

هل رغبت يومًا في تشغيل نماذج رؤية الذكاء الاصطناعي المتطورة مباشرة على جهازك الخاص، دون الاعتماد على خدمات السحابة المكلفة أو القلق بشأن خصوصية البيانات؟ حسنًا، أنت محظوظ! اليوم، سنتعمق في كيفية تشغيل نماذج Qwen 3 VL (الرؤية واللغة) محليًا باستخدام Ollama وثق بي، هذا سيغير قواعد اللعبة لسير عمل تطوير الذكاء الاصطناعي الخاص بك.
الآن، قبل أن ننتقل إلى الأمور التقنية، اسمح لي أن أسألك شيئًا: هل سئمت من الوصول إلى حدود معدل واجهة برمجة التطبيقات (API)، ودفع تكاليف باهظة للاستدلال السحابي، أو ببساطة تريد مزيدًا من التحكم في نماذج الذكاء الاصطناعي الخاصة بك؟ إذا أومأت برأسك بالإيجاب، فهذا الدليل مصمم خصيصًا لك. علاوة على ذلك، إذا كنت تبحث عن أداة قوية لاختبار وتصحيح أخطاء واجهات برمجة تطبيقات الذكاء الاصطناعي المحلية الخاصة بك، فإنني أوصي بشدة بتنزيل Apidog مجانًا، إنها منصة ممتازة لاختبار واجهات برمجة التطبيقات تعمل بسلاسة مع نقاط النهاية المحلية لـ Ollama.
في هذا الدليل، سنتناول كل ما تحتاجه لتشغيل نماذج Qwen 3 VL محليًا باستخدام Ollama، بدءًا من التثبيت وحتى الاستدلال، واستكشاف الأخطاء وإصلاحها، وحتى التكامل مع أدوات مثل Apidog. بنهاية هذا الدليل الشامل، سيكون لديك Qwen3-VL للرؤية واللغة يعمل بكامل طاقته، وبشكل خاص، وسريع الاستجابة على جهازك المحلي، وستكون مجهزًا بكل المعرفة التي تحتاجها لدمجه في مشاريعك.
لذا، استعد، احضر مشروبك المفضل، ودعنا نبدأ هذه الرحلة المثيرة معًا.
فهم Qwen3-VL: نموذج الرؤية واللغة الثوري

لماذا Qwen 3 VL؟ ولماذا تشغيله محليًا؟
قبل أن ننتقل إلى الخطوات التقنية، دعنا نتحدث عن أهمية Qwen 3 VL ولماذا يعتبر تشغيله محليًا أمرًا يغير قواعد اللعبة.
Qwen 3 VL هو جزء من سلسلة Qwen من Alibaba، ولكنه مصمم خصيصًا لمهام الرؤية واللغة. على عكس نماذج اللغة الكبيرة التقليدية التي تفهم النص فقط، يمكن لـ Qwen 3 VL:
- تحليل الصور والإجابة على الأسئلة المتعلقة بها ("ماذا يوجد في هذه الصورة؟")
- إنشاء تسميات توضيحية مفصلة
- استخراج البيانات المنظمة من الرسوم البيانية أو المخططات أو المستندات
- دعم RAG متعدد الوسائط (التوليد المعزز بالاسترجاع) مع سياق بصري
ولأنه مفتوح الوزن (بموجب ترخيص Tongyi Qianwen)، يمكن للمطورين استخدامه وتعديله ونشره بحرية طالما أنهم يلتزمون بشروط الترخيص.
الآن، لماذا تشغيله محليًا؟
- الخصوصية: صورك ومطالباتك لا تغادر جهازك أبدًا.
- التكلفة: لا توجد رسوم واجهة برمجة تطبيقات أو حدود استخدام.
- التخصيص: الضبط الدقيق، التكميم، أو التكامل مع خطوط الأنابيب الخاصة بك.
- الوصول دون اتصال: مثالي للبيئات الآمنة أو المعزولة عن الشبكة.
لكن النشر المحلي كان يعني في السابق الصراع مع إصدارات CUDA وبيئات Python وملفات Dockerfile الضخمة. هنا يأتي دور Ollama.
متغيرات النموذج: شيء لكل حالة استخدام
يأتي Qwen3-VL بأحجام مختلفة لتناسب تكوينات الأجهزة المختلفة وحالات الاستخدام. سواء كنت تعمل على جهاز كمبيوتر محمول خفيف الوزن أو لديك وصول إلى محطة عمل قوية، هناك نموذج Qwen3-VL يناسب احتياجاتك تمامًا.
النماذج الكثيفة (البنية التقليدية):
- Qwen3-VL-2B: مثالي للأجهزة الطرفية وتطبيقات الهاتف المحمول
- Qwen3-VL-4B: توازن رائع بين الأداء واستخدام الموارد
- Qwen3-VL-8B: ممتاز للمهام العامة ذات التفكير المعتدل
- Qwen3-VL-32B: مهام عالية المستوى تتطلب تفكيرًا قويًا وسياقًا واسعًا
نماذج مزيج الخبراء (MoE) (البنية الفعالة):
- Qwen3-VL-30B-A3B: أداء فعال مع 3 مليارات معلمة نشطة فقط
- Qwen3-VL-235B-A22B: تطبيقات واسعة النطاق مع إجمالي 235 مليار معلمة ولكن 22 مليار معلمة نشطة فقط
جمال نماذج MoE هو أنها تنشط مجموعة فرعية فقط من الشبكات العصبية "الخبيرة" لكل استدلال، مما يسمح بأعداد هائلة من المعلمات مع الحفاظ على تكاليف الحوسبة قابلة للإدارة.
Ollama: بوابتك إلى تميز الذكاء الاصطناعي المحلي
الآن بعد أن فهمنا ما يقدمه Qwen3-VL، دعنا نتحدث عن سبب كون Ollama هي المنصة المثالية لتشغيل هذه النماذج محليًا. فكر في Ollama كقائد أوركسترا - فهو ينسق جميع العمليات المعقدة التي تحدث خلف الكواليس حتى تتمكن من التركيز على الأهم: استخدام نماذج الذكاء الاصطناعي الخاصة بك.
ما هو Ollama ولماذا هو مثالي لـ Qwen 3 VL
Ollama هي أداة مفتوحة المصدر تتيح لك تشغيل نماذج لغوية كبيرة (والآن، نماذج متعددة الوسائط) محليًا بأمر واحد. فكر فيها على أنها "Docker لنماذج اللغة الكبيرة" ولكن أبسط.
الميزات الرئيسية:
- تسريع تلقائي لوحدة معالجة الرسوميات (عبر Metal على macOS، CUDA على Linux)
- مكتبة نماذج مدمجة (بما في ذلك Llama 3، Mistral، Gemma، والآن Qwen)
- واجهة برمجة تطبيقات REST للتكامل السهل
- خفيف الوزن وسهل الاستخدام للمبتدئين
الأفضل من ذلك كله، يدعم Ollama الآن نماذج Qwen 3 VL، بما في ذلك المتغيرات مثل qwen3-vl:4b و qwen3-vl:8b. هذه إصدارات مكممة ومحسّنة للأجهزة المحلية، مما يعني أنه يمكنك تشغيلها على وحدات معالجة رسوميات من الفئة الاستهلاكية أو حتى أجهزة الكمبيوتر المحمولة القوية.
اللمسة التقنية السحرية وراء Ollama
ماذا يحدث خلف الكواليس عندما تقوم بتشغيل أمر Ollama؟ إنه مثل مشاهدة رقصة متقنة التنسيق من العمليات التكنولوجية:
1.تنزيل النموذج والتخزين المؤقت: يقوم Ollama بتنزيل أوزان النموذج وتخزينها مؤقتًا بذكاء، مما يضمن أوقات بدء تشغيل سريعة للنماذج المستخدمة بشكل متكرر.
2.تحسين التكميم: يتم تحسين النماذج تلقائيًا لتكوين جهازك، واختيار أفضل طريقة تكميم (4 بت، 8 بت، إلخ) لوحدة معالجة الرسوميات والذاكرة العشوائية لديك.
3.إدارة الذاكرة: تضمن تقنيات تعيين الذاكرة المتقدمة الاستخدام الفعال لذاكرة وحدة معالجة الرسوميات مع الحفاظ على الأداء العالي.
4.المعالجة المتوازية: يستفيد Ollama من نوى وحدة المعالجة المركزية المتعددة وتدفقات وحدة معالجة الرسوميات لتحقيق أقصى قدر من الإنتاجية.
المتطلبات الأساسية: ما ستحتاجه قبل التثبيت
قبل أن نقوم بتثبيت أي شيء، دعنا نتأكد من أن نظامك جاهز.
متطلبات الأجهزة
- ذاكرة الوصول العشوائي (RAM): 16 جيجابايت على الأقل (يوصى بـ 32 جيجابايت لنماذج 8B)
- وحدة معالجة الرسوميات (GPU): وحدة معالجة رسوميات NVIDIA بذاكرة VRAM تبلغ 8 جيجابايت أو أكثر (لنظام Linux) أو جهاز Mac بمعالج Apple Silicon (M1/M2/M3 بذاكرة موحدة تبلغ 16 جيجابايت أو أكثر)
- التخزين: 10-20 جيجابايت من المساحة الحرة (النماذج كبيرة!)
متطلبات البرمجيات
- نظام التشغيل: macOS (12+) أو Linux (يوصى بـ Ubuntu 20.04+)
- Ollama: أحدث إصدار (v0.1.40+ لدعم Qwen 3 VL)
- اختياري: Docker (إذا كنت تفضل النشر في حاويات)، Python (للكتابة المتقدمة للنصوص)
دليل التثبيت خطوة بخطوة: طريقك إلى إتقان الذكاء الاصطناعي المحلي
الخطوة 1: تثبيت Ollama - الأساس
دعنا نبدأ بأساس إعدادنا بالكامل. تثبيت Ollama بسيط بشكل مدهش - إنه مصمم ليكون متاحًا للجميع، من مبتدئي الذكاء الاصطناعي إلى المطورين المتمرسين.
لمستخدمي macOS:
1. قم بزيارة ollama.com/download
2. قم بتنزيل مثبت macOS
3. افتح الملف الذي تم تنزيله واسحب Ollama إلى مجلد التطبيقات الخاص بك
4. قم بتشغيل Ollama من مجلد التطبيقات الخاص بك أو بحث Spotlight
عملية التثبيت سلسة بشكل لا يصدق على macOS، وسترى أيقونة Ollama تظهر في شريط القائمة بمجرد اكتمال التثبيت.
لمستخدمي Windows:
1. انتقل إلى ollama.com/download
2. قم بتنزيل مثبت Windows (ملف .exe)
3. قم بتشغيل المثبت بامتيازات المسؤول
4. اتبع معالج التثبيت (إنه بديهي للغاية)
5. بمجرد التثبيت، سيبدأ Ollama تلقائيًا في الخلفية
قد يرى مستخدمو Windows إشعارًا من Windows Defender - لا تقلق، هذا أمر طبيعي للتشغيل الأول. ما عليك سوى النقر على "السماح" وسيعمل Ollama بشكل مثالي.
لمستخدمي Linux:
لدى مستخدمي Linux خياران:
الخيار أ: نص التثبيت (موصى به)
bash
curl -fsSL <https://ollama.com/install.sh> | sh
الخيار ب: التثبيت اليدوي
bash
# Download the latest Ollama binarycurl -o ollama <https://ollama.com/download/ollama-linux-amd64>
# Make it executablechmod +x ollama
# Move to PATHsudo mv ollama /usr/local/bin/
الخطوة 2: التحقق من التثبيت الخاص بك
الآن بعد أن تم تثبيت Ollama، دعنا نتأكد من أن كل شيء يعمل بشكل صحيح. فكر في هذا كاختبار دخان لضمان أن أساسنا متين.
افتح الطرفية (أو موجه الأوامر على Windows) وقم بتشغيل:
bash
ollama --version
يجب أن ترى إخراجًا مشابهًا لما يلي:
ollama version is 0.1.0
بعد ذلك، دعنا نختبر الوظائف الأساسية:
bash
ollama serve
يبدأ هذا الأمر خادم Ollama. يجب أن ترى إخراجًا يشير إلى أن الخادم يعمل على http://localhost:11434. دع الخادم يعمل - سنستخدمه لاختبار تثبيت Qwen3-VL الخاص بنا.
الخطوة 3: سحب وتشغيل نماذج Qwen3-VL
الآن للجزء المثير! دعنا نقوم بتنزيل وتشغيل أول نموذج Qwen3-VL. سنبدأ بنموذج أصغر لاختبار الأمور، ثم ننتقل إلى متغيرات أكثر قوة.
الاختبار باستخدام Qwen3-VL-4B (نقطة بداية رائعة):
bash
ollama run qwen3-vl:4b
سيقوم هذا الأمر بما يلي:
1. تنزيل نموذج Qwen3-VL-4B (حوالي 2.8 جيجابايت)
2. تحسينه لجهازك
3. بدء جلسة دردشة تفاعلية
تشغيل متغيرات النموذج الأخرى:
إذا كان لديك أجهزة أقوى، جرب هذه البدائل:
bash
# For 8GB+ GPU systemsollama run qwen3-vl:8b
# For 16GB+ RAM systemsollama run qwen3-vl:32b
# For high-end systems with multiple GPUsollama run qwen3-vl:30b-a3b
# For maximum performance (requires serious hardware)ollama run qwen3-vl:235b-a22b
الخطوة 4: التفاعل الأول مع Qwen3-VL المحلي الخاص بك
بمجرد تنزيل النموذج وتشغيله، سترى مطالبة مثل هذه:
Send a message (type /? for help)
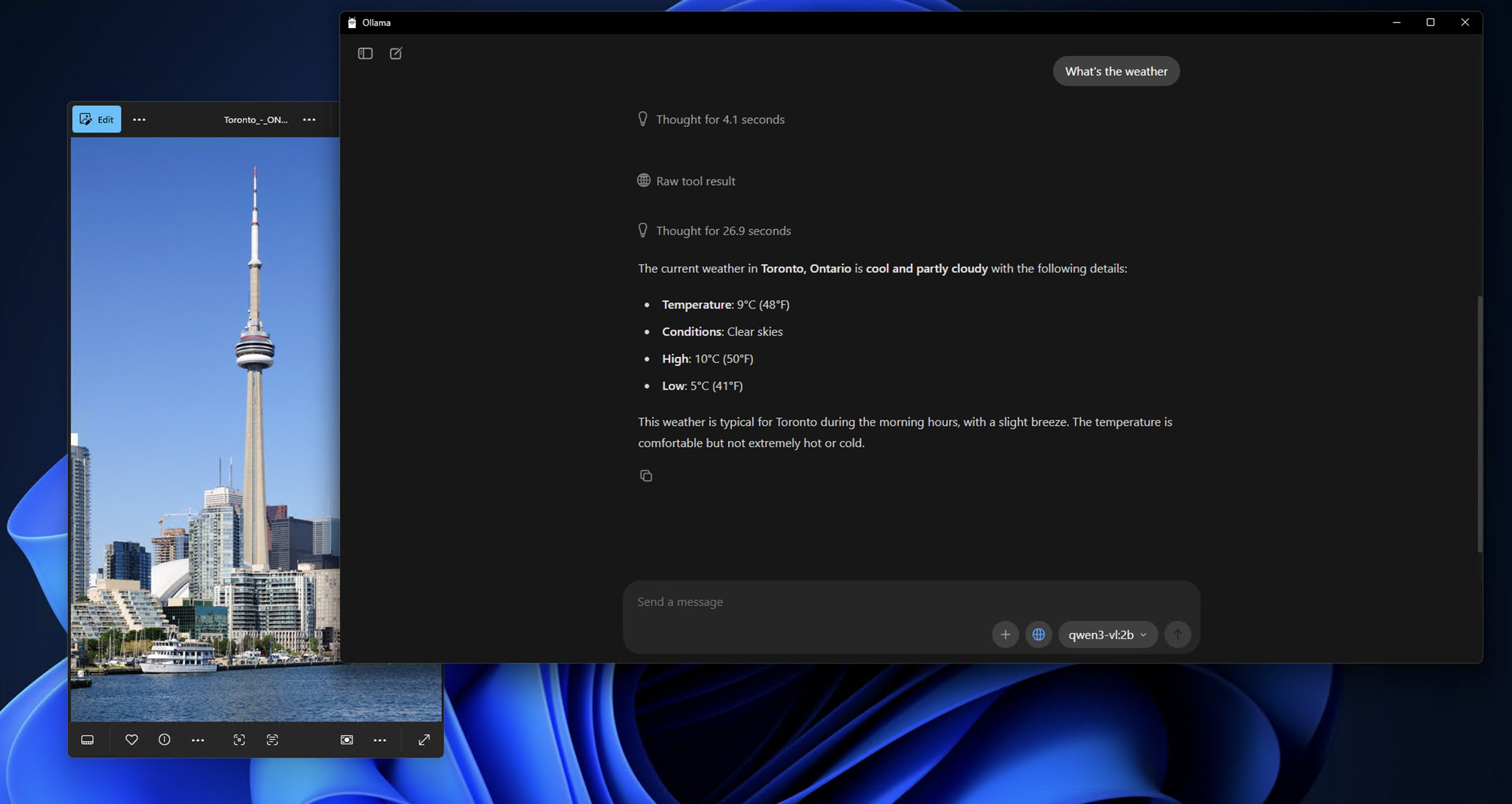
دعنا نختبر قدرات النموذج بتحليل صورة بسيط:
إعداد صورة اختبار:
ابحث عن أي صورة على جهاز الكمبيوتر الخاص بك - يمكن أن تكون صورة فوتوغرافية أو لقطة شاشة أو رسم توضيحي. لهذا المثال، سأفترض أن لديك صورة تسمى test_image.jpg في دليلك الحالي.

اختبار الدردشة التفاعلية:
bash
What do you see in this image? /path/to/your/image.jpg
بديل: استخدام واجهة برمجة التطبيقات للاختبار
إذا كنت تفضل الاختبار برمجيًا، يمكنك استخدام واجهة برمجة تطبيقات Ollama. إليك اختبار بسيط باستخدام curl:
bash
curl <http://localhost:11434/api/generate> \\
-H "Content-Type: application/json" \\
-d '{
"model": "qwen3-vl:4b",
"prompt": "What is in this image? Describe it in detail.",
"images": ["base64_encoded_image_data_here"]
}'

الخطوة 5: خيارات التكوين المتقدمة
الآن بعد أن أصبح لديك تثبيت عامل، دعنا نستكشف بعض خيارات التكوين المتقدمة لتحسين إعداداتك لجهازك وحالة الاستخدام المحددة.
تحسين الذاكرة:
إذا كنت تواجه مشكلات في الذاكرة، يمكنك تعديل سلوك تحميل النموذج:
bash
# Set maximum memory usage (adjust based on your RAM)export OLLAMA_MAX_LOADED_MODELS=1
# Enable GPU offloadingexport OLLAMA_GPU=1
# Set custom port (if 11434 is already in use)export OLLAMA_HOST=0.0.0.0:11435
خيارات التكميم:
بالنسبة للأنظمة ذات ذاكرة VRAM محدودة، يمكنك فرض مستويات تكميم محددة:
bash
# Load model with 4-bit quantization (more compatible, slower)ollama run qwen3-vl:4b --format json
# Load with 8-bit quantization (balanced)ollama run qwen3-vl:8b --format json
تكوين وحدات معالجة الرسوميات المتعددة:
إذا كان لديك وحدات معالجة رسوميات متعددة، يمكنك تحديد أي منها للاستخدام:
bash
# Use specific GPU IDs (Linux/macOS)export CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
# On macOS with multiple Apple Silicon GPUsexport CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
الاختبار والتكامل مع Apidog: ضمان الجودة والأداء

الآن بعد أن أصبح لديك Qwen3-VL يعمل محليًا، دعنا نتحدث عن كيفية اختباره ودمجه بشكل صحيح في سير عمل التطوير الخاص بك. هذا هو المكان الذي يتألق فيه Apidog حقًا كأداة لا غنى عنها لمطوري الذكاء الاصطناعي.
Apidog ليس مجرد أداة أخرى لاختبار واجهات برمجة التطبيقات، بل هو منصة شاملة مصممة خصيصًا لسير عمل تطوير واجهات برمجة التطبيقات الحديثة. عند العمل مع نماذج الذكاء الاصطناعي المحلية مثل Qwen3-VL، تحتاج إلى أداة يمكنها:
1.التعامل مع هياكل JSON المعقدة: غالبًا ما تحتوي استجابات نماذج الذكاء الاصطناعي على JSON متداخل بأنواع محتوى مختلفة
2.دعم تحميل الملفات: تحتاج العديد من نماذج الذكاء الاصطناعي إلى مدخلات صور أو فيديو أو مستندات
3.إدارة المصادقة: اختبار آمن لنقاط النهاية مع معالجة المصادقة المناسبة
4.إنشاء اختبارات آلية: اختبار الانحدار لضمان اتساق أداء النموذج
5.توليد التوثيق: إنشاء توثيق واجهة برمجة التطبيقات تلقائيًا من حالات الاختبار الخاصة بك
استكشاف المشكلات الشائعة وإصلاحها
حتى مع بساطة Ollama، قد تواجه عقبات. إليك حلول للمشكلات المتكررة.
❌ "النموذج غير موجود" أو "نموذج غير مدعوم"
- تأكد من أنك تستخدم Ollama الإصدار 0.1.40 أو أحدث
- قم بتشغيل
ollama pull qwen3-vl:4bمرة أخرى - أحيانًا يفشل التنزيل بصمت
❌ "نفاد الذاكرة" على وحدة معالجة الرسوميات (GPU)
- جرب الإصدار 4B بدلاً من 8B
- أغلق التطبيقات الأخرى التي تستهلك الكثير من موارد وحدة معالجة الرسوميات (Chrome، الألعاب، إلخ)
- على Linux، تحقق من ذاكرة VRAM باستخدام
nvidia-smi
❌ الصورة غير معترف بها
- تأكد من أن حجم الصورة أقل من 4 ميجابايت
- استخدم PNG أو JPG (تجنب HEIC، BMP)
- تأكد من أن سلسلة base64 لا تحتوي على أسطر جديدة (استخدم
base64 -w 0على Linux)
❌ استدلال بطيء على وحدة المعالجة المركزية (CPU)
- Qwen 3 VL كبير حتى لو كان مكممًا. توقع 1-5 رموز/ثانية على وحدة المعالجة المركزية
- قم بالترقية إلى Apple Silicon أو وحدة معالجة رسوميات NVIDIA للحصول على سرعة 10 أضعاف
حالات استخدام واقعية لـ Qwen 3 VL المحلي
لماذا كل هذا العناء؟ إليك تطبيقات عملية:
- ذكاء المستندات: استخراج الجداول أو التوقيعات أو البنود من ملفات PDF الممسوحة ضوئيًا
- أدوات الوصول: وصف الصور للمستخدمين ضعاف البصر
- روبوتات المعرفة الداخلية: الإجابة على الأسئلة حول المخططات أو لوحات المعلومات الداخلية
- التعليم: بناء معلم يشرح مسائل الرياضيات من الصور
- تحليل الأمان: تحليل مخططات الشبكة أو لقطات شاشة بنية النظام
لأنه محلي، فإنك تتجنب إرسال المرئيات الحساسة إلى واجهات برمجة تطبيقات الطرف الثالث - وهو مكسب كبير للمؤسسات والمطورين المهتمين بالخصوصية.
الخاتمة: رحلتك نحو التميز في الذكاء الاصطناعي المحلي
تهانينا! لقد أكملت للتو رحلة ملحمية إلى عالم الذكاء الاصطناعي المحلي باستخدام Qwen3-VL و Ollama. بحلول الآن، يجب أن يكون لديك:
- تثبيت Qwen3-VL يعمل بكامل طاقته محليًا
- إعداد اختبار شامل باستخدام Apidog
- فهم عميق لقدرات النموذج وقيوده
- معرفة عملية لدمج هذه النماذج في تطبيقات العالم الحقيقي
- مهارات استكشاف الأخطاء وإصلاحها للتعامل مع المشكلات الشائعة
- استراتيجيات تأمين المستقبل للنجاح المستمر
حقيقة أنك وصلت إلى هذا الحد تظهر التزامك بفهم واستغلال أحدث تقنيات الذكاء الاصطناعي. لم تقم فقط بتثبيت نموذج، بل اكتسبت خبرة في تقنية تعيد تشكيل كيفية تفاعلنا مع المعلومات المرئية والنصية.
المستقبل هو الذكاء الاصطناعي المحلي
ما أنجزناه هنا يمثل أكثر من مجرد إعداد تقني - إنه خطوة نحو مستقبل يكون فيه الذكاء الاصطناعي متاحًا وخاصًا وتحت السيطرة الفردية. مع استمرار هذه النماذج في التحسن وتصبح أكثر كفاءة، نتحرك نحو عالم تكون فيه قدرات الذكاء الاصطناعي المتطورة متاحة للجميع، بغض النظر عن ميزانيتهم أو خبرتهم التقنية.
تذكر، الرحلة لا تنتهي هنا. تتطور تقنية الذكاء الاصطناعي بسرعة، والبقاء فضوليًا ومتكيفًا ومتفاعلًا مع المجتمع سيضمن لك الاستمرار في الاستفادة من هذه الأدوات القوية بفعالية.
أفكار أخيرة
تشغيل Qwen 3 VL محليًا باستخدام Ollama ليس مجرد عرض تقني أو يتعلق بالراحة أو توفير التكاليف - إنه لمحة عن مستقبل الذكاء الاصطناعي على الجهاز. مع زيادة كفاءة النماذج وقوة الأجهزة، سنرى المزيد من المطورين يقدمون ميزات خاصة ومتعددة الوسائط مباشرة في تطبيقاتهم. لديك الآن الأدوات لاستكشاف تقنية الذكاء الاصطناعي بلا حدود، والتجربة بحرية، وبناء تطبيقات تهمك وتهم مؤسستك.
يخلق الجمع بين قدرات Qwen3-VL المتعددة الوسائط المثيرة للإعجاب وواجهة Ollama سهلة الاستخدام فرصًا للابتكار كانت متاحة في السابق فقط للشركات الكبيرة ذات الموارد الضخمة. أنت الآن جزء من مجتمع متنامٍ من المطورين الذين يقومون بإضفاء الطابع الديمقراطي على تقنية الذكاء الاصطناعي.
ومع أدوات مثل Ollama التي تبسط النشر و Apidog التي تبسط تطوير واجهة برمجة التطبيقات، لم يكن حاجز الدخول أقل من أي وقت مضى.
لذا، سواء كنت مخترقًا منفردًا، أو مؤسس شركة ناشئة، أو مهندسًا في شركة، فقد حان الوقت المثالي لتجربة نماذج الرؤية واللغة بأمان، وبأسعار معقولة، ومحليًا.