
حظيت Claude من Anthropic مؤخرًا باهتمام كبير مع ميزات جديدة تتيح له الوصول إلى معلومات الويب في الوقت الحقيقي وتوليفها، مما يجعله يعمل بفعالية كمساعد بحث. تهدف هذه الميزة، التي تُناقش غالبًا باسم "Claude Research"، إلى تجاوز البحث البسيط على الويب من خلال استكشاف زوايا متعددة لموضوع معين، وجمع المعلومات من مصادر مختلفة، وتقديم إجابات مركبة. على الرغم من قوتها، فإن الاعتماد على أنظمة مغلقة المصدر وملكية ليست دائمًا مثالية. يبحث العديد من المستخدمين عن مزيد من التحكم والشفافية والتخصيص، أو ببساطة يريدون تجربة التكنولوجيا الأساسية.

الخبر السار هو أن المجتمع المفتوح المصدر غالبًا ما يقدم لبنات بناء لتكرار مثل هذه الوظائف. أحد المشاريع المثيرة في هذا المجال هو btahir/open-deep-research على GitHub. تهدف هذه الأداة إلى أتمتة عملية إجراء بحث معمق في موضوع معين من خلال الاستفادة من عمليات البحث على الويب ونماذج اللغة الكبيرة (LLMs).
دعنا نفهم أولاً القدرات الرئيسية التي تقدمها ميزات البحث المتطورة بالذكاء الاصطناعي مثل تلك الخاصة بـ Claude، والتي يحاول open-deep-research محاكاتها بطريقة مفتوحة المصدر، ثم نستعرض كيف يمكنك تشغيل هذه الأداة بنفسك.
تقديم open-deep-research: نقطة انطلاقك المفتوحة المصدر
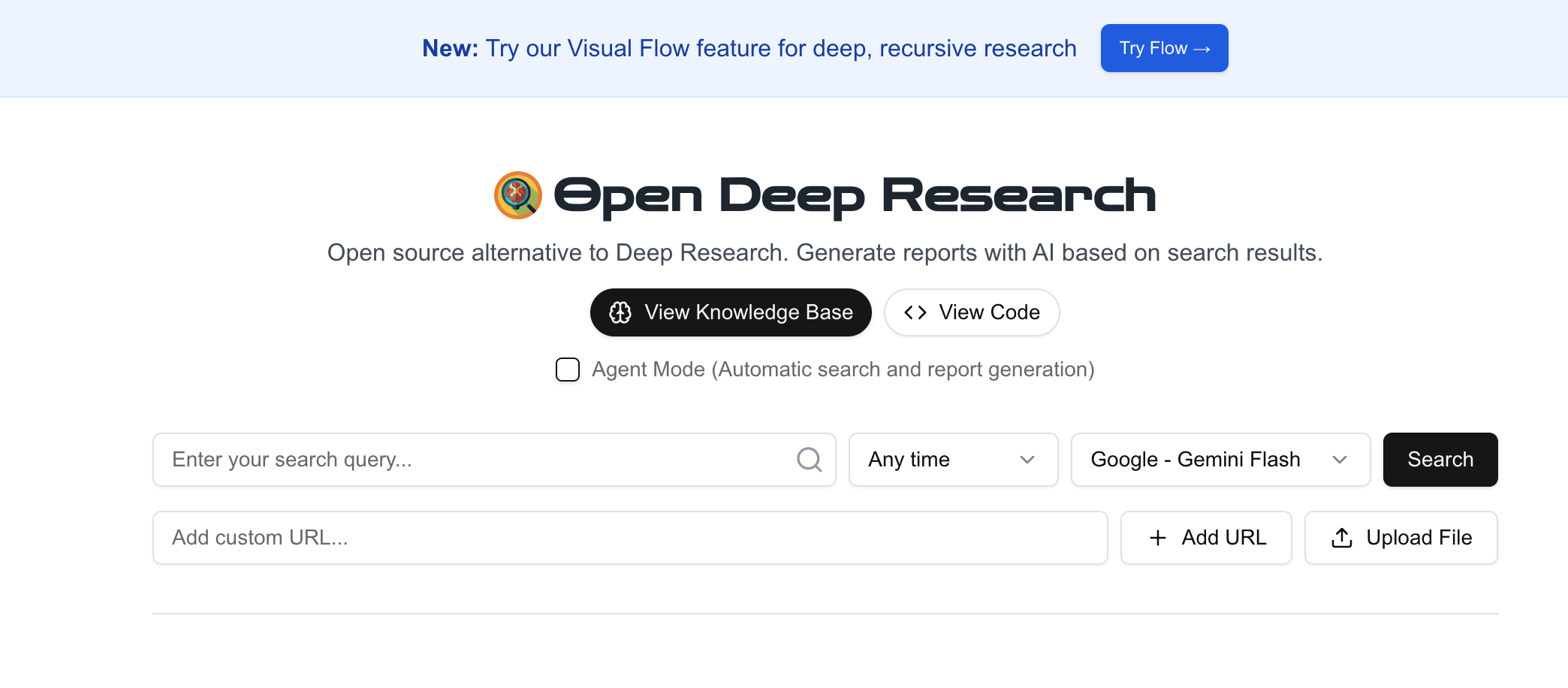
يوفر مشروع open-deep-research (https://github.com/btahir/open-deep-research) إطارًا لتحقيق أهداف مشابهة باستخدام أدوات واجهة برمجة التطبيقات المتاحة بسهولة. من المحتمل أنه ينظم سلسلة تتضمن:
- استعلامات محركات البحث: استخدام واجهات البرمجة (مثل SearchApi، Google Search API، إلخ) للعثور على صفحات الويب ذات الصلة بموضوع البحث المعطى.
- خدش الويب: جلب المحتوى من عناوين URL المحددة.
- معالجة LLM: استخدام نموذج لغة كبير (عادة عبر واجهة برمجة تطبيقات OpenAI، ولكن قد يكون قابلاً للتكيف) لقراءة وفهم وتوليف وهيكلة المعلومات المجمعة من صفحات الويب.
- توليد التقارير: تجميع المعلومات المعالجة في نتيجة نهائية، مثل تقرير مفصل.
من خلال تشغيل هذه الأداة بنفسك، ستحصل على شفافية حول العملية وإمكانية تخصيصها.
تبحث عن منصة متكاملة، تجمع كل شيء، لفريق المطورين لديك للعمل معًا بكفاءة قصوى?
Apidog تلبي جميع احتياجاتك، وتحل محل Postman بسعر أكثر ملاءمة بكثير!

دليل خطوة بخطوة لتشغيل open-deep-research
هل أنت مستعد لتجربة بناء مساعد بحث خاص بك؟ إليك دليل مفصل للحصول على open-deep-research قيد التشغيل.
اشتراطات سابقة:
- بايثون: ستحتاج إلى تثبيت بايثون على نظامك (عادة بايثون 3.7+).
- Git: مطلوب لاستنساخ المستودع.
- مفاتيح API: هذه خطوة حاسمة. ستحتاج الأداة إلى مفاتيح API لـ:
- واجهة برمجة تطبيقات محرك البحث: لإجراء عمليات البحث على الويب برمجيًا. تشمل الأمثلة SearchApi، Serper، أو ربما غيرها بناءً على تكوين المشروع. ستحتاج إلى التسجيل في واحدة من هذه الخدمات والحصول على مفتاح API.
- واجهة برمجة تطبيقات LLM: من المحتمل أن مطلوب مفتاح واجهة برمجة تطبيقات OpenAI للوصول إلى نماذج GPT (مثل GPT-3.5 أو GPT-4) لخطوة التوليف. ستحتاج إلى حساب OpenAI مع وصول إلى API.
- (تحقق من
open-deep-researchREADME للحصول على واجهات برمجة التطبيقات والمفاتيح المطلوبة بالتحديد). - سطر الأوامر / الطرفية: ستقوم بتشغيل الأوامر في الطرفية أو موجه الأوامر لديك.
الخطوة 1: استنساخ المستودع
أولًا، افتح الطرفية الخاصة بك وانتقل إلى الدليل حيث تريد تخزين المشروع. ثم، استنسخ مستودع GitHub:
git clone <https://github.com/btahir/open-deep-research.git>
الآن، انتقل إلى دليل المشروع الجديد الذي تم إنشاؤه:
cd open-deep-research
الخطوة 2: إعداد بيئة افتراضية (موصى بها)
من الأفضل استخدام بيئة افتراضية لإدارة تبعيات المشروع بشكل منفصل.
على macOS/Linux:
python3 -m venv venv
source venv/bin/activate
على Windows:
python -m venv venv
.\\venv\\Scripts\\activate
يجب أن تشير موجه الطرفية الآن إلى أنك في بيئة (venv).
الخطوة 3: تثبيت التبعيات
يجب أن يتضمن المشروع ملف requirements.txt الذي يسرد جميع المكتبات الضرورية بايثون. قم بتثبيتها باستخدام pip:
pip install -r requirements.txt
ستقوم هذه الأمر بتحميل وتثبيت مكتبات مثل openai، requests، وإمكانية beautifulsoup4 أو مشابهة للخدش، ومكتبات لواجهة برمجة التطبيقات الخاصة بمحرك البحث المستخدم.
الخطوة 4: تكوين مفاتيح API
هذه هي الخطوة الأكثر أهمية في التكوين. تحتاج إلى توفير مفاتيح API التي حصلت عليها في الاشتراطات السابقة. عادة ما تتولى المشاريع المفتوحة المصدر إدارة المفاتيح عبر متغيرات البيئة أو ملف .env. استشر ملف README الخاص بـ open-deep-research بعناية للحصول على أسماء المتغيرات المطلوبة بدقة.
عادةً، قد تحتاج إلى تعيين متغيرات مثل:
OPENAI_API_KEYSEARCHAPI_API_KEY(أوSERPER_API_KEY،GOOGLE_API_KEY، إلخ، حسب خدمة البحث المستخدمة)
يمكنك تعيين متغيرات البيئة مباشرة في الطرفية الخاصة بك (هذه مؤقتة للجلسة الحالية):
على macOS/Linux:
export OPENAI_API_KEY='your_openai_api_key_here'
export SEARCHAPI_API_KEY='your_search_api_key_here'
على Windows (موجه الأوامر):
set OPENAI_API_KEY=your_openai_api_key_here
set SEARCHAPI_API_KEY=your_search_api_key_here
على Windows (PowerShell):
$env:OPENAI_API_KEY="your_openai_api_key_here"$env:SEARCHAPI_API_KEY="your_search_api_key_here"
بدلاً من ذلك، قد يدعم المشروع ملف .env. إذا كان الأمر كذلك، قم بإنشاء ملف باسم .env في الدليل الجذر للمشروع وأضف المفاتيح على هذا النحو:
OPENAI_API_KEY=your_openai_api_key_here
SEARCHAPI_API_KEY=your_search_api_key_here
ستقوم مكتبات مثل python-dotenv (إذا تم ذكرها في requirements.txt) بتحميل هذه المتغيرات تلقائيًا عند تشغيل البرنامج النصي. مرة أخرى، تحقق من توثيق المشروع للحصول على الطريقة الصحيحة وأسماء المتغيرات.
الخطوة 5: تشغيل أداة البحث
مع إعداد البيئة، وتثبيت التبعيات، وتكوين مفاتيح API، يمكنك الآن تشغيل البرنامج النصي الرئيسي. ستعتمد الأمر الدقيق على كيفية تنظيم المشروع. ابحث عن برنامج نصي بايثون أساسي (مثل main.py، research.py، أو ما شابه).
قد يبدو الأمر كما يلي ( تحقق من README للحصول على الأمر والوسائط الدقيقة!):
python main.py --query "أثر اعتماد الطاقة المتجددة على اتجاهات انبعاثات CO2 العالمية"
أو ربما:
python research_agent.py "أحدث التطورات في تكنولوجيا البطاريات الحالة الصلبة للمركبات الكهربائية"
سوف يقوم البرنامج النصي بعد ذلك:
- تأخذ استفسارك.
- استخدام مفتاح API الخاص بالبحث للعثور على عناوين URL ذات الصلة.
- خدش المحتوى من تلك العناوين URL.
- استخدام مفتاح واجهة برمجة تطبيقات OpenAI لمعالجة وتوليف المحتوى.
- توليد مخرجات.
الخطوة 6: مراجعة المخرجات
من المحتمل أن تستغرق الأداة بعض الوقت للقيام بعملياتها، اعتمادًا على تعقيد الاستفسار وعدد المصادر المعالجة وسرعة واجهات برمجة التطبيقات. بمجرد الانتهاء، تحقق من الإخراج. قد يكون هذا:
- مطبوع مباشرة إلى وحدة التحكم في الطرفية الخاصة بك.
- محفوظ كملف نصي أو ملف Markdown في دليل المشروع (مثل
research_report.txtأوreport.md).
راجع التقرير المُنتَج لتحديد ملاءمته، وترابطه، ودقته.
التخصيص والاعتبارات
- اختيار LLM: بينما من المحتمل أن يتم الافتراضي إلى OpenAI، تحقق مما إذا كان المشروع يسمح بتكوين نماذج LLM مختلفة (ربما نماذج مفتوحة المصدر تعمل محليًا عبر Ollama أو LM Studio، على الرغم من أن هذا سيتطلب تغييرات في الشيفرة إذا لم يكن مدمجًا).
- موفر البحث: قد تتمكن من تبديل موفر واجهة برمجة التطبيقات للبحث إذا لزم الأمر.
- هندسة الموجهات: يمكنك تعديل الموجهات المستخدمة لإرشاد LLM خلال مرحلة التوليف لتخصيص أسلوب أو تركيز الإخراج.
- التكلفة: تذكر أن استخدام واجهات برمجة التطبيقات (وخاصة نماذج OpenAI الأكثر قوة وواجهات برمجة التطبيقات الخاصة بالبحث) يتكبد تكاليف بناءً على الاستخدام. تابع إنفاقك.
- الموثوقية: قد تكون الأدوات مفتوحة المصدر مثل هذه أقل متانة من المنتجات التجارية. تتغير المواقع، وقد يفشل الخدش، ويمكن أن تتنوع مخرجات LLM. توقع أن تقوم بإصلاح المشكلات المحتملة.
- التعقيد: يتطلب إعداد هذا المزيد من الجهد التقني مقارنة باستخدام منتج SaaS مصقول مثل Claude.
الخاتمة
بينما تقدم أدوات الذكاء الاصطناعي التجارية مثل Claude قدرات بحث متكاملة مثيرة للإعجاب، فإن المشاريع المفتوحة المصدر مثل btahir/open-deep-research تثبت أن الوظائف المشابهة يمكن بناؤها وتشغيلها بشكل مستقل. من خلال اتباع الخطوات المذكورة أعلاه، يمكنك إعداد وكيل بحث تلقائي خاص بك، مما يمنحك أداة قوية للتعمق في مواضيع متعددة، مع الشفافية وإمكانية التخصيص التي تقدمها المصادر المفتوحة. تذكر دائمًا استشارة الوثائق الخاصة بالمشروع المحدد (README.md) للحصول على التعليمات الأكثر دقة وحداثة. نتمنى لك بحثًا سعيدًا!
تبحث عن منصة متكاملة، تجمع كل شيء، لفريق المطورين لديك للعمل معًا بكفاءة قصوى?
Apidog تلبي جميع احتياجاتك، وتحل محل Postman بسعر أكثر ملاءمة بكثير!