
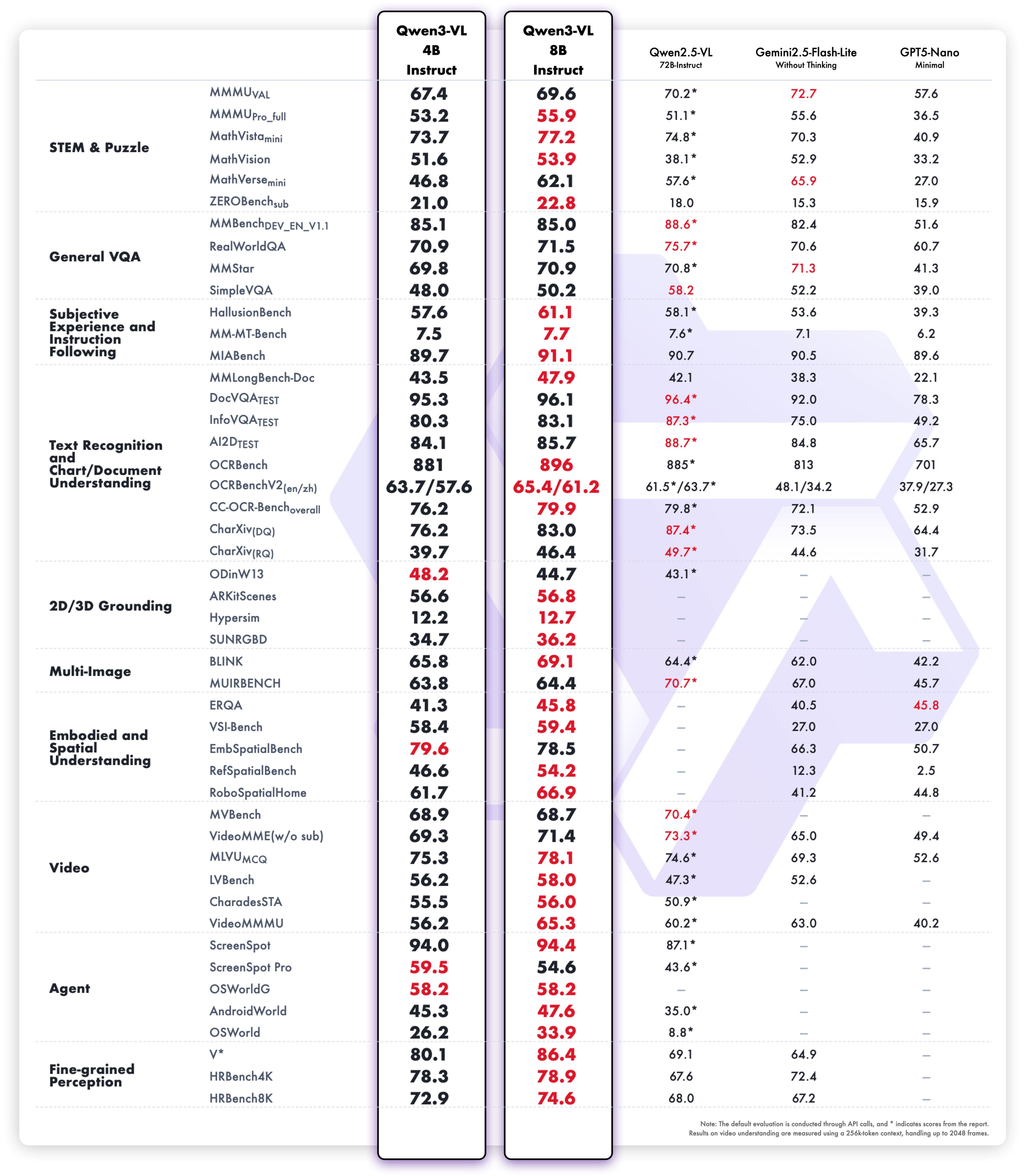
تهيمن عائلة Qwen 3 على مشهد نماذج اللغات الكبيرة مفتوحة المصدر (LLMs) في عام 2025. ينشر المهندسون هذه النماذج في كل مكان، من وكلاء الشركات الحاسمين للمهام إلى المساعدين المتنقلين. قبل أن تبدأ في إرسال الطلبات إلى Alibaba Cloud أو الاستضافة الذاتية، قم بتبسيط سير عملك باستخدام Apidog.
نظرة عامة على Qwen 3: الابتكارات المعمارية التي تدفع أداء 2025
أصدر فريق Qwen التابع لـ Alibaba سلسلة Qwen 3 في 29 أبريل 2025، مما يمثل تقدمًا محوريًا في نماذج اللغات الكبيرة مفتوحة المصدر (LLMs). يثني المطورون على ترخيصها Apache 2.0، الذي يتيح التعديل الدقيق والنشر التجاري غير المقيد. في جوهرها، تستخدم Qwen 3 بنية قائمة على Transformer مع تحسينات في التضمينات الموضعية وآليات الانتباه، مما يدعم أطوال سياق تصل إلى 128 ألف رمز بشكل طبيعي - وقابل للتوسيع إلى 131 ألفًا عبر YaRN.

علاوة على ذلك، تتضمن السلسلة تصميمات Mixture-of-Experts (MoE) في متغيرات مختارة، حيث يتم تنشيط جزء فقط من المعلمات أثناء الاستدلال. يقلل هذا النهج من الحمل الحسابي مع الحفاظ على دقة عالية في المخرجات. على سبيل المثال، يبلغ المهندسون عن إنتاجية أسرع بمقدار 10 مرات في مهام السياق الطويل مقارنة بالنماذج الكثيفة السابقة مثل Qwen2.5-72B. ونتيجة لذلك، تتوسع متغيرات Qwen 3 بكفاءة عبر الأجهزة، من الأجهزة الطرفية إلى المجموعات السحابية.
تتفوق Qwen 3 أيضًا في دعم اللغات المتعددة، حيث تتعامل مع أكثر من 119 لغة مع اتباع تعليمات دقيقة. تؤكد المعايير تفوقها في مجالات العلوم والتكنولوجيا والهندسة والرياضيات، حيث تعالج بيانات الرياضيات والتعليمات البرمجية الاصطناعية المكررة من 36 تريليون رمز. لذلك، تستفيد التطبيقات في الشركات العالمية من تقليل أخطاء الترجمة وتحسين الاستدلال عبر اللغات. بالانتقال إلى التفاصيل، يتيح وضع الاستدلال الهجين – الذي يتم تبديله عبر علامات الترميز – للنماذج المشاركة في منطق خطوة بخطوة للرياضيات أو البرمجة، أو الافتراض على عدم التفكير للحوار. تمكن هذه الازدواجية المطورين من التحسين لكل حالة استخدام.
الميزات الرئيسية التي توحد متغيرات Qwen 3
تتشارك جميع نماذج Qwen 3 سمات أساسية ترفع من فائدتها في عام 2025. أولاً، تدعم التشغيل ثنائي الوضع: وضع التفكير ينشط عمليات سلسلة الأفكار للمعايير مثل AIME25، بينما يعطي وضع عدم التفكير الأولوية للسرعة لتطبيقات الدردشة. يقوم المهندسون بتبديل هذا بمعاملات بسيطة، محققين دقة تصل إلى 92.3% في الرياضيات المعقدة دون التضحية بالاستجابة.
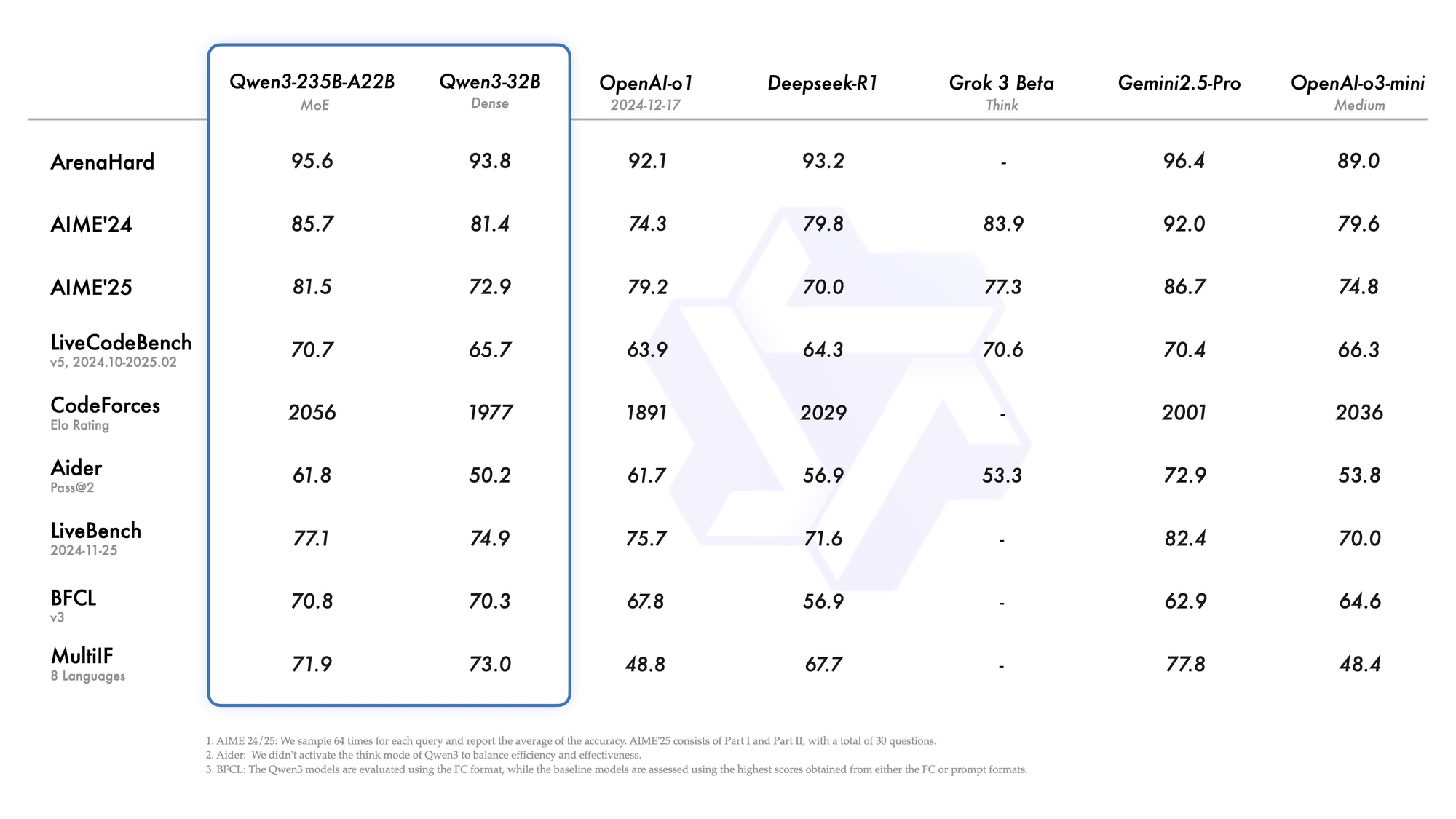
ثانياً، تتيح الميزات الوكيلة استدعاء الأدوات بسلاسة، متفوقة على النظراء مفتوحي المصدر في مهام مثل التنقل في المتصفح أو تنفيذ التعليمات البرمجية. على سبيل المثال، تسجل متغيرات Qwen 3 69.6 نقطة في Tau2-Bench Verified، منافسة النماذج الاحتكارية. بالإضافة إلى ذلك، تغطي البراعة متعددة اللغات لهجات من الماندرين إلى السواحيلية، مع 73.0 نقطة في معايير MultiIF.
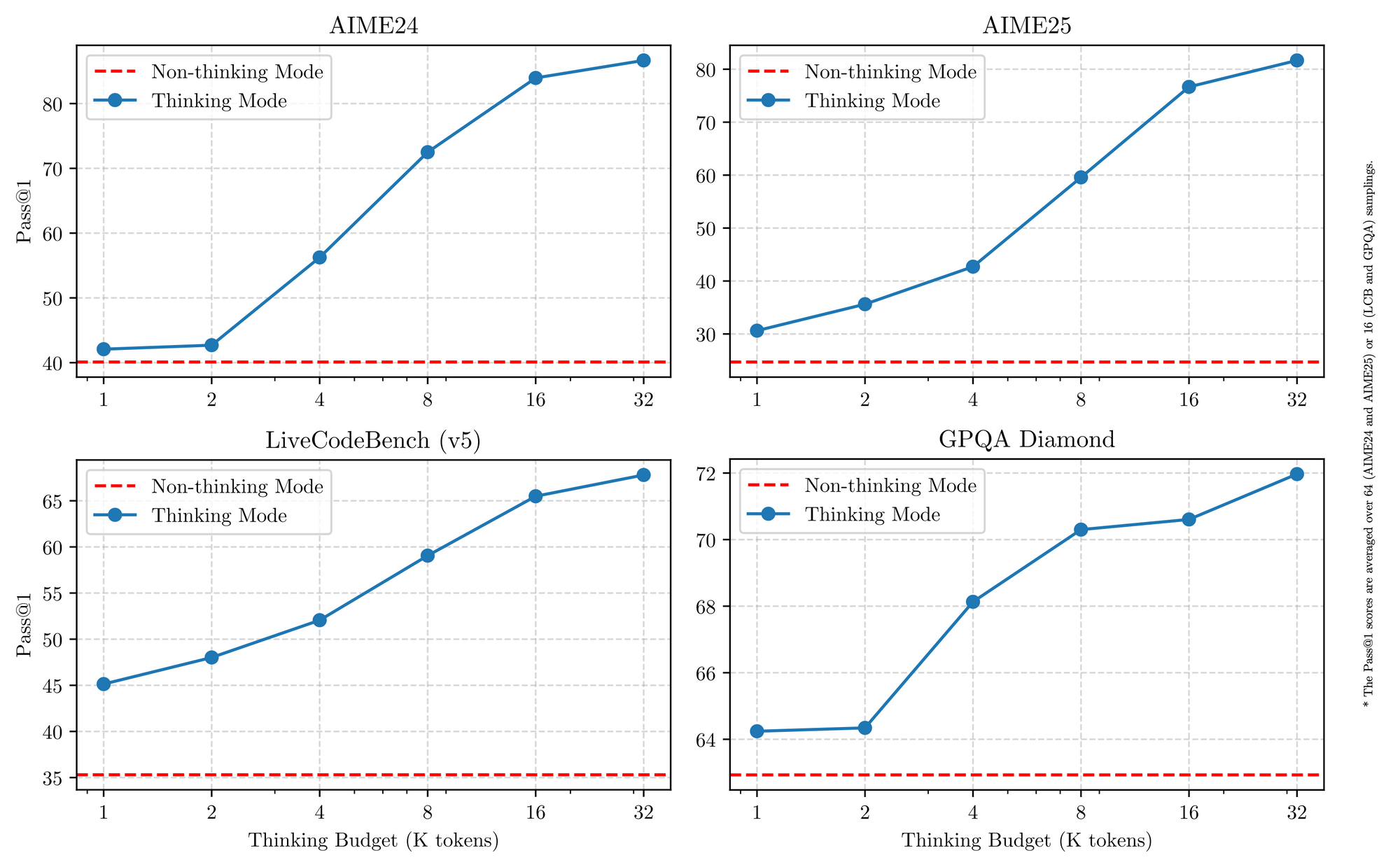
ثالثاً، تنبع الكفاءة من المتغيرات المكممة (مثل Q4_K_M) والأطر مثل vLLM أو SGLang، والتي تقدم 25 رمزًا في الثانية على وحدات معالجة الرسوميات الاستهلاكية. ومع ذلك، تتطلب النماذج الأكبر حجمًا ذاكرة وصول عشوائي للفيديو (VRAM) تبلغ 16 جيجابايت فأكثر، مما يستدعي عمليات النشر السحابي. تظل الأسعار تنافسية، مع تكلفة الرموز المدخلة تتراوح بين 0.20 دولار و 1.20 دولار لكل مليون عبر Alibaba Cloud.
علاوة على ذلك، تركز Qwen 3 على الأمان من خلال الإشراف المدمج، مما يقلل من الهلوسة بنسبة 15% مقارنة بـ Qwen2.5. يستفيد المطورون من هذا في تطبيقات على مستوى الإنتاج، من أنظمة توصية التجارة الإلكترونية إلى المحللين القانونيين. ومع انتقالنا إلى المتغيرات الفردية، توفر هذه القوى المشتركة أساسًا متسقًا للمقارنة.
أفضل 5 متغيرات من نماذج Qwen 3 في عام 2025
بناءً على معايير 2025 من LMSYS Arena و LiveCodeBench و SWE-Bench، نصنف أفضل خمسة متغيرات من Qwen 3. تشمل معايير الاختيار درجات الاستدلال وسرعة الاستدلال وكفاءة المعلمات وإمكانية الوصول إلى واجهة برمجة التطبيقات (API). يتفوق كل منها في سيناريوهات مميزة، لكنها جميعًا تدفع بحدود المصادر المفتوحة.
1. Qwen3-235B-A22B – نموذج MoE الرائد المطلق
Qwen3-235B-A22B يلفت الانتباه باعتباره المتغير الرائد بتقنية MoE، بإجمالي 235 مليار معلمة و22 مليار معلمة نشطة لكل رمز. صدر في يوليو 2025 باسم Qwen3-235B-A22B-Instruct-2507، وهو ينشط ثمانية خبراء عبر توجيه top-k، مما يقلل من الحساب بنسبة 90% مقارنة بالنماذج الكثيفة المكافئة. تضعه المعايير جنبًا إلى جنب مع Gemini 2.5 Pro: 95.6 في ArenaHard، و77.1 في LiveBench، والريادة في CodeForces Elo (متفوقًا بنسبة 5%).
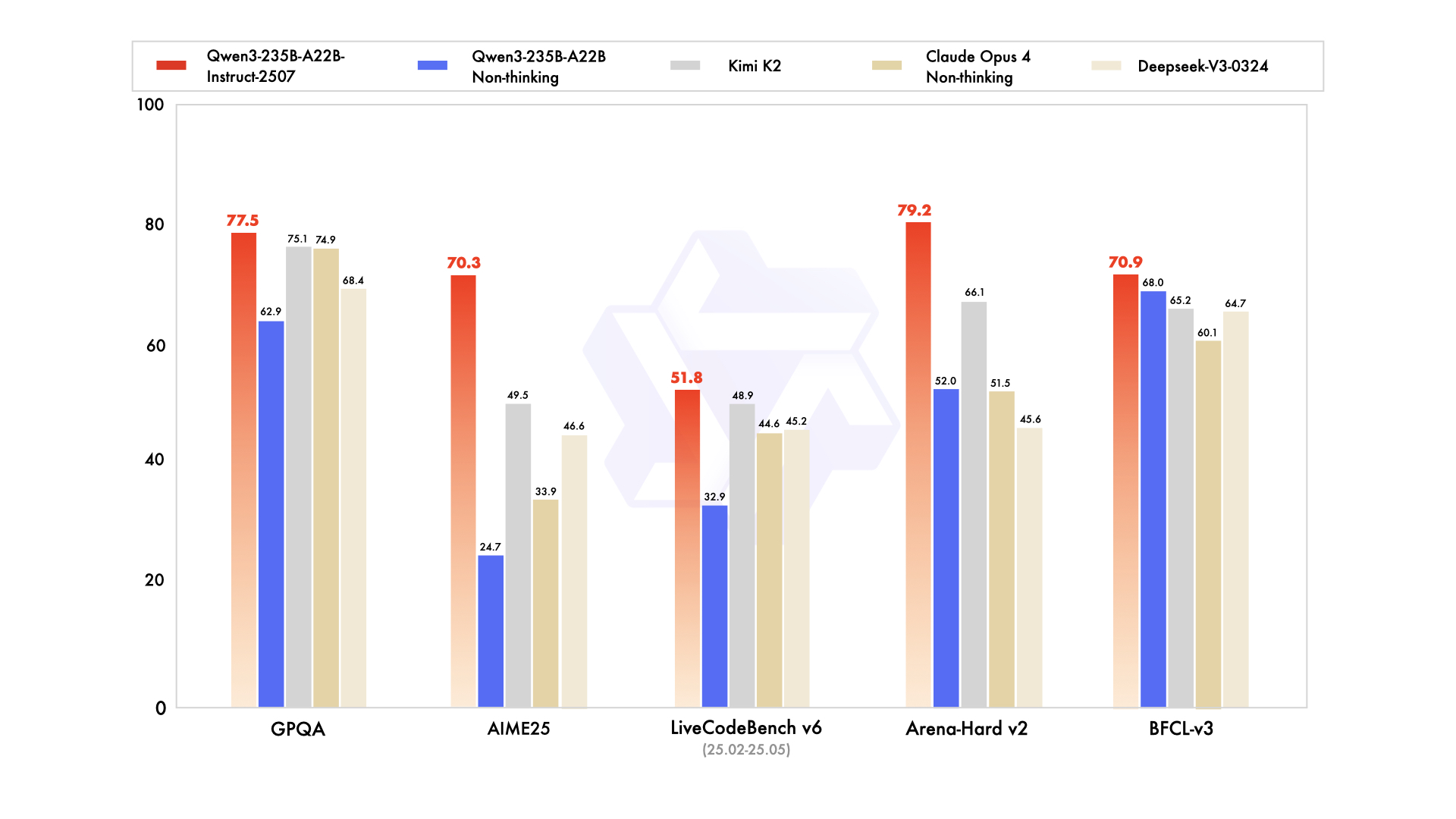
في البرمجة، يحقق 74.8 في LiveCodeBench v6، وينشئ TypeScript وظيفيًا بأقل تكرارات. للرياضيات، ينتج وضع التفكير 92.3 في AIME25، ويحل التكاملات متعددة الخطوات عبر الاستنتاج الصريح. تشهد المهام متعددة اللغات 73.0 في MultiIF، حيث تعالج الاستفسارات العربية بسلاسة.
يفضل النشر واجهات برمجة التطبيقات السحابية، حيث يتعامل مع سياقات 256 ألف. ومع ذلك، تتطلب التشغيلات المحلية 8x وحدات معالجة الرسوميات H100. يدمجه المهندسون لسير العمل الوكيلي، مثل تصحيح الأخطاء على مستوى المستودع. بشكل عام، يحدد هذا المتغير معيار 2025 للعمق، على الرغم من أن حجمه يناسب الفرق ذات الميزانيات الكبيرة.
نقاط القوة
- يطابق أو يتفوق على Gemini 2.5 Pro و Claude 3.7 Sonnet في جميع لوحات المتصدرين تقريبًا لعام 2025 (95.6 ArenaHard، 92.3 AIME25 وضع التفكير، 74.8 LiveCodeBench v6).
- يتفوق في سير العمل الوكيلي متعدد الأدوار، واستدعاء الأدوات المعقدة، وفهم التعليمات البرمجية على مستوى المستودع.
- يتعامل مع سياقات 256 ألف إلى 1 مليون باستخدام YaRN دون تدهور في الجودة.
- يقدم وضع التفكير استدلالًا قائمًا على سلسلة الأفكار يمكن التحقق منه وينافس النماذج المتطورة مغلقة المصدر.
نقاط الضعف
- باهظ التكلفة وبطيء للغاية محليًا — يتطلب 8x H100 أو ما يعادله للحصول على استجابة معقولة.
- تسعير واجهة برمجة التطبيقات هو الأعلى في العائلة (1.20 دولار – 6.00 دولارات/مليون رمز مخرج عند ذروة السياق).
- إفراط في القدرة لـ 95% من أعباء العمل الإنتاجية؛ معظم الفرق لا تستغل قدرته بالكامل أبدًا.
متى تستخدمه
- الوكلاء المستقلون على مستوى الشركات الذين يجب أن يحلوا مسائل رياضية على مستوى الدكتوراه، أو يصححوا أخطاء قواعد التعليمات البرمجية بأكملها، أو يجروا تحليل العقود القانونية مع شبه انعدام للهلوسة.
- المختبرات البحثية ذات الميزانيات الكبيرة التي تدفع بحدود أحدث التقنيات في المعايير الجديدة.
- الواجهات الخلفية للاستدلال الداخلية حيث تكون التكلفة لكل رمز ثانوية بالنسبة للذكاء الأقصى.
2. Qwen3-30B-A3B – بطل MoE ذو النقطة المثلى
يبرز Qwen3-30B-A3B كخيار مفضل للإعدادات ذات الموارد المحدودة، حيث يضم 30.5 مليار معلمة إجمالية و3.3 مليار معلمة نشطة. تعكس بنيته بتقنية MoE – 48 طبقة، 128 خبيرًا (ثمانية موجهين) – النموذج الرائد ولكن بعُشر البصمة. تم تحديثه في يوليو 2025، ويتجاوز QwQ-32B بعشرة أضعاف في الكفاءة النشطة، مسجلاً 91.0 في ArenaHard و69.6 في SWE-Bench Verified.
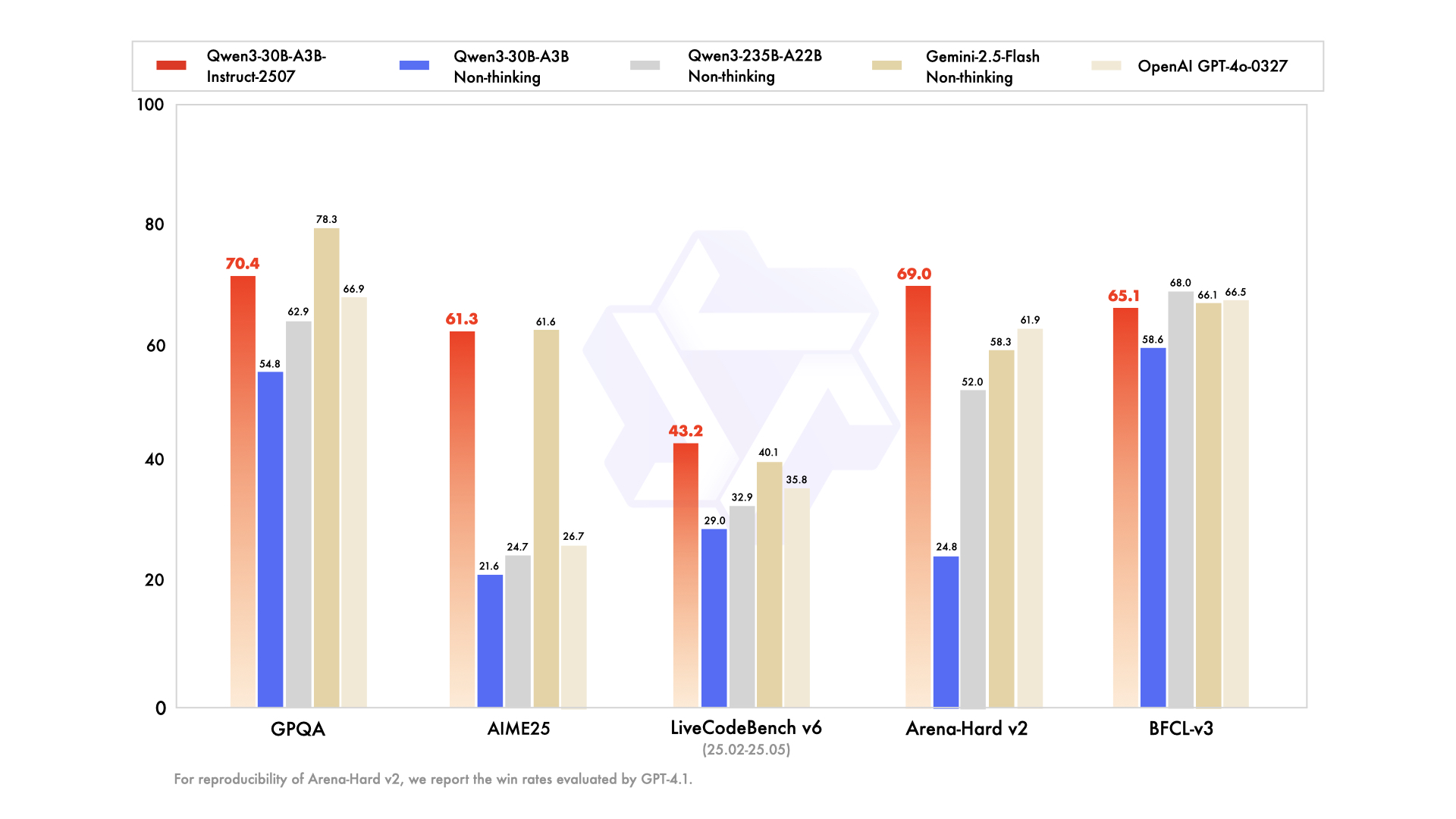
تبرز تقييمات البرمجة براعته: 32.4% pass@5 على طلبات السحب الجديدة من GitHub، مطابقة لـ GPT-5-High. تُظهر معايير الرياضيات 81.6 في AIME25 في وضع التفكير، منافسة الإخوة الأكبر حجمًا. مع سياق 131K عبر YaRN، فإنه يعالج المستندات الطويلة دون اقتطاع.
نقاط القوة
- معلمات نشطة أرخص بـ 10 أضعاف من نموذج 235B مع الاحتفاظ بحوالي 90-95% من جودة الاستدلال الرائدة (91.0 ArenaHard، 81.6 AIME25).
- يعمل بسهولة على بطاقة A100 واحدة بسعة 80 جيجابايت أو بطاقتي 40 جيجابايت مع vLLM + FlashAttention.
- أفضل نسبة سعر إلى أداء بين جميع نماذج MoE المفتوحة لعام 2025.
- يتفوق على كل نموذج كثيف بحجم 72B-110B في البرمجة والرياضيات.
نقاط الضعف
- لا يزال يحتاج إلى حوالي 24-30 جيجابايت VRAM في FP8/INT4؛ ليس صديقًا لأجهزة الكمبيوتر المحمولة.
- براعة أقل قليلاً في الكتابة الإبداعية مقارنة بالنماذج الكثيفة النقية ذات الحجم المماثل.
- تزداد استجابة وضع التفكير بمقدار 2-3 أضعاف مقارنة بوضع عدم التفكير.
متى تستخدمه
- وكلاء البرمجة الإنتاجية، مراجعات طلبات السحب الآلية، أو مساعدي المطورين الداخليين.
- خطوط أنابيب البحث عالية الإنتاجية التي تحتاج إلى استدلال رياضي أو علمي على مستوى الحدود بميزانية معقولة.
- أي فريق استخدم سابقًا Llama-405B أو Mixtral-123B ولكنه يريد استدلالًا أفضل بتكلفة أقل.
3. Qwen3-32B – الملك الكثيف الشامل
يقدم Qwen3-32B الكثيف 32 مليار معلمة نشطة بالكامل، مع التركيز على الإنتاجية الخام بدلاً من التناثر. تم تدريبه على 36 تريليون رمز، ويطابق Qwen2.5-72B في الأداء الأساسي ولكنه يتفوق في محاذاة ما بعد التدريب. تكشف المعايير عن 89.5 في ArenaHard و73.0 في MultiIF، مع كتابة إبداعية قوية (مثل السرد القصصي الذي يسجل 85% تفضيلًا بشريًا).
في البرمجة، يقود BFCL بنتيجة 68.2، وينشئ واجهات مستخدم قابلة للسحب والإفلات من الموجهات. تعطي الرياضيات 70.3 في AIME25، على الرغم من أنها تتخلف عن نظيراتها من MoE في سلسلة الأفكار. سياقها البالغ 128 ألفًا يناسب قواعد المعرفة، ويعزز وضع عدم التفكير سرعة الحوار إلى 20 رمزًا في الثانية.
نقاط القوة
- اتباع استثنائي للتعليمات وإنتاج إبداعي — غالبًا ما يُفضل على نماذج MoE الأكبر في التقييمات البشرية العمياء للكتابة ولعب الأدوار.
- سهل التعديل الدقيق باستخدام LoRA/QLoRA على الأجهزة الاستهلاكية (16-24 جيجابايت VRAM).
- أسرع استدلال بين النماذج التي لا تزال تتفوق على GPT-4o في العديد من المهام (89.5 ArenaHard).
- أداء قوي جدًا متعدد اللغات عبر أكثر من 119 لغة.
نقاط الضعف
- يتخلف بحوالي 8-12 نقطة عن نظيراته من MoE في أصعب معايير الرياضيات والبرمجة عند تمكين وضع التفكير.
- لا توجد حيل لكفاءة المعلمات — يكلف كل رمز الحساب الكامل لـ 32B.
متى تستخدمه
- منصات إنشاء المحتوى، ومساعدي كتابة الروايات، وأدوات التسويق.
- المشاريع التي تتطلب تعديلًا دقيقًا مكثفًا (روبوتات الدردشة الخاصة بالمجال، نقل النمط).
- الفرق التي تريد جودة شبه رائدة ولكن يجب أن تظل تحت 24 جيجابايت VRAM.
4. Qwen3-14B – قوة الأجهزة الطرفية والمحمولة
يعطي Qwen3-14B الأولوية لقابلية النقل بـ 14.8 مليار معلمة، ويدعم 128 ألف سياق على أجهزة متوسطة المدى. ينافس Qwen2.5-32B في الكفاءة، مسجلاً 85.5 في ArenaHard ويتبادل الضربات مع Qwen3-30B-A3B في الرياضيات/البرمجة (ضمن هامش 5%). عند تكميمه إلى Q4_0، يعمل بسرعة 24.5 رمزًا في الثانية على الأجهزة المحمولة مثل RedMagic 8S Pro.
تشهد المهام الوكيلة 65.1 في Tau2-Bench، مما يتيح استخدام الأدوات في التطبيقات ذات الاستجابة المنخفضة. يتألق الدعم متعدد اللغات، بدقة 70% في استدلال اللهجات. بالنسبة للأجهزة الطرفية، يعالج 32 ألف سياق دون اتصال، وهو مثالي لتحليلات إنترنت الأشياء.
يقدر المهندسون بصمته للتعلم الموحد، حيث تفوق الخصوصية الحجم. وبالتالي، فهو يناسب مساعدي الذكاء الاصطناعي المتنقلة أو الأنظمة المدمجة.
نقاط القوة
- يعمل بسرعة 24-30 رمزًا/ثانية حتى على الهواتف الحديثة (Snapdragon 8 Gen 4، Dimensity 9400) عند تكميمه إلى Q4_K_M.
- لا يزال يتفوق على Qwen2.5-32B و Llama-3.1-70B في معظم معايير الاستدلال.
- ممتاز لـ RAG على الجهاز مع سياق 32K-128K.
- أقل تكلفة لواجهة برمجة التطبيقات في فئة الأداء العليا.
نقاط الضعف
- يبدأ في المعاناة مع المهام الوكيلة متعددة الخطوات التي تتطلب >5 استدعاءات أداة.
- جودة الكتابة الإبداعية أقل بشكل ملحوظ من نماذج 32B+.
- أقل جاهزية للمستقبل مع استمرار ارتفاع المعايير.
متى تستخدمه
- المساعدون على الجهاز (تطبيقات Android/iOS، الأجهزة القابلة للارتداء).
- الانتشار الحساس للخصوصية (الرعاية الصحية، المالية) حيث لا يمكن للبيانات مغادرة الجهاز.
- الأنظمة المدمجة في الوقت الفعلي (الروبوتات، السيارات، بوابات إنترنت الأشياء).
5. Qwen3-8B – رائد النماذج الأولية وخفيف الوزن المثالي
تُكمل Qwen3-8B المراكز الخمسة الأولى، حيث تقدم 8 مليارات معلمة للتكرار السريع، متفوقة على Qwen2.5-14B في 15 معيارًا. تحقق 81.5 في AIME25 (وضع عدم التفكير) و60.2 في LiveCodeBench، وهو ما يكفي لمراجعات التعليمات البرمجية الأساسية. مع سياق أصلي يبلغ 32 ألفًا، يتم نشرها على أجهزة الكمبيوتر المحمولة عبر Ollama، لتصل إلى 25 رمزًا في الثانية.
يناسب هذا المتغير المبتدئين الذين يختبرون الدردشة متعددة اللغات أو الوكلاء البسيطين. يعزز وضع التفكير الألغاز المنطقية، مسجلاً 75% في مهام الاستنتاج. ونتيجة لذلك، يسرع إثبات المفاهيم قبل التوسع إلى الإخوة الأكبر.
نقاط القوة
- يعمل بسرعة >25 رمزًا/ثانية حتى على أجهزة الكمبيوتر المحمولة ذات ذاكرة وصول عشوائي للفيديو (VRAM) تتراوح بين 8-12 جيجابايت (MacBook M3 Pro، RTX 4070 mobile).
- اتباع تعليمات كفء بشكل مدهش — يتفوق على Gemma-2-27B و Phi-4-14B في معظم لوحات المتصدرين لعام 2025.
- مثالي للتجارب المحلية في Ollama أو LM Studio.
- أرخص تسعير لواجهة برمجة التطبيقات في العائلة.
نقاط الضعف
- سقف استدلال واضح في مسائل الرياضيات على مستوى الدراسات العليا ومشاكل البرمجة المتقدمة.
- أكثر عرضة للهلوسة في المهام كثيفة المعرفة.
- سياق محدود (32K أصلي، 128K مع YaRN ولكنه أبطأ).
متى تستخدمه
- النماذج الأولية السريعة وبناء المنتجات الدنيا القابلة للتطبيق (MVP).
- الأدوات التعليمية، المساعدين الشخصيين، أو المشاريع الهواة.
- طبقة توجيه الواجهة الأمامية في الأنظمة الهجينة (استخدم 8B لفرز المهام، ثم تصعيدها إلى 30B/235B عند الحاجة).
اعتبارات تسعير واجهة برمجة التطبيقات ونشر نماذج Qwen 3
إن الوصول إلى Qwen 3 عبر واجهات برمجة التطبيقات (APIs) يضفي الطابع الديمقراطي على الذكاء الاصطناعي المتقدم، مع تصدر Alibaba Cloud بأسعار تنافسية. تتدرج الأسعار حسب الرموز: بالنسبة لـ Qwen3-235B-A22B، تتراوح تكاليف الإدخال بين 0.20 و 1.20 دولارًا للمليون (نطاق 0-252 ألف)، وتكاليف الإخراج بين 1.00 و 6.00 دولارات للمليون. يعكس Qwen3-30B-A3B هذا بمعدل 80%، بينما تنخفض النماذج الكثيفة مثل Qwen3-32B إلى 0.15 دولارًا للإدخال و0.75 دولارًا للإخراج.
يقدم مقدمو الخدمات الخارجيون مثل Together AI نموذج Qwen3-32B بسعر 0.80 دولارًا لكل مليون رمز إجمالي، مع خصومات على الحجم. تقلل مرات الوصول إلى الذاكرة المؤقتة من الفواتير: ضمنيًا بنسبة 20%، وصريحًا بنسبة 10%. مقارنة بـ GPT-5 (3-15 دولارًا/مليون)، تقل تكلفة Qwen 3 بنسبة 70%، مما يتيح التوسع الفعال من حيث التكلفة.
نصائح النشر: استخدم vLLM للتجميع، و SGLang للتوافق مع OpenAI. يعزز Apidog ذلك من خلال محاكاة نقاط نهاية Qwen، واختبار الحمولة، وإنشاء الوثائق — وهو أمر بالغ الأهمية لخطوط أنابيب CI/CD. تُعد التشغيلات المحلية عبر Ollama مناسبة للنماذج الأولية، لكن واجهات برمجة التطبيقات تتفوق في الإنتاج.
تضيف ميزات الأمان مثل تحديد المعدل والإشراف قيمة، بدون رسوم إضافية. وبالتالي، تختار الفرق ذات الميزانية المحدودة بناءً على حجم الرمز: المتغيرات الصغيرة للتطوير، والمتغيرات الرائدة للاستدلال.
جدول القرار – اختر نموذج Qwen 3 الخاص بك في عام 2025
| الترتيب | النموذج | المعلمات (الإجمالي/النشط) | ملخص نقاط القوة | نقاط الضعف الرئيسية | الأفضل لـ | التكلفة التقريبية لواجهة برمجة التطبيقات (الإدخال/الإخراج لكل مليون رمز) | الحد الأدنى من ذاكرة الوصول العشوائي للفيديو (المكممة) |
|---|---|---|---|---|---|---|---|
| 1 | Qwen3-235B-A22B | 235 مليار / 22 مليار MoE | أقصى قدر من الاستدلال، وكيل، رياضيات، برمجة | باهظ التكلفة وثقيل للغاية | البحث الرائد، وكلاء الشركات، دقة لا تحتمل الأخطاء | 0.20–1.20 دولار / 1.00–6.00 دولارات | 64 جيجابايت فما فوق (سحابي) |
| 2 | Qwen3-30B-A3B | 30.5 مليار / 3.3 مليار MoE | أفضل نسبة سعر إلى أداء، استدلال قوي | لا يزال يحتاج إلى وحدة معالجة رسوميات خادم | وكلاء البرمجة الإنتاجية، الواجهات الخلفية للرياضيات/العلوم، الاستدلال عالي الحجم | 0.16–0.96 دولار / 0.80–4.80 دولارات | 24–30 جيجابايت |
| 3 | Qwen3-32B | 32 مليار كثيف | الكتابة الإبداعية، سهولة التعديل الدقيق، السرعة | يتخلف عن MoE في أصعب المهام | منصات المحتوى، التعديل الدقيق الخاص بالمجال، روبوتات الدردشة متعددة اللغات | 0.15 دولار / 0.75 دولار | 16–20 جيجابايت |
| 4 | Qwen3-14B | 14.8 مليار كثيف | قادر على الأجهزة الطرفية/المحمولة، RAG ممتاز على الجهاز | قدرة محدودة للوكلاء متعدد الخطوات | الذكاء الاصطناعي على الجهاز، التطبيقات الحساسة للخصوصية، الأنظمة المدمجة | 0.12 دولار / 0.60 دولار | 8–12 جيجابايت |
| 5 | Qwen3-8B | 8 مليار كثيف | سرعة الكمبيوتر المحمول/الهاتف، الأرخص | سقف واضح للمهام المعقدة | النماذج الأولية، المساعدون الشخصيون، طبقة التوجيه في الأنظمة الهجينة | 0.10 دولار / 0.50 دولار | 4–8 جيجابايت |
التوصية النهائية لعام 2025
يجب على معظم الفرق في عام 2025 أن تعتمد افتراضيًا على Qwen3-30B-A3B — فهو يوفر أكثر من 90% من قوة النموذج الرائد بجزء صغير من التكلفة ومتطلبات الأجهزة. انتقل فقط إلى 235B-A22B إذا كنت حقًا بحاجة إلى آخر 5-10% من جودة الاستدلال ولديك الميزانية. انزل إلى 32B الكثيف لأعباء العمل الإبداعية أو التي تتطلب تعديلًا دقيقًا مكثفًا، واستخدم 14B/8B عندما تكون الاستجابة أو الخصوصية أو قيود الجهاز هي السائدة.
أيا كان المتغير الذي تختاره، سيوفر لك Apidog ساعات من تصحيح أخطاء واجهة برمجة التطبيقات. قم بتنزيله مجانًا اليوم وابدأ البناء باستخدام Qwen 3 بثقة.