
Ejecutar modelos de lenguaje grandes como Mistral 3 en su máquina local ofrece a los desarrolladores un control sin precedentes sobre la privacidad de los datos, la velocidad de inferencia y la personalización. A medida que las cargas de trabajo de IA se vuelven más exigentes, la ejecución local se vuelve esencial para la creación de prototipos, pruebas y despliegue de aplicaciones sin conexión. Además, herramientas como Ollama simplifican este proceso, permitiéndole aprovechar las capacidades de Mistral 3 directamente desde su escritorio o servidor.
Esta guía le proporciona instrucciones paso a paso para instalar y ejecutar variantes de Mistral 3 localmente. Nos centramos en la serie de código abierto Ministral 3, que sobresale en despliegues en el borde. Al final, optimizará el rendimiento para tareas del mundo real, asegurando respuestas de baja latencia y eficiencia de recursos.
Entendiendo Mistral 3: La Potencia de Código Abierto en IA
Mistral AI continúa superando los límites con su última versión: Mistral 3. Desarrolladores e investigadores elogian esta familia de modelos por equilibrar precisión, eficiencia y accesibilidad. A diferencia de los gigantes propietarios, Mistral 3 adopta los principios de código abierto, liberándose bajo la licencia Apache 2.0. Este movimiento empodera a la comunidad para modificar, distribuir e innovar sin restricciones.
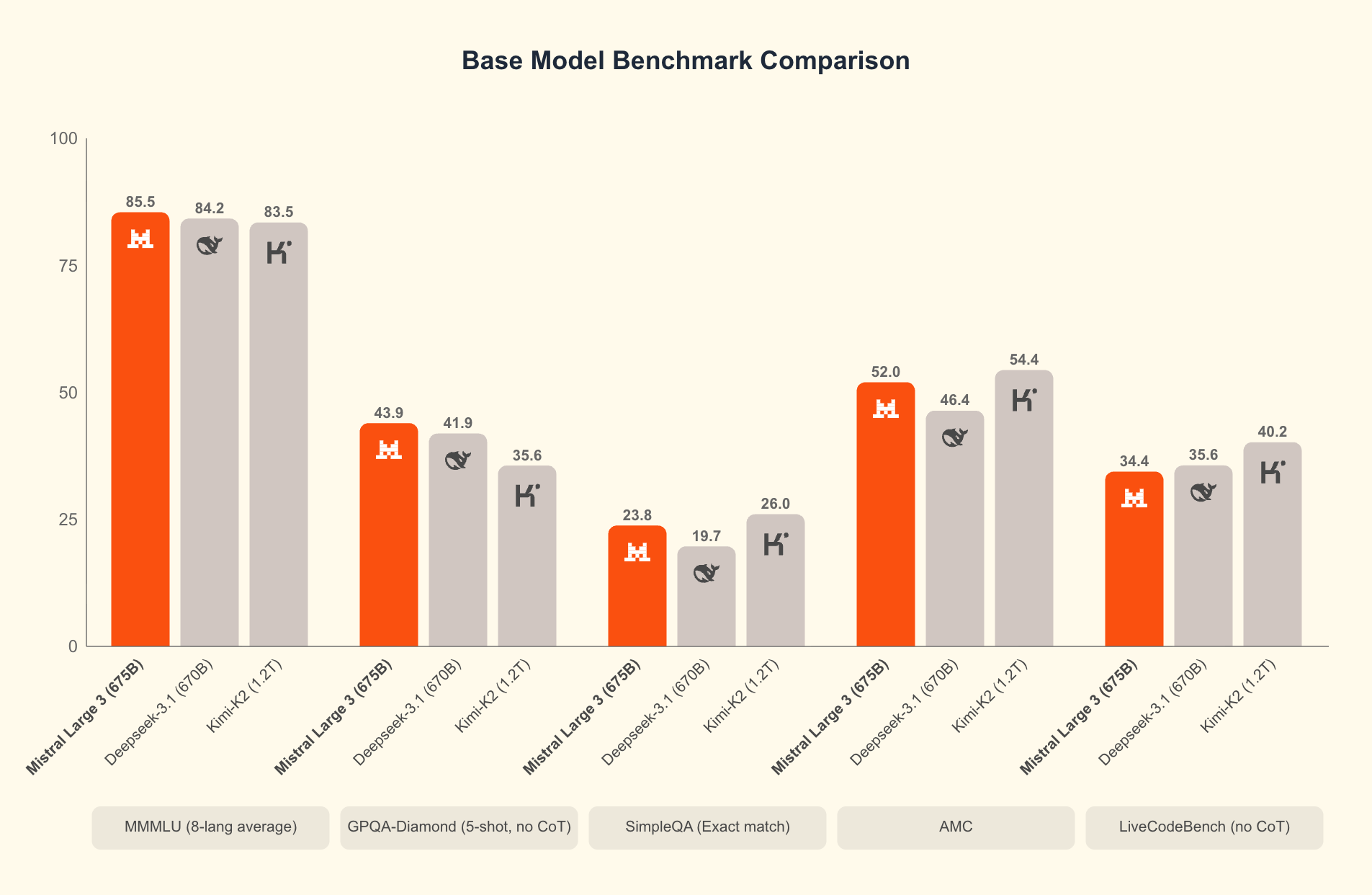
En su esencia, Mistral 3 comprende dos ramas principales: la serie compacta Ministral 3 y el expansivo Mistral Large 3. Los modelos Ministral 3, disponibles en tamaños de parámetros de 3B, 8B y 14B, están dirigidos a entornos con recursos limitados. Los ingenieros los diseñan para casos de uso locales y de borde, donde cada vatio y núcleo cuenta. Por ejemplo, la variante 3B cabe cómodamente en portátiles con GPU modestas, mientras que la 14B supera los límites en configuraciones de múltiples GPU sin sacrificar la velocidad.
Mistral Large 3, por otro lado, emplea una arquitectura dispersa de mezcla de expertos con 41B parámetros activos y 675B en total. Este diseño activa solo los expertos relevantes por consulta, reduciendo la sobrecarga computacional. Los desarrolladores acceden a versiones ajustadas para tareas como asistencia de codificación, resumen de documentos y traducción multilingüe. El modelo soporta más de 40 idiomas de forma nativa, superando a sus pares en diálogos no ingleses.
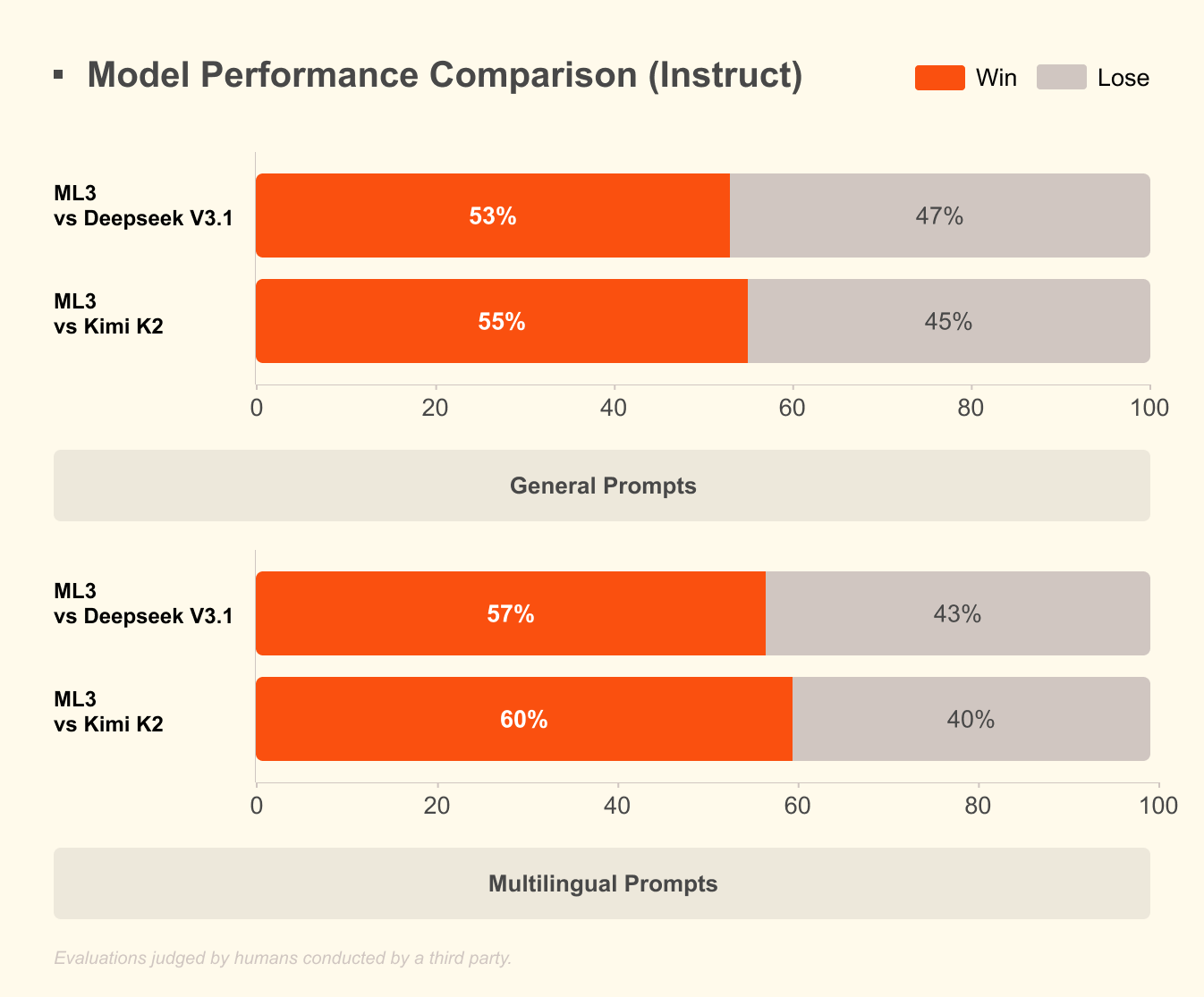
¿Qué distingue a Mistral 3? Los puntos de referencia revelan su ventaja en escenarios del mundo real. En el conjunto de datos GPQA Diamond, una prueba rigurosa de razonamiento científico, las variantes de Mistral 3 mantienen una alta precisión incluso a medida que los tokens de salida escalan. Por ejemplo, el modelo Ministral 3B Instruct mantiene alrededor del 35-40% de precisión hasta 20,000 tokens, rivalizando con modelos más grandes como Gemma 2 9B mientras utiliza menos recursos. Esta eficiencia proviene de técnicas avanzadas de cuantificación, como la compresión NVFP4, que reduce el tamaño del modelo sin degradar la calidad de la salida.
Además, Mistral 3 integra funciones multimodales, procesando imágenes junto con texto para aplicaciones en respuesta a preguntas visuales o generación de contenido. La apertura del código de estos modelos fomenta la iteración rápida; las comunidades ya los están ajustando para dominios especializados como el análisis legal o la escritura creativa. Como resultado, Mistral 3 democratiza la IA de vanguardia, permitiendo a las startups y desarrolladores individuales competir con las grandes empresas tecnológicas.

Pasando de la teoría a la práctica, ejecutar estos modelos localmente libera todo su potencial. Las APIs en la nube introducen latencia y costos, pero la inferencia local ofrece respuestas en subsegundos. A continuación, examinamos los requisitos de hardware que hacen esto factible.
Por Qué Ejecutar Mistral 3 Localmente: Beneficios para Desarrolladores y Ganancias de Eficiencia
Los desarrolladores eligen la ejecución local por varias razones convincentes. Primero, la privacidad es primordial: los datos sensibles permanecen en su máquina, evitando servidores de terceros. En industrias reguladas como la atención médica o las finanzas, esta ventaja de cumplimiento resulta invaluable. Segundo, el ahorro de costos se acumula rápidamente. La alta eficiencia de Mistral 3 significa que evita tarifas por token, ideal para pruebas de alto volumen.
Además, las ejecuciones locales aceleran la experimentación. Itere sobre prompts, ajuste hiperparámetros o encadene modelos sin demoras de red. Los puntos de referencia lo confirman: en hardware de consumo, Ministral 8B alcanza 50-60 tokens por segundo, comparable a las configuraciones en la nube pero con cero tiempo de inactividad.
La eficiencia define el atractivo de Mistral 3. Los modelos optimizan la inferencia de bajo costo, como se muestra en los resultados de GPQA Diamond, donde las variantes de Ministral superan a Gemma 3 4B y 12B en precisión sostenida. Esto es importante para tareas de contexto largo; a medida que las salidas se extienden a 20,000 tokens, la precisión disminuye mínimamente, asegurando un rendimiento confiable en chatbots o generadores de código.
Además, el acceso de código abierto a través de plataformas como Hugging Face permite una integración perfecta con herramientas como Apidog para la creación de prototipos de API. Pruebe los puntos finales de Mistral 3 localmente antes de escalar, cerrando la brecha entre el desarrollo y la producción.
Sin embargo, el éxito depende de una configuración adecuada. Con el hardware en su lugar, se procede a la instalación. Esta preparación garantiza un funcionamiento suave y maximiza el rendimiento.
Requisitos de Hardware y Software para el Despliegue Local de Mistral 3
Antes de lanzar Mistral 3, evalúe las capacidades de su sistema. Las especificaciones mínimas incluyen una CPU moderna (Intel i7 o AMD Ryzen 7) con 16 GB de RAM para el modelo 3B. Para las variantes 8B y 14B, asigne 32 GB de RAM y una GPU NVIDIA con al menos 8 GB de VRAM, piense en una RTX 3060 o superior. Los usuarios de Apple Silicon se benefician de la memoria unificada; un M1 Pro con 16 GB maneja 3B sin esfuerzo, mientras que un M3 Max sobresale en 14B.
Las demandas de almacenamiento varían: el modelo 3B ocupa ~2 GB cuantificados, escalando a ~9 GB para 14B. Use SSD para una carga más rápida. ¿Sistemas operativos? Linux (Ubuntu 22.04) ofrece el mejor rendimiento, seguido de macOS Ventura+. Windows 11 funciona a través de WSL2, aunque el paso de GPU requiere ajustes.
En cuanto al software, Python 3.10+ forma la columna vertebral. Instale CUDA 12.1 para tarjetas NVIDIA para habilitar la aceleración de GPU, esencial para latencias inferiores a 100 ms. Para ejecuciones solo de CPU, aproveche bibliotecas como ONNX Runtime.
La cuantificación juega un papel fundamental aquí. Mistral 3 admite formatos de 4 y 8 bits, reduciendo la huella de memoria en un 75% mientras conserva el 95% de precisión. Herramientas como bitsandbytes manejan esto automáticamente.
Una vez equipado, la instalación sigue un camino sencillo. Recomendamos Ollama por su simplicidad, pero existen alternativas. Esta elección agiliza el proceso, llevándonos a los pasos clave de configuración.
Instalación de Ollama: La Puerta de Entrada a la IA Local sin Esfuerzo
Ollama se destaca como la herramienta principal para ejecutar modelos de código abierto como Mistral 3 localmente. Esta plataforma ligera abstrae las complejidades, proporcionando una CLI y un servidor API en un solo paquete. Los desarrolladores aprecian su soporte multiplataforma y la detección de GPU sin configuración.
Comience descargando Ollama del sitio oficial (ollama.com). En Linux, ejecute:
curl -fsSL https://ollama.com/install.sh | sh
Este script instala binarios y configura servicios. Verifique con ollama --version; espere una salida como "ollama version 0.3.0". Para macOS, el instalador DMG maneja las dependencias, incluyendo Rosetta para la emulación Intel en ARM.
Los usuarios de Windows obtienen el EXE de los lanzamientos de GitHub. Después de la instalación, inicie a través de PowerShell: ollama serve. Ollama se ejecuta como un demonio en segundo plano, exponiendo una API REST en el puerto 11434.
¿Por qué Ollama? Extrae modelos de su registro, incluyendo Ministral 3, con cuantificación incorporada. No se necesita clonación manual de Hugging Face. Además, soporta Modelfiles para ajuste fino personalizado, alineándose con el ethos de código abierto de Mistral 3.
Con Ollama listo, lo siguiente es extraer y ejecutar modelos. Este paso transforma su configuración en una estación de trabajo de IA funcional.
Extracción y Ejecución de Modelos Ministral 3 con Ollama
La biblioteca de Ollama aloja variantes de Ministral 3.
Comience listando las etiquetas disponibles:
ollama list
Para descargar el modelo 3B:
ollama pull ministral:3b-instruct-q4_0
Este comando descarga ~2 GB, verificando la integridad mediante hashes. Las barras de progreso rastrean la descarga, que normalmente se completa en minutos con banda ancha.
Inicie una sesión interactiva:
ollama run ministral-3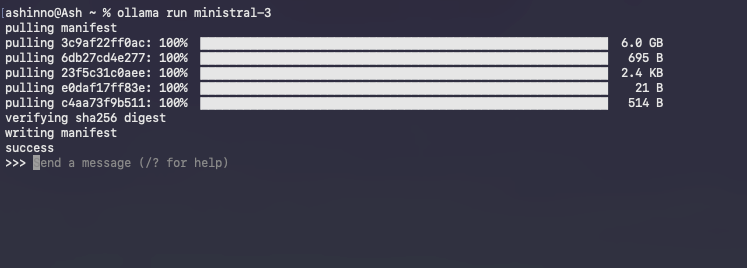
Ollama carga el modelo en la memoria, calentando las cachés para consultas posteriores. Escriba las indicaciones directamente; por ejemplo:
>> Explica el entrelazamiento cuántico en términos sencillos.

El modelo responde en tiempo real, aprovechando el ajuste de instrucciones para obtener resultados coherentes. Salga con /bye.
¿Solución de problemas comunes? Si la GPU se subutiliza, establezca la variable de entorno OLLAMA_NUM_GPU=999. Para errores de OOM, baje a una cuantificación menor como q3_K_M.
Más allá de lo básico, la API de Ollama permite el acceso programático. Realice una solicitud de compleción con Curl:
curl http://localhost:11434/api/generate -d '{
"model": "ministral:3b-instruct-q4_0",
"prompt": "Write a Python function to sort a list.",
"stream": false
}'
Esta respuesta JSON incluye texto generado, perfecta para integrar con Apidog durante el desarrollo de API.
Ejecutar modelos es el comienzo; la optimización eleva el rendimiento. En consecuencia, pasamos a técnicas que exprimen cada gota de eficiencia de su hardware.
Optimizando la Inferencia de Mistral 3: Compromisos de Velocidad, Memoria y Precisión
La eficiencia define el éxito de la IA local. El diseño de Mistral 3 brilla aquí, pero los ajustes amplifican las ganancias. Comience con la cuantificación: Ollama por defecto usa Q4_0, equilibrando tamaño y fidelidad. Para recursos ultrabajos, pruebe Q2_K, reduciendo la memoria a la mitad con un costo de perplejidad del 10%.
La orquestación de la GPU importa. Habilite la atención flash a través de OLLAMA_FLASH_ATTENTION=1 para aceleraciones de 2x en contextos largos. Mistral 3 soporta hasta 128K tokens; pruebe con prompts tipo GPQA para verificar la precisión sostenida.
El procesamiento por lotes aumenta el rendimiento. Use /api/generate de Ollama con múltiples prompts en paralelo, aprovechando los clientes Python asíncronos. Por ejemplo, escriba un script de bucle:
import requests
import json
model = "ministral:8b-instruct-q4_0"
url = "http://localhost:11434/api/generate"
prompts = ["Prompt 1", "Prompt 2"]
for p in prompts:
response = requests.post(url, json={"model": model, "prompt": p})
print(json.loads(response.text)["response"])
Esto maneja más de 10 consultas por segundo en configuraciones multinúcleo.
La gestión de la memoria evita los intercambios. Monitoree con nvidia-smi; descargue capas a la CPU si la VRAM se agota. Bibliotecas como vLLM se integran con Ollama para el procesamiento continuo por lotes, manteniendo 100 tokens/segundo en A100s.
¿Ajuste de precisión? Afine con adaptadores LoRA en datos de dominio. La biblioteca PEFT de Hugging Face los aplica a Ministral 3, requiriendo ~1GB de espacio extra. Después del ajuste fino, exporte al formato Ollama mediante ollama create.
Compare su configuración con GPQA Diamond. Evalúe con scripts para trazar la precisión frente a los tokens, reflejando los gráficos de Mistral. Las variantes de alta eficiencia como Ministral 8B mantienen puntuaciones del 50%+, lo que subraya su ventaja sobre Qwen 2.5 VL.
Estas optimizaciones le preparan para aplicaciones avanzadas. Por lo tanto, exploramos integraciones que amplían el alcance de Mistral 3.
Integrando Mistral 3 con Herramientas de Desarrollo: APIs y Más Allá
Mistral 3 local prospera en ecosistemas. Combínelo con Apidog para simular APIs impulsadas por IA. Diseñe puntos finales que consulten a Ollama, pruebe cargas útiles y valide respuestas, todo sin conexión.
Por ejemplo, cree una ruta POST /generate en Apidog, reenviando a la API de Ollama. Importe colecciones para plantillas de prompts, asegurando que Mistral 3 maneje las solicitudes multilingües sin problemas.
Los usuarios de LangChain encadenan Mistral 3 con herramientas:
from langchain_ollama import OllamaLLM
from langchain_core.prompts import PromptTemplate
llm = OllamaLLM(model="ministral:3b-instruct-q4_0")
prompt = PromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello world"}))
Esta configuración procesa 50 consultas/minuto, ideal para pipelines RAG.
Los paneles de Streamlit visualizan las salidas. Inserte llamadas a Ollama en aplicaciones para chats interactivos, aprovechando el razonamiento de Mistral 3 para preguntas y respuestas dinámicas.
¿Consideraciones de seguridad? Ejecute Ollama detrás de proxies NGINX, limitando la velocidad de los puntos finales. Para producción, contenga con Docker:
FROM ollama/ollama
COPY Modelfile .
RUN ollama create mistral-local -f Modelfile
Esto aísla los entornos, escalando a Kubernetes.
A medida que las aplicaciones evolucionan, el monitoreo se vuelve clave. Herramientas como Prometheus rastrean la latencia, alertando sobre desviaciones de la eficiencia de referencia.
En resumen, estas integraciones transforman Mistral 3 de un modelo independiente en un motor versátil. Sin embargo, surgen desafíos; abordarlos garantiza implementaciones robustas.
Resolución de Problemas Comunes en Ejecuciones Locales de Mistral 3
Incluso las configuraciones optimizadas encuentran obstáculos. Las discrepancias de CUDA encabezan la lista: verifique las versiones con nvcc --version. Reduzca la versión si surgen conflictos, ya que Mistral 3 tolera 11.8+.
¿Falla la carga del modelo? Borre la caché de Ollama: ollama rm ministral:3b-instruct-q4_0 y luego vuelva a extraer. Las descargas corruptas provienen de las redes; use --insecure con moderación.
En macOS, la aceleración de Metal es más lenta que CUDA. Fuerza la CPU para mayor estabilidad: OLLAMA_METAL=0. Los usuarios de Windows WSL habilitan los controladores NVIDIA a través de wsl --update.
El sobrecalentamiento afecta a los portátiles; regule con nvidia-smi -pl 100 para limitar la potencia. Para caídas de precisión, inspeccione las indicaciones: Ministral 3 sobresale en formatos de instrucción.
Los foros de la comunidad en Reddit y Hugging Face resuelven el 90% de los casos extremos. Registre errores con OLLAMA_DEBUG=1 para diagnósticos.
Una vez superados los problemas, Mistral 3 ofrece un valor constante. Finalmente, reflexionamos sobre su impacto más amplio.
Conclusión: Aproveche Mistral 3 Localmente para las Innovaciones de IA del Mañana
Mistral 3 redefine la IA de código abierto con su combinación de potencia y practicidad. Al ejecutarlo localmente a través de Ollama, los desarrolladores obtienen velocidad, privacidad y control de costos inalcanzables en otros lugares. Desde la extracción de modelos hasta las integraciones de ajuste fino, esta guía le proporciona pasos accionables.
Experimente audazmente: comience con la variante 3B, escale a 14B y mida contra los puntos de referencia. A medida que Mistral AI itera, las ejecuciones locales lo mantienen a la vanguardia.
¿Listo para construir? Descargue Apidog gratis y prototipe APIs impulsadas por su configuración de Mistral 3. El futuro de la IA eficiente comienza en su máquina, hágalo valer.