
يسعى المطورون باستمرار إلى أدوات قوية لبناء تطبيقات ذكية. تلبي OpenAI هذه الحاجة بإطلاق GPT-OSS، وهي سلسلة من نماذج اللغة مفتوحة الوزن التي توفر قدرات استدلال متقدمة. تتيح هذه النماذج، بما في ذلك gpt-oss-120b و gpt-oss-20b، التخصيص والنشر في بيئات مختلفة. يصل المستخدمون إليها عبر واجهات برمجة التطبيقات (APIs) التي توفرها منصات الاستضافة، مما يتيح التكامل السلس في المشاريع.
للبدء في العمل مع واجهة برمجة تطبيقات GPT-OSS، يحصل المطورون على الوصول عبر مزودين مثل OpenRouter أو Together AI. تستضيف هذه المنصات النماذج وتوفر نقاط نهاية قياسية متوافقة مع تنسيق واجهة برمجة تطبيقات OpenAI. تبسط هذه التوافقية عملية الترحيل من النماذج الاحتكارية.
ما هو GPT-OSS؟ الميزات والقدرات الرئيسية
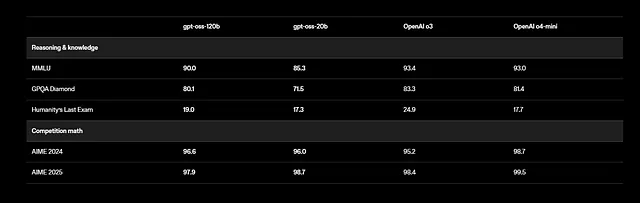
تصمم OpenAI GPT-OSS كسلسلة من نماذج "مزيج الخبراء" (MoE). تعمل هذه البنية على تنشيط مجموعة فرعية فقط من المعلمات لكل رمز، مما يعزز الكفاءة. على سبيل المثال، يتميز gpt-oss-120b بـ 117 مليار معلمة إجمالية ولكنه ينشط 5.1 مليار فقط لكل رمز. وبالمثل، يستخدم gpt-oss-20b 21 مليار معلمة مع 3.6 مليار نشطة.
تستخدم النماذج هياكل قائمة على المحولات (Transformer-based) مع طبقات انتباه كثيفة ومتباعدة متناوبة. وهي تتضمن تضمينات موضعية دوارة (RoPE) للتعامل مع السياقات الطويلة التي تصل إلى 128,000 رمز. يستفيد المطورون من ذلك في التطبيقات التي تتطلب إدخالاً واسع النطاق، مثل تلخيص المستندات.
علاوة على ذلك، يدعم GPT-OSS المهام متعددة اللغات، على الرغم من أن التدريب يركز على اللغة الإنجليزية مع التركيز على بيانات العلوم والتكنولوجيا والهندسة والرياضيات (STEM) والترميز. تُظهر المعايير نتائج مبهرة: يسجل gpt-oss-120b 94.2% في MMLU (فهم اللغة متعدد المهام الضخم) و 96.6% في AIME (الامتحان الأمريكي للرياضيات الدعوية). ويتفوق على نماذج مثل o4-mini في الاستعلامات المتعلقة بالصحة ومسابقات الرياضيات.
يستخدم المطورون ميزات استدعاء الأدوات، حيث يستدعي النموذج وظائف خارجية مثل البحث على الويب أو تنفيذ التعليمات البرمجية. تتيح هذه القدرة الوكيلية بناء أنظمة مستقلة. على سبيل المثال، يربط النموذج عدة استدعاءات أدوات في استجابة واحدة لحل المشكلات خطوة بخطوة.
بالإضافة إلى ذلك، تلتزم النماذج بترخيص Apache 2.0، مما يسمح بالتعديل والنشر المجاني. توفر OpenAI الأوزان على Hugging Face، ومكممة بتنسيق MXFP4 لتقليل استخدام الذاكرة. يمكن للمستخدمين تشغيلها محليًا أو عبر مزودي الخدمات السحابية.
ومع ذلك، تنطبق اعتبارات السلامة. تجري OpenAI تقييمات بموجب إطار عملها "الاستعداد"، واختبار المخاطر مثل المعلومات المضللة. ينفذ المطورون ضمانات، مثل تصفية المخرجات، للتخفيف من المشكلات.
باختصار، يجمع GPT-OSS بين القوة وسهولة الوصول. تشجع طبيعته المفتوحة مساهمات المجتمع، مما يؤدي إلى تحسينات سريعة. بعد ذلك، حدد المزودين الذين يقدمون وصولاً لواجهة برمجة التطبيقات إلى هذه النماذج.
اختيار المزودين للوصول إلى واجهة برمجة تطبيقات GPT-OSS
تستضيف العديد من المنصات نماذج GPT-OSS وتوفر نقاط نهاية لواجهة برمجة التطبيقات. يختار المطورون بناءً على الاحتياجات مثل السرعة والتكلفة وقابلية التوسع. OpenRouter، على سبيل المثال، يقدم gpt-oss-120b بأسعار تنافسية وتكامل سهل.
توفر Together AI خيارًا آخر، مع التركيز على عمليات النشر الجاهزة للمؤسسات. وهي تدعم النموذج من خلال نقطة نهاية /v1/chat/completions، المتوافقة مع عملاء OpenAI. يرسل المطورون حمولات JSON تحدد الرسائل، والحد الأقصى للرموز، ودرجة الحرارة.
علاوة على ذلك، تقدم Fireworks AI و Cerebras استنتاجًا عالي السرعة. تحقق Cerebras ما يصل إلى 3000 رمز في الثانية، وهو مثالي للتطبيقات في الوقت الفعلي. تختلف الأسعار: تفرض OpenRouter حوالي 0.15 دولار لكل مليون رمز إدخال، بينما تقدم Together AI أسعارًا مماثلة مع خصومات على الحجم.
ينظر المطورون أيضًا في الاستضافة الذاتية للخصوصية. تسمح أدوات مثل vLLM أو Ollama بتشغيل GPT-OSS على الخوادم المحلية، مما يوفر واجهة برمجة تطبيقات. على سبيل المثال، يخدم vLLM النموذج بمسارات متوافقة مع OpenAI، ويتطلب أمرًا واحدًا للبدء.
ومع ذلك، تبسط مزودو الخدمات السحابية عملية التوسع. تدمج AWS و Azure و Vercel GPT-OSS عبر شراكات مع OpenAI. تتعامل هذه الخيارات مع موازنة التحميل والتوسع التلقائي تلقائيًا.
بالإضافة إلى ذلك، قم بتقييم زمن الاستجابة. يناسب gpt-oss-20b الأجهزة الطرفية ذات المتطلبات الأقل، بينما يتطلب gpt-oss-120b وحدات معالجة رسومات مثل NVIDIA H100. يقوم المزودون بتحسين الأجهزة، مما يضمن أداءً ثابتًا.
باختصار، يتوافق المزود المناسب مع أهداف المشروع. بمجرد الاختيار، انتقل إلى الحصول على بيانات اعتماد واجهة برمجة التطبيقات.
الحصول على وصول API وإعداد بيئتك
يبدأ المطورون بالتسجيل في موقع المزود. بالنسبة لـ OpenRouter، قم بزيارة openrouter.ai، وأنشئ حسابًا، وانتقل إلى قسم المفاتيح. قم بإنشاء مفتاح API جديد، وقم بتسميته للرجوع إليه، وانسخه بأمان.
بعد ذلك، قم بتثبيت مكتبات العميل. في بايثون، استخدم pip لإضافة openai: pip install openai. قم بتكوين العميل باستخدام عنوان URL الأساسي والمفتاح. على سبيل المثال:
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="your_api_key_here"
)
يتيح هذا الإعداد إرسال الطلبات إلى نماذج gpt-oss.
علاوة على ذلك، بالنسبة لـ Together AI، استخدم SDK الخاص بهم: pip install together. قم بالتهيئة باستخدام:
import together
together.api_key = "your_together_api_key"
اختبر الاتصال عن طريق سرد النماذج أو إرسال استعلام بسيط.
ومع ذلك، تحقق من الأجهزة إذا كنت تستضيف ذاتيًا. قم بتنزيل الأوزان من Hugging Face: huggingface-cli download openai/gpt-oss-120b. ثم استخدم vLLM للخدمة: vllm serve openai/gpt-oss-120b.
بالإضافة إلى ذلك، قم بتعيين متغيرات البيئة للأمان. قم بتخزين المفاتيح في ملفات .env وقم بتحميلها باستخدام مكتبة dotenv.
في حالة وجود مشكلات، تحقق من وثائق المزود لمعرفة حدود المعدل أو أخطاء المصادقة. يضمن هذا الإعداد تفاعلات سلسة لواجهة برمجة التطبيقات.
إجراء أول استدعاء API لـ GPT-OSS
يقوم المطورون بإنشاء الطلبات باستخدام نقطة نهاية إكمال الدردشة. حدد النموذج، مثل "openai/gpt-oss-120b"، في الحمولة.
لإجراء استدعاء أساسي، قم بإعداد الرسائل كقائمة من القواميس. يتضمن كل منها الدور (النظام، المستخدم، المساعد) والمحتوى.
إليك مثال في بايثون:
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum superposition."}
],
max_tokens=200,
temperature=0.7
)
print(completion.choices[0].message.content)
يولد هذا استجابة تشرح المفهوم تقنيًا.
علاوة على ذلك، قم بضبط المعلمات للتحكم. تؤثر درجة الحرارة على الإبداع - القيم الأقل تنتج مخرجات حتمية. يحد top_p من أخذ عينات الرموز، بينما يثبط presence_penalty التكرار.
بعد ذلك، قم بدمج استدعاء الأدوات. حدد الأدوات في الطلب:
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location"]
}
}
}
]
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[{"role": "user", "content": "What's the weather like in Boston?"}],
tools=tools,
tool_choice="auto"
)
يستجيب النموذج باستدعاء أداة، يقوم المطورون بتنفيذها وإعادة تغذيتها.
ومع ذلك، تعامل مع الاستجابات بعناية. قم بتحليل JSON للمحتوى، وسبب الانتهاء، وإحصائيات الاستخدام مثل عدد الرموز.
بالإضافة إلى ذلك، بالنسبة لسلسلة الأفكار، اطلب "فكر خطوة بخطوة". حدد جهد الاستدلال في رسائل النظام: "reasoning_effort: medium".
جرب gpt-oss-20b لاختبارات أسرع: استبدل اسم النموذج في الاستدعاءات.
في السيناريوهات المتقدمة، قم ببث الاستجابات باستخدام stream=True للحصول على مخرجات في الوقت الفعلي.
تبني هذه الخطوات مهارات أساسية. الآن، قم بدمج أدوات الاختبار مثل Apidog.
دمج Apidog لاختبار واجهة برمجة تطبيقات GPT-OSS بكفاءة
يعتمد المطورون على Apidog لاختبار وتصحيح أخطاء تفاعلات واجهة برمجة التطبيقات. توفر هذه الأداة واجهة سهلة الاستخدام لإرسال الطلبات إلى نقاط نهاية gpt-oss.
أولاً، قم بتثبيت Apidog من موقعهم على الويب. أنشئ مشروعًا جديدًا وأضف نقطة نهاية API، مثل https://openrouter.ai/api/v1/chat/completions.
بعد ذلك، قم بتكوين الرؤوس: أضف Authorization مع رمز Bearer و Content-Type كـ application/json.
علاوة على ذلك، قم ببناء نص الطلب. استخدم محرر JSON في Apidog لإدخال النموذج والرسائل والمعلمات. على سبيل المثال، اختبر استدعاء gpt-oss لتوليد التعليمات البرمجية.
يعرض Apidog الاستجابات بصريًا، ويسلط الضوء على الأخطاء أو النجاحات. وهو يدعم متغيرات البيئة لتبديل مفاتيح API بين المزودين.
ومع ذلك، استفد من المجموعات لتنظيم الاختبارات. قم بتجميع استعلامات GPT-OSS حسب المهمة، مثل الاستدلال أو استخدام الأداة، وقم بتشغيلها على دفعات.
بالإضافة إلى ذلك، يولد Apidog مقتطفات تعليمات برمجية بلغات مثل بايثون أو cURL من طلباتك، مما يسرع عملية التطوير.
للتعاون، شارك المشاريع مع الفرق. يضمن ذلك اختبارًا متسقًا لتكاملات gpt-oss.
عمليًا، استخدم Apidog لمراقبة استخدام الرموز وتحسين المطالبات، مما يقلل التكاليف.
بشكل عام، يعزز Apidog الإنتاجية عند العمل مع واجهة برمجة تطبيقات GPT-OSS.
الاستخدام المتقدم: الضبط الدقيق والنشر
يقوم المطورون بضبط GPT-OSS بدقة لمجالات محددة. استخدم مكتبة المحولات في Hugging Face لتحميل الأوزان والتدريب على مجموعات بيانات مخصصة.
على سبيل المثال، قم بإعداد البيانات بتنسيق JSONL مع أزواج المطالبة والإكمال. قم بتشغيل نصوص الضبط الدقيق من مستودع GitHub.
علاوة على ذلك، قم بنشر النماذج المضبوطة عبر vLLM لخدمة API. يدعم هذا أحمال الإنتاج بميزات مثل التجميع الديناميكي.
بعد ذلك، استكشف التوسعات متعددة الوسائط. على الرغم من التركيز على النص، قم بالدمج مع نماذج الرؤية للتطبيقات الهجينة.
ومع ذلك، راقب التجاوز (overfitting) أثناء الضبط الدقيق. استخدم مجموعات التحقق والتوقف المبكر.
بالإضافة إلى ذلك، قم بالتوسع مع الاستدلال الموزع على المجموعات. يقدم المزودون مثل AWS خيارات مُدارة.
في الإعدادات الوكيلية، قم بربط GPT-OSS بواجهات برمجة تطبيقات خارجية لسير العمل مثل البحث الآلي.
توسع هذه التقنيات القدرات إلى ما هو أبعد من الاستدعاءات الأساسية.
أفضل الممارسات، القيود، واستكشاف الأخطاء وإصلاحها
يتبع المطورون أفضل الممارسات للحصول على أفضل النتائج. قم بصياغة مطالبات واضحة، واستخدم أمثلة قليلة اللقطات، وكرر بناءً على المخرجات.
علاوة على ذلك، احترم حدود المعدل – تحقق من لوحات معلومات المزود لتجنب الاختناق.
ومع ذلك، اعترف بالقيود: قد يهذي GPT-OSS، لذا تحقق من الاستجابات الهامة. يفتقر إلى تحديثات المعرفة في الوقت الفعلي.
بالإضافة إلى ذلك، قم بتأمين مفاتيح API وسجل الاستخدام للتحكم في التكلفة.
استكشف الأخطاء وإصلاحها عن طريق مراجعة رموز الخطأ؛ 401 يشير إلى مصادقة غير صالحة، 429 يعني تجاوز حد المعدل.
باختصار، التزم بهذه الإرشادات للحصول على أداء موثوق.
الخلاصة: عزز مشاريعك باستخدام واجهة برمجة تطبيقات GPT-OSS
يمتلك المطورون الآن الأدوات اللازمة لدمج GPT-OSS بفعالية. من الإعداد إلى الميزات المتقدمة، يرشدك هذا الدليل نحو النجاح. جرب، وحسّن، وابتكر باستخدام gpt-oss و Apidog لإنشاء حلول ذكاء اصطناعي مؤثرة.