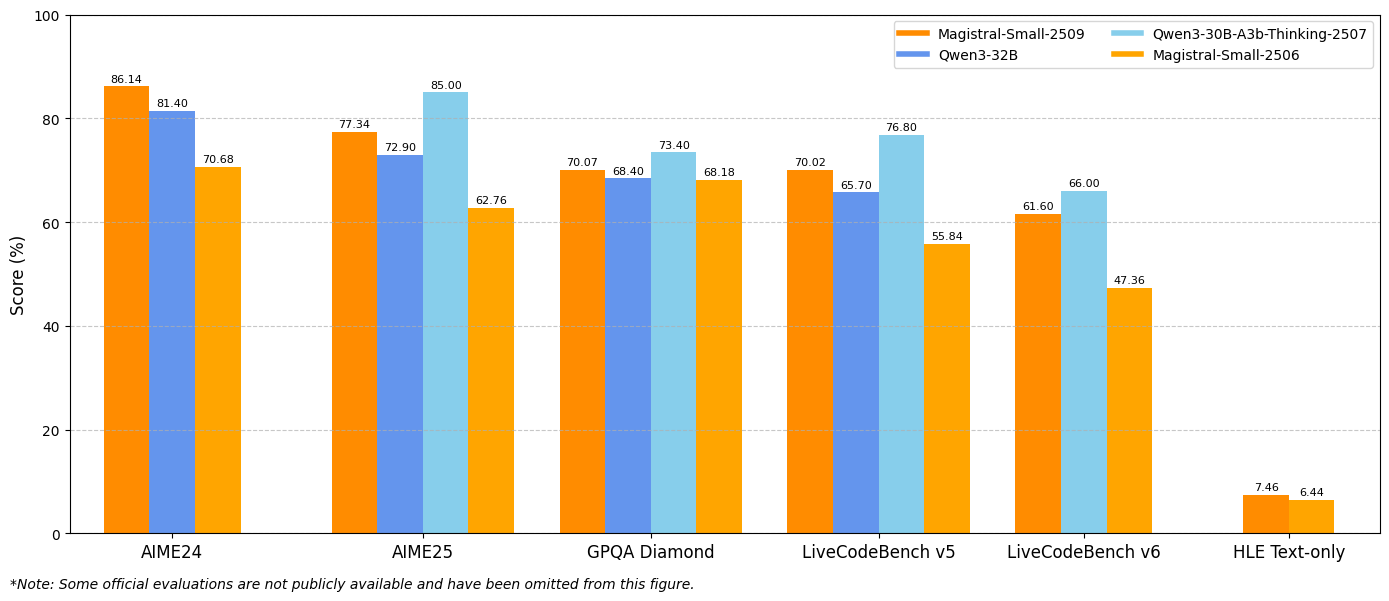
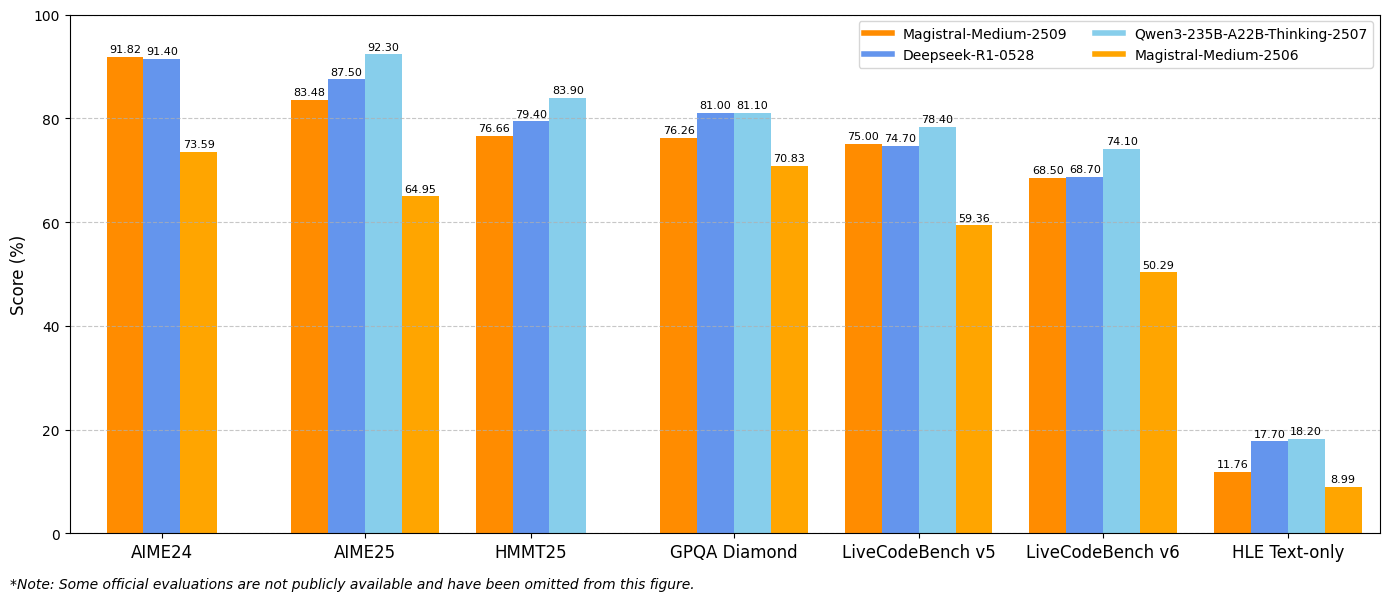
وبالمثل، يقدم Magistral Medium 1.2 أداءً استثنائيًا بنسبة 91.82% في AIME24 pass@1 و 83.48% في AIME25 pass@1، متجاوزًا أداء الإصدار 1.1 الذي كان 72.03% و 60.99%. تشير هذه التحسينات إلى قدرات استدلال رياضي معززة تفيد مباشرة الحوسبة العلمية والتطبيقات الهندسية وبيئات البحث.
مقاييس أداء البرمجة
تكشف تقييمات LiveCodeBench عن تحسينات كبيرة في قدرات البرمجة. يحقق Magistral Small 1.2 نسبة 70.88% في LiveCodeBench v5، بينما يحقق Magistral Medium 1.2 نسبة 75.00%. تمثل هذه الدرجات تقدمًا ذا مغزى في مهام توليد الكود وتصحيح الأخطاء وتطبيق الخوارزميات.
علاوة على ذلك، تُظهر النماذج فهمًا محسنًا لمفاهيم البرمجة وأنماط بنية البرامج ومنهجيات تصحيح الأخطاء. يفيد أداء البرمجة المحسن هذا فرق تطوير البرامج وأطر الاختبار الآلي وبيئات البرمجة التعليمية.
نتائج GPQA Diamond
تُظهر نتائج معيار GPQA Diamond (الإجابة على الأسئلة ذات الأغراض العامة) قدرات النماذج الواسعة في تطبيق المعرفة. يحقق Magistral Small 1.2 نسبة 70.07%، بينما يصل Magistral Medium 1.2 إلى 76.26%. تعكس هذه الدرجات قدرة النماذج على التعامل مع أنواع الأسئلة المتنوعة التي تتطلب معرفة واستدلالًا متعدد التخصصات.
استراتيجيات التنفيذ والتكامل
تكوين بيئة التطوير
يتطلب تنفيذ Magistral Small 1.2 و Magistral Medium 1.2 تكوينات تقنية محددة لتحسين الأداء. تتضمن معلمات أخذ العينات الموصى بها top_p: 0.95، و temperature: 0.7، و max_tokens: 131072. توازن هذه الإعدادات بين الإبداع والاتساق مع دعم تسلسلات الاستدلال الممتدة.
بالإضافة إلى ذلك، تدعم النماذج أطر عمل نشر متنوعة بما في ذلك vLLM و Transformers و llama.cpp وتنسيقات التكميم المتخصصة. تتيح هذه المرونة التكامل عبر بيئات الحوسبة المختلفة وحالات الاستخدام.
تكامل واجهة برمجة التطبيقات مع Apidog
Apidog يوفر أدوات شاملة لاختبار ودمج واجهات برمجة تطبيقات Magistral في تطبيقاتك. تدعم المنصة سيناريوهات اختبار واجهة برمجة التطبيقات المتقدمة، بما في ذلك معالجة المدخلات متعددة الوسائط، وتحليل مسار الاستدلال، ومراقبة الأداء. من خلال واجهة Apidog، يمكن للمطورين اختبار مجموعات الصور والنصوص بكفاءة، والتحقق من صحة مخرجات الاستدلال، وتحسين معلمات استدعاء واجهة برمجة التطبيقات.
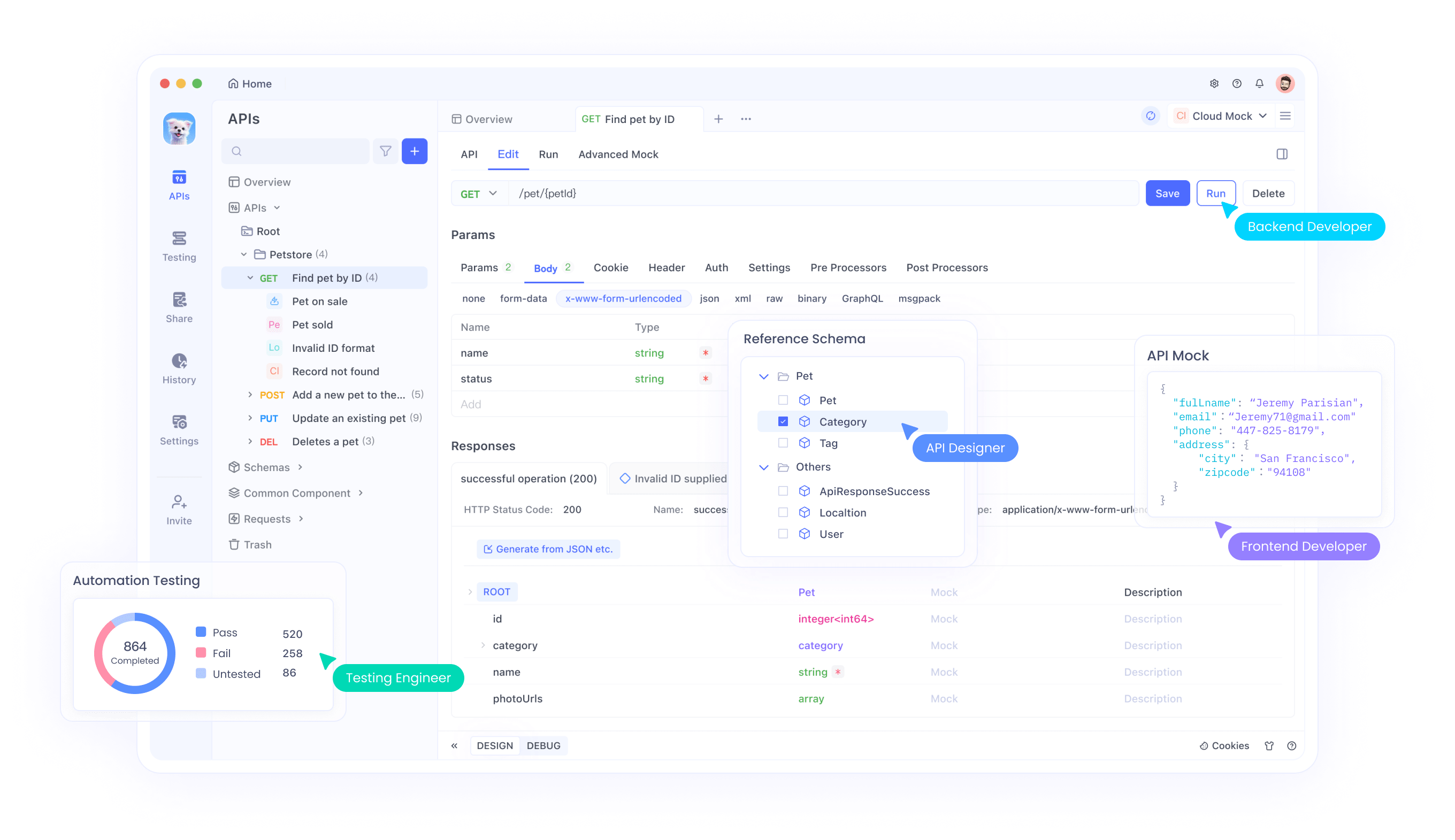
علاوة على ذلك، تتيح ميزات التعاون في Apidog للفرق مشاركة تكوينات اختبار واجهة برمجة التطبيقات، وتوثيق أنماط التكامل، والحفاظ على معايير اختبار متسقة عبر دورات التطوير. يسرع هذا النهج التعاوني الجداول الزمنية للتطوير مع ضمان تطبيقات واجهة برمجة تطبيقات قوية.
تحسين موجه النظام
تتطلب النماذج موجهات نظام مصممة بعناية لتحقيق الأداء الأمثل. يتضمن هيكل موجه النظام الموصى به تعليمات الاستدلال، وإرشادات التنسيق، ومواصفات اللغة. يجب أن يطلب الموجه صراحة عمليات التفكير باستخدام الرموز المتخصصة مع الحفاظ على تنسيق استجابة متسق.
علاوة على ذلك، يتيح تخصيص موجه النظام تحسينات خاصة بالتطبيق. يمكن للمطورين تعديل الموجهات للتأكيد على أنماط استدلال معينة، أو ضبط تنسيقات الإخراج، أو دمج متطلبات المعرفة الخاصة بالمجال.
تعمق في التنفيذ التقني
متطلبات الذاكرة والحوسبة
يعمل Magistral Small 1.2 بكفاءة ضمن بيئات الأجهزة المقيدة مع الحفاظ على الأداء العالي. تتيح بنية الـ 24 مليار معلمة النشر على الأجهزة الاستهلاكية عند تكميمها بشكل صحيح، مما يجعل قدرات الاستدلال المتقدمة متاحة للمطورين الأفراد والفرق الصغيرة.
علاوة على ذلك، تعمل تحسينات الكفاءة الحسابية في الإصدار 1.2 على تقليل زمن استجابة الاستدلال مع الحفاظ على جودة الاستدلال. يتيح هذا التحسين التطبيقات في الوقت الفعلي والأنظمة التفاعلية التي تتطلب توليد استجابات فورية.
نافذة السياق وقدرات المعالجة
تدعم النماذج نافذة سياق تبلغ 128,000 رمز، مما يتيح معالجة المستندات الشاملة والمحادثات المعقدة والمهام التحليلية واسعة النطاق. بينما قد يتدهور الأداء بعد 40,000 رمز، تحافظ النماذج على وظائف معقولة عبر نطاق السياق الكامل.
بالإضافة إلى ذلك، تتيح قدرة السياق الممتد تحليلًا شاملاً للمستندات، ومهام الاستدلال الطويلة، والمحادثات متعددة الأدوار مع الحفاظ على الوعي بالسياق. تدعم هذه القدرة تطبيقات المؤسسات التي تتطلب معالجة معلومات واسعة النطاق.
تقنيات التكميم والتحسين
تدعم النماذج تنسيقات تكميم مختلفة من خلال تطبيقات GGUF، مما يتيح النشر عبر تكوينات أجهزة مختلفة. تقلل هذه التحسينات من متطلبات الذاكرة مع الحفاظ على قدرات الاستدلال، مما يجعل النماذج متاحة في البيئات محدودة الموارد.
علاوة على ذلك، تحافظ تقنيات التحسين المتخصصة على سرعة الاستدلال مع دعم عمليات الاستدلال المعقدة. تضمن هذه التحسينات التقنية جدوى النشر العملي عبر بيئات الحوسبة المتنوعة.
الاختبار والتحقق باستخدام Apidog
استراتيجيات اختبار واجهة برمجة التطبيقات الشاملة
يوفر Apidog أدوات أساسية للتحقق من تكاملات نماذج Magistral من خلال أطر اختبار شاملة. تدعم المنصة اختبار المدخلات متعددة الوسائط، والتحقق من مسار الاستدلال، وقياس الأداء. يمكن للفرق إنشاء مجموعات اختبار تتحقق من كل من الصحة الوظيفية وخصائص الأداء.
تتيح إمكانيات الاختبار الآلي في Apidog سير عمل التكامل المستمر الذي يضمن اتساق أداء النموذج عبر دورات التطوير. يقلل هذا الأتمتة من عبء الاختبار اليدوي مع الحفاظ على معايير ضمان الجودة.
مراقبة الأداء والتحسين
من خلال إمكانيات مراقبة Apidog، يمكن لفرق التطوير تتبع مقاييس أداء واجهة برمجة التطبيقات، وتحديد فرص التحسين، والحفاظ على موثوقية الخدمة. توفر المنصة تحليلات مفصلة حول أوقات الاستجابة، وجودة الاستدلال، وأنماط استخدام الموارد.
علاوة على ذلك، تتيح بيانات المراقبة استراتيجيات تحسين استباقية تعمل على تحسين أداء التطبيق وتجربة المستخدم. يضمن هذا النهج القائم على البيانات الاستخدام الأمثل للنموذج عبر بيئات الإنتاج.
الخاتمة
يمثل Magistral Small 1.2 و Magistral Medium 1.2 تقدمًا كبيرًا في تكنولوجيا استدلال الذكاء الاصطناعي متعدد الوسائط. يخلق الجمع بين الأداء الرياضي المحسن، وقدرات الرؤية، وشفافية الاستدلال المحسنة أدوات قوية لتطبيقات متنوعة تتراوح من البحث العلمي إلى تطوير البرامج.
تعمل تحسينات إمكانية الوصول من خلال خيارات النشر المحلي ودعم واجهة برمجة التطبيقات الشامل على إضفاء الطابع الديمقراطي على الوصول إلى قدرات الاستدلال المتقدمة. يمكن للمؤسسات الآن دمج استدلال الذكاء الاصطناعي المتطور في سير عملها دون الحاجة إلى استثمارات واسعة في البنية التحتية.
سواء كنت تقوم بتطوير تطبيقات تعليمية، أو إجراء أبحاث علمية، أو بناء أنظمة برمجية معقدة، فإن Magistral Small 1.2 و Magistral Medium 1.2 يوفران قدرات الاستدلال الضرورية لتطبيقات الذكاء الاصطناعي من الجيل التالي. بالاقتران مع أدوات الاختبار والتكامل القوية مثل Apidog، تتيح هذه النماذج سير عمل تطوير شاملة تسرع الابتكار مع الحفاظ على معايير الجودة.