
Los desarrolladores buscan formas eficientes de integrar modelos de lenguaje avanzados en sus aplicaciones. INTELLECT-3 surge como una opción atractiva debido a su base de código abierto y su sólido rendimiento en tareas de razonamiento. Este modelo, desarrollado por Prime Intellect, se destaca por su arquitectura de Mezcla de Expertos (MoE) de 106 mil millones de parámetros, que permite una alta eficiencia en el manejo de cálculos complejos.
Comprendiendo INTELLECT-3: La Potencia de Código Abierto
Prime Intellect lanza INTELLECT-3 como un modelo completamente de código abierto, lo que permite a investigadores y desarrolladores personalizar y extender sus capacidades sin barreras propietarias. Esta transparencia fomenta la innovación en áreas como el aprendizaje por refuerzo (RL) y los sistemas de IA agenciales. Puede acceder al paquete completo, que incluye pesos del modelo, frameworks de entrenamiento, conjuntos de datos, entornos de RL y herramientas de evaluación, directamente desde los repositorios de Prime Intellect.

En su núcleo, INTELLECT-3 emplea una arquitectura MoE de 106 mil millones de parámetros, construida sobre el modelo base GLM-4.5-Air. Los diseños MoE dirigen las entradas a subredes "expertas" especializadas, lo que optimiza el uso de computación y acelera la inferencia. Por ejemplo, durante el procesamiento, el modelo activa solo un subconjunto de parámetros relevantes para la consulta, reduciendo la latencia mientras mantiene la precisión. Esta configuración resulta particularmente efectiva para tareas que requieren experiencia selectiva, como derivaciones matemáticas o generación de código.
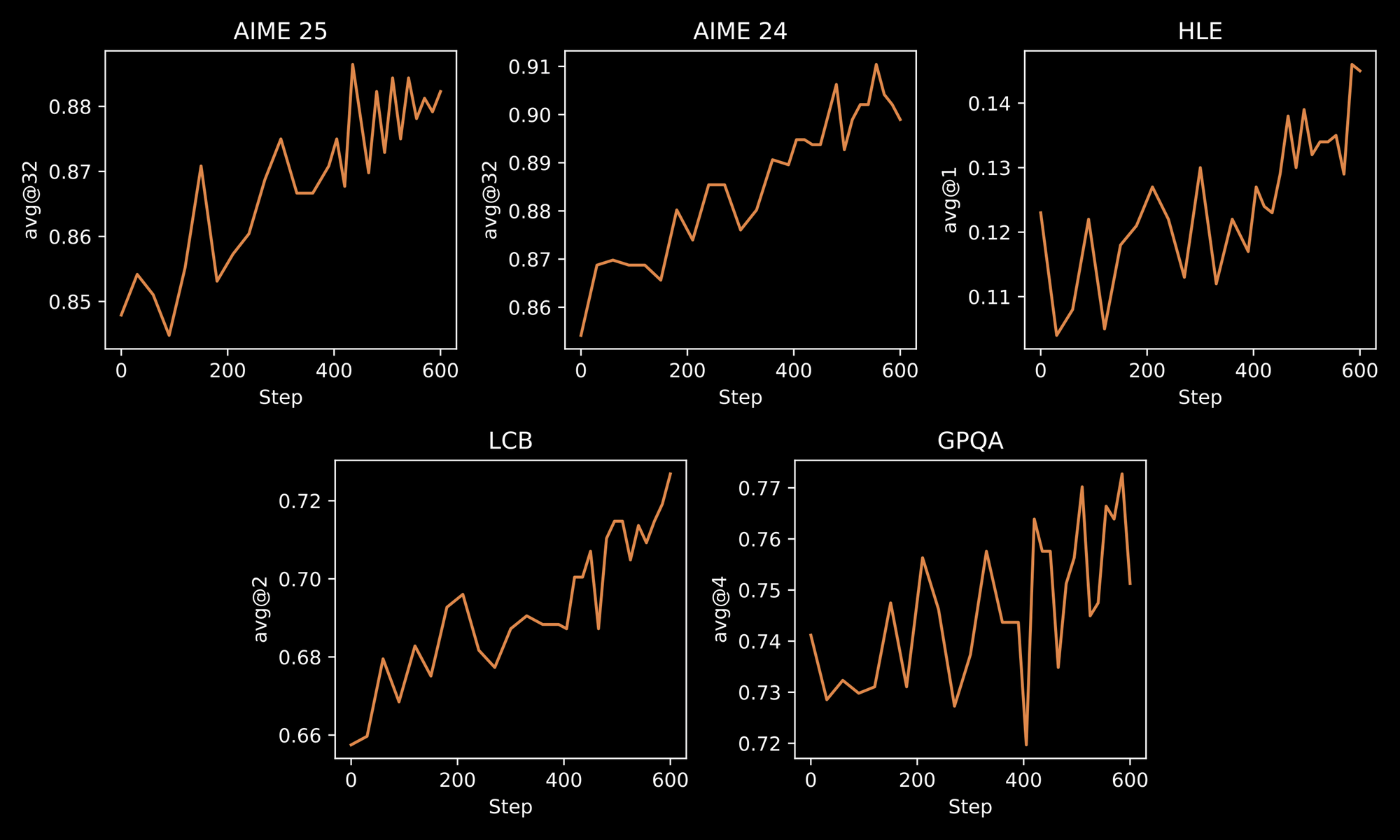
El proceso de entrenamiento subraya la robustez de INTELLECT-3. Los ingenieros aplican una metodología de dos etapas: un Ajuste Fino Supervisado (SFT) inicial en conjuntos de datos curados, seguido de un RL a gran escala utilizando el framework personalizado prime-rl. prime-rl opera como un sistema RL asíncrono fuera de política, que maneja simulaciones paralelas vastas de manera eficiente. Usted se beneficia de esto a través de comportamientos mejorados del modelo en entornos dinámicos, como la resolución iterativa de problemas o la planificación en múltiples pasos.
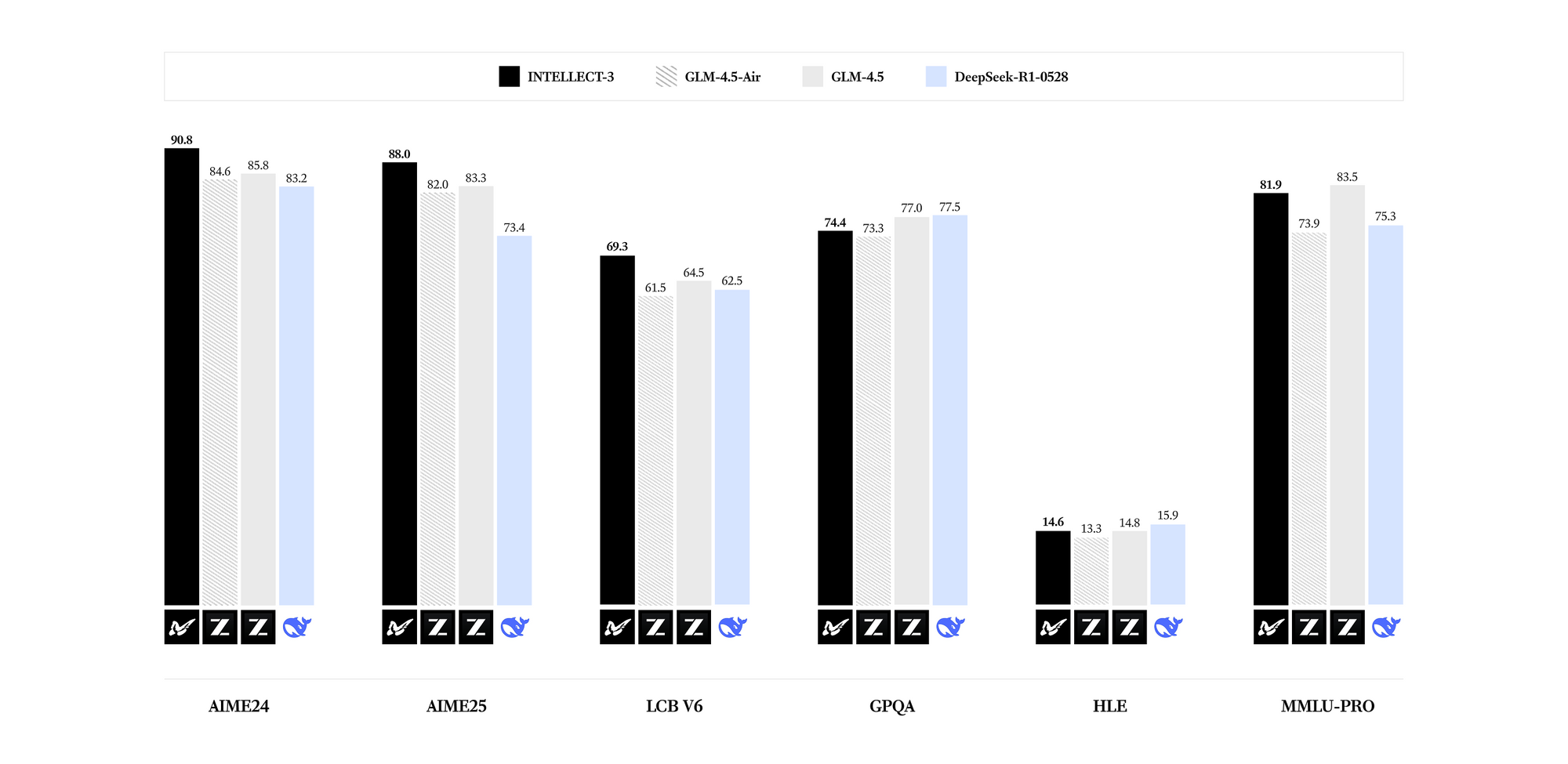
INTELLECT-3 sobresale en dominios especializados. Los benchmarks revelan resultados de vanguardia para su conteo de parámetros en matemáticas (ej., puntajes GSM8K que superan el 95%), codificación (tasas de aprobación HumanEval superiores al 85%), ciencia (precisión GPQA superior al 60%) y razonamiento (puntajes MMLU cercanos al 80%). Comparado con modelos más densos como Llama 3.1 70B, INTELLECT-3 logra una eficiencia superior —hasta 2 veces más rápido en inferencia en hardware equivalente— debido a sus patrones de activación dispersos. En consecuencia, puede implementarlo en entornos con recursos limitados sin sacrificar la calidad de la salida.
La infraestructura de soporte mejora su atractivo de código abierto. El Centro de Verificadores y Entornos ofrece más de 500 entornos de RL, desde rompecabezas simples hasta demostradores de teoremas avanzados.
Prime Sandboxes ofrecen una ejecución de código segura y de alto rendimiento, que aísla las acciones del agente durante el entrenamiento o la inferencia. Los desarrolladores aprovechan estas herramientas para ajustar INTELLECT-3 para aplicaciones personalizadas, como agentes autónomos en pipelines de desarrollo de software.
En la práctica, puede descargar los pesos del modelo a través de Hugging Face o el GitHub de Prime Intellect. La instalación requiere dependencias estándar como PyTorch y la biblioteca Transformers. Un script básico para cargar el modelo se ve así:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "prime-intellect/intellect-3" # Placeholder for official repo
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
inputs = tokenizer("Solve this equation: x^2 + 3x - 4 = 0", return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0]))
Este código inicializa el modelo en hardware con GPU. Sin embargo, para un uso a escala de producción, se pasa a APIs alojadas, ya que el autoalojamiento exige una computación significativa (por ejemplo, múltiples GPU A100). Así, el acceso de código abierto sienta las bases, pero la integración de la API escala sus implementaciones de manera efectiva.
Pasando de la experimentación local, ahora explorará cómo acceder a INTELLECT-3 a través de servicios gestionados. Este cambio garantiza la fiabilidad y maneja las complejidades de la inferencia distribuida.
Accediendo a la API de INTELLECT-3: Configuración y Autenticación
Opción 1 – Punto de Acceso Nativo de Prime Intellect (Recomendado para máximo rendimiento y menor latencia)
Comienza el acceso a la API obteniendo credenciales de la plataforma de Prime Intellect. Visite el panel de Prime Intellect en app.primeintellect.ai y cree una cuenta si es necesario.
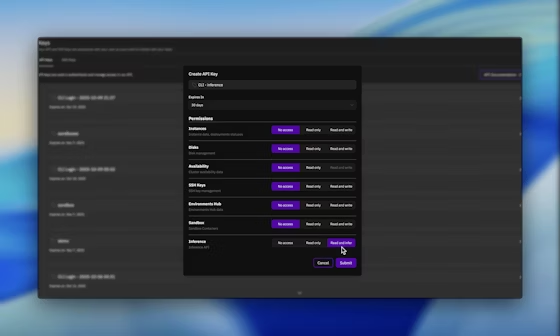
Una vez iniciada la sesión, navegue hasta la sección de claves API y genere una nueva clave con permisos de Inferencia habilitados. Esta clave autentica todas las solicitudes posteriores, asegurando un acceso seguro a INTELLECT-3.
A continuación, configure su entorno. Establezca la clave API como una variable de entorno para una integración sin problemas:
export PRIME_API_KEY="your-api-key-here"
Para flujos de trabajo basados en equipos, incluya el encabezado X-Prime-Team-ID en las solicitudes. Este identificador dirige el uso al grupo de facturación correcto, evitando cargos entre cuentas. Puede recuperar el ID del equipo desde el panel de control en la configuración de la cuenta.
La API adopta una interfaz compatible con OpenAI, lo que simplifica la adopción si ya utiliza bibliotecas como openai-python. Especifique la URL base como https://api.pinference.ai/api/v1. Este endpoint proxy envía las solicitudes a proveedores de inferencia optimizados, incluyendo Parasail y Nebius, que alojan instancias de INTELLECT-3. Como resultado, logra respuestas de baja latencia sin gestionar clústeres subyacentes.
Para verificar el acceso, consulte el endpoint de modelos. Esto lista los modelos disponibles, confirmando la presencia de INTELLECT-3 (típicamente bajo un identificador como prime-intellect/intellect-3). Utilice la herramienta CLI para verificaciones rápidas:
prime inference models
Alternativamente, envíe una solicitud GET a través de curl:
curl -H "Authorization: Bearer $PRIME_API_KEY" \
https://api.pinference.ai/api/v1/models
La respuesta devuelve un array JSON de objetos de modelo, cada uno detallando parámetros como id, max_tokens y context_window. INTELLECT-3 soporta un contexto de 128K tokens, lo que permite cadenas de razonamiento de formato largo.
La autenticación se extiende a la limitación de tasas y cuotas. Prime Intellect aplica límites por minuto y diarios basados en su plan, visibles en el panel de control. Puede monitorear el uso a través de la pestaña de Facturación, que registra los tokens procesados y las llamadas API realizadas. Si los límites restringen su flujo de trabajo, actualice sin problemas a través de la plataforma.
Además, integre con Apidog para pruebas mejoradas. Importe el esquema de OpenAI en Apidog, luego simule solicitudes a los puntos finales de INTELLECT-3. Esta práctica identifica problemas temprano, como cargas JSON mal formadas. La versión gratuita de Apidog es suficiente para las configuraciones iniciales, uniendo el desarrollo local con las APIs de producción.
Con la autenticación en su lugar, procede a elaborar solicitudes. La siguiente sección describe formatos precisos para obtener respuestas óptimas de INTELLECT-3.
Opción 2 – OpenRouter (Acceso instantáneo y créditos unificados)
Además del autoalojamiento o el uso de la plataforma de inferencia nativa de Prime Intellect, INTELLECT-3 también está oficialmente disponible en OpenRouter. Esto le proporciona una puerta de enlace alternativa con facturación unificada, enrutamiento de respaldo automático y acceso instantáneo, sin necesidad de una cuenta de Prime Intellect separada si ya utiliza OpenRouter.
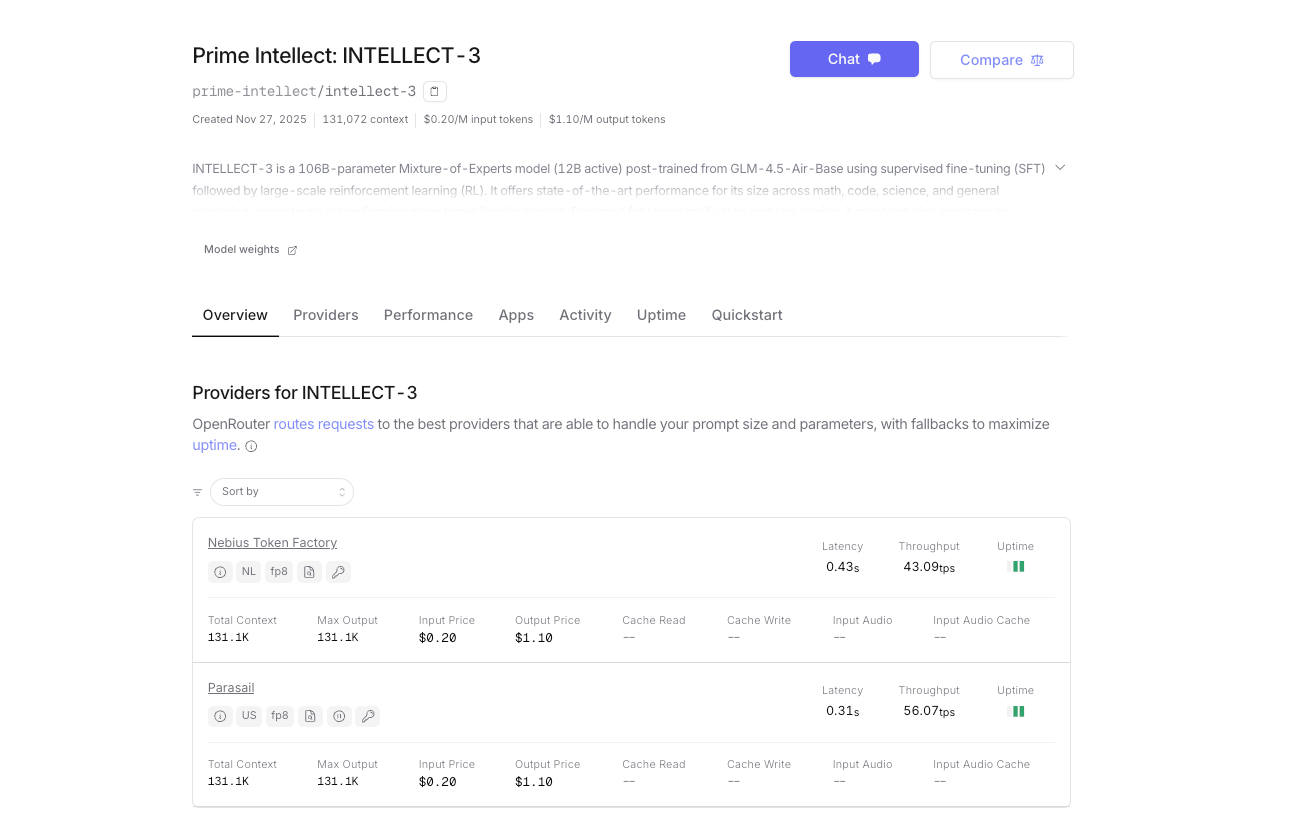
- URL base: https://openrouter.ai/api/v1
- Nombre del modelo: prime-intellect/intellect-3
- Autenticación: Su clave API de OpenRouter (OPENROUTER_API_KEY)
- Enrutamiento automático del proveedor (actualmente servido por los clústeres de Prime Intellect)
- Pago por uso con créditos de OpenRouter; costo por token ligeramente más alto debido a la tarifa de la plataforma
Ambos endpoints soportan esquemas idénticos de solicitud/respuesta, streaming, llamada a herramientas y modo JSON.
Realizando Solicitudes a la API de INTELLECT-3: Formatos y Ejemplos
Usted inicia las interacciones a través del endpoint /chat/completions, que maneja prompts conversacionales y orientados a tareas. Construya las solicitudes como objetos JSON con campos para model, messages, temperature y max_tokens. El array messages imita historiales de chat, usando roles como "system", "user" y "assistant".
Considere un ejemplo básico para la generación de código. Usted envía:
import openai
import os
client = openai.OpenAI(
api_key=os.environ.get("PRIME_API_KEY"),
base_url="https://api.pinference.ai/api/v1"
)
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to compute Fibonacci numbers up to n."}
],
temperature=0.7,
max_tokens=200
)
print(response.choices[0].message.content)
Este código genera una implementación recursiva de Fibonacci con memoización, aprovechando la destreza de codificación de INTELLECT-3. El parámetro temperature controla la creatividad: valores más bajos (por ejemplo, 0.2) favorecen salidas deterministas para consultas factuales, mientras que valores más altos (hasta 1.0) fomentan diversas rutas de razonamiento.
Para el razonamiento matemático, usted estructura los prompts para encadenar pensamientos. El entrenamiento de RL de INTELLECT-3 brilla aquí, ya que simula la verificación paso a paso. Ejemplo:
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "user", "content": "Prove that the sum of angles in a triangle is 180 degrees. Use Euclidean geometry."}
],
max_tokens=500
)
El modelo responde con una prueba rigurosa, citando axiomas y teoremas. Usted analiza la salida a través de response.choices[0].message.content, que llega como una cadena. Para datos estructurados, habilite el modo JSON agregando "response_format": {"type": "json_object"} a la solicitud, asegurando respuestas analizables.
El uso avanzado implica la llamada a herramientas, donde INTELLECT-3 integra funciones externas. Defina las herramientas en la solicitud:
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": "What's the weather in New York?"}],
tools=tools
)
Si el modelo invoca la herramienta, devuelve argumentos en response.choices[0].message.tool_calls. Usted ejecuta la función externamente y alimenta los resultados de vuelta en un mensaje de seguimiento. Este patrón construye flujos de trabajo agenciales, capitalizando los comportamientos de INTELLECT-3 entrenados en el entorno.
El manejo de errores constituye una parte crítica. Los problemas comunes incluyen 401 (clave no válida), 429 (límite de tasa) y 400 (solicitud mal formada). Implemente reintentos con retroceso exponencial:
import time
from openai import OpenAIError
try:
response = client.chat.completions.create(...)
except OpenAIError as e:
if e.status_code == 429:
time.sleep(2 ** e.attempt) # Backoff
# Retry logic here
raise
Las respuestas incluyen metadatos como usage (prompt_tokens, completion_tokens, total_tokens), que usted registra para la optimización. INTELLECT-3 procesa hasta 4096 tokens por completado, equilibrando profundidad y velocidad.
Las respuestas en streaming mejoran las aplicaciones en tiempo real. Añada stream=True a la llamada de creación; el cliente produce fragmentos como Eventos Enviados por el Servidor. Analícelos iterativamente:
stream = client.chat.completions.create(..., stream=True)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
Esta técnica es adecuada para chatbots o asistentes de código en vivo, donde los usuarios esperan retroalimentación incremental.
Habiendo dominado la elaboración de solicitudes, ahora evaluará el rendimiento. El siguiente segmento presenta herramientas de benchmarking adaptadas a INTELLECT-3.
Optimizando y Evaluando el Uso de la API de INTELLECT-3
Usted optimiza las llamadas API ajustando parámetros empíricamente. Comience agrupando múltiples mensajes en una sola solicitud para obtener ganancias de rendimiento, hasta 10 veces la eficiencia en suites de evaluación. La CLI de Prime Intellect soporta esto:
prime env eval gsm8k -m prime-intellect/intellect-3 -n 100 --batch-size 8
Este comando ejecuta 100 muestras GSM8K, agregando métricas de precisión y latencia. Usted analiza los resultados para ajustar top_p o frequency_penalty, que mitigan la repetición en generaciones largas.
La evaluación se extiende a entornos personalizados del Verifiers Hub. Cargue un entorno de RL y consulte INTELLECT-3 como la política:
from prime_rl.environments import load_env
env = load_env("theorem_prover")
observation = env.reset()
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": observation}]
)
action = parse_response(response) # Custom parser
next_obs, reward, done = env.step(action)
Las recompensas cuantifican las mejoras, guiando el ajuste fino si se aloja localmente. Para usuarios solo de API, registre las interacciones en una base de datos vectorial y calcule métricas posteriores como la tasa de éxito de la tarea.
Las consideraciones de seguridad también importan. Saneé las entradas del usuario para prevenir la inyección de prompts, y use prompts del sistema para establecer límites. El trasfondo de RL de INTELLECT-3 reduce las alucinaciones, pero usted valida las salidas contra verificadores para aplicaciones de alto riesgo.
El escalado implica monitoreo a través del panel de control. Configure alertas para umbrales de tokens e integre con herramientas de observabilidad como Prometheus, que Prime Intellect expone para los clústeres. Así, mantiene la fiabilidad a medida que crece el uso.
Ahora que maneja la optimización, considere los costos. La transparencia de precios asegura una integración sostenible.
Precios de la API de INTELLECT-3: Modelo Transparente Basado en Tokens
Prime Intellect estructura los precios en torno al consumo de tokens, cobrando por separado la entrada y la salida. Usted paga por cada 1,000 tokens, con tarifas que varían según el modelo y el proveedor. Para INTELLECT-3, espere cifras competitivas —alrededor de $0.50 por millón de tokens de entrada y $1.50 por millón de salida— aunque los valores exactos aparecen en la respuesta del endpoint de modelos.
| Proveedor | Entrada ($$ /1M tokens) | Salida ( $$/1M tokens) | Notas |
|---|---|---|---|
| Prime Intellect Direct | ~$0.45–$0.60 | ~$1.30–$1.80 | Costo más bajo, descuentos por volumen |
| OpenRouter | ~$0.60–$0.80 | ~$1.80–$2.40 | Incluye tarifa de plataforma OpenRouter |
Las tarifas exactas fluctúan; siempre verifique los valores más recientes en su panel de control o a través del endpoint de modelos.
¿Cuál Debería Elegir?
- Elija Prime Intellect directo si desea máxima velocidad, el costo más bajo o planifica un uso de alto volumen.
- Elija OpenRouter si prefiere una única clave API para más de 50 modelos, necesita una incorporación instantánea o desea un enrutamiento de respaldo integrado.
Ambas opciones ofrecen el mismo rendimiento de INTELLECT-3. Elija la que mejor se adapte a su flujo de trabajo; muchos equipos incluso usan ambas simultáneamente para redundancia.
El resto de esta guía (formatos de solicitud, streaming, llamada a herramientas, optimización, etc.) se aplica por igual, ya sea que llame a Prime Intellect directamente o a través de OpenRouter.
Continúe con los detalles completos de implementación técnica a continuación, y comience a construir con INTELLECT-3 hoy, a través de la puerta de enlace que mejor funcione para usted.
Integraciones Avanzadas con la API de INTELLECT-3
Usted extiende INTELLECT-3 a ecosistemas como LangChain o LlamaIndex para orquestación. En LangChain:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="prime-intellect/intellect-3", openai_api_key=os.environ["PRIME_API_KEY"], openai_api_base="https://api.pinference.ai/api/v1")
prompt = ChatPromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello, world!"}))
Esto vincula la API a pipelines de generación aumentada por recuperación (RAG), mejorando la precisión con conocimiento externo.
Para microservicios, implemente a través de wrappers de FastAPI que actúen como proxy para INTELLECT-3:
from fastapi import FastAPI
from openai import OpenAI
app = FastAPI()
client = OpenAI(...) # As above
@app.post("/generate")
def generate(body: dict):
response = client.chat.completions.create(model="prime-intellect/intellect-3", **body)
return {"content": response.choices[0].message.content}
Exponga este endpoint de forma segura, con limitación de tasas usando Redis. Estas configuraciones impulsan herramientas SaaS, desde generadores de contenido hasta asistentes de investigación.
Los casos extremos requieren atención. Maneje los desbordamientos de tokens truncando las entradas dinámicamente y recurra a modelos más pequeños si INTELLECT-3 se pone en cola. Los foros de la comunidad en el sitio de Prime Intellect ofrecen hilos de solución de problemas.
Conclusión: Implemente la API de INTELLECT-3 con Confianza
Ahora posee un kit de herramientas completo para el uso de la API de INTELLECT-3. Desde sus raíces de código abierto hasta el manejo preciso de solicitudes y la gestión de costos, esta guía lo equipa para implementaciones en el mundo real. Experimente con Apidog para refinar sus flujos de trabajo y monitoree la documentación en evolución para actualizaciones.
Implemente estas técnicas de forma incremental: comience con chats simples, luego escale a agentes. La eficiencia y la apertura de INTELLECT-3 lo posicionan como una opción preferente para proyectos de IA técnicos. Comience a codificar hoy y sea testigo del impacto en sus aplicaciones.