
يتقدم عالم نماذج اللغات الكبيرة (LLMs) بسرعة جنونية، لكن التحديات في الكفاءة والقدرة على التكيف في الوقت الفعلي لا تزال قائمة. في 10 سبتمبر 2025، أطلقت Moonshot AI—القوة الابتكارية وراء سلسلة Kimi—أداة checkpoint-engine، وهي برنامج وسيط مفتوح المصدر يعيد تعريف تحديثات الأوزان في محركات استدلال نماذج اللغات الكبيرة. صُممت هذه الأداة خفيفة الوزن خصيصًا للتعلم المعزز (RL)، ويمكنها تحديث نموذج عملاق بمليار معلمة مثل Kimi-K2 عبر آلاف وحدات معالجة الرسوميات (GPUs) في 20 ثانية فقط، مما يقلل من وقت التوقف ويعزز قابلية التوسع.
زر
تتعمق هذه المقالة في آليات checkpoint-engine، بدءًا من بنيتها وصولاً إلى معايير الأداء، مع تسليط الضوء على آثارها على التعلم المعزز (RL) وملاءمتها للنظام البيئي الأوسع. من خلال جعل هذه الجوهرة مفتوحة المصدر، تمكّن Moonshot AI المجتمع من دفع حدود نماذج اللغات الكبيرة إلى أبعد من ذلك. دعنا نستعرض هذا الابتكار طبقة تلو الأخرى.
فهم Checkpoint-Engine: المفاهيم الأساسية والبنية
ما هو Checkpoint-Engine؟
في جوهره، يعد checkpoint-engine برنامجًا وسيطًا يسهل تحديثات الأوزان بسلاسة وفي مكانها لنماذج اللغات الكبيرة أثناء الاستدلال. هذا أمر محوري في التعلم المعزز (RL)، حيث تتطور النماذج من خلال التغذية الراجعة التكرارية دون إعادة تدريب كاملة. تعمل الطرق التقليدية على إبطاء الأنظمة بعمليات إعادة تحميل طويلة؛ بينما يتصدى checkpoint-engine لذلك بنهج مبسط ومنخفض التكلفة.
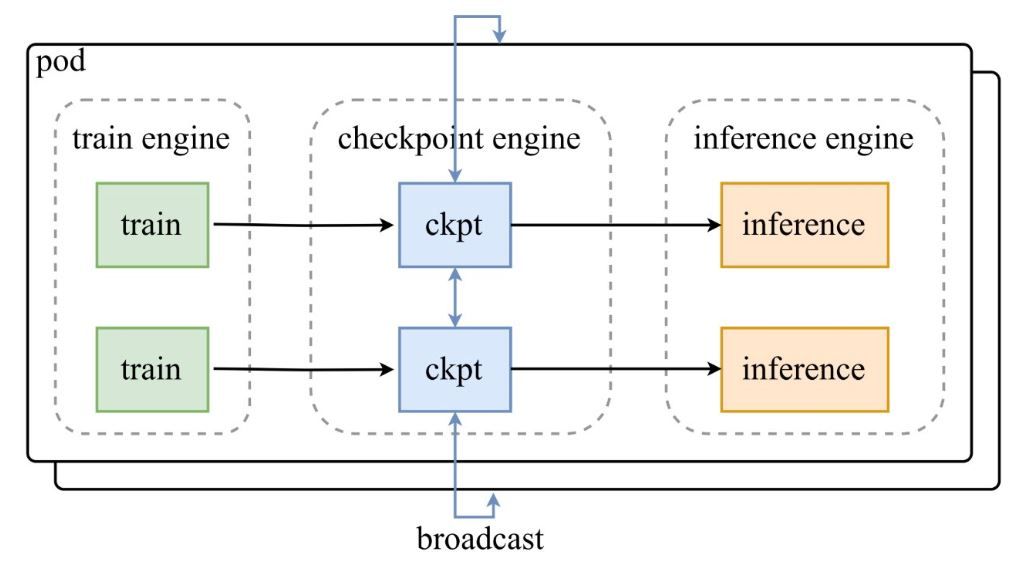
كما هو موضح في الرسم التخطيطي للبنية من تغريدة إعلان Moonshot AI، تقوم مجموعة من محركات التدريب بتغذية نقاط التفتيش إلى محرك checkpoint-engine المركزي، والذي يقوم بعد ذلك ببث التحديثات إلى محركات الاستدلال. يتعمق مستودع GitHub في الكود، ويسلط الضوء على فئة ParameterServer كمنسق للتحديثات.
المكونات المعمارية
- محرك التدريب: ينتج أوزانًا جديدة من تدريب التعلم المعزز (RL) المستمر، ويلتقط تحسينات السياسة في البيئات الديناميكية.
- محرك Checkpoint: هو جوهر البرنامج الوسيط، يتواجد مع الاستدلال لتقليل زمن الاستجابة. يتعامل مع جمع البيانات الوصفية وينفذ التحديثات عبر وضعي البث (Broadcast) أو الند للند (P2P).
- محرك الاستدلال: يدمج التحديثات أثناء التشغيل، ويحافظ على استمرارية الخدمة عبر مجموعات وحدات معالجة الرسوميات (GPU) الموزعة.
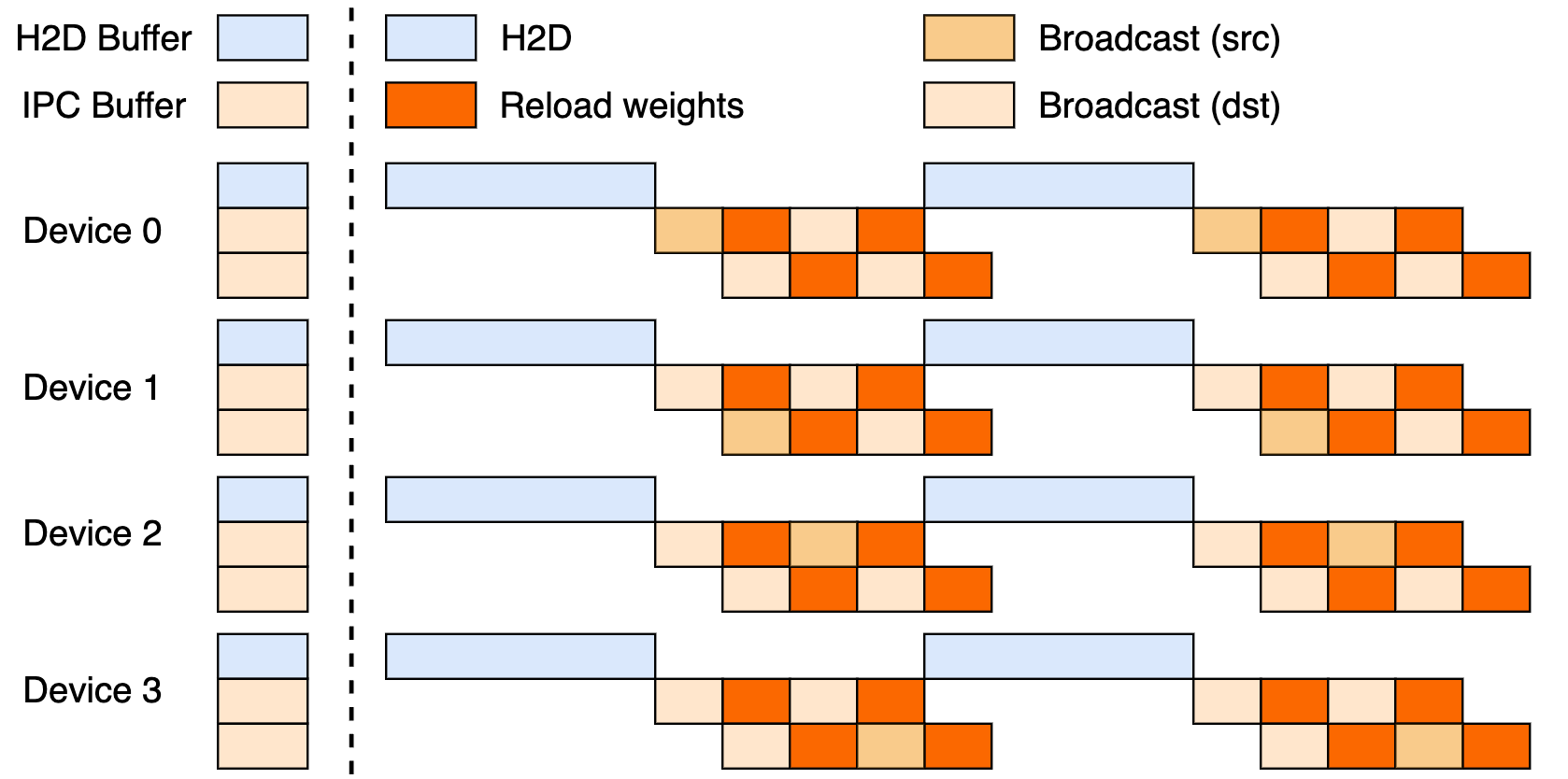
يستفيد هذا الإعداد من مسار ثلاثي المراحل: عمليات نقل من المضيف إلى الجهاز (H2D)، وعمليات بث بين العمال باستخدام CUDA IPC، وعمليات إعادة تحميل مستهدفة. من خلال تداخل هذه العمليات، فإنه يزيد من استخدام وحدة معالجة الرسوميات (GPU) ويحد من اختناقات النقل.
تحديثات البث (Broadcast) مقابل الند للند (P2P)
يتألق البث (Broadcast) في التحديثات المتزامنة على مستوى المجموعة—وهو وضعه الافتراضي لأقصى سرعة، حيث يقوم بتجميع البيانات لتدفق أمثل. في المقابل، يتفوق الند للند (P2P) في السيناريوهات المرنة، مثل التوسع أثناء الذروات، باستخدام RDMA عبر mooncake-transfer-engine لتجنب الاضطرابات. هذه الازدواجية تجعل checkpoint-engine متعدد الاستخدامات لكل من عمليات النشر المستقرة والمرنة.
معايير الأداء: ما مدى السرعة الكافية؟
تحديث نموذج بمليار معلمة في 20 ثانية
الإنجاز الرئيسي لـ checkpoint-engine؟ تحديث معلمة Kimi-K2 البالغة 1 تريليون عبر آلاف وحدات معالجة الرسوميات (GPUs) في حوالي 20 ثانية. ينبع هذا من التجميع الذكي للمراحل: يحدد تخطيط البيانات الوصفية أحجامًا فعالة للمجموعات، وتنسق مآخذ ZeroMQ عمليات النقل، وتخفي مراحل H2D/البث المتداخلة فترات التأخير.
قارن هذا بالتقنيات القديمة، التي قد تعطل الأنظمة لدقائق وسط عمليات نقل البيانات الضخمة. تحافظ فلسفة checkpoint-engine للتحديث في المكان على عمل الاستدلال بسلاسة، وهو مثالي لحاجة التعلم المعزز (RL) إلى التكيفات السريعة.
تحليل معايير الأداء
يكشف جدول معايير الأداء عن نتائج ممتازة عبر النماذج والإعدادات، تم اختبارها باستخدام vLLM v0.10.2rc1:
| النموذج | معلومات الجهاز | جمع البيانات الوصفية | تحديث (بث) | تحديث (ند للند) |
|---|---|---|---|---|
| GLM-4.5-Air (BF16) | 8xH800 TP8 | 0.17s | 3.94s (1.42GiB) | 8.83s (4.77GiB) |
| Qwen3-235B-A22B-Instruct-2507 (BF16) | 8xH800 TP8 | 0.46s | 6.75s (2.69GiB) | 16.47s (4.05GiB) |
| DeepSeek-V3.1 (FP8) | 16xH20 TP16 | 1.44s | 12.22s (2.38GiB) | 25.77s (3.61GiB) |
| Kimi-K2-Instruct (FP8) | 16xH20 TP16 | 1.81s | 15.45s (2.93GiB) | 36.24s (4.46GiB) |
| DeepSeek-V3.1 (FP8) | 256xH20 TP16 | 1.40s | 13.88s (2.54GiB) | 33.30s (3.86GiB) |
| Kimi-K2-Instruct (FP8) | 256xH20 TP16 | 1.88s | 21.50s (2.99GiB) | 34.49s (4.57GiB) |
يمكنك تكرار هذه النتائج عبر ملف examples/update.py في المستودع. تتطلب عمليات تشغيل FP8 تصحيحات vLLM، مما يؤكد الكفاءة على نطاق واسع.
الآثار المترتبة على التعلم المعزز
يزدهر التعلم المعزز (RL) بالتكرارات السريعة؛ تمكّن دورات checkpoint-engine التي تقل عن 20 ثانية حلقات التعلم المستمر، متجاوزة طرق الدفعات. يفتح هذا الباب أمام تطبيقات سريعة الاستجابة—من الوكلاء التكيفيين إلى روبوتات الدردشة المتطورة—حيث كل ثانية مهمة في ضبط السياسة.
التنفيذ الفني: الغوص في قاعدة الكود
إمكانية الوصول مفتوحة المصدر
يعمل إصدار Moonshot AI على GitHub على إضفاء الطابع الديمقراطي على أدوات التعلم المعزز (RL) النخبوية. يقوم ParameterServer بتثبيت التحديثات، موفرًا البث (Broadcast) (مشاركة CUDA IPC السريعة) والند للند (P2P) (RDMA للوافدين الجدد). أمثلة مثل update.py والاختبارات (test_update.py) تسهل عملية البدء.
تبدأ التوافقية مع vLLM (عبر امتدادات العاملين)، مع التخطيط لدمج SGLang لاحقًا. يشير المسار الجزئي ذو المراحل الثلاث إلى إمكانات غير مستغلة.
تقنيات التحسين
تشمل التقنيات الذكية الرئيسية ما يلي:
- تداخل المسارات (Pipelined Overlaps): تعمل الاتصالات والنسخ بشكل متزامن، مما يقلل الوقت الفعلي.
- تحسين التجميع (Bucket Optimization): يتم ضبط الحجم المدفوع بالبيانات الوصفية ليتناسب مع التجزئة والشبكات.
- تحكم ZeroMQ: إشارات منخفضة التأخير إلى محركات الاستدلال.
تتعامل هذه التقنيات مع عقبات المعلمات التريليونية، من تعارضات PCIe إلى ضغوط الذاكرة (مع الرجوع إلى التسلسل إذا لزم الأمر).
القيود الحالية
يمكن أن تختنق قناة P2P ذات الرتبة 0 عند التوسع، ولا يزال المسار الكامل ينتظر التحسين. يحد التركيز على vLLM من النطاق، لكن التصحيحات تسد فجوات FP8 لنماذج مثل DeepSeek-V3.1. راقب المستودع للتطورات.
التكامل مع الأطر الحالية: vLLM وما بعدها
التعاون مع vLLM
يتكامل checkpoint-engine بشكل أصلي مع PagedAttention الخاص بـ vLLM لاستدلال التعلم المعزز (RL) السلس. يحقق هذا الثنائي تزامنًا لمدة 20 ثانية على نماذج 1T، كما تم الإشارة إليه في تحديثات vLLM—إشارة إلى التعاون المفتوح الذي يعزز الإنتاجية.
الامتدادات المحتملة إلى Claude و Apidog
يمكن أن يؤدي التوسع ليشمل Claude من Anthropic إلى إضفاء ديناميكية التعلم المعزز (RL) على محادثاته التي تركز على السلامة، مما يتيح التعديلات الدقيقة المباشرة. يتناسب Apidog تمامًا لمحاكاة نقاط النهاية أثناء تعديلات ZeroMQ—قم بتنزيل Apidog مجانًا لإنشاء نماذج أولية لهذه الجسور بسهولة.
تأثير النظام البيئي الأوسع
يمكن أن يؤدي التوصيل بـ Ollama أو LM Studio إلى توطين قوة المعلمات التريليونية، مما يمهد الطريق للمطورين المستقلين. يعزز هذا التأثير المتتالي مشهدًا أكثر شمولاً للذكاء الاصطناعي.
الآفاق المستقبلية: ماذا يخبئ المستقبل لـ Checkpoint-Engine؟
تحسينات قابلية التوسع والأداء
يمكن أن يوفر إطلاق المسار الكامل ثوانٍ إضافية، بينما يلغي اللامركزية في P2P الاختناقات لتحقيق مرونة حقيقية. تعد تعديلات RDMA ببراعة أصلية سحابية.
مساهمات المجتمع
يدعو المصدر المفتوح إلى الإصلاحات والمنافذ—فكر في دمج SGLang أو الأوضاع المستقلة عن PCIe. تزدحم الردود المبكرة على التغريدة بالحماس، مما يغذي الزخم.
التطبيقات الصناعية
من الترجمة في الوقت الفعلي إلى التعلم المعزز للقيادة الذاتية، يناسب checkpoint-engine المجالات كثيرة التغير. تحافظ سرعته على حداثة النماذج، متفوقة على المنافسين في المرونة.
عصر جديد لاستدلال نماذج اللغات الكبيرة (LLM)؟
يبشر checkpoint-engine بمستقبل مرن لنماذج اللغات الكبيرة (LLM)، حيث يعالج مشاكل الأوزان ببراعة المصدر المفتوح. إن تحديث 1 تريليون معلمة في 20 ثانية، مدعومًا ببنية ذكية ومعايير أداء، يرسخ مكانته في التعلم المعزز (RL)—بغض النظر عن القيود.
اقرنه بـ Apidog لسير عمل المطورين أو Claude للذكاء الهجين، وسيرتفع الابتكار. تابع GitHub، واحصل على Apidog مجانًا، وانضم إلى الثورة التي تعيد تشكيل الاستدلال اليوم!
زر