
DeepSeekは、推論と効率を優先するリリースによって、大規模言語モデルの進化を続けています。現在、エンジニアや研究者は、複雑な問題解決とエージェントワークフローに優れたモデルであるDeepSeek-V3.2およびDeepSeek-V3.2-Specialeを利用しています。これらのツールはアプリケーションにシームレスに統合されますが、開発者はセットアップ、認証、最適化で課題に直面することがよくあります。この記事では、これらのモデルを効果的に活用するための段階的な技術ガイドを提供します。
DeepSeek-V3.2を理解する:高度な推論のためのオープンソース基盤
開発者は、透明性、カスタマイズ性、コミュニティ主導の改善が期待できるオープンソースモデルに基づいて堅牢なAIシステムを構築します。DeepSeek-V3.2は、DeepSeekが疎なアテンションメカニズムをテストするために以前リリースした実験的なV3.2-Expバリアントの正式な後継です。このモデルは、合計6,710億パラメータのMixture-of-Experts(MoE)アーキテクチャのうち370億パラメータをアクティブ化し、14.8兆個の高品質なトークンでトレーニングされています。このような規模により、DeepSeek-V3.2は自然言語生成から複雑な数学的証明まで、さまざまなタスクを処理できます。
このモデルの核となるイノベーションは、DeepSeek Sparse Attention(DSA)にあります。これは、特に128,000トークンまでの長いコンテキストにおいて、推論中の計算オーバーヘッドを削減するきめ細かいメカニズムです。エンジニアがこれを評価するのは、出力品質を維持しながらレイテンシを削減できるためです。これはチャットボットやコードアシスタントのようなリアルタイムアプリケーションにとって不可欠です。さらに、DeepSeek-V3.2は「思考」モードを統合しており、モデルが最終出力の前に中間推論ステップを生成することで、AIME 2025やHMMT 2025などのベンチマークでの精度を向上させています。
Hugging Faceのオープンソース版はdeepseek-ai/DeepSeek-V3.2でアクセスできます。開発者はウェイトと設定を直接ダウンロードし、GPUクラスターへのローカルデプロイを可能にします。例えば、Transformersライブラリを使用してモデルをロードするには、次のようにします。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "deepseek-ai/DeepSeek-V3.2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "Solve this equation: x^2 + 3x - 4 = 0"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200, do_sample=False)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
このコードスニペットは、最新のNVIDIA GPUでの効率のために、モデルをbfloat16精度で初期化します。ただし、ローカル実行にはかなりのハードウェアが必要であり、完全な精度を得るには少なくとも8基のA100 GPUが推奨されます。そのため、多くのチームは、コンシューマー向けハードウェアに適合させるために、bitsandbytesのようなライブラリを介して量子化バージョンを選択しています。
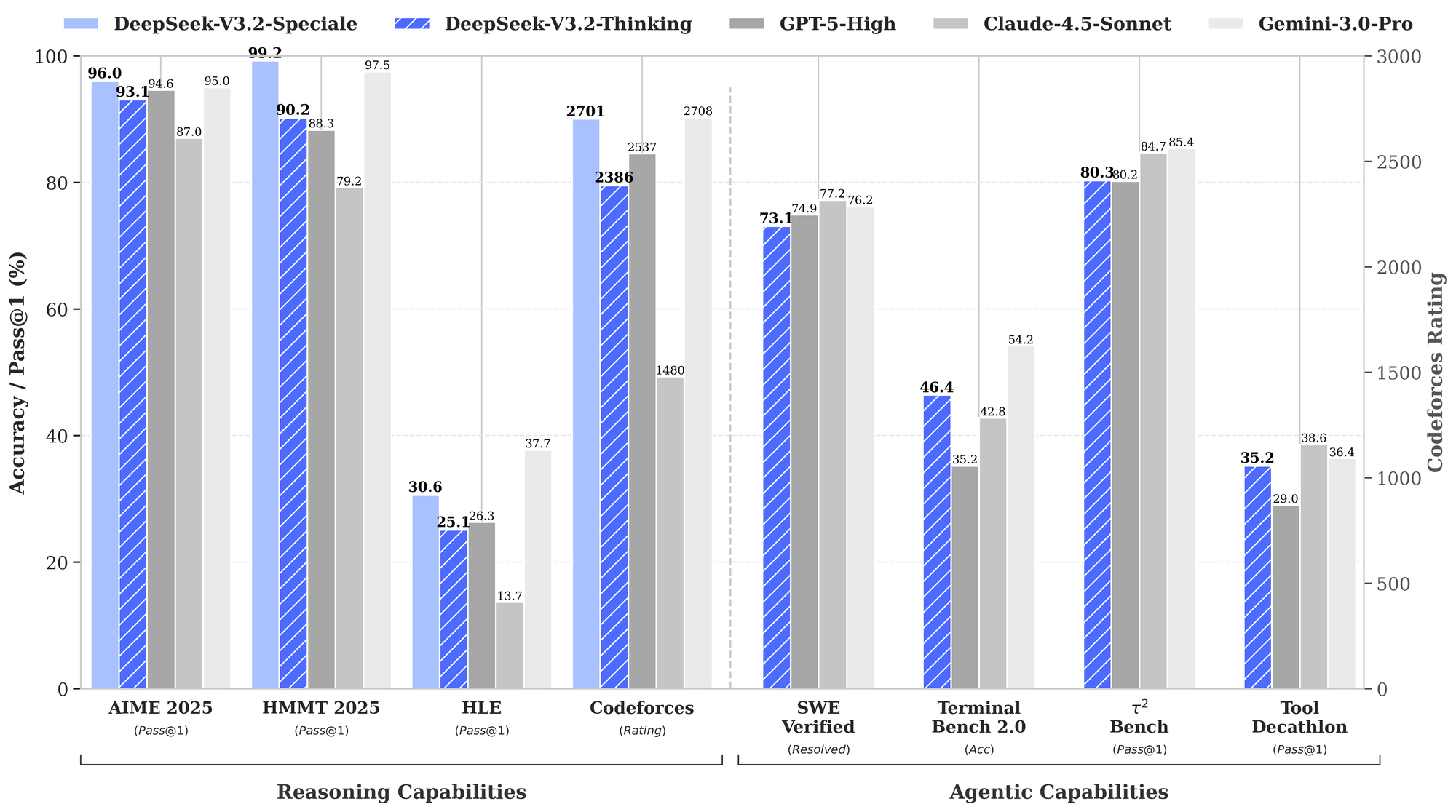
ベンチマークはDeepSeek-V3.2の強みを浮き彫りにしています。推論タスクでは、AIME 2025(pass@1)で93.1%を達成し、GPT-5-Highの90.2%を上回りました。エージェント能力では、SWE-Bench Verifiedで2,537の問題を解決し、Claude-4.5-Sonnetの2,536を僅差で上回っています。これらの指標は、DeepSeek-V3.2が、推論速度が純粋な知能と同じくらい重要である本番環境向けのバランスの取れた「日常の主力」であることを示しています。
さらに、このモデルは将来のアップデートでマルチモーダル拡張をサポートする予定ですが、現在のリリースはテキストベースの推論に焦点を当てています。エンジニアはLoRAアダプターを使用してドメイン固有のデータセットでファインチューニングを行い、基本的な機能を維持しつつ、法律分析や科学シミュレーションなどのニッチな分野に適応させています。その結果、オープンソースへのアクセスは、ベンダーロックインなしに迅速なプロトタイプ作成を可能にします。
DeepSeek-V3.2-Specialeを探る:最高の推論パフォーマンスのために最適化
DeepSeek-V3.2は幅広い用途を提供しますが、DeepSeek-V3.2-Specialeは、最大の認知深度が要求されるシナリオをターゲットにしています。このバリアントは推論の限界を押し広げ、エリートコンペティションでGemini-3.0-Proと競合します。IMO 2025、CMO、ICPC World Finals、IOI 2025で金メダルの成績を収めており、これらは微妙な論理的連鎖と創造的な問題解決を必要とする偉業です。
DeepSeek-V3.2-Specialeは同じMoE基盤に基づいていますが、人間のフィードバックからの強化学習(RLHF)ステージを強化し、エージェント的な振る舞いを重視しています。ベースモデルとは異なり、より長い内部思考プロセスを生成するため、より多くのトークンを消費しますが、多段階環境でのツール使用などのタスクで優れた精度を発揮します。例えば、1,800以上のシミュレートされた世界と85,000以上の指示にわたるトレーニングデータを統合することで、未経験のシナリオを堅牢に処理することを可能にします。
Hugging Faceのモデルカードはdeepseek-ai/DeepSeek-V3.2-Specialeで閲覧できます。ダウンロードは同様のプロセスで行われます。
model_name = "deepseek-ai/DeepSeek-V3.2-Speciale"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto"
)
prompt = "Prove that the sum of angles in a triangle is 180 degrees."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=500, temperature=0.1)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
Specialeはカスタムのアテンション実装を採用しているため、trust_remote_code=Trueフラグに注意してください。この設定はさらに多くのVRAMを要求し、非量子化推論には最大1TBが必要となるため、エッジデバイスよりも研究室での使用に最適です。
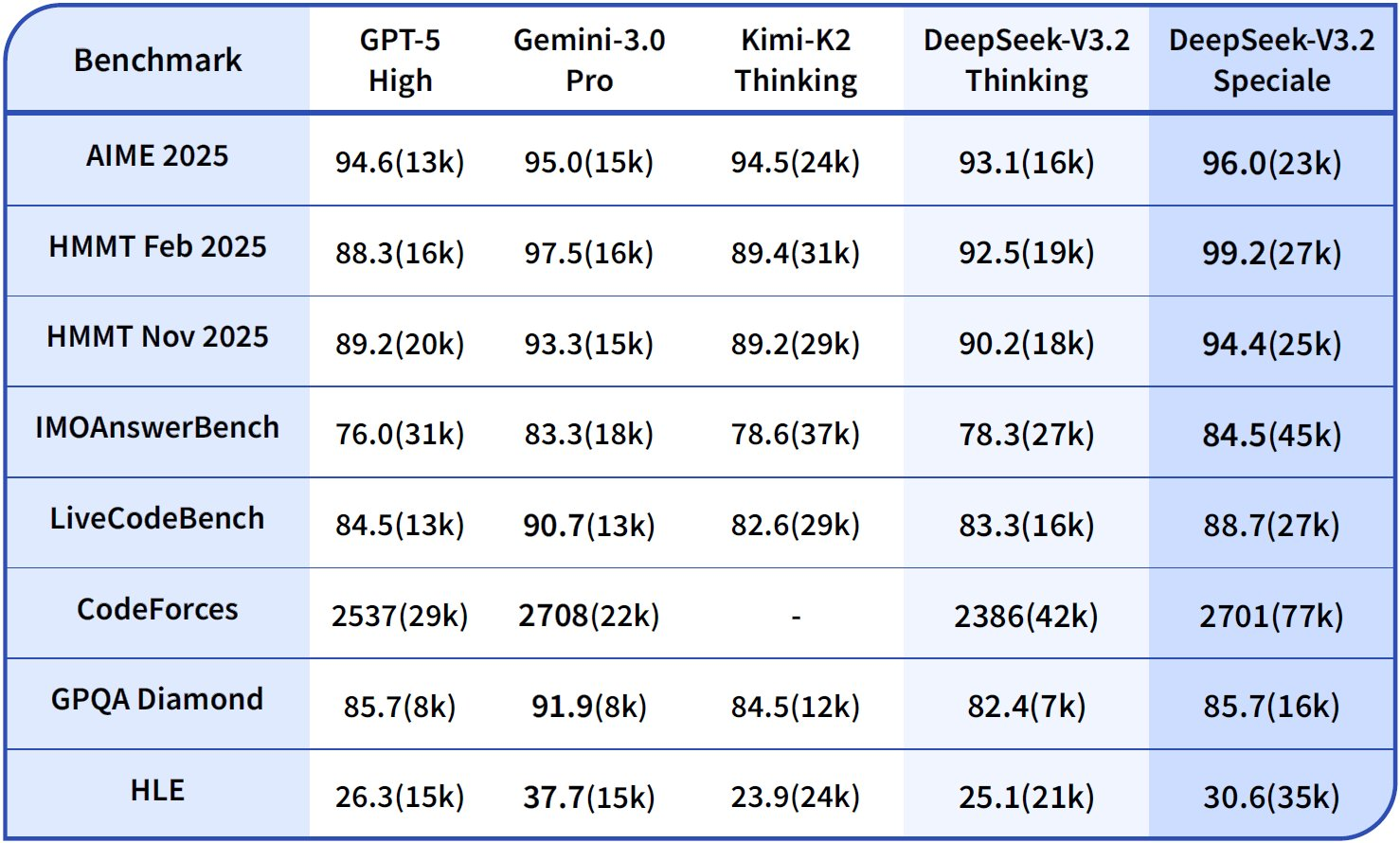
パフォーマンスデータはその優位性を浮き彫りにしています。提示されたベンチマークチャートは、DeepSeek-V3.2-Speciale(青いバー)が推論でリードしていることを示しています。HMMT 2025(pass@1)では99.0%を達成し、GPT-5-Highの97.5%を上回り、Codeforces(レーティング)ではClaude-4.5-Sonnetの84.7%に対し84.8%の精度を誇ります。エージェント領域では、Terminal-Bench v0.2(84.3%の精度)とTool-Use(pass@1)で優れており、連鎖的な操作で差が広がる僅差で勝利することがよくあります。ただし、V3.2より最大50%多いトークン使用量は、コストを抑えるために慎重なプロンプトエンジニアリングを必要とします。
Specialeは最初のリリースではネイティブのツール使用機能がないため、開発者はハイブリッドエージェントのために外部APIと連携させます。このアプローチは評価で際立っており、8万5千以上の指示ベンチマークで他のモデルを凌駕しています。全体として、DeepSeek-V3.2-Specialeは、自動定理証明や戦略的計画シミュレーションなどの高リスクなアプリケーションに適しています。
オープンソースからAPIへの移行:ホスト型アクセスが重要な理由
ローカルデプロイは制御を提供しますが、スケールアップはハードウェアのプロビジョニングやメンテナンスといった複雑さを伴います。開発者は、即時アクセス、従量課金制、管理されたインフラストラクチャのためにAPIに頼ります。DeepSeekは、V3.2とV3.2-Specialeの両方に対してホスト型エンドポイントを提供し、OpenAIスタイルのインターフェースとの互換性を保証します。この移行により、チームはセットアップの障害を回避し、統合に集中できるため、プロトタイピングが加速されます。
さらに、APIアクセスは、レート制限やキャッシュなどのエンタープライズ機能を利用可能にし、本番環境の負荷を最適化します。たとえば、キャッシュヒットは入力コストを劇的に削減し、繰り返しのクエリを経済的にします。その結果、スタートアップ企業や大企業は、コストに敏感なデプロイメントのためにこれらのエンドポイントを採用しています。
DeepSeek APIへのアクセス:ステップバイステップのセットアップ
エンジニアは、公式プラットフォームを通じてDeepSeek APIにアクセスします。まず、アカウントを作成し、「API Keys」セクションでAPIキーを生成します。このキーは、Authorizationヘッダー:Bearer YOUR_API_KEYを介してリクエストを認証します。
ベースURLはhttps://api.deepseek.com/v1です。DeepSeek-V3.2の場合は、モデル識別子deepseek-v3.2を使用します。DeepSeek-V3.2-Specialeは一時的なエンドポイントhttps://api.deepseek.com/v3.2_speciale_expires_on_20251215で動作し、2025年12月15日UTC 15:59まで利用可能です。この日付以降、標準提供に統合されます。
簡素化のためにOpenAI SDKをインストールします。
pip install openai
次に、クライアントを設定します。
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.deepseek.com/v1"
)
DeepSeek-V3.2の補完リクエストを送信します。
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant focused on reasoning."},
{"role": "user", "content": "Explain quantum entanglement in simple terms."}
],
max_tokens=300,
temperature=0.7
)
print(response.choices[0].message.content)
DeepSeek-V3.2-Specialeの場合は、base_urlとモデルを調整します。
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.deepseek.com/v3.2_speciale_expires_on_20251215"
)
response = client.chat.completions.create(
model="deepseek-v3.2-speciale",
messages=[{"role": "user", "content": "Solve: Integrate e^x sin(x) dx."}],
max_tokens=500
)
これらの呼び出しは、プロンプトと補完トークンを含む使用状況統計を伴うJSONレスポンスを返します。レート制限(例:V3.2の場合10,000 RPM)をチェックしながら、try-exceptブロックを介してエラーを処理します。
さらに、モデル名に/thinkingを追加することで、思考モードを有効にできます(例:deepseek-v3.2/thinking)。これにより段階的な推論がトリガーされ、複雑なクエリのデバッグに最適です。
API料金:DeepSeek-V3.2とSpecialeの費用対効果の高いスケーリング
料金設定はAPI導入の要石であり、DeepSeekは100万トークンあたりの料金を透明に構成しています。両モデルとも同じ料金体系で、入力(キャッシュヒット/ミス)と出力に基づいて課金されます。キャッシュヒットはセッション内の繰り返されるプレフィックスに適用され、反復的なワークフローのコストを削減します。
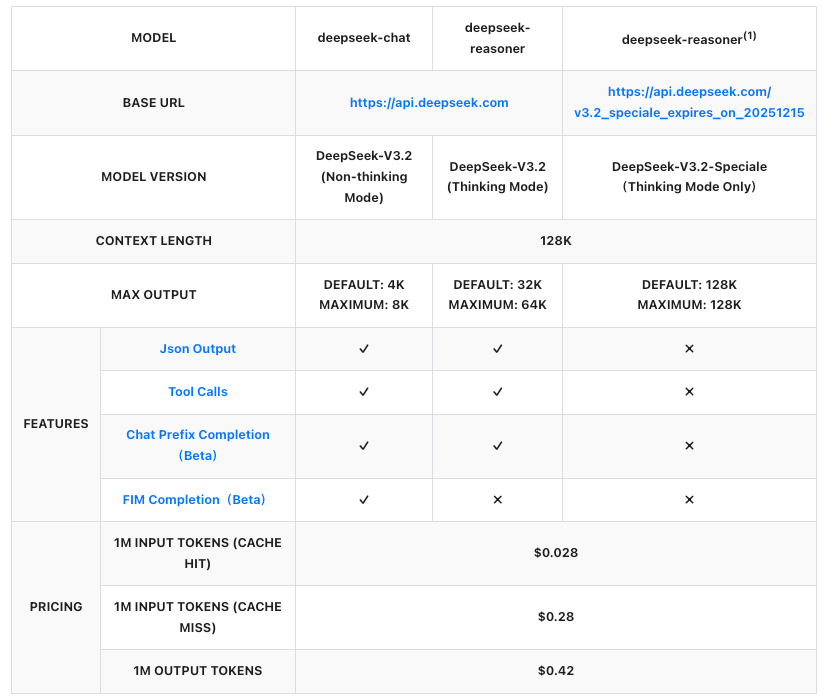
これらの数値は以前のバージョンから50%以上の削減を示しており、DeepSeekをプロプライエタリAPIと競争力のあるものにしています。例えば、500トークンのプロンプト(キャッシュミス)で1,000トークンの応答を生成するのにかかる費用は約0.00035ドルであり、ほとんどのユースケースでは無視できるレベルです。企業はより大量の利用のためにカスタムプランを交渉しますが、従量課金制は開発者にとって適しています。
そのため、チームはDeepSeekダッシュボードのトークン見積もりツールを使用して費用を予測します。Specialeのより高いトークン消費量を考慮に入れてください。推論に重いクエリはコストを倍増させる可能性がありますが、Tau²(Specialeではpass@1で29.0% vs V3.2では25.1%)のようなベンチマークでは精度が4倍になる可能性があります。
Apidogとの統合:効率的なAPIテストとドキュメント作成
開発者は、コードなしでAPIを設計、テスト、ドキュメント化できるApidogのようなツールでワークフローを効率化します。DeepSeek APIキーをApidogの環境変数にインポートし、V3.2およびSpecialeエンドポイント用の新しいリクエストコレクションを作成します。
/chat/completionsへのPOSTリクエストを構築します。
- ヘッダー:
Authorization: Bearer {{api_key}},Content-Type: application/json - ボディ: モデル、メッセージ、パラメータを含むJSONペイロード。
Apidogのインターフェースでテストを実行すると、応答とアサーションが自動生成されます。たとえば、数学のプロンプトでSpecialeの出力が200トークンを超えることを検証できます。さらに、ApidogはOpenAPIスペックをエクスポートするため、チーム間の引き継ぎが容易になります。
この統合により、視覚的な差分が不一致を浮き彫りにするため、デバッグ時間が40%削減されます。チームはオフライン開発のために応答をモックすることもでき、ライブデプロイ前に堅牢性を確保します。
高度なテクニック:ツール利用とエージェントワークフロー
DeepSeek-V3.2は、内部推論と外部呼び出しを融合させたツール利用における思考を導入しています。APIペイロードでツールを指定します。
tools = [
{
"type": "function",
"function": {
"name": "calculator",
"description": "Perform basic math",
"parameters": {
"type": "object",
"properties": {"expression": {"type": "string"}}
}
}
}
]
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[{"role": "user", "content": "What is 15% of 250?"}],
tools=tools,
tool_choice="auto"
)
モデルは段階的に推論し、必要に応じてツールを呼び出します。現在ツールを持たないSpecialeは、複数モデルのチェーンにおいて推論オラクルとしてうまく機能します。
エージェントの場合、LangChainを介してオーケストレーションします。DeepSeekの呼び出しを、タスクを動的にルーティングするエージェント内にラップします。この設定により、ベンチマークによると、SWE-Bench Verifiedの課題の73.1%が解決されます。
本番環境デプロイメントのベストプラクティス
思考モードを活用するために、思考連鎖テンプレートでプロンプトを最適化します。APIメタデータを通じてトークン使用量を監視し、予算上限に対するフォールバックを実装します。高スループットアプリケーションのために、Pythonの非同期クライアントでスケールします。
セキュリティにはキーのローテーションとIPホワイトリスティングが必要です。最後に、技術レポートにあるようなベンチマークに対して反復的に評価し、ドメイン適合のためにハイパーパラメータを調整します。
結論:今日からDeepSeekの力を活用しよう
DeepSeek-V3.2とDeepSeek-V3.2-Specialeは、アクセスしやすいAI推論を再定義します。オープンソースの柔軟性からAPIの効率性まで、これらのモデルは開発者がよりスマートなエージェントを構築する力を与えます。まずはローカルでの実験から始め、ホスト型エンドポイントに移行し、シームレスなテストのためにApidogを統合しましょう。ベンチマークが進化するにつれて、DeepSeekの軌跡はさらに大きな可能性を約束します。あなたのプロジェクトを最前線に位置づけましょう。