
El procesamiento de documentos ha sido durante mucho tiempo una de las aplicaciones más prácticas de la IA; sin embargo, la mayoría de las soluciones de OCR obligan a un incómodo compromiso entre precisión y eficiencia. Los sistemas tradicionales como Tesseract requieren un preprocesamiento extenso. Las API en la nube cobran por página y añaden latencia. Incluso los modelos modernos de visión-lenguaje luchan con la explosión de tokens que proviene de imágenes de documentos de alta resolución.
DeepSeek-OCR 2 cambia esta ecuación por completo. Basándose en el enfoque de "Compresión Óptica de Contextos" de la versión 1, la nueva versión introduce el "Flujo Causal Visual"—una arquitectura que procesa documentos de la manera en que los humanos realmente los leen, comprendiendo las relaciones visuales y el contexto en lugar de simplemente reconocer caracteres. El resultado es un modelo que logra un 97% de precisión mientras comprime imágenes a tan solo 64 tokens, lo que permite un rendimiento de más de 200,000 páginas por día en una sola GPU.
Esta guía cubre todo, desde la configuración básica hasta la implementación en producción, con código funcional que puedes copiar, pegar y ejecutar de inmediato.
¿Qué es DeepSeek-OCR 2?
DeepSeek-OCR 2 es un modelo de visión-lenguaje de código abierto diseñado específicamente para la comprensión de documentos y la extracción de texto. Lanzado por DeepSeek AI en enero de 2026, se basa en el DeepSeek-OCR original con una nueva arquitectura de "Flujo Causal Visual" que modela cómo los elementos visuales en los documentos se relacionan causalmente entre sí, entendiendo que un encabezado de tabla determina cómo deben interpretarse las celdas debajo de él, o que una leyenda explica el gráfico que tiene encima.
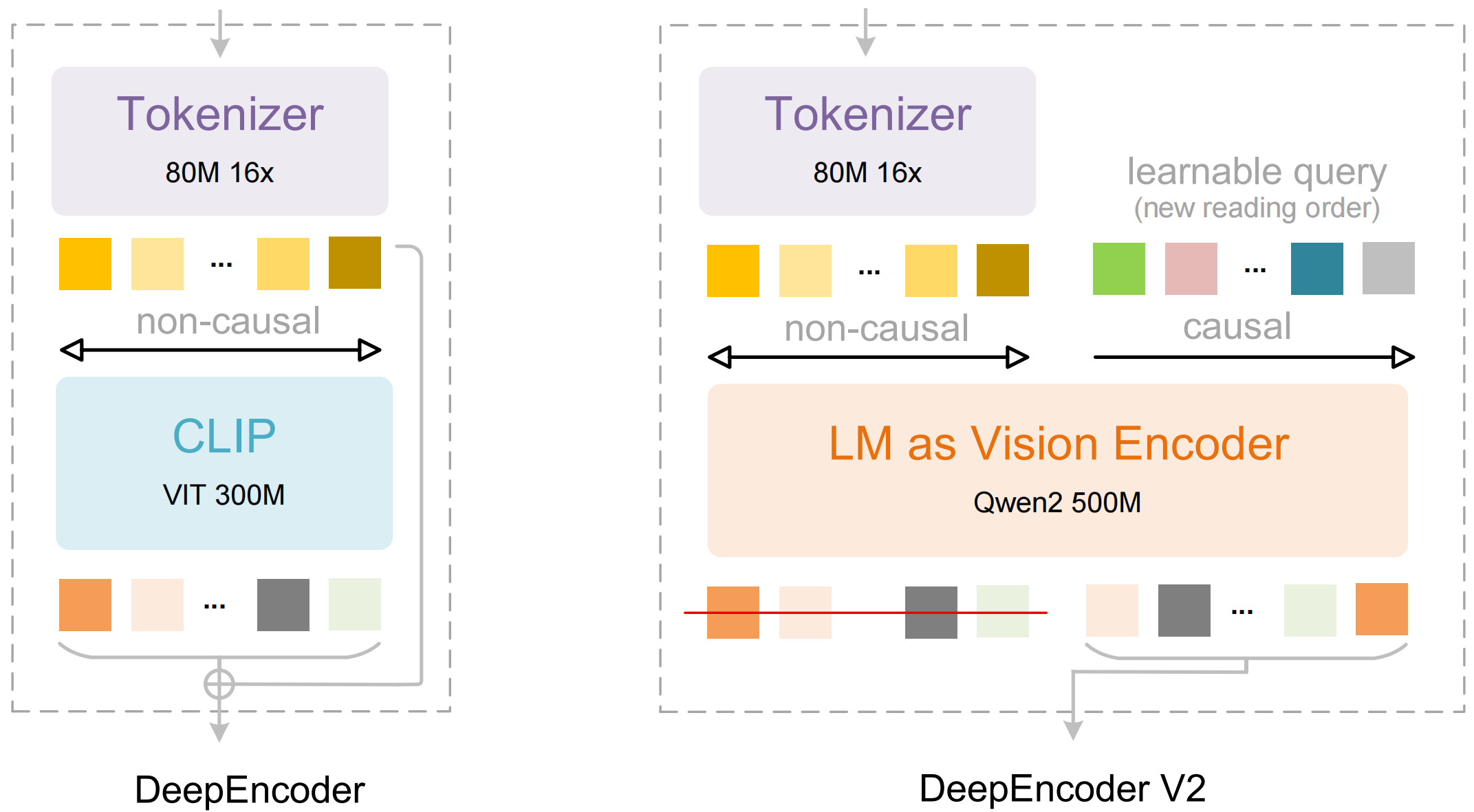
El modelo consta de dos componentes principales:
- DeepEncoder: Un transformador de visión dual que combina la extracción de detalles locales (basado en SAM, 80M de parámetros) con la comprensión global del diseño (basado en CLIP, 300M de parámetros)
- Decodificador DeepSeek3B-MoE: Un modelo de lenguaje de mezcla de expertos que genera una salida estructurada (Markdown, LaTeX, JSON) a partir de la representación visual comprimida
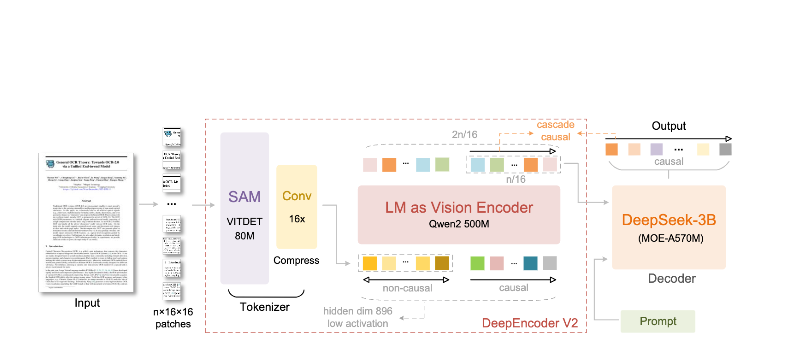
Lo que hace diferente a DeepSeek-OCR 2:
- Compresión extrema: Reduce una imagen de 1024×1024 de 4.096 parches a solo 256 tokens, una reducción de 16 veces
- Salida estructurada: Genera Markdown limpio con tablas, encabezados y formato adecuados
- Soporte multiformato: Maneja PDFs, documentos escaneados, capturas de pantalla, notas escritas a mano y más
- Más de 100 idiomas: Entrenado con 30 millones de páginas que cubren aproximadamente 100 idiomas
- Pesos abiertos: Con licencia MIT, disponible en Hugging Face
Características Clave y Arquitectura
Flujo Causal Visual
La característica principal de la versión 2 es el "Flujo Causal Visual"—un nuevo enfoque para comprender documentos que va más allá del simple OCR. En lugar de tratar una página como una cuadrícula plana de caracteres, el modelo aprende relaciones causales entre los elementos visuales:
- Inferencia del orden de lectura: Determina automáticamente la secuencia correcta para diseños de varias columnas
- Comprensión de la estructura de tablas: Reconoce encabezados, celdas fusionadas y tablas anidadas
- Vinculación figura-leyenda: Asocia imágenes con sus descripciones
- Análisis de expresiones matemáticas: Maneja LaTeX en línea y en bloque con precisión
Arquitectura de DeepEncoder
El DeepEncoder es donde ocurre la magia. Procesa imágenes de alta resolución mientras mantiene un recuento de tokens manejable:
Input Image (1024×1024)
↓
SAM-base Block (80M params)
- Windowed attention for local detail
- Extracts fine-grained features
↓
CLIP-large Block (300M params)
- Global attention for layout
- Understands document structure
↓
Convolution Block
- 16× token reduction
- 4,096 patches → 256 tokens
↓
Output: Compressed Vision Tokens
Compromiso entre Compresión y Precisión
| Relación de Compresión | Tokens de Visión | Precisión |
|---|---|---|
| 4× | 1.024 | 99%+ |
| 10× | 256 | 97% |
| 16× | 160 | 92% |
| 20× | 128 | ~60% |
El punto óptimo para la mayoría de las aplicaciones es la relación de compresión de 10×, que mantiene una precisión del 97% mientras permite el alto rendimiento que hace práctica la implementación en producción.
Instalación y Configuración
Requisitos Previos
- Python 3.10+ (3.12.9 recomendado)
- CUDA 11.8+ con GPU NVIDIA compatible
- Al menos 16 GB de memoria de GPU (A100-40G recomendado para producción)
Método 1: Instalación de vLLM (Recomendado)
vLLM proporciona el mejor rendimiento para implementaciones de producción:
# Create virtual environment
python -m venv deepseek-ocr-env
source deepseek-ocr-env/bin/activate
# Install vLLM with CUDA support
pip install vllm>=0.8.5
# Install flash attention for optimal performance
pip install flash-attn==2.7.3 --no-build-isolation
Método 2: Instalación de Transformers
Para desarrollo y experimentación:
pip install transformers>=4.40.0
pip install torch>=2.6.0 torchvision>=0.21.0
pip install accelerate
pip install flash-attn==2.7.3 --no-build-isolation
Método 3: Docker (Producción)
FROM nvidia/cuda:11.8-devel-ubuntu22.04
RUN pip install vllm>=0.8.5 flash-attn==2.7.3
# Pre-download model
RUN python -c "from vllm import LLM; LLM(model='deepseek-ai/DeepSeek-OCR-2')"
EXPOSE 8000
CMD ["vllm", "serve", "deepseek-ai/DeepSeek-OCR-2", "--port", "8000"]
Verificar Instalación
import torch
print(f"PyTorch version: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
print(f"GPU: {torch.cuda.get_device_name(0)}")
import vllm
print(f"vLLM version: {vllm.__version__}")
Ejemplos de Código Python
OCR Básico con vLLM
Aquí está la forma más sencilla de extraer texto de una imagen de documento:
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
# Initialize the model
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
trust_remote_code=True,
)
# Load your document image
image = Image.open("document.png").convert("RGB")
# Prepare the prompt - "Free OCR." triggers standard extraction
prompt = "<image>\nFree OCR."
model_input = [{
"prompt": prompt,
"multi_modal_data": {"image": image}
}]
# Configure sampling parameters
sampling_params = SamplingParams(
temperature=0.0, # Deterministic for OCR
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822}, # <td>, </td> for tables
},
skip_special_tokens=False,
)
# Generate output
outputs = llm.generate(model_input, sampling_params)
# Extract the markdown text
markdown_text = outputs[0].outputs[0].text
print(markdown_text)
Procesamiento por Lotes de Múltiples Documentos
Procesa múltiples documentos de manera eficiente en un solo lote:
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
from pathlib import Path
def batch_ocr(image_paths: list[str], llm: LLM) -> list[str]:
"""Process multiple images in a single batch."""
# Load all images
images = [Image.open(p).convert("RGB") for p in image_paths]
# Prepare batch input
prompt = "<image>\nFree OCR."
model_inputs = [
{"prompt": prompt, "multi_modal_data": {"image": img}}
for img in images
]
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
skip_special_tokens=False,
)
# Generate all outputs in one call
outputs = llm.generate(model_inputs, sampling_params)
return [out.outputs[0].text for out in outputs]
# Usage
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
)
image_files = list(Path("documents/").glob("*.png"))
results = batch_ocr([str(f) for f in image_files], llm)
for path, text in zip(image_files, results):
print(f"--- {path.name} ---")
print(text[:500]) # First 500 chars
print()
Usando Transformers Directamente
Para un mayor control sobre el proceso de inferencia:
import torch
from transformers import AutoModel, AutoTokenizer
from PIL import Image
# Set GPU
device = "cuda:0"
# Load model and tokenizer
model_name = "deepseek-ai/DeepSeek-OCR-2"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation="flash_attention_2",
trust_remote_code=True,
use_safetensors=True,
)
model = model.eval().to(device).to(torch.bfloat16)
# Load and preprocess image
image = Image.open("document.png").convert("RGB")
# Different prompts for different tasks
prompts = {
"ocr": "<image>\nFree OCR.",
"markdown": "<image>\n<|grounding|>Convert the document to markdown.",
"table": "<image>\nExtract all tables as markdown.",
"math": "<image>\nExtract mathematical expressions as LaTeX.",
}
# Process with your chosen prompt
prompt = prompts["markdown"]
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# Add image to inputs (model-specific preprocessing)
with torch.no_grad():
outputs = model.generate(
**inputs,
images=[image],
max_new_tokens=4096,
do_sample=False,
)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
Procesamiento Asíncrono para Alto Rendimiento
import asyncio
from vllm import AsyncLLMEngine, AsyncEngineArgs, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
async def process_document(engine, image_path: str, request_id: str):
"""Process a single document asynchronously."""
image = Image.open(image_path).convert("RGB")
prompt = "<image>\nFree OCR."
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
)
results = []
async for output in engine.generate(prompt, sampling_params, request_id):
results.append(output)
return results[-1].outputs[0].text
async def main():
# Initialize async engine
engine_args = AsyncEngineArgs(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
)
engine = AsyncLLMEngine.from_engine_args(engine_args)
# Process multiple documents concurrently
image_paths = ["doc1.png", "doc2.png", "doc3.png"]
tasks = [
process_document(engine, path, f"req_{i}")
for i, path in enumerate(image_paths)
]
results = await asyncio.gather(*tasks)
for path, text in zip(image_paths, results):
print(f"{path}: {len(text)} characters extracted")
asyncio.run(main())
Usando vLLM para Producción
Iniciando el Servidor Compatible con OpenAI
Despliega DeepSeek-OCR 2 como un servidor API:
vllm serve deepseek-ai/DeepSeek-OCR-2 \
--host 0.0.0.0 \
--port 8000 \
--logits_processors vllm.model_executor.models.deepseek_ocr:NGramPerReqLogitsProcessor \
--no-enable-prefix-caching \
--mm-processor-cache-gb 0 \
--max-model-len 16384 \
--gpu-memory-utilization 0.9
Llamando al Servidor con el SDK de OpenAI
from openai import OpenAI
import base64
# Initialize client pointing to local server
client = OpenAI(
api_key="EMPTY", # Not required for local server
base_url="http://localhost:8000/v1",
timeout=3600,
)
def encode_image(image_path: str) -> str:
"""Encode image to base64."""
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
def ocr_document(image_path: str) -> str:
"""Extract text from document using OCR API."""
base64_image = encode_image(image_path)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{base64_image}"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
max_tokens=8192,
temperature=0.0,
extra_body={
"skip_special_tokens": False,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822],
},
},
)
return response.choices[0].message.content
# Usage
result = ocr_document("invoice.png")
print(result)
Usando con URLs
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/document.png"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
max_tokens=8192,
temperature=0.0,
)
Probando con Apidog
Probar las APIs de OCR de manera efectiva requiere visualizar tanto los documentos de entrada como la salida extraída. Apidog proporciona una interfaz intuitiva para experimentar con DeepSeek-OCR 2.
Configurando el Endpoint de OCR
Paso 1: Crear una Nueva Solicitud
- Abre Apidog y crea un nuevo proyecto
- Añade una solicitud POST a
http://localhost:8000/v1/chat/completions
Paso 2: Configurar Encabezados
Content-Type: application/json
Paso 3: Configurar Cuerpo de la Solicitud
{
"model": "deepseek-ai/DeepSeek-OCR-2",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,{{base64_image}}"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
"max_tokens": 8192,
"temperature": 0,
"extra_body": {
"skip_special_tokens": false,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822]
}
}
}
Probando Diferentes Tipos de Documentos
Crea solicitudes guardadas para tipos de documentos comunes:
- Extracción de facturas - Prueba de extracción de datos estructurados
- Artículo académico - Prueba de manejo de matemáticas en LaTeX
- Notas manuscritas - Prueba de reconocimiento de escritura a mano
- Diseño de varias columnas - Prueba de inferencia del orden de lectura
Comparando Modos de Resolución
Configura variables de entorno para probar rápidamente diferentes modos:
| Modo | Resolución | Tokens | Caso de Uso |
|---|---|---|---|
tiny | 512×512 | 64 | Vistas previas rápidas |
small | 640×640 | 100 | Documentos simples |
base | 1024×1024 | 256 | Documentos estándar |
large | 1280×1280 | 400 | Texto denso |
gundam | Dinámico | Variable | Diseños complejos |

Modos de Resolución y Compresión
DeepSeek-OCR 2 soporta cinco modos de resolución, cada uno optimizado para diferentes casos de uso:
Modo Minúsculo (64 tokens)
Mejor para: Detección rápida de texto, formularios simples, entradas de baja resolución
# Configure for tiny mode
os.environ["DEEPSEEK_OCR_MODE"] = "tiny" # 512×512
Modo Pequeño (100 tokens)
Mejor para: Documentos digitales limpios, texto de una sola columna
Modo Base (256 tokens) - Predeterminado
Mejor para: La mayoría de los documentos estándar, facturas, cartas
Modo Grande (400 tokens)
Mejor para: Artículos académicos densos, documentos legales
Modo Gundam (Dinámico)
Mejor para: Documentos complejos de varias páginas con diseños variados
# Gundam mode combines multiple views
# - n × 640×640 local tiles for detail
# - 1 × 1024×1024 global view for structure
Eligiendo el Modo Correcto
def select_mode(document_type: str, page_count: int) -> str:
"""Selecciona el modo de resolución óptimo según las características del documento."""
if document_type == "simple_form":
return "tiny"
elif document_type == "digital_document" and page_count == 1:
return "small"
elif document_type == "academic_paper":
return "large"
elif document_type == "mixed_layout" or page_count > 1:
return "gundam"
else:
return "base" # Predeterminado
Procesando PDFs y Documentos
Convirtiendo PDFs a Imágenes
import fitz # PyMuPDF
from PIL import Image
import io
def pdf_to_images(pdf_path: str, dpi: int = 150) -> list[Image.Image]:
"""Convierte páginas PDF a Imágenes PIL."""
doc = fitz.open(pdf_path)
images = []
for page_num in range(len(doc)):
page = doc[page_num]
# Renderizar a la DPI especificada
mat = fitz.Matrix(dpi / 72, dpi / 72)
pix = page.get_pixmap(matrix=mat)
# Convertir a Imagen PIL
img_data = pix.tobytes("png")
img = Image.open(io.BytesIO(img_data))
images.append(img)
doc.close()
return images
# Uso
images = pdf_to_images("report.pdf", dpi=200)
print(f"Se extrajeron {len(images)} páginas")
Pipeline Completo de Procesamiento de PDF
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from pathlib import Path
import fitz
from PIL import Image
import io
class PDFProcessor:
def __init__(self, model_name: str = "deepseek-ai/DeepSeek-OCR-2"):
self.llm = LLM(
model=model_name,
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
)
self.sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
skip_special_tokens=False,
)
def process_pdf(self, pdf_path: str, dpi: int = 150) -> str:
"""Procesa el PDF completo y devuelve el markdown combinado."""
doc = fitz.open(pdf_path)
all_text = []
for page_num in range(len(doc)):
# Convertir página a imagen
page = doc[page_num]
mat = fitz.Matrix(dpi / 72, dpi / 72)
pix = page.get_pixmap(matrix=mat)
img = Image.open(io.BytesIO(pix.tobytes("png")))
# Realizar OCR en la página
prompt = "<image>\nFree OCR."
model_input = [{
"prompt": prompt,
"multi_modal_data": {"image": img}
}]
output = self.llm.generate(model_input, self.sampling_params)
page_text = output[0].outputs[0].text
all_text.append(f"## Page {page_num + 1}\n\n{page_text}")
doc.close()
return "\n\n---\n\n".join(all_text)
# Uso
processor = PDFProcessor()
markdown = processor.process_pdf("annual_report.pdf")
# Guardar en archivo
Path("output.md").write_text(markdown)
Rendimiento de Referencia
Benchmarks de Precisión
| Benchmark | DeepSeek-OCR 2 | GOT-OCR2.0 | MinerU2.0 |
|---|---|---|---|
| OmniDocBench | 94.2% | 91.8% | 89.5% |
| Tokens/página | 100-256 | 256 | 6.000+ |
| Fox (compresión 10×) | 97% | - | - |
| Fox (compresión 20×) | 60% | - | - |
Rendimiento de Producción
| Hardware | Páginas/Día | Páginas/Hora |
|---|---|---|
| A100-40G (único) | 200.000+ | ~8.300 |
| A100-40G × 20 | 33M+ | ~1.4M |
| RTX 4090 | ~80.000 | ~3.300 |
| RTX 3090 | ~50.000 | ~2.100 |
Precisión en el Mundo Real por Tipo de Documento
| Tipo de Documento | Precisión | Notas |
|---|---|---|
| PDFs Digitales | 98%+ | Mejor rendimiento |
| Documentos escaneados | 95%+ | Escaneos de buena calidad |
| Informes financieros | 92% | Tablas complejas |
| Notas manuscritas | 85% | Depende de la legibilidad |
| Documentos históricos | 80% | Calidad degradada |
Mejores Prácticas y Optimización
Preprocesamiento de Imagen
from PIL import Image, ImageEnhance, ImageFilter
def preprocess_document(image: Image.Image) -> Image.Image:
"""Preprocesar imagen de documento para un OCR óptimo."""
# Convertir a RGB si es necesario
if image.mode != "RGB":
image = image.convert("RGB")
# Redimensionar si es demasiado pequeña (mínimo 512px en el lado más corto)
min_dim = min(image.size)
if min_dim < 512:
scale = 512 / min_dim
new_size = (int(image.width * scale), int(image.height * scale))
image = image.resize(new_size, Image.Resampling.LANCZOS)
# Mejorar el contraste para documentos escaneados
enhancer = ImageEnhance.Contrast(image)
image = enhancer.enhance(1.2)
# Afilar ligeramente
image = image.filter(ImageFilter.SHARPEN)
return image
Ingeniería de Prompts
# Diferentes prompts para diferentes tareas
PROMPTS = {
# OCR estándar - el más rápido, bueno para la mayoría de los casos
"ocr": "<image>\nFree OCR.",
# Conversión a Markdown - mejor preservación de la estructura
"markdown": "<image>\n<|grounding|>Convert the document to markdown.",
# Extracción de tablas - optimizado para datos tabulares
"table": "<image>\nExtract all tables in markdown format.",
# Extracción de matemáticas - para documentos académicos/científicos
"math": "<image>\nExtract all text and mathematical expressions. Use LaTeX for math.",
# Campos específicos - para extracción de formularios
"fields": "<image>\nExtract the following fields: name, date, amount, signature.",
}
Optimización de Memoria
# Para memoria de GPU limitada
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
gpu_memory_utilization=0.8, # Dejar margen
max_model_len=8192, # Reducir contexto máximo
enable_chunked_prefill=True, # Mejor eficiencia de memoria
)
Estrategia de Procesamiento por Lotes
def optimal_batch_size(gpu_memory_gb: int, avg_image_size: tuple) -> int:
"""Calcula el tamaño de lote óptimo basado en la memoria de la GPU."""
# Memoria aproximada por imagen (en GB)
pixels = avg_image_size[0] * avg_image_size[1]
mem_per_image = (pixels * 4) / (1024**3) # 4 bytes por píxel
# Reservar el 60% de la memoria de la GPU para el modelo
available = gpu_memory_gb * 0.4
return max(1, int(available / mem_per_image))
# Ejemplo: A100-40G con imágenes de 1024x1024
batch_size = optimal_batch_size(40, (1024, 1024))
print(f"Tamaño de lote recomendado: {batch_size}") # ~10
Solución de Problemas Comunes
Errores de Memoria Insuficiente
Problema: CUDA out of memory
Soluciones:
# 1. Reducir tamaño de lote
sampling_params = SamplingParams(max_tokens=4096) # Reducir de 8192
# 2. Usar modo de resolución más pequeño
os.environ["DEEPSEEK_OCR_MODE"] = "small"
# 3. Habilitar optimización de memoria
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
gpu_memory_utilization=0.7,
enforce_eager=True, # Deshabilitar gráficos CUDA
)
Mala Extracción de Tablas
Problema: Las tablas están desalineadas o faltan celdas
Soluciones:
# Asegurarse de que los tokens de la lista blanca estén configurados
sampling_params = SamplingParams(
extra_args={
"whitelist_token_ids": {128821, 128822}, # Crítico para tablas
},
)
# Usar mayor resolución
os.environ["DEEPSEEK_OCR_MODE"] = "large"
Inferencia Lenta
Problema: El procesamiento tarda demasiado
Soluciones:
- Usa vLLM en lugar de Transformers (2-3 veces más rápido)
- Habilitar Flash Attention 2
- Usa procesamiento por lotes en lugar de secuencial
- Despliega en GPU con núcleos tensores (A100, H100)
Salida Distorsionada
Problema: La salida contiene disparates o caracteres repetidos
Soluciones:
# Asegurarse de que el procesador de logits esté habilitado
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
logits_processors=[NGramPerReqLogitsProcessor], # ¡Requerido!
)
# Usar temperature=0 para salida determinista
sampling_params = SamplingParams(temperature=0.0)
¿Listo para extraer texto de tus documentos? Descarga Apidog para probar las llamadas a la API de DeepSeek-OCR 2 con una interfaz visual, y luego despliega con confianza usando los patrones de producción de esta guía.