
يبحث المطورون والباحثون عن نماذج تُعطي الأولوية للاستدلال لتشغيل الوكلاء المستقلين. تلبي DeepSeek-V3.2 ونسختها المتخصصة، DeepSeek-V3.2-Speciale، هذه الحاجة بدقة. تعتمد هذه النماذج على الإصدارات السابقة، مثل DeepSeek-V3.2-Exp، لتقديم قدرات معززة في الاستدلال المنطقي وحل المشكلات الرياضية وسير عمل الوكلاء. يحصل المهندسون الآن على أدوات تعالج الاستفسارات المعقدة بكفاءة، متجاوزة المعايير التي حددتها الأنظمة الرائدة ذات المصدر المغلق.
عندما نفحص هذه النماذج، يبقى التركيز على مزاياها التقنية. أولاً، يتيح الأساس مفتوح المصدر تجربة واسعة. ثم، يوفر الوصول إلى واجهة برمجة التطبيقات (API) خيارات نشر قابلة للتوسع. في جميع أنحاء هذا المنشور، توضح البيانات من المصادر الرسمية والمعايير إمكاناتها.
إطلاق DeepSeek-V3.2 كمصدر مفتوح: أساس لتطوير الذكاء الاصطناعي التعاوني
تطلق DeepSeek نموذج DeepSeek-V3.2 بموجب ترخيص MIT المتساهل، مما يعزز انتشاره على نطاق واسع بين مجتمع الذكاء الاصطناعي. يمكّن هذا القرار المطورين من فحص النموذج وتعديله ونشره دون قيود. ونتيجة لذلك، تسرع الفرق الابتكار في تطبيقات الوكلاء، من إنشاء الشفرة الآلي إلى مسارات الاستدلال متعددة الخطوات.
تتمحور بنية النموذج حول DeepSeek Sparse Attention (DSA)، وهي آلية تعمل على تحسين المتطلبات الحسابية لمعالجة السياقات الطويلة. تستخدم DSA التشتت الدقيق، مما يقلل من تعقيد الانتباه من التربيعي إلى ما يقرب من الخطي مع الحفاظ على جودة المخرجات. على سبيل المثال، في التسلسلات التي تتجاوز 128,000 رمز - أي ما يعادل مئات الصفحات من النصوص - يحافظ النموذج على سرعات استنتاج تنافسية مع نظيراته الأصغر حجماً.
يتميز DeepSeek-V3.2 بـ 685 مليار معلمة، موزعة عبر أنواع الموتر مثل BF16 وF8_E4M3 وF32 للكمي المرن. يتضمن التدريب إطار عمل تعلم معزز (RL) قابل للتوسع، حيث يتعلم الوكلاء من خلال التغذية الراجعة التكرارية على المهام الاصطناعية. يعزز هذا النهج مسارات الاستدلال، مما يمكّن النموذج من ربط الخطوات المنطقية بفعالية. بالإضافة إلى ذلك، يقوم خط أنابيب توليف مهام الوكلاء واسع النطاق بتوليد سيناريوهات متنوعة، ويمزج الاستدلال مع استدعاء الأدوات. يمكن للمطورين الوصول إلى هذه المهام عبر مستودعات Hugging Face، حيث توجد الأوزان المدربة مسبقًا والنماذج الأساسية.
يبدأ الاستخدام بترميز المدخلات بتنسيق متوافق مع OpenAI، وهو ما تسهله نصوص بايثون في دليل ترميز النموذج. يقدم قالب الدردشة وضع "التفكير بالأدوات"، حيث يتداول النموذج قبل التصرف. تنتج معلمات العينات - درجة حرارة 1.0 و top_p عند 0.95 - مخرجات متسقة وإبداعية. للنشر المحلي، يوفر مستودع GitHub لـ DeepSeek-V3.2-Exp عوامل تشغيل محسنة لـ CUDA، بما في ذلك نسخة TileLang لأنظمة GPU البيئية المتنوعة.
علاوة على ذلك، يضمن ترخيص MIT قابلية التطبيق المؤسسي. تقوم المنظمات بتخصيص النموذج للوكلاء الخاصين دون عقبات قانونية. تُثبت المعايير هذا الانفتاح: يحقق DeepSeek-V3.2 تكافؤًا مع GPT-5 في درجات الاستدلال المجمعة، كما هو مفصل في التقرير الفني. وبالتالي، فإن إطلاق المصدر المفتوح لا يُضفي الطابع الديمقراطي على الوصول فحسب، بل يُقارن أيضًا بعمالقة الملكية الفكرية.
DeepSeek-V3.2-Speciale: تحسينات مخصصة لمتطلبات الاستدلال المتقدمة
بينما يخدم DeepSeek-V3.2 الأغراض العامة، يستهدف DeepSeek-V3.2-Speciale الاستدلال العميق حصريًا. يطبق هذا المتغير تدريبًا لاحقًا عالي الحساب على نفس قاعدة المعلمات 685B، مما يعزز الكفاءة في حل المشكلات المجردة. ونتيجة لذلك، يحصل على ما يعادل الميداليات الذهبية في أولمبياد الرياضيات الدولي (IMO) وأولمبياد المعلوماتية الدولي (IOI) لعام 2025، متفوقًا على المستويات البشرية في الحلول المقدمة.
من الناحية المعمارية، يعكس DeepSeek-V3.2-Speciale نسخته الشقيقة مع DSA للتعامل الفعال مع السياقات الطويلة. ومع ذلك، يركز التدريب اللاحق على RL على مجموعات بيانات منسقة، بما في ذلك مشاكل الأولمبياد وسلاسل وكلاء اصطناعية. تعمل هذه العملية على صقل الاستدلال المتسلسل للأفكار (CoT)، حيث يقوم النموذج بتفكيك الاستعلامات إلى خطوات قابلة للتحقق. وتجدر الإشارة إلى أنه يتجاهل دعم استدعاء الأدوات لتركيز الموارد على الاستدلال البحت، مما يجعله مثاليًا للمهام التي تتطلب الكثير من الحسابات مثل إثبات النظريات.
تبرز بطاقة نموذج Hugging Face الاختلافات: يعالج DeepSeek-V3.2-Speciale المدخلات دون تبعيات خارجية، معتمداً على التفكير الداخلي. يقوم المطورون بترميز الرسائل بالمثل، ولكن المخرجات تتطلب تحليلًا مخصصًا بسبب عدم وجود قوالب Jinja. يصبح التعامل مع الأخطاء في كود الإنتاج أمرًا حاسمًا، حيث تتطلب الاستجابات المشوهة طبقات تحقق.
في المقارنات، يتجاوز DeepSeek-V3.2-Speciale أداء GPT-5-High في مجموعات الاستدلال ويتوافق مع Gemini-3.0-Pro. على سبيل المثال، في AIME 2025 (Pass@1)، يسجل 93.1%، متفوقًا على Claude-4.5-Sonnet بنسبة 90.2%. تنبع هذه المكاسب من التعلم المعزز المستهدف، والذي يحاكي السيناريوهات العدائية لتعزيز السلاسل المنطقية. وبالتالي، ينشر الباحثون النموذج للمهام الرائدة، مثل التحقق من كود نهائيات بطولة العالم ICPC أو إثباتات CMO 2025، مع توفر الأصول في المستودع.
بشكل عام، يوسع DeepSeek-V3.2-Speciale نطاق النظام البيئي. إنه يكمل النموذج الأساسي من خلال التعامل مع الحالات الهامشية حيث تتفوق العمق على الاتساع، مما يضمن تغطية شاملة لمنشئي الوكلاء.
معايير القدرات الاستدلالية والوكيلية: رؤى تعتمد على البيانات
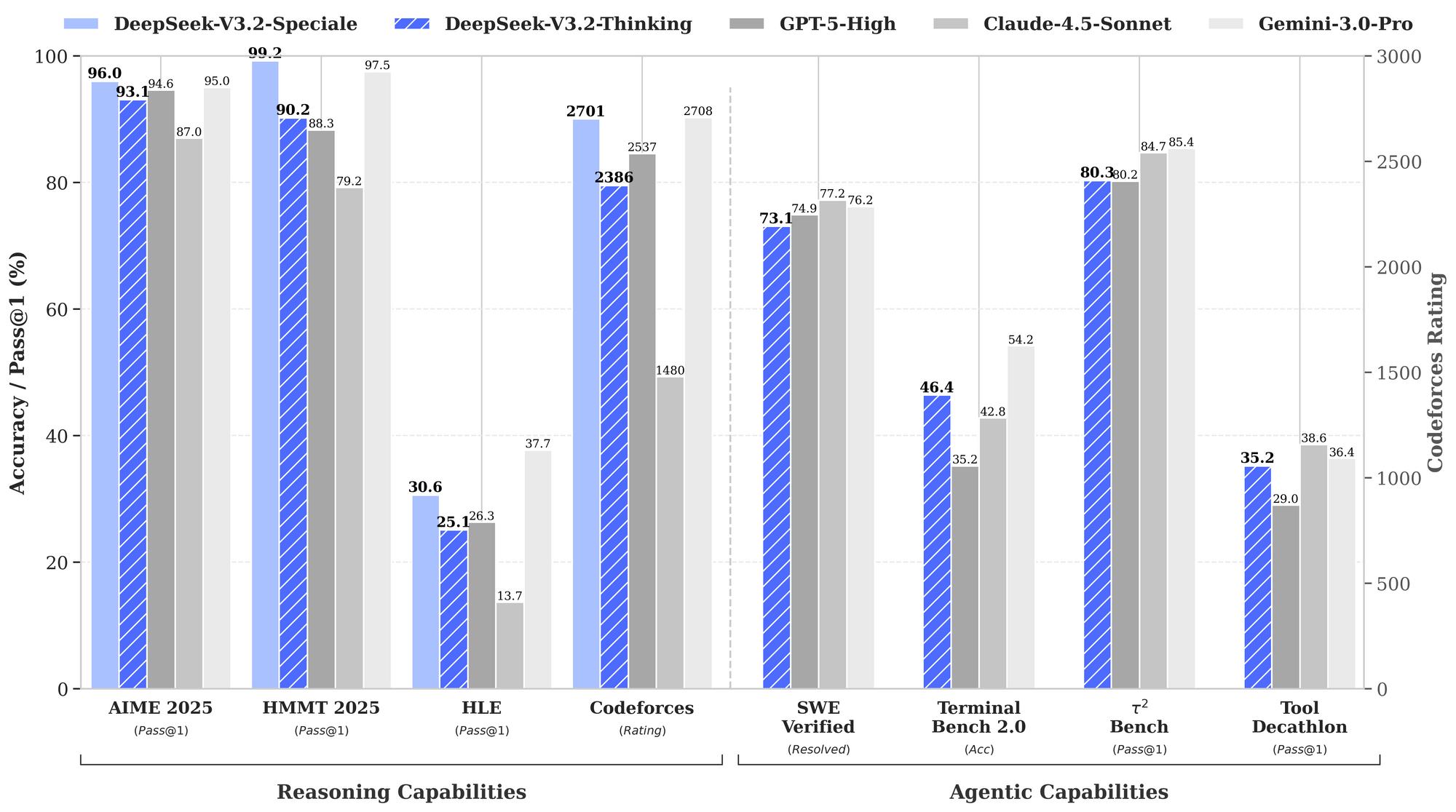
تقوم المعايير بتحديد نقاط قوة DeepSeek-V3.2، خاصة في مجالات الاستدلال والوكلاء. يوضح الرسم البياني للأداء المقدم معدلات النجاح والدقة عبر التقييمات الرئيسية، مما يضع هذه النماذج في مواجهة GPT-5-High و Claude-4.5-Sonnet و Gemini-3.0-Pro.
في قدرات الاستدلال، يتصدر DeepSeek-V3.2-Thinking (تكوين حاسوبي عالي شبيه بـ Speciale) بنسبة 93.1% على AIME 2025 (Pass@1)، متجاوزًا GPT-5-High بنسبة 90.8% و Claude-4.5-Sonnet بنسبة 87.0%. وبالمثل، في HMMT 2025، يحقق 94.6%، مما يعكس تفكيكًا رياضيًا فائقًا. يظهر تقييم HLE نسبة نجاح 95.0% في Pass@1، حيث يحل النموذج ألغاز المنطق الإنجليزي عالية المستوى بأقل عدد من المحاولات المتكررة.
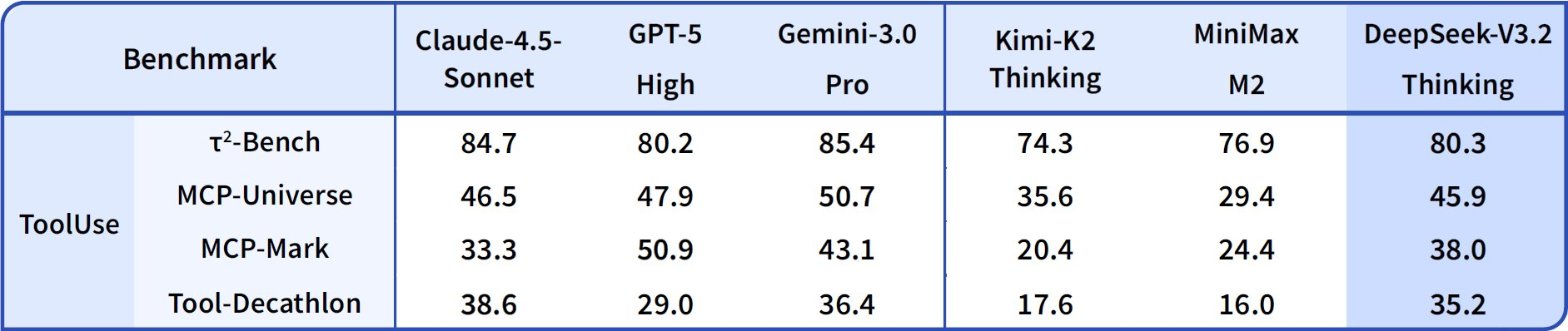
بالانتقال إلى قدرات الوكيل، يتفوق DeepSeek-V3.2 في الترميز واستخدام الأدوات. يصل تصنيف Codeforces إلى 2708 لوضع التفكير، متفوقًا على Gemini-3.0-Pro البالغ 2537. يجمع هذا المقياس المشكلات المحلولة في ظل قيود الوقت، مع التركيز على كفاءة الخوارزميات. في SWE-Verified (المحلول)، يحقق 73.1%، مما يشير إلى اكتشاف الأخطاء الموثوق به وإنشاء الإصلاحات في قواعد الشفرة التي تم التحقق منها.
تبلغ دقة Terminal Bench 2.0 80.3%، حيث يتنقل النموذج في بيئات Shell عبر أوامر اللغة الطبيعية. يسجل T² (Pass@1) 84.8%، بتقييم المهام المعززة بالأدوات مثل استرجاع البيانات وتوليفها. ويصل تقييم الأداة إلى 84.7%، حيث يستدعي النموذج واجهات برمجة التطبيقات ويحلل الاستجابات بدقة.
يعزز DeepSeek-V3.2-Speciale هذه في المجموعات الفرعية للاستدلال النقي. على سبيل المثال، يرفع AIME إلى 99.2% و HMMT إلى 99.0%، مقتربًا من الكمال في الرياضيات على غرار الأولمبياد. ومع ذلك، تنخفض درجات وكالته بدون دعم الأدوات - على سبيل المثال، الأداة عند 73.1% مقابل 84.7% للأساس - مع إعطاء الأولوية للعمق على التكامل.
تُشتق هذه النتائج من بروتوكولات موحدة: يقيس Pass@1 النجاح في محاولة واحدة، بينما تتضمن التقييمات قياسًا على غرار Elo. بالمقارنة مع خطوط الأساس، تسد نماذج DeepSeek الفجوة مفتوحة المصدر، حيث تمكن DSA من توفير 50% من الحسابات على السياقات الطويلة. وبالتالي، لا تُثبت المعايير المزاعم فحسب، بل توجه الاختيار أيضًا: استخدم V3.2 للوكلاء المتوازنين، و Speciale للمنطق المكثف.
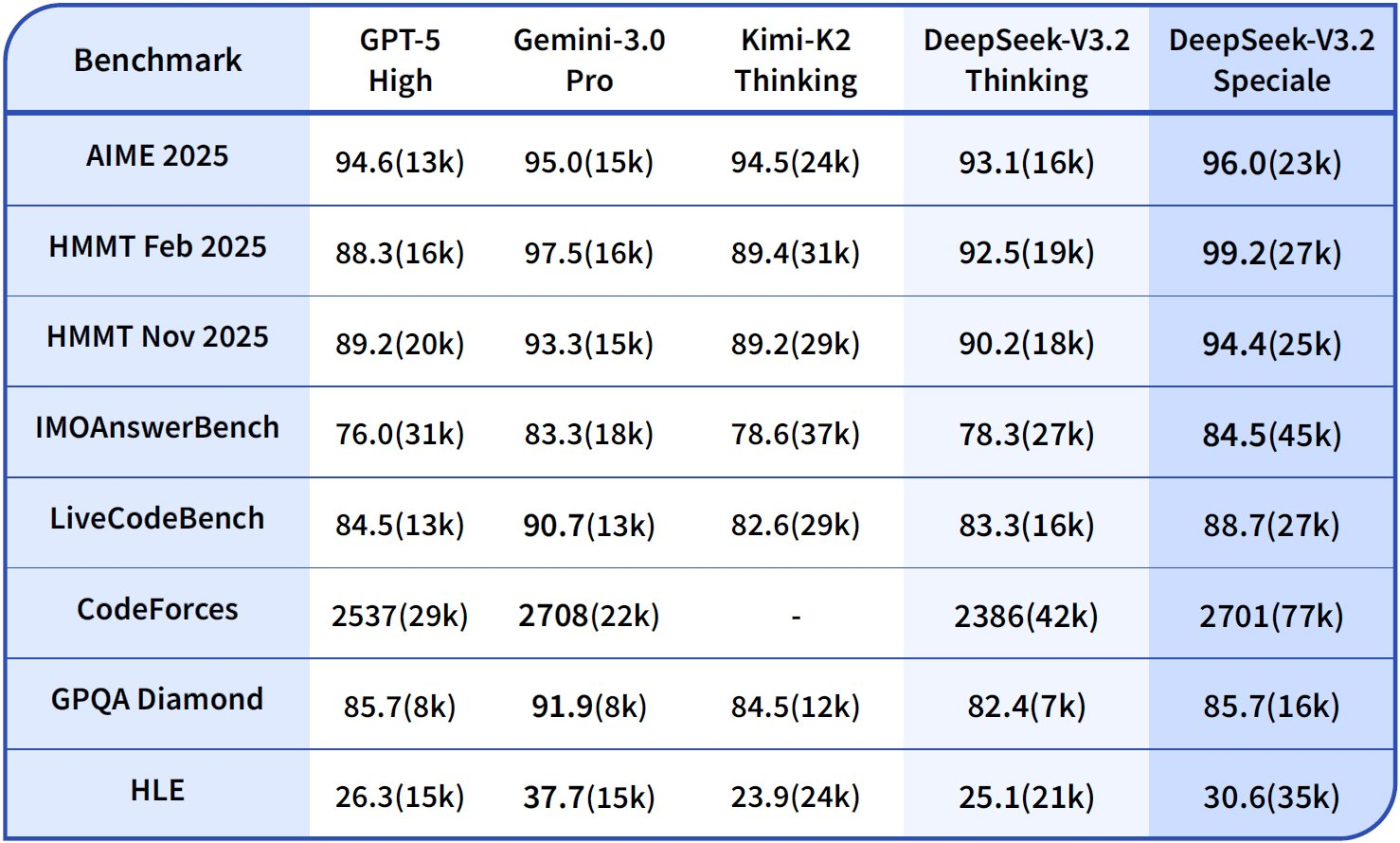
| المعيار | المقياس | DeepSeek-V3.2 | DeepSeek-V3.2-Speciale | GPT-5-High | Claude-4.5-Sonnet | Gemini-3.0-Pro |
|---|---|---|---|---|---|---|
| AIME 2025 | نسبة النجاح@1 (%) | 93.1 | 99.2 | 90.8 | 87.0 | 90.2 |
| HMMT 2025 | نسبة النجاح@1 (%) | 94.6 | 99.0 | 91.4 | 83.3 | 95.0 |
| HLE | نسبة النجاح@1 (%) | 95.0 | 97.5 | 92.8 | 79.2 | 98.3 |
| Codeforces | التقييم | 2701 | 2708 | 2537 | 2386 | 2537 |
| SWE-Verified | تم الحل (%) | 73.1 | 77.2 | 71.9 | 73.1 | 64.4 |
| Terminal Bench 2.0 | الدقة (%) | 80.3 | 80.6 | 84.7 | 85.4 | 80.3 |
| T² | نسبة النجاح@1 (%) | 84.8 | 83.2 | 82.0 | 82.9 | 78.5 |
| الأداة | نسبة النجاح@1 (%) | 84.7 | 73.1 | 74.9 | 77.2 | 76.2 |
يجمع هذا الجدول بيانات الرسم البياني، مسلطًا الضوء على الريادة الثابتة في الاستدلال مع الحفاظ على القدرة التنافسية في الوكالة.
الوصول إلى واجهة برمجة تطبيقات DeepSeek: تكامل سلس للنشر القابل للتوسع
تتيح الأوزان مفتوحة المصدر التشغيل المحلي، لكن الوصول إلى واجهة برمجة التطبيقات (API) يوسع نطاق وكلاء الإنتاج بسهولة. يتم نشر DeepSeek-V3.2 عبر واجهة برمجة التطبيقات الرسمية، جنبًا إلى جنب مع واجهات التطبيق والويب. يقوم المطورون بالمصادقة باستخدام مفاتيح API من لوحة تحكم المنصة، ثم يستعلمون عن نقاط النهاية بتنسيق JSON المتوافق مع OpenAI.
بالنسبة لـ DeepSeek-V3.2-Speciale، يقتصر الوصول على واجهة برمجة التطبيقات (API) فقط، مما يناسب احتياجات الحوسبة العالية دون حمل إضافي محلي. تدعم نقاط النهاية معلمات مثل الأدوات للاستدعاء، على الرغم من أن Speciale يعالج الاستدلال بدون أدوات. تمتد نوافذ السياق إلى 128,000 رمز، مع تحسينات التخزين المؤقت للاستعلامات المتكررة.
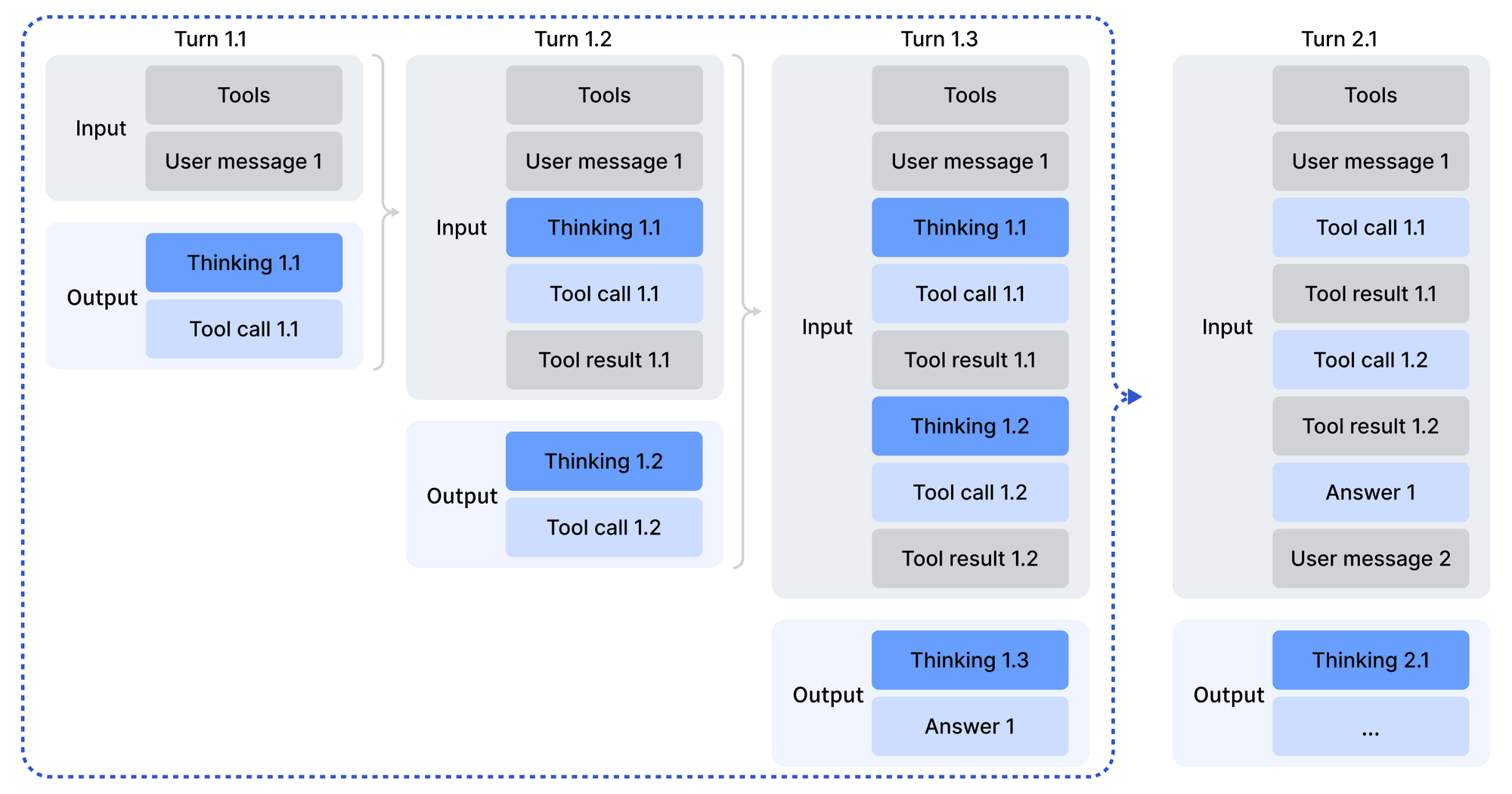
يستفيد التكامل من حزم SDK بلغات بايثون و Node.js و cURL. يرمز استدعاء نموذجي للمطالبات بدور المطور لسيناريوهات الوكيل:
import openai
client = openai.OpenAI(
api_key="your_deepseek_key",
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[{"role": "developer", "content": "Solve this IMO problem: ..."}],
temperature=1.0,
top_p=0.95
)
يقوم هذا الهيكل بتحليل المخرجات عبر السكريبتات المتوفرة، ويتعامل مع استدعاءات الأدوات عند الاقتضاء. وبالتالي، تربط الوكلاء الاستجابات، وتستدعي الخدمات الخارجية في منتصف عملية الاستدلال.
لتعزيز سير العمل هذا، يثبت Apidog أنه لا يقدر بثمن. فهو يحاكي استجابات واجهة برمجة التطبيقات، ويوثق المخططات، ويختبر الحالات الهامشية — وهو ما ينطبق مباشرة على نقاط نهاية DeepSeek. قم بتنزيل Apidog مجانًا لتصور تدفقات الطلبات وضمان منطق وكيل قوي قبل النشر.
تسعير واجهة برمجة التطبيقات: الكفاءة في التكلفة تلتقي بالأداء العالي
يؤكد تسعير واجهة برمجة تطبيقات DeepSeek على القدرة على تحمل التكاليف، مع إطلاق V3.2-Exp الذي خفض التكاليف إلى النصف مقارنة بـ V3.1-Terminus. يدفع المطورون لكل مليون رمز: 0.028 دولارًا لعمليات الوصول إلى ذاكرة التخزين المؤقت للمدخلات، و 0.28 دولارًا لعمليات عدم الوصول، و 0.42 دولارًا للمخرجات. يكافئ هذا الهيكل السياقات المتكررة، وهو أمر حيوي للحلقات الوكيلية.
مقارنة بالمنافسين، هذه الأسعار أقل من أسعار GPT-5 التي تتراوح بين 15 و 75 دولارًا لكل مليون مخرج. تتيح آليات التخزين المؤقت - التي تصل إلى 10% من تكلفة الفشل - جلسات طويلة واقتصادية. لتفاعل وكيل يتكون من 10,000 رمز (مع 80% من الوصول إلى ذاكرة التخزين المؤقت)، تنخفض التكاليف إلى أقل من 0.01 دولار، وتتصاعد خطيًا.
تقدم المستويات المجانية وصولاً مبدئيًا، وتنتقل إلى الدفع حسب الاستخدام للمطورين. تقوم خطط الشركات بتخصيص الأحجام، ولكن الأسعار الأساسية تكفي لمعظم الاحتياجات. وبالتالي، يتوافق التسعير مع روح المصادر المفتوحة، مما يضفي الطابع الديمقراطي على الاستدلال المتقدم.
تقدر حاسبة: لمليون رمز إدخال (50% وصول) و 200,000 مخرج، إجمالي التكلفة يقارب 0.20 دولار - وهو جزء صغير مقارنة بالبدائل. هذه الكفاءة تدعم المهام الكبيرة، من مراجعة التعليمات البرمجية إلى تركيب البيانات.
استعراض تقني معمق: ابتكارات البنية والتدريب
تشكل DSA جوهر العملية، حيث تقوم بتفتيت مصفوفات الانتباه ديناميكيًا. للموضع i، فإنها تهتم بالنوافذ المحلية والمفاتيح العالمية، مما يقلل من عمليات الفلوب (FLOPs) بنسبة 40% على سياقات 100 ألف. يؤدي التحويل الكمي إلى F8_E4M3 إلى خفض الذاكرة إلى النصف دون فقدان الدقة، مما يتيح عمليات نشر A100 بمقدار 8 أضعاف.

يمتد التدريب ليشمل التدريب المسبق على 10 تريليونات رمز، والتعديل الدقيق تحت الإشراف، والتعلم المعزز بالتعليقات البشرية (RLHF) مع مكافآت الوكلاء. يولد خط أنابيب التوليف أكثر من مليون مهمة، محاكياً وكالة العالم الحقيقي. يخصص التدريب اللاحق لـ Speciale 10 أضعاف القوة الحاسوبية، مستخلصاً الاستدلال من المسارات.
تؤدي هذه الابتكارات إلى سلوكيات ناشئة: التصحيح الذاتي في 85% من حالات فشل HLE ونجاح الأداة بنسبة 92% في T². قد تتضمن التكرارات المستقبلية تعدد الوسائط، وفقًا لخرائط الطريق.
الخلاصة: وضع DeepSeek لمستقبل الوكلاء
تعيد DeepSeek-V3.2 و DeepSeek-V3.2-Speciale تعريف الاستدلال مفتوح المصدر. تؤكد المعايير تفوقها، ويدعو الوصول المفتوح إلى التعاون، وتمكّن واجهات برمجة التطبيقات (APIs) بأسعار معقولة من التوسع. يبني المطورون وكلاء متفوقين، من حلول الأولمبياد إلى آلات الأتمتة للشركات.
مع تطور الذكاء الاصطناعي، تضع هذه النماذج سوابق. جرب اليوم - قم بتنزيل الأوزان من Hugging Face، ودمجها عبر API، واختبرها باستخدام Apidog. يبدأ الطريق إلى الأنظمة الذكية هنا.