
لقد كانت عبارة "الاختبار المدعوم بالذكاء الاصطناعي" تتردد في الصناعة لسنوات، ومع ذلك، لا تزال معظم الأدوات تتطلب من البشر كتابة حالات الاختبار، وتحديد السيناريوهات، وتفسير النتائج. يمثل الاختبار الآلي المدعم بالذكاء الاصطناعي (Agentic AI Testing) تحولًا جوهريًا، حيث يمكن لوكلاء الذكاء الاصطناعي المستقلين التخطيط لاستراتيجيات الاختبار وتنفيذها وتكييفها دون توجيه/تدخل بشري مستمر. هؤلاء ليسوا مجرد مساعدين أذكياء؛ بل هم مختبرون رقميون يتصرفون كمهندسي ضمان جودة ذوي خبرة، يتخذون القرارات، ويتعلمون من الإخفاقات، ويحددون أولويات المخاطر بناءً على التحليل في الوقت الفعلي.
يستكشف هذا الدليل الاختبار الآلي المدعم بالذكاء الاصطناعي من الألف إلى الياء: ما الذي يجعله مختلفًا، وكيف يعزز دورة حياة تطوير البرامج بأكملها، ولماذا أصبح ضروريًا لفرق التطوير الحديثة التي تغرق في التعقيد.
زر
ما هو الاختبار الآلي المدعم بالذكاء الاصطناعي بالضبط؟
يستخدم الاختبار الآلي المدعم بالذكاء الاصطناعي وكلاء ذكاء اصطناعي مستقلين — أنظمة يمكنها إدراك بيئتها، واتخاذ القرارات، واتخاذ الإجراءات لتحقيق أهداف محددة — لأداء اختبار البرامج. على عكس أتمتة الاختبار التقليدية التي تتبع نصوصًا جامدة، فإن هؤلاء الوكلاء:
- يخططون ديناميكيًا: يحللون تغييرات الكود والأخطاء التاريخية وأنماط الاستخدام لتحديد ما يجب اختباره
- ينفذون بذكاء: يتفاعلون مع التطبيقات كالبشر، ويستكشفون الحالات الهامشية ويتكيفون مع تغييرات واجهة المستخدم
- يتعلمون باستمرار: يتذكرون الاختبارات التي عثرت على أخطاء ويعدّلون الاستراتيجيات المستقبلية وفقًا لذلك
- يصلحون أنفسهم ذاتيًا: عندما تتغير واجهة المستخدم، يقوم الوكلاء بتحديث محدداتهم وخطوات الاختبار الخاصة بهم
فكر في الأمر على أنه توظيف مهندس ضمان جودة رفيع المستوى لا ينام أبدًا، ويكتب الاختبارات بسرعة الآلة، ويصبح أكثر ذكاءً مع كل إصدار.
كيف يعزز الذكاء الاصطناعي الوكيلي دورة حياة تطوير البرمجيات
لا يقوم الاختبار الآلي المدعم بالذكاء الاصطناعي بأتمتة الاختبارات فحسب، بل يحسن بشكل أساسي كيفية قيام الفرق ببناء البرامج وشحنها عبر كل مرحلة من مراحل دورة حياة تطوير البرمجيات (SDLC):
تحليل المتطلبات
يحلل الوكلاء قصص المستخدمين ويولّدون تلقائيًا معايير القبول في صيغة Gherkin:
# Auto-generated by AI agent from story: "User can reset password"
Scenario: Password reset with valid email
Given the user is on the login page
When they enter "user@example.com" in the reset form
And click "Send Reset Link"
Then they should see "Check your email"
And receive an email within 2 minutes
تصميم الاختبار
ينشئ الوكلاء مجموعات اختبار شاملة من خلال الجمع بين:
- تحليل تغطية الكود
- أنماط الأخطاء التاريخية
- تعريفات عقود الـ API
- تحليلات رحلة المستخدم
تنفيذ الاختبار
يقوم الوكلاء بتشغيل الاختبارات على مدار الساعة طوال أيام الأسبوع، مع إعطاء الأولوية للمناطق عالية المخاطر بناءً على:
- تغييرات الكود الحديثة
- مقاييس التعقيد
- كثافة العيوب السابقة
- أنماط الاستخدام في الإنتاج
تحليل العيوب
عندما تفشل الاختبارات، لا يكتفي الوكلاء بالإبلاغ — بل يحققون:
- يعزلون السبب الجذري (API مقابل واجهة المستخدم مقابل قاعدة البيانات)
- يقترحون إصلاحات محتملة بناءً على مشكلات سابقة مماثلة
- يتنبأون بالميزات الأخرى التي قد تتأثر
التحسين المستمر
يحلل الوكلاء فعالية الاختبار ويزيلون الاختبارات ذات القيمة المنخفضة بينما ينشئون اختبارات جديدة للمناطق غير المكتشفة.
الاختبار الآلي المدعم بالذكاء الاصطناعي مقابل الاختبار اليدوي: مقارنة واضحة
| الجانب | الاختبار اليدوي | الاختبار الآلي المدعم بالذكاء الاصطناعي |
|---|---|---|
| السرعة | ساعات/أيام لاختبار الانحدار | دقائق للمجموعة الكاملة |
| الاتساق | عرضة للأخطاء البشرية | تنفيذ حتمي |
| التغطية | محدودة بالوقت | شاملة، قابلة للتكيف |
| الاستكشاف | مخصص، قائم على الخبرة | مدفوع بالبيانات، ذكي |
| التعلم | فقدان المعرفة الفردية | ذاكرة مؤسسية |
| التكلفة | عالية (الراتب × الوقت) | منخفضة بعد الإعداد |
| قابلية التوسع | خطية (إضافة أشخاص) | أُسّية (إضافة قدرة حاسوبية) |
| القدرة على التكيف | تحديثات يدوية مطلوبة | محددات ذاتية الإصلاح |
الرؤية الرئيسية: الاختبار الآلي المدعم بالذكاء الاصطناعي لا يحل محل المختبرين البشريين — بل يرتقي بهم. يصبح المختبرون مهندسي اختبار، يركزون على الاستراتيجية بينما يتولى الوكلاء التنفيذ المتكرر.
الأدوات والأطر للاختبار الآلي المدعم بالذكاء الاصطناعي
المنصات التجارية
- Apidog: متخصص في وكلاء اختبار الـ API الذين ينشئون وينفذون الاختبارات من المواصفات باستخدام الذكاء الاصطناعي
- Mabl: منصة منخفضة الكود مع اختبارات واجهة المستخدم ذاتية الإصلاح
- Functionize: اختبار مستقل قائم على السحابة مع إنشاء اختبارات بالمعالجة اللغوية الطبيعية (NLP)

الأطر مفتوحة المصدر
- Playwright + نماذج الذكاء الاصطناعي: وكلاء مخصصون يستخدمون GPT-5 / Sonnet 4.5 لإنشاء الاختبارات وصيانتها
- Cypress مع ملحقات التعلم الآلي: امتدادات ذاتية الإصلاح مدعومة من المجتمع
الأدوات المتخصصة
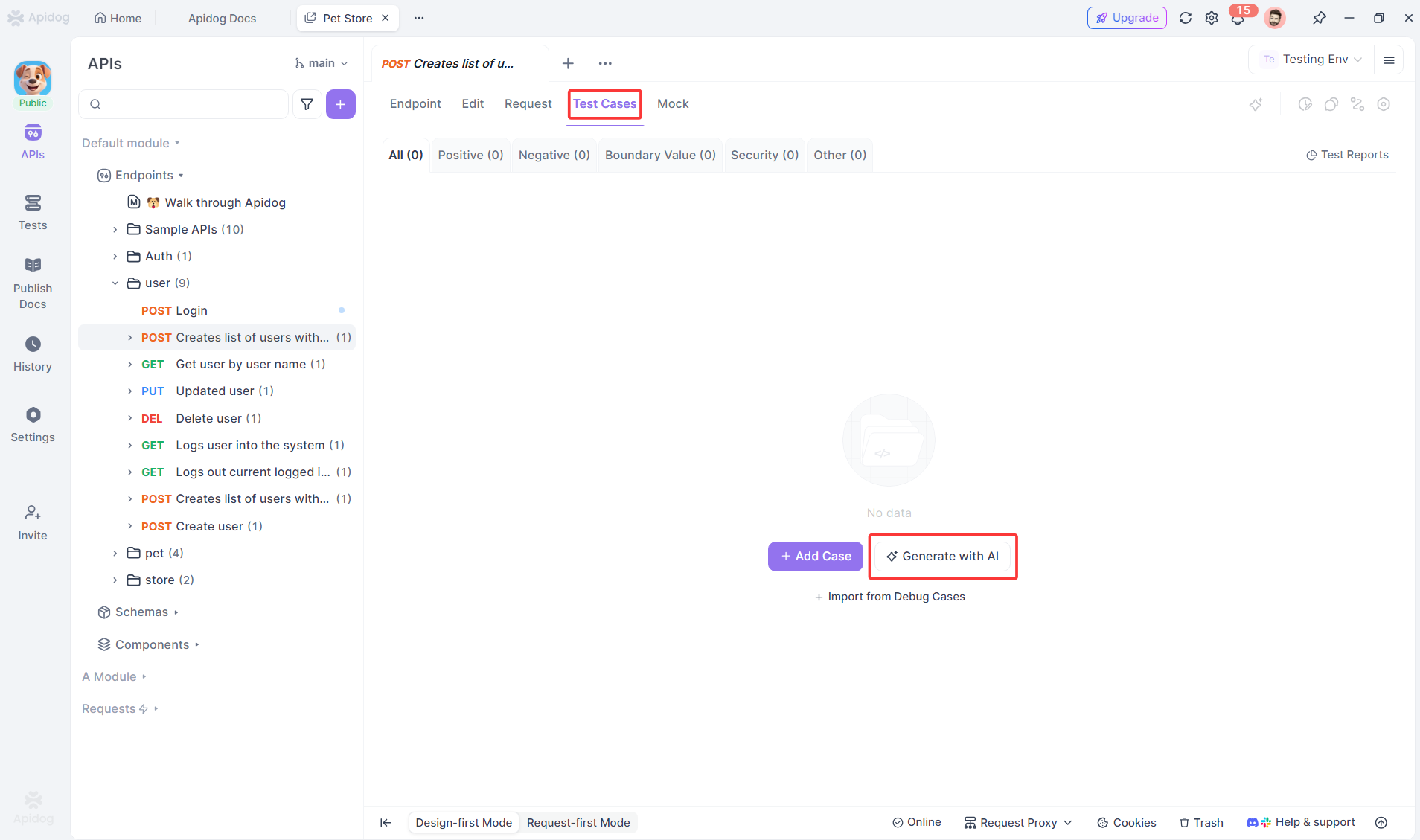
- Apidog: اختبار آلي مدعم بالذكاء الاصطناعي يعتمد على الـ API أولاً، يولد حالات اختبار من مواصفات OpenAPI ويقوم بتشغيلها بشكل مستقل
// مثال: وكيل Apidog AI يولد اختبارات API
const apidog = require('apidog-ai');
// يقرأ الوكيل مواصفات API وينشئ اختبارات شاملة
const testSuite = await apidog.agent.analyzeSpec('openapi.yaml');
// يحدد الوكيل الأولويات بناءً على المخاطر
const prioritizedTests = await apidog.agent.rankByRisk(testSuite);
// يقوم الوكيل بالتنفيذ والتكيف
const results = await apidog.agent.run(prioritizedTests, {
selfHeal: true,
parallel: 10,
maxRetries: 3
});
كيف يتم أداء الاختبار الآلي المدعم بالذكاء الاصطناعي: سير العمل
الخطوة 1: يستوعب الوكيل سياق التطبيق
يقوم الوكيل بمسح:
- مواصفات OpenAPI الخاصة بك
- مخططات قواعد البيانات
- كود الواجهة الأمامية (مكونات React، النماذج)
- نتائج الاختبار التاريخية
- سجلات الإنتاج
الخطوة 2: يولد الوكيل استراتيجية الاختبار
باستخدام نموذج لغوي كبير متصل (Claude, GPT-4)، ينشئ الوكيل:
- اختبارات المسار السعيد (Happy path tests): 40% من المجموعة
- اختبارات الحالات الهامشية (Edge case tests): 35% من المجموعة (القيم الحدودية، المدخلات غير الصالحة)
- الاختبارات السلبية (Negative tests): 15% (الأمان، معالجة الأخطاء)
- الاختبارات الاستكشافية (Exploratory tests): 10% (تدفقات المستخدم غير المعتادة)
الخطوة 3: ينفذ الوكيل الاختبارات بشكل مستقل
الوكيل:
- يدير دورة حياة بيانات الاختبار
- يتعامل مع المصادقة
- يتكيف مع تغييرات واجهة المستخدم (محددات ذاتية الإصلاح)
- يعيد محاولة الاختبارات المتقطعة مع التراجع الأُسِّي
- يلتقط سجلات وتتبعات مفصلة
الخطوة 4: يحلل الوكيل النتائج
بالإضافة إلى النجاح/الفشل، فإن الوكيل:
- ينشئ تقارير الأخطاء مع خطوات إعادة الإنتاج
- ينشئ تسجيلات فيديو للإخفاقات
- يقترح السبب الجذري بناءً على تتبعات المكدس (stack traces)
- يحدد الثغرات في تغطية الاختبار
الخطوة 5: يحدّث الوكيل الاستراتيجية
بناءً على النتائج، فإن الوكيل:
- يزيل الاختبارات غير الفعالة
- ينشئ اختبارات جديدة للمسارات الفائتة
- يعدّل درجات المخاطر لتحديد الأولويات المستقبلية
إيجابيات وسلبيات الاختبار الآلي المدعم بالذكاء الاصطناعي
| الإيجابيات | السلبيات |
|---|---|
| تغطية واسعة: يختبر آلاف السيناريوهات المستحيلة يدويًا | الإعداد الأولي: يتطلب مفاتيح API، وتكوين البيئة |
| ذاتي الإصلاح: يتكيف مع تغييرات واجهة المستخدم تلقائيًا | منحنى التعلم: تحتاج الفرق إلى فهم سلوك الوكيل |
| السرعة: يشغل اختبارات أكثر 1000 مرة في نفس الوقت | التكلفة: قد تتراكم تكاليف الحوسبة وواجهة برمجة تطبيقات النموذج اللغوي الكبير (LLM) |
| الاتساق: لا يوجد خطأ بشري أو إرهاق | السيناريوهات المعقدة: قد يواجه صعوبة في تصميم الاختبار الإبداعي للغاية |
| التوثيق: يولد مواصفات اختبار حية | تصحيح الأخطاء: يمكن أن تكون قرارات الوكيل غامضة بدون تسجيل جيد |
| العمل على مدار الساعة طوال أيام الأسبوع: اختبار مستمر بدون إشراف | الأمان: يحتاج الوكلاء إلى الوصول إلى بيئات الاختبار والبيانات |
كيف يدعم Apidog الاختبار الآلي المدعم بالذكاء الاصطناعي
بينما توجد منصات وكيلية عامة، يتخصص Apidog في وكلاء اختبار الـ API الذين يقدمون قيمة فورية دون إعداد معقد.
توليد حالات الاختبار التلقائي
يقرأ وكيل Apidog AI مواصفات OpenAPI الخاصة بك وينشئ اختبارات شاملة:
# API Spec
paths:
/api/users:
post:
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
email:
type: string
format: email
name:
type: string
minLength: 1
تنفيذ الاختبار الذكي
لا يقوم وكلاء Apidog بتشغيل الاختبارات فحسب — بل يقومون بتحسين التنفيذ:
// يحدد الوكيل الأولويات بناءً على المخاطر
const executionPlan = {
runOrder: ['critical-path', 'high-risk', 'medium-risk', 'low-risk'],
parallelism: 10,
selfHeal: true,
retryFlaky: {
enabled: true,
maxAttempts: 3,
backoff: 'exponential'
}
};
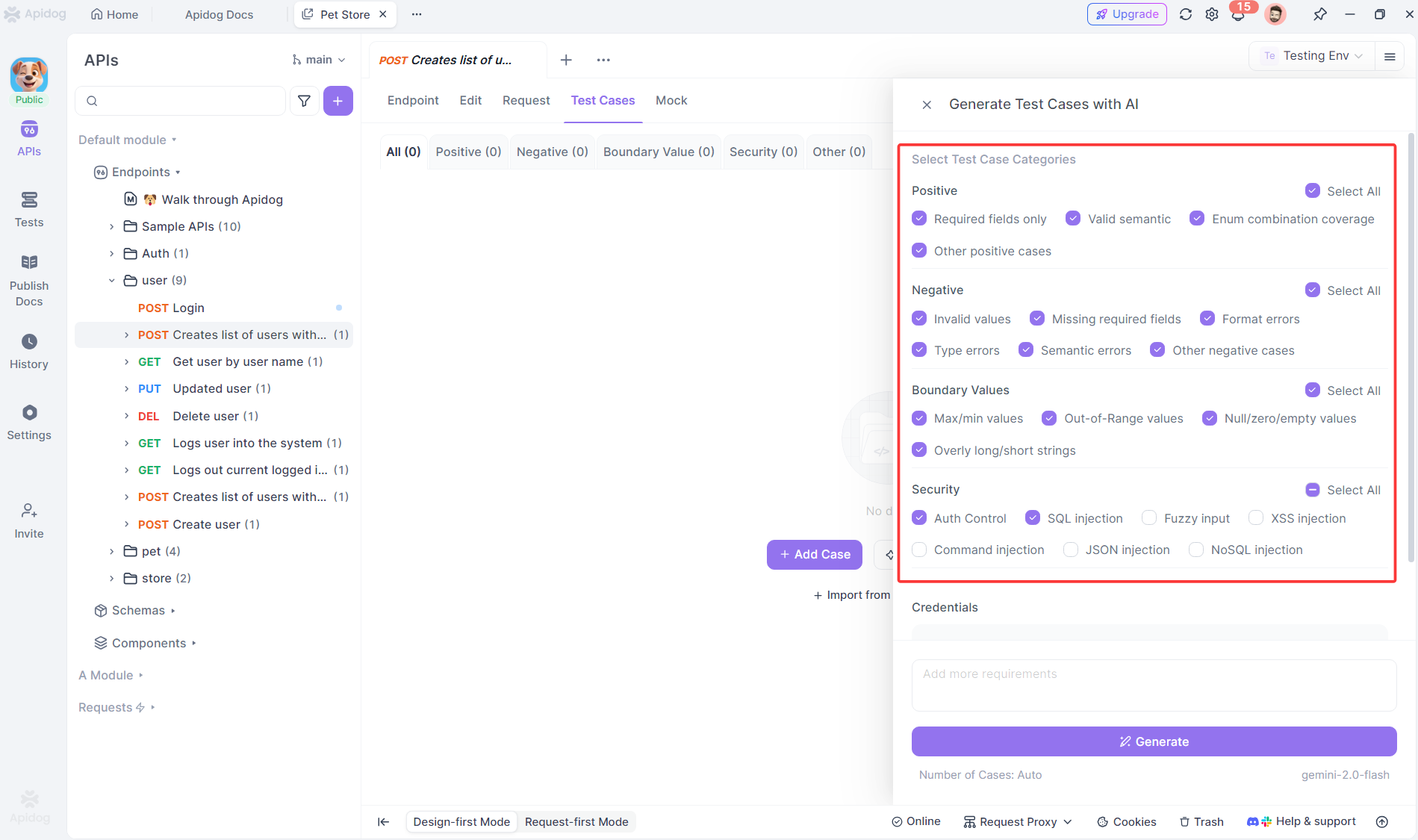
الصيانة التكيفية
عندما تتغير واجهة برمجة التطبيقات (API) الخاصة بك، يكتشفها وكيل Apidog ويقوم بتحديث الاختبارات:
- نقطة نهاية جديدة؟ يولد الوكيل اختبارات تلقائيًا
- حقل تمت إزالته؟ يزيل الوكيل الاختبارات التابعة
- نوع متغير؟ يضبط الوكيل تأكيدات التحقق من الصحة
الأسئلة المتكررة
س1: هل سيحل الاختبار الآلي المدعم بالذكاء الاصطناعي محل فرق ضمان الجودة؟
ج: لا — بل يرتقي بها. يصبح مهندسو ضمان الجودة خبراء في استراتيجيات الاختبار الذين يدربون الوكلاء، ويراجعون نتائجهم، ويركزون على الاختبار الاستكشافي. يتعامل الوكلاء مع التنفيذ المتكرر، ويتعامل البشر مع تحليل المخاطر الإبداعي.
س2: كيف أثق بما يختبره الوكيل؟
ج: يوفر Apidog سجلات تدقيق كاملة لقرارات الوكيل: لماذا اختار اختبارات معينة، وماذا لاحظ، وكيف تكيف. يمكنك مراجعة واعتماد مجموعات الاختبار التي يولدها الوكيل قبل التنفيذ.
س3: هل يمكن للوكلاء اختبار منطق الأعمال المعقد؟
ج: نعم، ولكنهم يحتاجون إلى سياق غني. زودهم بقصص المستخدمين، ومعايير القبول، وقواعد العمل. كلما زاد السياق، كان تصميم اختبار الوكيل أفضل.
س4: ماذا لو فات الوكيل أخطاءً حرجة؟
ج: ابدأ بالاختبارات التي يولدها الوكيل كخط أساس، ثم أضف اختبارات مصممة بشريًا للمناطق الخطرة المعروفة. بمرور الوقت، يتعلم الوكيل من الأخطاء الفائتة ويحسن التغطية.
س5: كيف يتعامل Apidog مع المصادقة في الاختبارات الوكيلية؟
ج: يدير وكلاء Apidog المصادقة تلقائيًا — معالجة تحديث الرمز المميز، وتدفقات OAuth، وتدوير بيانات الاعتماد. يمكنك تحديد المصادقة مرة واحدة، ويستخدمها الوكيل في جميع الاختبارات.
الخاتمة
يمثل الاختبار الآلي المدعم بالذكاء الاصطناعي التطور التالي في ضمان الجودة — الانتقال من الأتمتة المبرمجة إلى التحقق الذكي والمستقل. من خلال تفويض تنفيذ الاختبارات المتكررة للوكلاء، تحقق الفرق مستويات تغطية مستحيلة بالأساليب اليدوية مع تحرير المختبرين البشريين للتركيز على مخاطر الجودة الاستراتيجية.
التكنولوجيا متاحة اليوم. أدوات مثل Apidog تجعلها في متناول اليد دون استثمار ضخم في البنية التحتية. ابدأ صغيرًا: دع وكيلًا ينشئ اختبارات لنقطة نهاية API واحدة، راجع عمله، وشاهد النتائج. مع ازدياد الثقة، وسّع الاختبار الآلي المدعم بالذكاء الاصطناعي عبر تطبيقك.
مستقبل الاختبار ليس في قيام المزيد من البشر بكتابة المزيد من النصوص البرمجية — بل في وكلاء أكثر ذكاءً يتعاونون مع البشر لبناء برامج تعمل بالفعل في الواقع. هذا المستقبل هو الاختبار الآلي المدعم بالذكاء الاصطناعي، وهو بالفعل يغير طريقة شحن الفرق الحديثة لكود عالي الجودة.
زر