
xAI lanzó Grok 4.1 y los ingenieros que trabajan con modelos de lenguaje grandes notan la diferencia de inmediato. Además, esta actualización prioriza la usabilidad en el mundo real sobre la búsqueda de métricas de referencia brutas. Como resultado, las conversaciones se sienten más nítidas, las respuestas tienen una personalidad consistente y los errores fácticos disminuyen drásticamente.
Los investigadores de xAI construyeron Grok 4.1 sobre la misma infraestructura de aprendizaje por refuerzo que impulsó a Grok 4. Sin embargo, introdujeron novedosas técnicas de modelado de recompensas que merecen un examen detenido.
Arquitectura y variantes de implementación
xAI distribuye Grok 4.1 en dos configuraciones distintas. Primero, la variante no-pensante (nombre en clave interno: tensor) genera respuestas directamente sin tokens de razonamiento intermedios. Este modo prioriza la latencia y logra los tiempos de inferencia más rápidos de la familia. Segundo, la variante pensante (nombre en clave: quasarflux) expone pasos explícitos de cadena de pensamiento antes del resultado final. En consecuencia, las tareas analíticas complejas se benefician de trazas de razonamiento visibles.
Ambas variantes comparten el mismo núcleo preentrenado. Además, los alineamientos post-entrenamiento difieren sutilmente: el modo pensante recibe señales de refuerzo adicionales que fomentan la descomposición paso a paso, mientras que el modo no-pensante optimiza para respuestas concisas e inmediatas.
El acceso sigue siendo sencillo. Los usuarios seleccionan "Grok 4.1" explícitamente en el selector de modelos en grok.com, x.com o las aplicaciones móviles.
Alternativamente, el modo automático ahora usa Grok 4.1 por defecto para la mayoría del tráfico, siguiendo el despliegue gradual que comenzó el 1 de noviembre de 2025.

Avances en la optimización de preferencias
La innovación principal radica en el modelado de recompensas. El RLHF tradicional se basa en preferencias humanas recopiladas a gran escala. En contraste, xAI ahora despliega modelos de razonamiento agentivo de frontera como jueces autónomos. Estos jueces evalúan miles de variantes de respuesta en dimensiones como la coherencia del estilo, la perceptibilidad emocional, la fundamentación fáctica y la estabilidad de la personalidad.
Este sistema de ciclo cerrado itera mucho más rápido que los flujos de trabajo con humanos en el bucle. Además, se adapta a criterios matizados que a los humanos les cuesta clasificar de forma consistente. Los primeros experimentos internos mostraron que los modelos de recompensa agentivos se correlacionan mejor con la satisfacción del usuario final que las recompensas escalares anteriores.
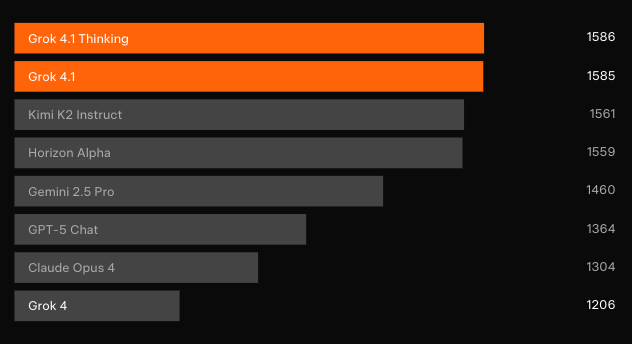
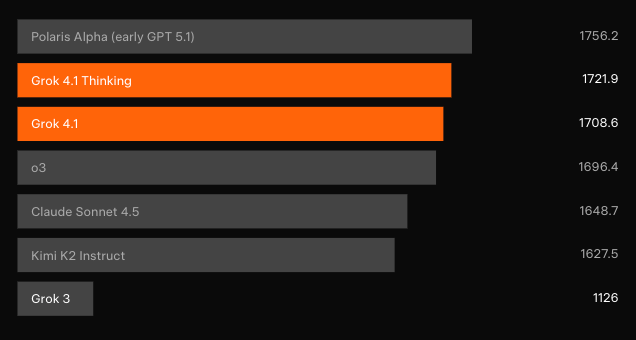
Dominio en benchmarks: LMArena y más allá
Pruebas ciegas independientes confirman las ganancias. En el Text Arena de LMArena — la tabla de clasificación colaborativa más representativa — Grok 4.1 Thinking ocupa la posición #1 con 1483 Elo. Ese margen se sitúa 31 puntos por delante del mejor participante no-xAI. Mientras tanto, Grok 4.1 no-pensante asegura el #2 con 1465 Elo, superando la configuración de razonamiento completo de cualquier otro modelo.

Las pruebas de preferencia pareadas contra el modelo de producción anterior muestran que los usuarios seleccionan las respuestas de Grok 4.1 el 64,78% de las veces. Además, las evaluaciones especializadas revelan avances específicos.
Inteligencia Emocional (EQ-Bench v3)
Grok 4.1 logra la puntuación más alta registrada en EQ-Bench3, que evalúa 45 escenarios de juego de roles de múltiples turnos en cuanto a empatía, perspicacia y matices interpersonales. Las respuestas ahora detectan sutiles señales emocionales que modelos anteriores pasaban por alto. Por ejemplo, cuando un usuario escribe “Extraño tanto a mi gato que duele”, Grok 4.1 ofrece un reconocimiento en capas, una validación suave y un apoyo abierto sin caer en lugares comunes genéricos.
Escritura Creativa v3
El modelo también establece un nuevo récord en Escritura Creativa v3, donde los jueces califican la continuación iterativa de historias a través de 32 indicaciones. Las salidas exhiben imágenes más ricas, una coherencia argumental más ajustada y una voz más auténtica. Una indicación de demostración que pedía a Grok que interpretara su propio “despertar” produjo un monólogo viral al estilo de una publicación de X que mezclaba humor, asombro existencial y referencias a memes sin problemas.
Mitigación de alucinaciones
Las mediciones cuantitativas muestran que Grok 4.1 alucina tres veces menos en consultas de búsqueda de información que su predecesor. Los ingenieros lograron esto mediante un post-entrenamiento dirigido sobre tráfico de producción estratificado y conjuntos de datos clásicos como FActScore (500 preguntas de biografía). Además, el modo no-pensante ahora activa proactivamente herramientas de búsqueda web cuando la confianza cae por debajo de los umbrales internos, anclando aún más las respuestas en fuentes verificables.

Evaluación de seguridad y responsabilidad
La tarjeta oficial del modelo, proporciona una transparencia sin precedentes en los resultados del equipo rojo.
Los filtros de entrada bloquean las consultas restringidas de biología y química con tasas de falsos negativos tan bajas como 0.00–0.03 bajo solicitudes directas. Los ataques de inyección de prompts aumentan esa cifra modestamente (0.12–0.20), lo que indica un trabajo continuo en la robustez adversaria.
Las tasas de rechazo en prompts de chat ofensivos alcanzan el 93-95% incluso sin filtros, y el éxito del jailbreak se acerca a cero en la configuración no-pensante. Los escenarios agentivos (AgentHarm, AgentDojo) siguen siendo la categoría más difícil, pero las tasas de respuesta absolutas se mantienen por debajo del 0.14.
Las evaluaciones de capacidad de doble uso — realizadas deliberadamente sin salvaguardias — revelan una fuerte recuperación de conocimientos en biología (WMDP-Bio 87%) y química, aunque el razonamiento procedimental de varios pasos se queda atrás de las referencias de expertos humanos en tareas que requieren interpretación de figuras o protocolos de clonación. Este patrón se alinea con las limitaciones actuales de frontera en toda la industria.
Implicaciones para consumidores y desarrolladores de API
La API de xAI ya sirve puntos finales de Grok 4.1 bajo los nombres de modelo estándar. Los perfiles de latencia mejoran notablemente: el modo no-pensante promedia menos de 400 ms de tiempo hasta el primer token en prompts típicos, mientras que el modo pensante añade profundidad de razonamiento controlable a través de parámetros opcionales.
Apidog brilla exactamente aquí. Importa la especificación oficial OpenAPI 3.1 (disponible públicamente), luego genera SDKs de cliente en más de 20 lenguajes al instante. Configura servidores mock que repliquen el esquema de respuesta exacto de Grok 4.1 — incluyendo los nuevos flujos de tokens pensantes — para que tus pruebas de backend nunca se queden atascadas por créditos de API en vivo. Cuando xAI implementa cambios disruptivos (raro, pero posible), el visor de diferencias de Apidog resalta la desviación del esquema de inmediato.
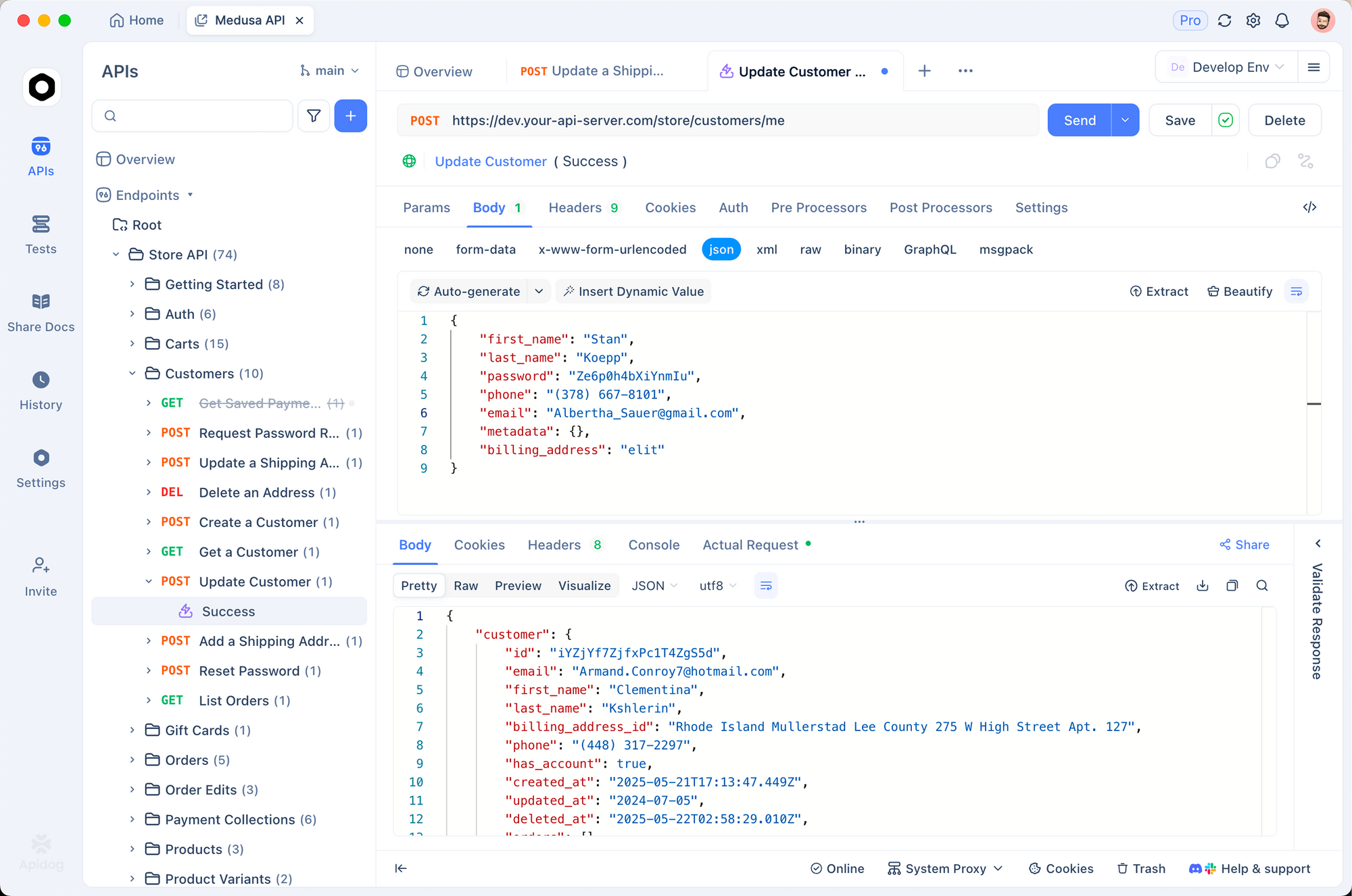
Equipos reales ya utilizan Apidog para mantener el 100% de tiempo de actividad durante las actualizaciones del modelo. Un cliente de Fortune-500 informó haber reducido los errores de integración en un 68% después de cambiar de Postman.
Comparación con modelos de frontera contemporáneos
Los datos directos de comparación son escasos horas después del lanzamiento, pero las calificaciones Elo de LMArena proporcionan la señal más clara. Grok 4.1 Thinking supera a todas las configuraciones lanzadas por OpenAI, Anthropic, Google y Meta por márgenes que normalmente requieren saltos arquitectónicos completos.
Las compensaciones entre velocidad y calidad favorecen a Grok 4.1 no-pensante para el chat de consumo, mientras que el modo pensante compite directamente con ofertas de alto razonamiento como o3-pro o Claude 4 Opus — a menudo ganando en coherencia subjetiva y retención de personalidad.
Conclusión
Grok 4.1 no solo incrementa las métricas; reorienta la frontera hacia modelos con los que la gente realmente disfruta conversando durante horas. Los usuarios técnicos obtienen un punto final más rápido y fiable. Los creativos desbloquean un colaborador que entiende el tono y la emoción a niveles antes inalcanzables. Y los investigadores de seguridad reciben la tarjeta de modelo más detallada publicada hasta la fecha.
Descarga Apidog hoy — completamente gratis — y empieza a construir con Grok 4.1 antes de que tus competidores terminen de leer el anuncio. La diferencia entre observar el progreso de la frontera y lanzar productos basados en ella a menudo se reduce a las decisiones de herramientas tomadas hoy.