
يبحث المهندسون والمطورون باستمرار عن نماذج فعالة تقدم أداءً عاليًا دون متطلبات موارد مفرطة. يبرز GLM-4.7-Flash كخيار مقنع في هذا المشهد. يتميز هذا النموذج، GLM-4.7-Flash، الذي يعمل بتقنية Mixture-of-Experts (MoE) بحجم 30 مليار معلمة (30B-A3B) والذي طورته شركة Zhipu AI (Z.ai)، بتوازنه بين القوة والكفاءة. إنه يتفوق في معايير البرمجة ومهام التفكير وتكامل الأدوات، مما يجعله مناسبًا لسيناريوهات النشر المحلي.
يتيح تشغيل GLM-4.7-Flash محليًا للمستخدمين الحفاظ على خصوصية البيانات، وتقليل زمن الاستجابة، وتخصيص عمليات التكامل. تعمل أدوات مثل Ollama وLM Studio وHugging Face على تبسيط هذه العملية.
بينما تتقدم في هذا الدليل، ستكتسب رؤى عملية حول التثبيت والاستخدام. أولاً، لننظر في المتطلبات الأساسية للنظام.
ما هو GLM-4.7-Flash ولماذا نستخدمه محليًا؟
يمثل GLM-4.7-Flash تقدمًا في نماذج اللغة مفتوحة المصدر. تم بناؤه على بنية glm4_moe_lite، ويستخدم أنواع تينسور BF16 وF32 بموجب ترخيص MIT. توضح ورقة النموذج، "GLM-4.5: نماذج الأساس الذكية، التفكيرية، والبرمجية (ARC)"، تفاصيل تدريبه على استخدام الأدوات والتفكير، مستوحاة من arXiv:2508.06471.
تشمل الميزات الرئيسية دعم اللغة الإنجليزية والصينية، وتوليد النصوص، ومهام المحادثة. يتعامل مع المدخلات متعددة الوسائط كنص ولكنه يركز على المخرجات النصية فقط. تنشأ القيود من حجمه — فبينما هو فعال، قد لا يضاهي النماذج الأكبر في المجالات المتخصصة بدون ضبط دقيق. تظل تفاصيل بيانات التدريب غير معلنة، لكن التقييمات تؤكد تفوقه في البرمجة والسيناريوهات الذكية.
يلجأ المستخدمون إلى التشغيل المحلي لتجنب تكاليف API. تقدم Z.ai طبقة مجانية لـ GLM-4.7-Flash عبر منصتها، لكن النشر المحلي يلغي الاعتماد على الخدمات الخارجية. يناسب هذا النهج المطورين الذين يبنون تطبيقات مخصصة، والباحثين الذين يختبرون الفرضيات، أو الشركات التي تعطي الأولوية للأمان. على سبيل المثال، يمكنك التحكم في مستويات التكميم لتناسب قيود الأجهزة، مما يضمن الأداء الأمثل.
متطلبات النظام لتشغيل GLM-4.7-Flash محليًا
تلعب الأجهزة دورًا حاسمًا في استنتاج النموذج. يتطلب GLM-4.7-Flash ما لا يقل عن 16 جيجابايت من ذاكرة النظام للعمليات الأساسية، كما هو محدد في إرشادات LM Studio. ومع ذلك، يعزز تسريع وحدة معالجة الرسوميات (GPU) السرعة بشكل كبير.
بالنسبة لإصدارات Ollama:
- q4_K_M: 19 جيجابايت VRAM
- q8_0: 32 جيجابايت VRAM
- bf16: 60 جيجابايت VRAM
توصي Hugging Face بـ torch.bfloat16 لتحقيق الكفاءة، مما يتطلب وحدات معالجة رسوميات NVIDIA متوافقة (بنية Ampere أو أحدث). يعمل الاستنتاج عبر وحدة المعالجة المركزية (CPU) فقط ولكنه يتباطأ بشكل كبير للسياقات الكبيرة.
تشمل المتطلبات البرمجية المسبقة Python 3.8+ وpip وGit. تتطلب الأطر مثل Transformers تثبيتات إضافية. تأكد من أن نظام التشغيل الخاص بك يدعم CUDA لاستخدام GPU—يعمل Ubuntu 20.04 أو Windows مع WSL2 بشكل جيد.
إذا كانت الموارد غير كافية، يقلل التكميم من استهلاك الذاكرة. توفر أدوات مثل llama.cpp أو Unsloth إصدارات 4 بت أو 2 بت، مما يقلل المتطلبات إلى 15-20 جيجابايت VRAM. تتيح هذه المرونة النشر على أجهزة المستهلك مثل RTX 4090.
مع تلبية المتطلبات، استكشف طرق التثبيت. ابدأ بـ Ollama لسهولته.
كيفية تثبيت واستخدام GLM-4.7-Flash مع Ollama
يوفر Ollama منصة سهلة الوصول لتشغيل النماذج الكبيرة محليًا. يدير التكميم وخدمة API تلقائيًا.
أولاً، قم بتثبيت Ollama. قم بتنزيل الملف التنفيذي لنظام التشغيل الخاص بك وقم بتشغيله.

تحقق من التثبيت باستخدام ollama --version، مع التأكد من أن الإصدار 0.14.3 أو أحدث، حيث يتطلبه GLM-4.7-Flash.

بعد ذلك، اسحب النموذج: قم بتنفيذ ollama pull glm-4.7-flash.

اختر متغيرات مثل glm-4.7-flash:q4_K_M لاستخدام ذاكرة أقل. يقوم الأمر بتنزيل حوالي 19 جيجابايت لإصدار q4.
قم بتشغيل النموذج تفاعليًا: اكتب ollama run glm-4.7-flash. أدخل مطالبات مثل "Generate Python code for a Fibonacci sequence." يستجيب النموذج بمخرجات منطقية، مستفيدًا من نقاط قوته في البرمجة.
للوصول البرمجي، استخدم API. أرسل طلب curl:
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role": "user", "content": "Explain quantum computing basics."}]
}'
يعيد هذا JSON مع الاستجابة. في بايثون، ادمج مع مكتبة ollama:
from ollama import chat
response = chat(
model='glm-4.7-flash',
messages=[{'role': 'user', 'content': 'Solve this math problem: 2x + 3 = 7'}]
)
print(response['message']['content'])
الجافاسكريبت تتبع بالمثل مع حزمة ollama npm.
تخصيص الإعدادات عن طريق تحرير Modelfile. اضبط درجة الحرارة على 0.7 للمخرجات الحتمية في مهام البرمجة. يجلب أحدث وضع في Ollama المشاركات الحديثة إذا لزم الأمر، لكن التركيز هنا ينصب على الاستنتاج المحلي.
هذه الطريقة تناسب الإعدادات السريعة. ومع ذلك، لواجهة رسومية، انتقل إلى LM Studio.
إعداد GLM-4.7-Flash في LM Studio
يوفر LM Studio واجهة مستخدم رسومية سهلة الاستخدام لإدارة النماذج. قم بتنزيله وتثبيته.
ابحث عن "zai-org/glm-4.7-flash" في مركز النماذج. حدد إصدارًا مكممًا—MLX-4bit، 6bit، أو 8bit—من مستودعات Hugging Face المرتبطة. يكتمل التنزيل داخل التطبيق.
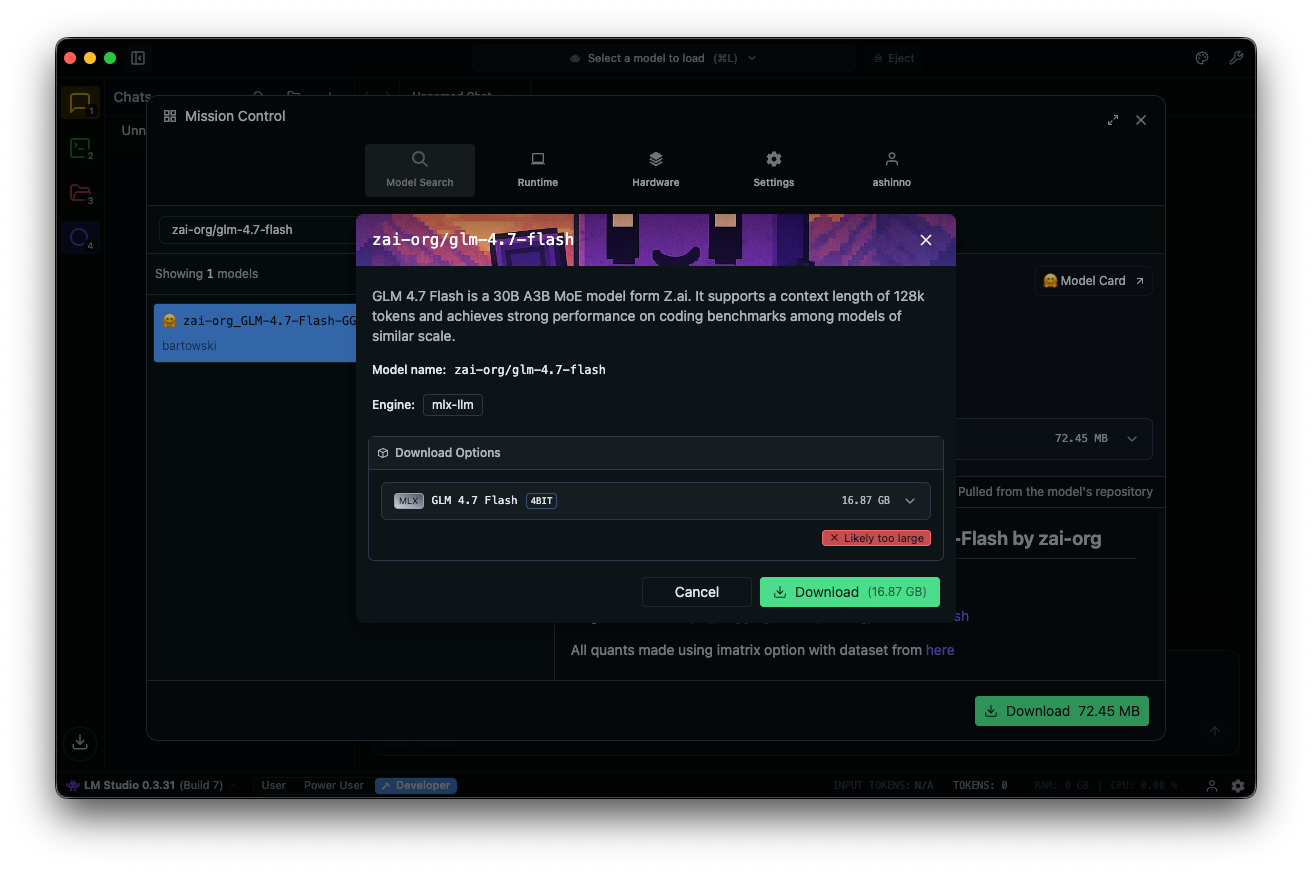
قم بتحميل النموذج: انتقل إلى واجهة الدردشة، حدد GLM-4.7-Flash، واضبط المعلمات. قم بتمكين التفكير (افتراضي: true) للتفكير خطوة بخطوة. اضبط درجة الحرارة على 1، وtop_k على 50، وtop_p على 0.95، وقم بتعطيل عقوبة التكرار.
اختبر باستخدام المطالبات: "Design a REST API for user authentication." يعرض LM Studio المخرجات مع سرعات التوكن، مما يساعد في ضبط الأداء.
تقوم الحقول المخصصة مثل clear_thinking (افتراضي: false) بإدارة السجل. بالنسبة لنماذج MoE، راقب الخبراء النشطين—A3B يعني ثلاثة خبراء نشطين لكل تمريرة أمامية، مما يحسن الكفاءة.
يدعم LM Studio الروابط العميقة للوصول المباشر إلى النموذج. إذا نشأت مشكلات، تحقق من ذاكرة النظام—16 جيجابايت كحد أدنى تمنع الأعطال.
تتفوق هذه الأداة في التجريب. للبرمجة المتقدمة، ادمج مع Hugging Face.
استخدام GLM-4.7-Flash مع Hugging Face Transformers
توفر Hugging Face مكتبات قوية للتحكم الدقيق. قم بتثبيت Transformers من الفرع الرئيسي:
pip install git+https://github.com/huggingface/transformers.git
قم بتحميل النموذج:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "zai-org/GLM-4.7-Flash"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto"
)
جهز المدخلات:
messages = [{"role": "user", "content": "Write a function to sort an array."}]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
أنشئ:
generated_ids = model.generate(**inputs, max_new_tokens=512, do_sample=False)
output = tokenizer.decode(generated_ids[0][inputs['input_ids'].shape[1]:])
print(output)
يدعم هذا الإعداد التكميم عبر bitsandbytes لـ VRAM أقل. أضف load_in_4bit=True عند تحميل النموذج.
للخدمة، استخدم vLLM أو SGLang. قم بتثبيت vLLM:
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
قم بتشغيل خادم:
python -m vllm.entrypoints.openai.api_server --model zai-org/GLM-4.7-Flash
الوصول عبر نقاط نهاية متوافقة مع OpenAI. يتطلب SGLang التثبيت من المصدر ويتبع خطوات مماثلة.
تمكن هذه الأطر من عمليات النشر على مستوى الإنتاج. الآن، لننظر في اختبار API باستخدام Apidog.
دمج Apidog لاختبار API مع GLM-4.7-Flash المحلي
بمجرد تقديم GLM-4.7-Flash عبر Ollama أو vLLM، اختبر نقاط النهاية بكفاءة. يسهل Apidog، وهو منصة API متكاملة، ذلك.
قم بتنزيل Apidog مجانًا. يدعم ميزات الذكاء الاصطناعي عن طريق تهيئة نموذجك المحلي كموفر—استخدم مفاتيح API إذا كانت قابلة للتطبيق، أو نقاط نهاية مباشرة.
يتكامل خادم MCP من Apidog مع بيئات التطوير المتكاملة (IDEs) مثل Cursor، باستخدام مواصفات API لتوليد الكود. يرتبط هذا بقدرات GLM-4.7-Flash البرمجية—اختبر المخرجات الذكية مباشرة.
على سبيل المثال، استعلم عن خادمك المحلي وتحقق من صحة الاستجابات. هذا يضمن الموثوقية في التطبيقات.
بناءً على الأساسيات، ننتقل إلى التحسين.
نصائح متقدمة لتحسين أداء GLM-4.7-Flash
اضبط المعلمات بدقة للمهام. اضبط درجة الحرارة على 0.7 للبرمجة، و1.0 للكتابة الإبداعية. استخدم top_p 0.95 لتحقيق التوازن في التنوع.
قم بتكميم المزيد باستخدام تنسيقات GGUF عبر llama.cpp. قم بتجميع llama.cpp مع CUDA، ثم قم بالتحويل:
./llama-gguf-split --model GLM-4.7-Flash.gguf
تشغيل مع --jinja لدعم القوالب.
التعامل مع السياقات الطويلة: قم بتقسيم المدخلات إذا تجاوزت 128 ألفًا. قم بتمكين التفكير للاستفسارات المعقدة.
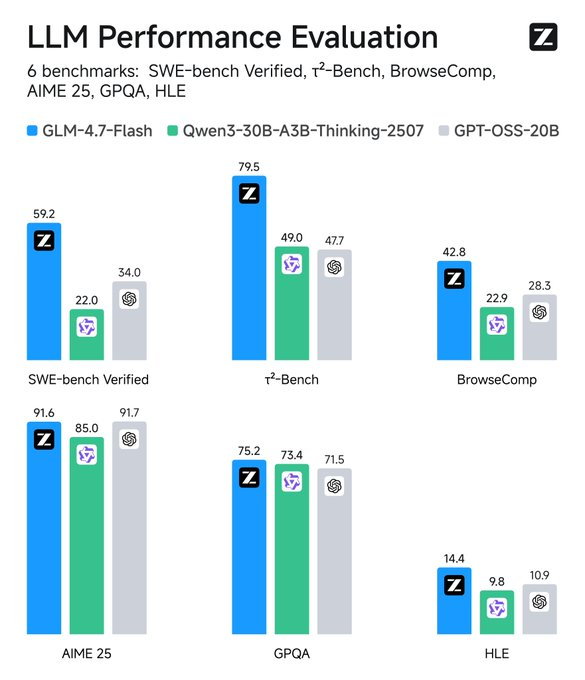
راقب المقاييس: تتعقب أدوات مثل TensorBoard زمن الوصول. قارن بالخطوط الأساسية—يتفوق GLM-4.7-Flash على أقرانه في SWE-bench بنسبة 37.2 نقطة.
تكامل الأدوات: أضف استدعاء الوظائف في المطالبات للسلوك الذكي.
الأمان: قم بالتشغيل في بيئات معزولة لمنع تسرب البيانات.
تعظم هذه الاستراتيجيات المنفعة. فكر في التطبيقات بعد ذلك.
استكشاف المشكلات الشائعة وإصلاحها
هل تواجه أخطاء نفاد الذاكرة؟ قلل حجم الدفعة أو كمّم بشكل أقل.
هل الاستدلال بطيء؟ قم بترقية وحدة معالجة الرسوميات (GPU) أو استخدم أطر عمل أسرع مثل vLLM.
مشاكل التوافق؟ قم بتحديث Transformers إلى الإصدار الرئيسي.
إذا فشل Ollama، تحقق من توفر المنفذ 11434.
أعطال LM Studio؟ تحقق من سلامة النموذج.
تعالج هذه المشاكل بشكل استباقي.
الخاتمة: عزز سير عملك باستخدام GLM-4.7-Flash
يتيح تشغيل GLM-4.7-Flash محليًا قدرات قوية للذكاء الاصطناعي. من سهولة Ollama إلى مرونة Hugging Face، تتوفر العديد من الخيارات. ادمج Apidog لإدارة API بسلاسة—قم بتنزيله مجانًا لرفع مستوى إعدادك.
مع تطور التكنولوجيا، تسد نماذج مثل هذه الفجوة بين الأداء وإمكانية الوصول. قم بتنفيذ هذه الخطوات، وستحقق عمليات نشر ذكاء اصطناعي فعالة وخاصة. تؤدي التعديلات الصغيرة في المعلمات أو الأدوات إلى تحسينات كبيرة، وتحويل المهام الروتينية إلى عمليات مبسطة.