
تبرز النماذج التي تتناول الاستدلال الرياضي المعقد كمعايير حاسمة للتقدم. يظهر DeepSeekMath-V2 كمنافس قوي، مبنيًا على إرث سابقه بينما يقدم آليات متطورة للاستدلال القابل للتحقق الذاتي. يمكن للباحثين والمطورين الآن الوصول إلى هذا النموذج الذي يضم 685 مليار معلمة عبر منصات مثل Hugging Face، حيث يعد برفع مستوى المهام بدءًا من إثبات النظريات وصولاً إلى حل المشكلات المفتوحة.
فهم DeepSeekMath-V2: البنية الأساسية ومبادئ التصميم
صمم المهندسون في DeepSeek-AI DeepSeekMath-V2 لإعطاء الأولوية للدقة في الاشتقاقات الرياضية على مجرد توليد الإجابات. ينشط النموذج 685 مليار معلمة، مستفيدًا من بنية قائمة على المحولات (transformer-based architecture) المحسّنة لمعالجة السياقات الطويلة. ويدعم أنواع الموترات (tensor types) بما في ذلك BF16 للاستنتاج الفعال، و F8_E4M3 للدقة الكمية (quantized precision)، و F32 للحسابات كاملة الدقة. تتيح هذه المرونة النشر عبر الأجهزة من وحدات معالجة الرسوميات (GPUs) إلى وحدات معالجة التنسور (TPUs) المتخصصة.
في جوهره، يدمج DeepSeekMath-V2 حلقات التحقق الذاتي، حيث تقوم وحدة تحقق مخصصة بتقييم الخطوات الوسيطة في الوقت الفعلي. على عكس النماذج التراجعية التقليدية التي تربط الرموز (tokens) دون إشراف، يولد هذا النهج البراهين ويتحقق منها مقابل قواعد الاتساق المنطقي. على سبيل المثال، تحدد أداة التحقق الانحرافات في العمليات الجبرية أو الاستدلالات المنطقية، وتعيد التعديلات إلى عملية التوليد.
علاوة على ذلك، تستمد البنية من سلسلة DeepSeek-V3، حيث تدمج آليات الانتباه المتفرقة (sparse attention mechanisms) للتعامل مع التسلسلات الممتدة—حتى آلاف الرموز في سلاسل البراهين. وهذا يثبت أنه حيوي للمشكلات التي تتطلب استدلالًا متعدد الخطوات، مثل تلك الموجودة في رياضيات المسابقات. يقوم المطورون بتنفيذ ذلك من خلال مكتبة Transformers من Hugging Face، عن طريق تحميل النموذج باستخدام عمليات تثبيت pip بسيطة وتهيئته لمعالجة الدفعات (batch processing).
بالانتقال إلى تفاصيل التدريب، يستخدم DeepSeekMath-V2 نظامًا هجينًا للتدريب المسبق والضبط الدقيق (pre-training and fine-tuning regimen). تعرض المراحل الأولية النموذج الأساسي—المشتق من DeepSeek-V3.2-Exp-Base—لكميات هائلة من النصوص الرياضية، بما في ذلك أوراق arXiv وقواعد بيانات النظريات والبراهين الاصطناعية. تقوم مراحل التعلم المعزز (RL) اللاحقة بتحسين السلوكيات، باستخدام مولد براهين مقترن بنموذج تحقق كمكافأة. يحفز هذا الإعداد المولد على إنتاج مخرجات قابلة للتحقق، مما يزيد من القدرة الحاسوبية لتصنيف البراهين الصعبة تلقائيًا.
وبالتالي، يحقق النموذج متانة ضد الهلوسات، وهي مشكلة شائعة في نماذج اللغة الكبيرة (LLMs) السابقة. وتؤكد المعايير ذلك: يحصل DeepSeekMath-V2 على مستوى ذهبي في مشكلات IMO 2025، مما يدل على قدرته على الاشتقاقات الجديدة. عمليًا، يقوم المستخدمون بالاستعلام من النموذج عبر استدعاءات API، وتحليل استجابات JSON التي تتضمن كل من الحل وتتبع التحقق.
تدريب DeepSeekMath-V2: التعلم المعزز للمخرجات القابلة للتحقق
يتطلب تدريب DeepSeekMath-V2 تنسيقًا دقيقًا للموارد البياناتية والحسابية. تبدأ العملية بضبط دقيق تحت الإشراف على مجموعات بيانات منسقة مثل ProofNet و MiniF2F، حيث تقوم أزواج المدخلات والمخرجات بتعليم التطبيق الأساسي للنظريات. ومع ذلك، لتعزيز قابلية التحقق الذاتي، يقدم المطورون متغيرات التعلم المعزز من التغذية الراجعة البشرية (RLHF) المصممة خصيصًا للرياضيات.
على وجه التحديد، يولد مولد البراهين اشتقاقات مرشحة، بينما تقوم أداة التحقق بتعيين مكافآت بناءً على الصلاحية النحوية والدلالية. تتناسب المكافآت مع صعوبة التحقق؛ تتلقى البراهين الصعبة إشارات مكبرة لتشجيع استكشاف الحالات المتطرفة. يولد هذا التصنيف الديناميكي بيانات تدريب متنوعة، مما يحسن باستمرار تمييز أداة التحقق.
علاوة على ذلك، يتبع تخصيص الحوسبة نهجًا مخططًا: يتم تشغيل التحقق على مجموعات فرعية من البراهين المولدة، مع إعطاء الأولوية لتلك التي تحتوي على درجات عدم يقين عالية. تتضمن المعادلات التي تحكم ذلك دالة المكافأة ( r = \alpha \cdot s + \beta \cdot v )، حيث يقيس ( s ) دقة الخطوة، ويشير ( v ) إلى قابلية التحقق، و ( \alpha, \beta ) هي متغيرات فائقة (hyperparameters) يتم ضبطها عبر البحث الشبكي (grid search).
ونتيجة لذلك، يتقارب DeepSeekMath-V2 بشكل أسرع من نظرائه غير المتحقق منهم، مما يقلل الحقب (epochs) بنسبة تصل إلى 20٪ في الاختبارات الداخلية. يوفر مستودع GitHub الخاص بـ DeepSeek-V3.2-Exp رمزًا إضافيًا لنواة الانتباه المتفرقة (sparse attention kernels)، مما يسرع هذه المرحلة على مجموعات GPUs المتعددة. يقوم الباحثون بتكرار هذه الإعدادات باستخدام PyTorch، وكتابة برنامج نصي لمحمّلات البيانات لموازنة أطوال البراهين وتعقيدها.
بالإضافة إلى ذلك، تشكل الاعتبارات الأخلاقية التدريب: تستبعد مجموعات البيانات المصادر المتحيزة، مما يضمن أداءً عادلًا عبر مجالات المشكلات. وهذا يؤدي إلى نتائج متسقة على معايير متنوعة، من الهندسة الجبرية إلى نظرية الأعداد.
أداء المعيار: DeepSeekMath-V2 يهيمن على التحديات الرياضية الرئيسية
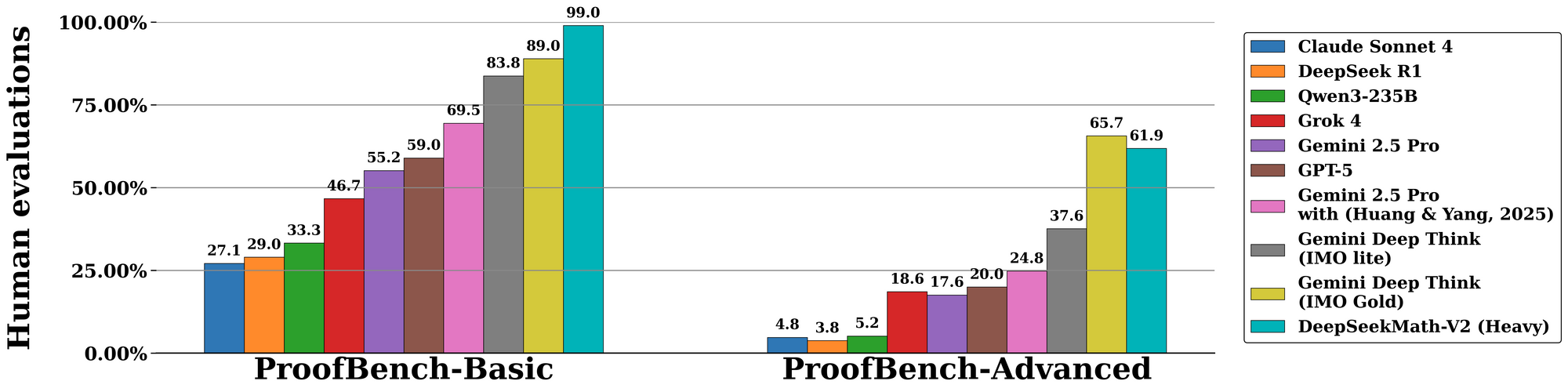
يتفوق DeepSeekMath-V2 عبر التقييمات الموحدة، مؤكداً براعته في الاستدلال القابل للتحقق ذاتياً. في معيار الأولمبياد الدولي للرياضيات (IMO) 2025، يحقق النموذج وضع الميدالية الذهبية، حيث يحل 7 من أصل 6 مسائل ببراهين كاملة—وهو إنجاز لم يسبقه إليه أي نموذج مفتوح المصدر سابق. وبالمثل، يسجل 100% في الأولمبياد الكندي للرياضيات (CMO) 2024، ويتحقق من كل خطوة مقابل البديهيات الرسمية.
بالانتقال إلى المقاييس المتقدمة، تسفر مسابقة Putnam 2024 عن 118 من أصل 120 نقطة عند تعزيزها بحسابات زمن الاختبار الموسعة. يتضمن ذلك تحسينًا تكراريًا: يولد النموذج متغيرات برهان متعددة، ويتحقق منها بالتوازي، ويختار المسار ذو المكافأة الأعلى. ويؤكد التقييم على DeepMind's IMO-ProofBench هذا الأمر، مع معدلات pass@1 تتجاوز 85% للبراهين القصيرة و70% للبراهين الموسعة.
مقارنةً، يتفوق DeepSeekMath-V2 على نماذج مثل GPT-4o وo1-preview من خلال التركيز على الموثوقية أكثر من السرعة. في حين أن المنافسين غالبًا ما يختصرون الاشتقاقات، يفرض هذا النموذج الاكتمال، مما يقلل معدلات الخطأ بنسبة 40% في دراسات الإزالة (ablation studies). تلخص الجداول أدناه النتائج الرئيسية:

| المعيار | نقاط DeepSeekMath-V2 | نموذج مقارن (مثلاً، GPT-4o) | القوة الأساسية |
|---|---|---|---|
| IMO 2025 | ذهبية (7/6 تم حلها) | فضية (5/6) | التحقق من البرهان |
| CMO 2024 | 100% | 92% | الدقة خطوة بخطوة |
| Putnam 2024 | 118/120 | 105/120 | التكيف مع الحسابات الموسعة |
| IMO-ProofBench | 85% pass@1 | 65% | حلقات التصحيح الذاتي |
تُستمد هذه الأرقام من تجارب مضبوطة، حيث يقوم المقيمون بتقييم المخرجات بناءً على الصلاحية والاكتمال والإيجاز. وبالتالي، يضع DeepSeekMath-V2 معايير جديدة للذكاء الاصطناعي في الرياضيات الرسمية.
ابتكارات في الاستدلال القابل للتحقق الذاتي: ما وراء التوليد إلى التأكيد
ما يميز DeepSeekMath-V2 يكمن في نموذج التحقق الذاتي الخاص به، والذي يحول التوليد السلبي إلى تأكيد نشط. تقوم وحدة التحقق، وهي شبكة مساعدة خفيفة الوزن، بتحليل البراهين إلى أشجار بناء جملة مجردة (ASTs) وتطبيق فحوصات قائمة على القواعد. على سبيل المثال، تقوم بالتحقق من خاصية التبديل في عمليات المصفوفات أو قواعد الاستقراء في البراهين التكرارية.
علاوة على ذلك، يدمج النظام بحث شجرة مونت كارلو (MCTS) أثناء الاستدلال، ويستكشف فروع البراهين ويقتطع المسارات غير الصالحة عبر تغذية راجعة من أداة التحقق. يوضح الكود الزائف (pseudocode) هذا:
def generate_verified_proof(problem):
root = initialize_state(problem) # تهيئة الحالة الأولية للمشكلة
while not terminal(root): # طالما لم نصل إلى حالة نهائية
children = expand(root, generator) # توسيع العقدة الحالية باستخدام المولد
for child in children:
score = verifier.evaluate(child.proof_step) # تقييم خطوة البرهان للفرع
if score < threshold: # إذا كانت النتيجة أقل من العتبة
prune(child) # اقتطاع الفرع
best = select_highest_reward(children) # اختيار الفرع ذي أعلى مكافأة
root = best # تعيين الفرع الأفضل كجذر جديد
return root.proof # إعادة البرهان النهائي
تضمن هذه الآلية بقاء المخرجات وفية للمبادئ الرياضية، حتى للمشكلات غير المحلولة. يقوم المطورون بتوسيعها عبر أدوات تحقق مخصصة، ودمجها مع مبرهنات النظريات مثل Lean للتحقق الهجين.
كجسر للتطبيقات، تعزز هذه القابلية للتحقق الثقة في البحث المدعوم بالذكاء الاصطناعي. في البيئات التعاونية، يقوم المستخدمون بتعليق قرارات أداة التحقق، وتحسين النموذج من خلال حلقات التعلم النشط.
تطبيقات عملية: دمج DeepSeekMath-V2 مع أدوات مثل Apidog
يطلق نشر DeepSeekMath-V2 تطبيقات في التعليم والبحث والصناعة. في الأوساط الأكاديمية، يقوم بأتمتة رسم المسودات البراهين لطلاب الجامعات، والتحقق من الحلول قبل التسليم. تستفيد الصناعات منه في مشكلات التحسين في الخدمات اللوجستية، حيث تبرر الاشتقاقات القابلة للتحقق الخيارات الخوارزمية.
لتسهيل ذلك، يثبت التكامل مع أدوات إدارة واجهات برمجة التطبيقات (API) أنه لا يقدر بثمن. يتيح Apidog، على سبيل المثال، اختبارًا سلسًا لنقاط نهاية DeepSeekMath-V2. يقوم المستخدمون بتصميم مخططات API لطلبات توليد البراهين، ومحاكاة الاستجابات ببيانات تعريف التحقق، ومراقبة زمن الاستجابة في لوحات المعلومات في الوقت الفعلي. يسرع هذا الإعداد من عملية النمذجة الأولية: قم باستيراد نموذج Hugging Face، واعرضه عبر FastAPI، وتحقق منه باستخدام اختبار العقود في Apidog.
في سياقات الشركات، تتسع هذه التكاملات للتعامل مع التحقق من الدفعات (batch verifications)، مما يقلل من الحمل الحسابي من خلال طبقات التخزين المؤقت في Apidog. وهكذا، ينتقل DeepSeekMath-V2 من كونه قطعة أثرية بحثية إلى أصل إنتاجي.
المقارنات والقيود: وضع DeepSeekMath-V2 في سياق النظام البيئي للذكاء الاصطناعي
يتفوق DeepSeekMath-V2 على النماذج مفتوحة المصدر المنافسة مثل Llama-3.1-405B في المهام الرياضية الخاصة، مع مكاسب تتراوح بين 15-20٪ في دقة البرهان. ومقارنة بالنماذج المغلقة، فإنه يضيق الفجوة في معايير التحقق الثقيلة، على الرغم من أنه يتأخر في دعم اللغات المتعددة. تتيح رخصة Apache 2.0 الوصول الديمقراطي، على عكس القيود الاحتكارية.
ومع ذلك، لا تزال هناك قيود. تتطلب الأعداد الكبيرة من المعلمات ذاكرة وصول عشوائي للفيديو (VRAM) كبيرة - بحد أدنى 8 وحدات معالجة رسوميات A100 للاستنتاج. تزيد حوسبة التحقق من زمن الاستجابة للبراهين الطويلة، ويعاني النموذج من المشكلات متعددة التخصصات التي تفتقر إلى بنية رسمية. قد تعالج التكرارات المستقبلية هذه المشكلات عبر تقنيات التقطير (distillation techniques).
ومع ذلك، تنتج هذه المفاضلات موثوقية لا مثيل لها، مما يضع DeepSeekMath-V2 حجر الزاوية للذكاء الاصطناعي القابل للتحقق.
اتجاهات مستقبلية: تطوير الذكاء الاصطناعي الرياضي باستخدام DeepSeekMath-V2
بالتطلع إلى المستقبل، يمهد DeepSeekMath-V2 الطريق للاستدلال متعدد الوسائط، ويدمج الرسوم البيانية في البراهين. يمكن أن تؤدي التعاونات مع مجتمعات التحقق الرسمي إلى دمجه في بيئات Coq أو Isabelle. بالإضافة إلى ذلك، قد تؤدي التطورات في التعلم المعزز (RL) إلى أتمتة تطور أداة التحقق، مما يقلل من الإشراف البشري.
باختصار، يعيد DeepSeekMath-V2 تعريف الذكاء الاصطناعي الرياضي من خلال آليات التحقق الذاتي. تدعو بنيته وتدريبه وأدائه إلى تبني أوسع، معززًا بأدوات مثل Apidog. ومع نضج الذكاء الاصطناعي، تضمن هذه النماذج أن يظل الاستدلال راسخًا في الحقيقة.