Los desarrolladores buscan constantemente modelos de lenguaje eficientes y de alto rendimiento para construir aplicaciones inteligentes. La API de MiniMax M2.1 se destaca como una opción robusta, particularmente para flujos de trabajo agénticos y tareas de codificación complejas.
Se empieza por entender el modelo en sí. A continuación, se exploran los métodos de acceso. Finalmente, se implementan integraciones prácticas.
¿Qué es MiniMax M2.1 y por qué usar su API?
MiniMax M2.1 representa el último avance de MiniMax AI, lanzado como un modelo de código abierto optimizado para capacidades agénticas. Los desarrolladores lo aprovechan para crear aplicaciones autónomas que manejan el desarrollo de software multilingüe, la planificación de múltiples pasos y el uso de herramientas con una robustez excepcional.
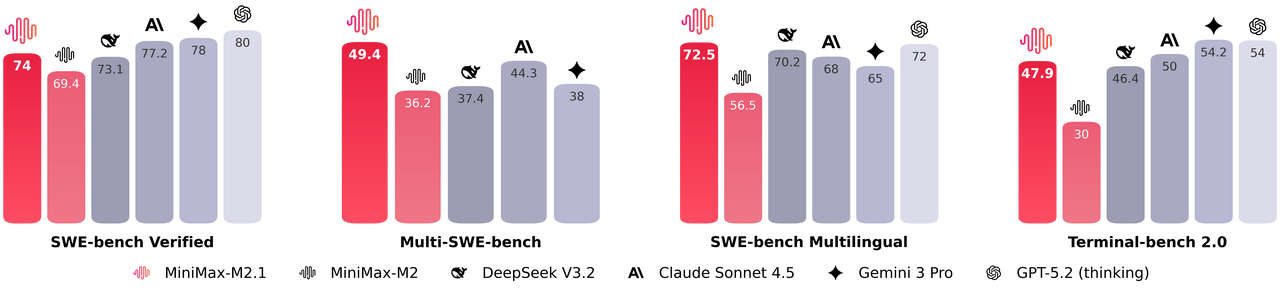
Además, MiniMax M2.1 activa un conjunto compacto de parámetros durante la inferencia, ofreciendo un rendimiento casi de vanguardia mientras mantiene una baja latencia. Destaca en benchmarks como SWE-bench Verified y VIBE, a menudo igualando o superando a los modelos propietarios en estabilidad de codificación y seguimiento de instrucciones. Adicionalmente, el modelo soporta demostraciones avanzadas, incluyendo la generación de animaciones 3D interactivas, aplicaciones móviles nativas y paneles de datos en tiempo real.
Usted elige MiniMax M2.1 cuando necesita transparencia y control. Además, sus pesos de código abierto permiten la implementación local a través de Hugging Face, pero la API alojada ofrece acceso inmediato sin gestión de infraestructura.
MiniMax M2.1 vs GLM-4.7: ¿Qué modelo se adapta a sus necesidades?
Los desarrolladores comparan frecuentemente MiniMax M2.1 con GLM-4.7, otro contendiente líder de código abierto de Z.ai. Ambos modelos están orientados a la codificación y el razonamiento, sin embargo, difieren en arquitectura, eficiencia y costo.
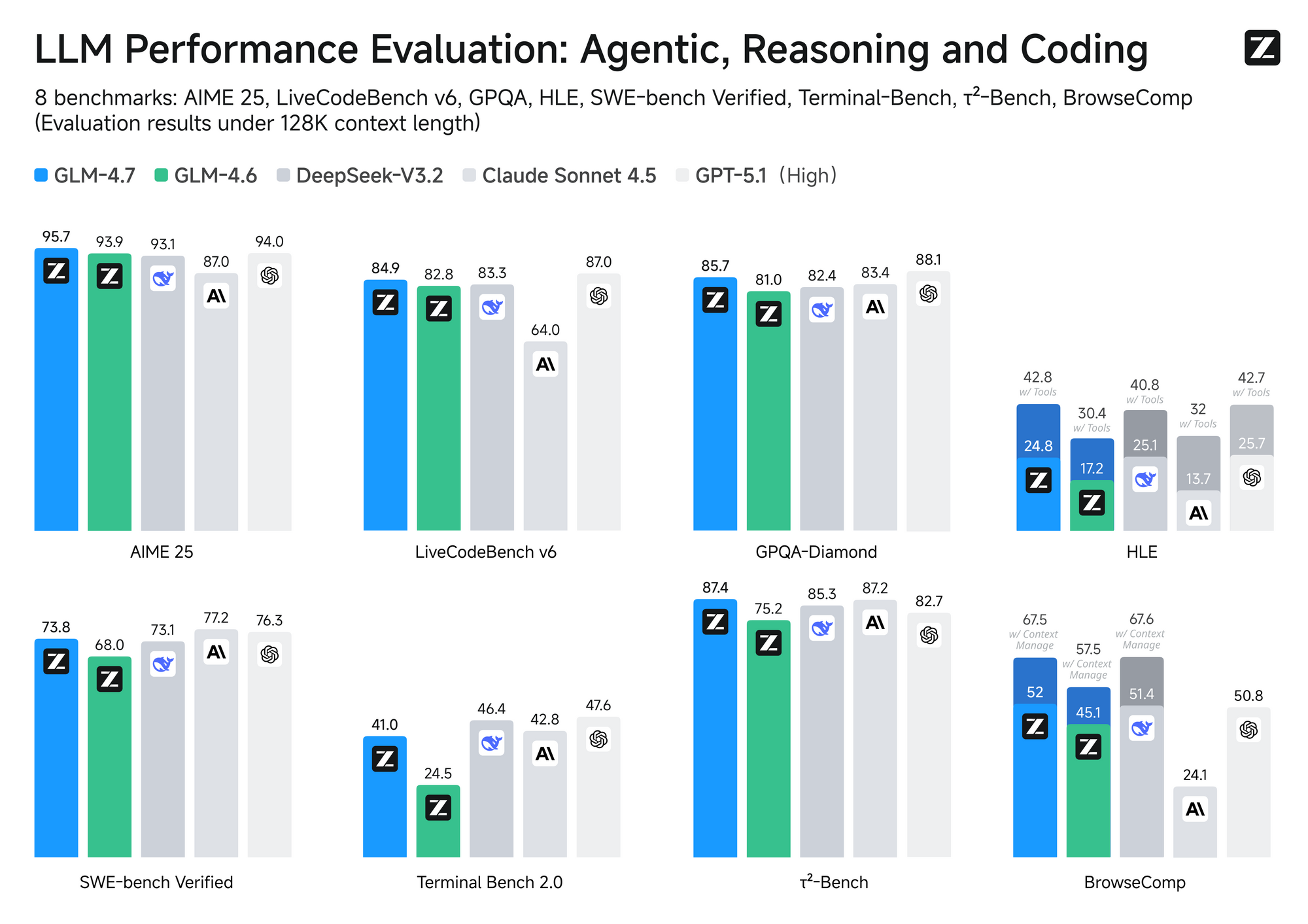
MiniMax M2.1 emplea un diseño de Mezcla de Expertos (MoE) con activación selectiva —típicamente alrededor de 10B de parámetros activos de un conjunto mayor. Este enfoque asegura una inferencia rápida y menores costos operativos. En contraste, GLM-4.7 utiliza un MoE completo con 358B de parámetros, soportando una ventana de contexto masiva de 200K tokens y características nativas como el control de pensamiento a nivel de turno.
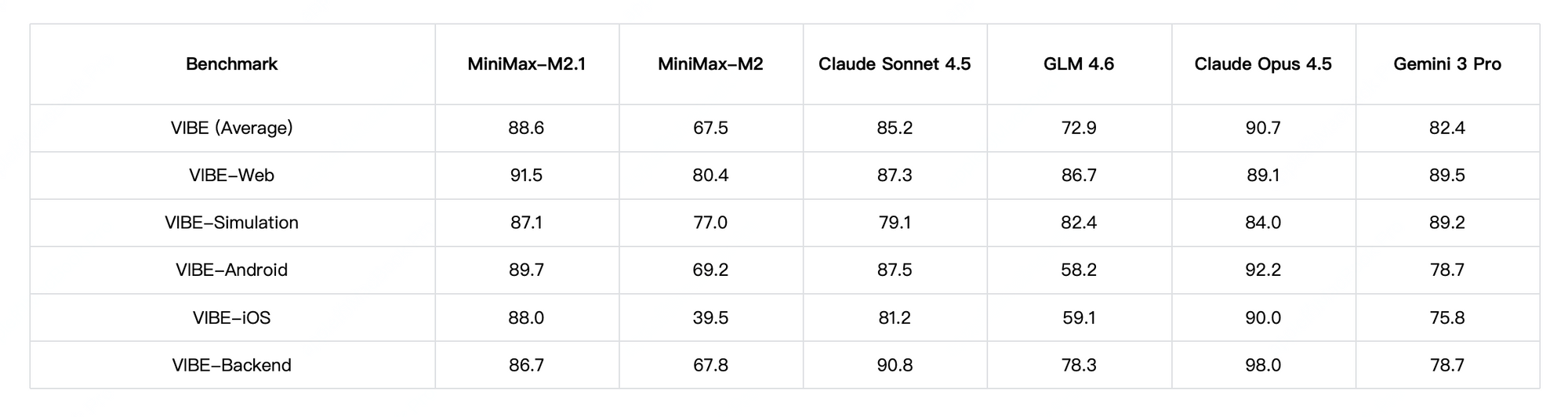
En cuanto al rendimiento, MiniMax M2.1 destaca en tareas agénticas y planificación a largo plazo, logrando altas puntuaciones en VIBE (88.6 de media) y demostrando una estabilidad superior en el uso de herramientas. Las pruebas de la comunidad muestran que supera a versiones anteriores de GLM en codificación creativa y autonomía multitarea. Sin embargo, GLM-4.7 aventaja en benchmarks de razonamiento puro y salidas estructuradas, con resultados sólidos en SWE-bench (73.8%).
El precio juega un papel clave. Los modelos MiniMax, incluyendo predecesores como M2, típicamente cobran alrededor de $0.30–$0.315 por millón de tokens de entrada y $1.20–$1.26 por millón de tokens de salida en la plataforma oficial. GLM-4.7, disponible a través de Z.ai o proveedores como OpenRouter, comienza en aproximadamente $0.44–$0.60 de entrada y $1.74–$2.20 de salida por millón de tokens —a menudo más, aunque las suscripciones reducen las tarifas efectivas.
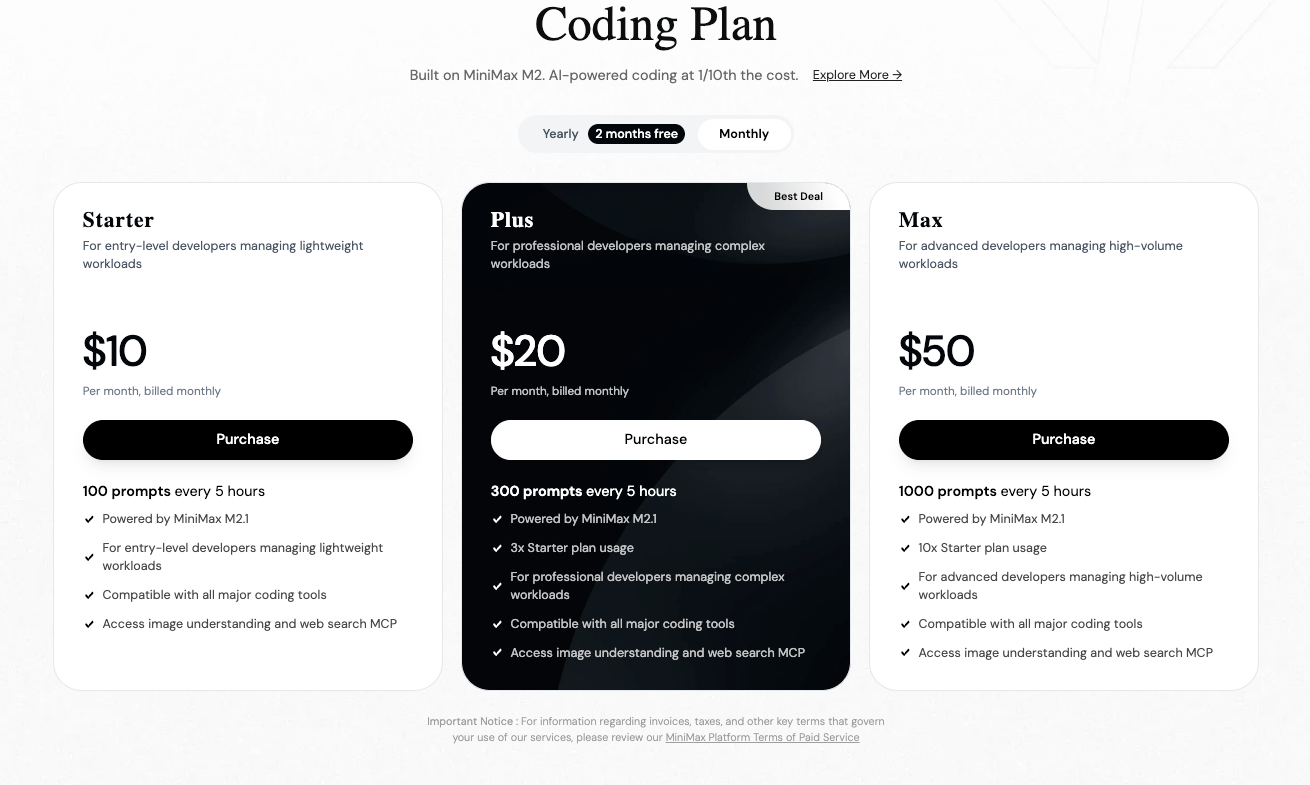
En consecuencia, usted selecciona MiniMax M2.1 para aplicaciones agénticas de alta velocidad y rentables. Alternativamente, opta por GLM-4.7 cuando el contexto extendido o los modos de pensamiento precisos resultan esenciales.
¿Cómo se registra en la plataforma API de MiniMax?
Usted comienza el acceso creando una cuenta en la Plataforma Abierta de MiniMax. Regístrese usando su correo electrónico o método preferido.
Después de la verificación, inicie sesión y acceda al panel de control. Aquí, gestiona las claves API y la facturación. La plataforma admite puntos finales tanto globales como específicos de la región, por lo que usted elige en función de su ubicación para una latencia óptima.
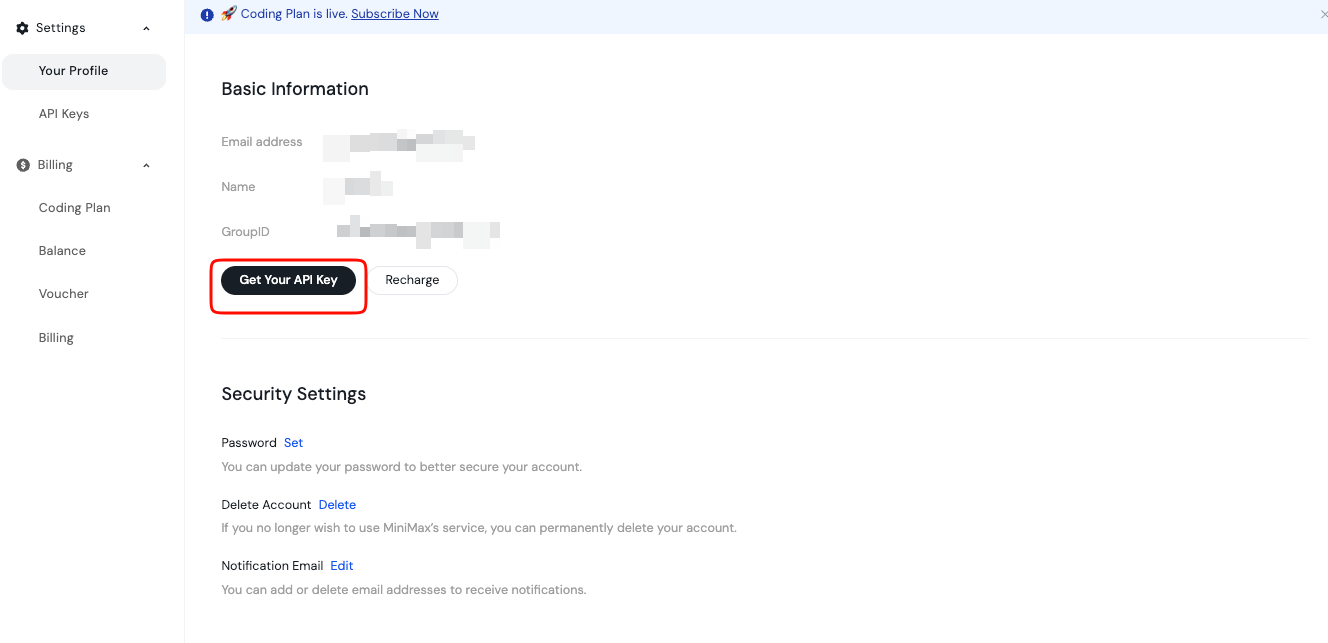
Además, revise las secciones de documentación con antelación. Cubren la disponibilidad del modelo, los límites de tarifas y las mejores prácticas. Guarde esta clave de forma segura, quizás en una variable de entorno o en un gestor de secretos. Nunca la exponga en el código del lado del cliente.
Además, recargue su saldo si es necesario a través de la página de Facturación. MiniMax opera con un modelo de pago por uso, lo que le permite controlar los costos con precisión.
¿Cuál es el punto final y la estructura de solicitud de la API de MiniMax M2.1?
La API de MiniMax ofrece compatibilidad con formatos populares, incluyendo los estilos de OpenAI y Anthropic. Para la generación de texto con M2.1, se dirige al punto final de completions de chat.
Normalmente, la URL base aparece como https://api.minimax.io o una variante regional. Usted especifica el nombre del modelo, como "MiniMax-M2.1", en su carga útil de solicitud.
Una solicitud POST estándar incluye encabezados para autorización y tipo de contenido. Usted establece Authorization: Bearer YOUR_API_KEY y Content-Type: application/json.
El cuerpo sigue un formato de array de mensajes, similar a otros LLMs. Usted incluye los roles de sistema, usuario y asistente según sea necesario.
Además, usted ajusta parámetros como temperatura, max_tokens, top_p y tool choices para afinar las salidas.
¿Cómo envía su primera solicitud a la API de MiniMax M2.1?
Usted prueba la API rápidamente usando curl para la verificación.
Aquí tiene un ejemplo básico:
curl https://api.minimax.io/v1/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "MiniMax-M2.1",
"messages": [
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to calculate Fibonacci numbers."}
],
"temperature": 0.7,
"max_tokens": 512
}'
Este comando devuelve una respuesta JSON con la completación generada. Usted inspecciona el array choices para la respuesta del asistente.
Además, usted habilita el streaming para salidas en tiempo real añadiendo "stream": true.
¿Cómo puede usar Python para interactuar con la API de MiniMax M2.1?
Los desarrolladores de Python prefieren las bibliotecas por su simplicidad. Aunque MiniMax proporciona compatibilidad, usted utiliza el SDK oficial de OpenAI con una URL base personalizada.
Primero, instale el paquete:
pip install openai
Luego, configure el cliente:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.minimax.io/v1" # Adjust if needed
)
response = client.chat.completions.create(
model="MiniMax-M2.1",
messages=[
{"role": "system", "content": "You are an expert developer."},
{"role": "user", "content": "Explain agentic workflows."}
],
temperature=0.8
)
print(response.choices[0].message.content)
Este código maneja las solicitudes de manera eficiente. Usted lo extiende con manejo de errores y reintentos para uso en producción.
¿Por qué usar Apidog para probar y gestionar las llamadas a la API de MiniMax M2.1?
Probar APIs manualmente se vuelve tedioso a medida que los proyectos crecen. Apidog simplifica este proceso significativamente.
Usted importa la documentación de MiniMax o crea colecciones manualmente en Apidog. Luego, establece variables de entorno para su clave API.
Apidog soporta el envío de solicitudes, la visualización de respuestas formateadas y la simulación de puntos finales. Además, genera código cliente en múltiples lenguajes automáticamente.
Por ejemplo, usted depura el uso de tokens o las respuestas de streaming visualmente. Esto ahorra horas en comparación con los comandos curl puros.
Además, Apidog se integra con pipelines de CI/CD, asegurando un comportamiento consistente de la API.
¿Cómo maneja la llamada a herramientas y las características avanzadas en MiniMax M2.1?
MiniMax M2.1 soporta la llamada nativa a herramientas, crucial para aplicaciones agénticas. Usted define las herramientas en la carga útil de la solicitud.
El modelo decide cuándo invocarlas, devolviendo llamadas estructuradas. Su aplicación ejecuta las herramientas y añade los resultados como mensajes del asistente.
Este bucle permite el razonamiento multi-paso. Además, usted aprovecha el pensamiento intercalado para rastros de razonamiento transparentes.
¿Cuáles son las mejores prácticas para límites de tarifas y manejo de errores?
MiniMax impone límites de tarifa para mantener la calidad del servicio. Usted monitorea encabezados como x-ratelimit-remaining en las respuestas.
Implemente retroceso exponencial para reintentos en errores 429. Además, usted captura fallos de autenticación (401) y solicitudes inválidas (400).
El registro de solicitudes y respuestas ayuda a la depuración. Usted rastrea el uso a través del panel de control para evitar sorpresas.
Conclusión: Empiece a construir con MiniMax M2.1 hoy mismo
Ahora posee el conocimiento para acceder y utilizar la API de MiniMax M2.1 de manera efectiva. Regístrese en la plataforma, genere su clave y envíe solicitudes —ya sea a través de curl, Python o Apidog.
Este modelo le permite construir agentes sofisticados y herramientas de codificación a costos competitivos. Experimente libremente, compare con alternativas como GLM-4.7 y escale sus proyectos.
Apidog mejora aún más su flujo de trabajo al proporcionar potentes herramientas de prueba. Descárguelo gratis y acelere su desarrollo.