
تخيل أنك تمتلك القدرة على استخراج البيانات من أي موقع ويب وجمع الرؤى على نطاق واسع - كل ذلك مع عدد قليل من أسطر التعليمات البرمجية. يبدو وكأنه سحر، أليس كذلك؟ حسنًا، Firecrawl يجعل هذا ممكنًا.
في هذا الدليل للمبتدئين، سأرشدك خلال كل ما تحتاج إلى معرفته عن Firecrawl، من التثبيت إلى تقنيات استخراج البيانات المتقدمة. سواء كنت مطورًا، أو محلل بيانات، أو مجرد فضولي حول تقنيات استخراج البيانات من الويب، سيساعدك هذا الدليل في البدء مع Firecrawl ودمجه في سير عملك.

ما هو Firecrawl؟
Firecrawl هو محرك مبتكر لاستخراج البيانات والزحف على الويب يحول محتوى المواقع إلى تنسيقات مثل markdown وHTML وبيانات منظمة. يجعل هذا منه مثاليًا لـ النماذج اللغوية الكبيرة (LLMs) وتطبيقات الذكاء الاصطناعي. مع Firecrawl، يمكنك جمع البيانات المنظمة وغير المنظمة من المواقع بكفاءة، مما يبسط سير عمل تحليل البيانات لديك.
الميزات الأساسية لـ Firecrawl
زحف: زحف شامل على الويب
نقطة النهاية /crawl في Firecrawl تتيح لك زيارة موقع ويب بشكل متكرر، واستخراج المحتوى من جميع الصفحات الفرعية. هذه الميزة مثالية لاكتشاف وتنظيم كميات كبيرة من بيانات الويب، وتحويلها إلى تنسيقات مناسبة للنماذج اللغوية الكبيرة.
استخراج: استخراج بيانات مستهدفة
استخدم ميزة استخراج لاستخراج بيانات معينة من عنوان URL واحد. يمكن لـ Firecrawl تقديم المحتوى في تنسيقات متنوعة، بما في ذلك markdown وبيانات منظمة ولقطات شاشة وHTML. هذه الميزة مفيدة بشكل خاص لاستخراج معلومات معينة من عناوين URL المعروفة.
خريطة: رسم موقع سريع
تسترجع ميزة الخريطة بسرعة جميع عناوين URL المرتبطة بموقع ويب معين، مما يوفر نظرة شاملة على هيكله. هذا مهم للغاية لاكتشاف المحتوى وتنظيمه.
استخراج: تحويل البيانات غير المهيكلة إلى تنسيق منظم
نقطة النهاية /extract هي ميزة مدعومة بالذكاء الاصطناعي في Firecrawl التي تبسط عملية جمع البيانات المنظمة من المواقع. إنها تتعامل مع الأعمال الشاقة من الزحف، تحليل البيانات، وتنظيمها في تنسيق منظم.
البدء مع Firecrawl
الخطوة 1: سجل واحصل على مفتاح API الخاص بك
قم بزيارة الموقع الرسمي لـ Firecrawl وقم بالتسجيل للحصول على حساب. بمجرد تسجيل الدخول، انتقل إلى لوحة التحكم الخاصة بك للعثور على مفتاح API الخاص بك.
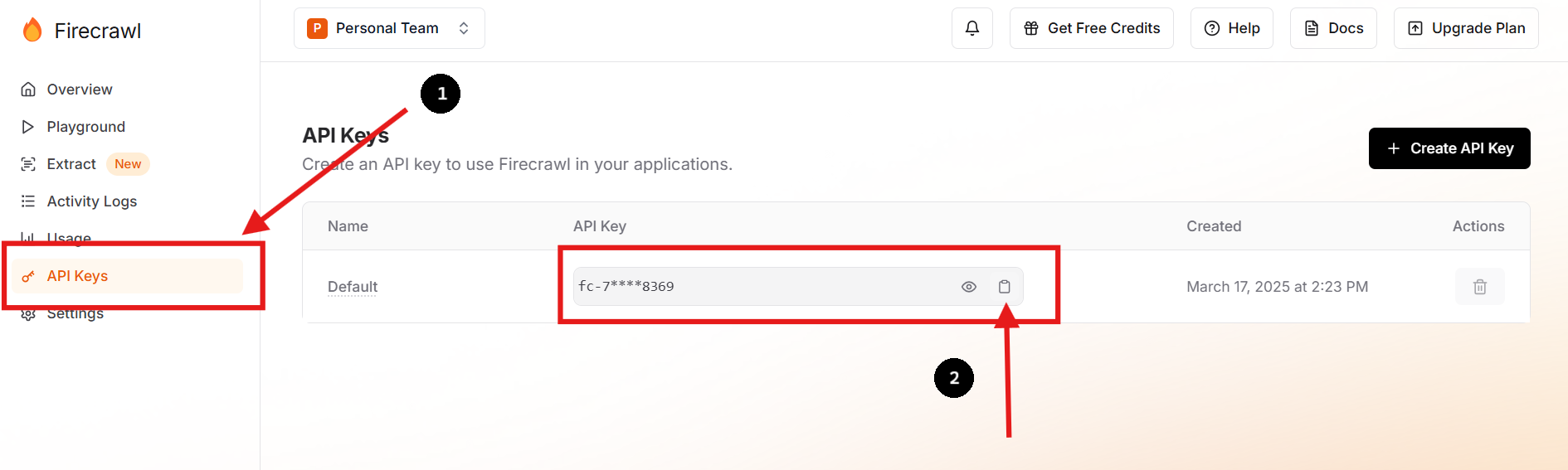
يمكنك أيضًا إنشاء مفتاح API جديد وحذف السابق إذا كنت تفضل ذلك أو تحتاج إلى القيام بذلك.

الخطوة 2: إعداد بيئتك
في مجلد مشروعك، قم بإنشاء ملف .env لتخزين مفتاح API الخاص بك بشكل آمن كمتغير بيئي. يمكنك القيام بذلك عن طريق تشغيل الأوامر التالية في الطرفية الخاصة بك:
touch .env
echo "FIRECRAWL_API_KEY='fc-YOUR-KEY-HERE'" >> .envتساعد هذه الطريقة على إبقاء المعلومات الحساسة خارج قاعدة التعليمات البرمجية الرئيسية، مما يعزز الأمان ويسهل إدارة التكوين.
الخطوة 3: تثبيت Firecrawl SDK
لمستخدمي بايثون، قم بتثبيت Firecrawl SDK باستخدام pip:
pip install firecrawl الخطوة 4: استخدام وظيفة "استخراج" الخاصة بـ Firecrawl
إليك مثال بسيط حول كيفية استخراج بيانات من موقع باستخدام Firecrawl SDK:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Define the URL to scrape
url = "https://www.python-unlimited.com/webscraping/hotels.php?page=1"
# Scrape the website
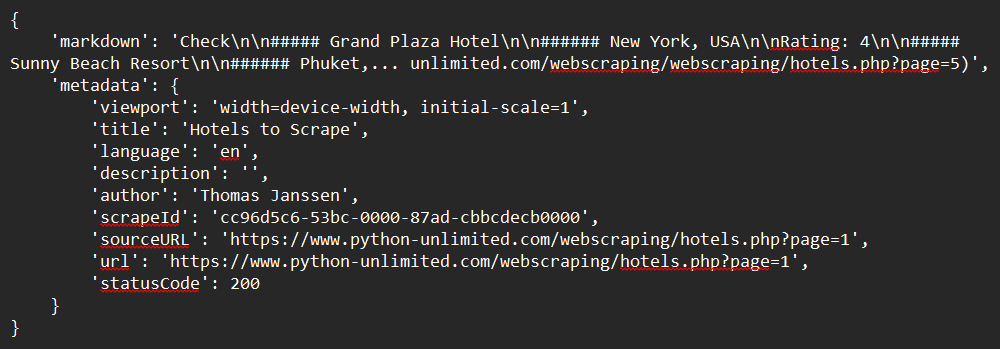
response = app.scrape_url(url)
# Print the response
print(response)نموذج المخرجات:
الخطوة 5: استخدام وظيفة "زحف" الخاصة بـ Firecrawl
هنا سنرى مثالًا بسيطًا حول كيفية زحف موقع باستخدام Firecrawl SDK:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Crawl a website and capture the response:
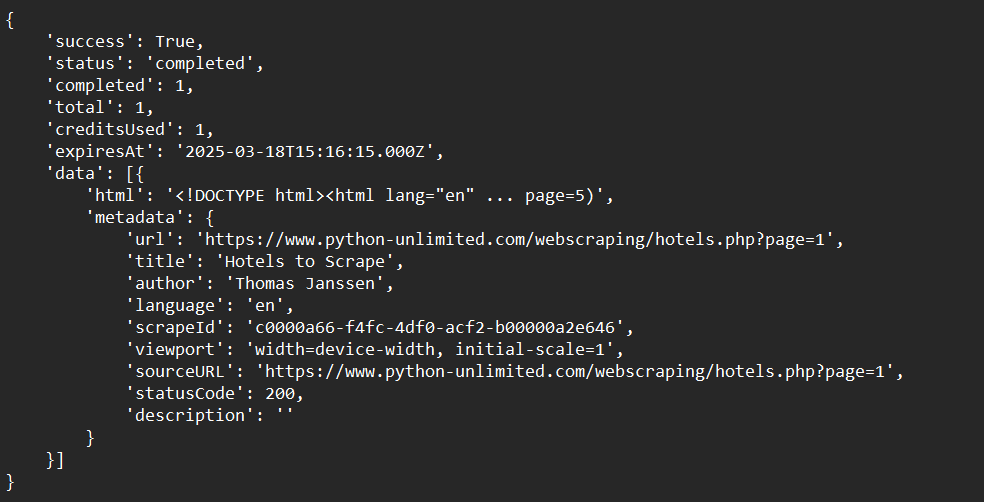
crawl_status = app.crawl_url(
'https://www.python-unlimited.com/webscraping/hotels.php?page=1',
params={
'limit': 100,
'scrapeOptions': {'formats': ['markdown', 'html']}
},
poll_interval=30
)
print(crawl_status)نموذج المخرجات:
الخطوة 6: استخدام وظيفة "خريطة" الخاصة بـ Firecrawl
إليك مثال بسيط حول كيفية رسم بيانات موقع باستخدام Firecrawl SDK:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Map a website:
map_result = app.map_url('https://www.python-unlimited.com/webscraping/hotels.php?page=1')
print(map_result)نموذج المخرجات:

الخطوة 7: استخدام وظيفة "استخراج" الخاصة بـ Firecrawl (نسخة تجريبية مفتوحة)
إليك مثال بسيط حول كيفية استخراج بيانات موقع باستخدام Firecrawl SDK:
from firecrawl import FirecrawlApp
from pydantic import BaseModel, Field
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Define schema to extract contents into
class ExtractSchema(BaseModel):
company_mission: str
supports_sso: bool
is_open_source: bool
is_in_yc: bool
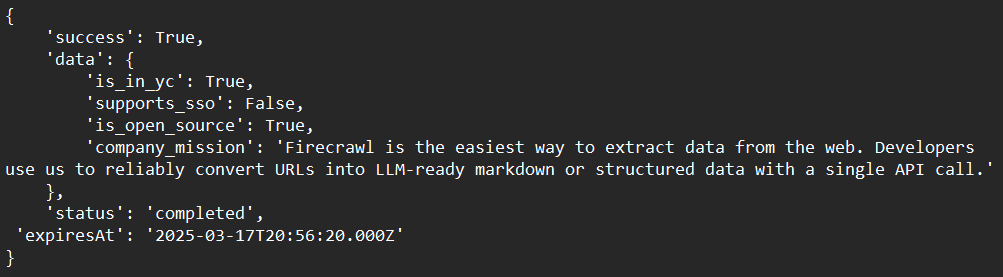
# Call the extract function and capture the response
response = app.extract([
'https://docs.firecrawl.dev/*',
'https://firecrawl.dev/',
'https://www.ycombinator.com/companies/'
], {
'prompt': "Extract the data provided in the schema.",
'schema': ExtractSchema.model_json_schema()
})
# Print the response
print(response)نموذج المخرجات:
تقنيات متقدمة مع Firecrawl
التعامل مع المحتوى الديناميكي
يمكن لـ Firecrawl التعامل مع المحتوى القائم على JavaScript الديناميكي باستخدام المتصفحات ذات الرأس الخالي من الزر لمعاينة الصفحات قبل الاستخراج. يضمن هذا التقاط جميع المحتويات، حتى لو تم تحميلها ديناميكيًا.
تجاوز حواجز استخراج البيانات
استخدم ميزات Firecrawl المدمجة لتجاوز حواجز استخراج البيانات الشائعة، مثل CAPTCHA أو حدود الاستخدام. يتضمن ذلك تدوير مستخدمي الوكلاء وعناوين IP لتقليد حركة المرور الطبيعية.
دمج مع LLMs
اجمع بين Firecrawl وLLMs مثل LangChain لبناء سير عمل قوي للذكاء الاصطناعي. على سبيل المثال، يمكنك استخدام Firecrawl لجمع البيانات ثم إدخالها في LLM لتحليلات أو مهام توليد.
استكشاف المشكلات الشائعة
المشكلة: "مفتاح API غير معترف به"
الحل: تأكد من أن مفتاح API الخاص بك مخزن بشكل صحيح كمتغير بيئي أو في ملف .env.
المشكلة: "الزحف ببطء"
الحل: استخدم الزحف غير المتزامن لتسريع العملية. يدعم Firecrawl الطلبات المتزامنة لتحسين الكفاءة.
المشكلة: "المحتوى لم يتم استخراجه بشكل صحيح"
الحل: تحقق مما إذا كان الموقع يستخدم محتوى ديناميكي. إذا كان الأمر كذلك، تأكد من تكوين Firecrawl للتعامل مع عرض JavaScript.
الاستنتاج
تهانينا على إكمال هذا الدليل الشامل للمبتدئين حول Firecrawl! لقد تناولنا كل ما تحتاج لمعرفته حول البدء - من ماهية Firecrawl، إلى تعليمات التثبيت التفصيلية، وأمثلة الاستخدام، وخيارات التخصيص المتقدمة. بحلول الآن، يجب أن يكون لديك فهم واضح لكيفية:
- إعداد وتثبيت Firecrawl في بيئة التطوير الخاصة بك.
- تهيئة وتشغيل Firecrawl لاستخراج وزحف ورسم البيانات بكفاءة.
- استكشاف الأخطاء في عمليات الزحف لديك لتلبية احتياجاتك الخاصة.
Firecrawl أداة قوية للغاية يمكن أن تبسط سير العمل لاستخراج البيانات بشكل كبير. تعد مرونتها وكفاءتها وسهولة تكاملها خيارًا مثاليًا لتحديات الزحف الحديثة.
حان الوقت الآن لوضع مهاراتك الجديدة قيد التنفيذ. ابدأ في تجربة مواقع ويب مختلفة، وضبط محللاتك، ودمجها مع أدوات إضافية لإنشاء حل مخصص حقًا يلبي متطلباتك الفريدة.
هل أنت مستعد لزيادة سرعة سير عملية استخراج البيانات لديك؟ قم بتنزيل Apidog مجانًا اليوم واكتشف كيف يمكن أن يعزز تكامل Firecrawl الخاص بك!