
Los modelos gpt-oss-safeguard de OpenAI abordan esta necesidad al habilitar el razonamiento basado en políticas para tareas de clasificación. Los ingenieros integran estos modelos para clasificar contenido generado por el usuario, detectar violaciones y mantener la integridad de la plataforma.
Comprensión de GPT-OSS-Safeguard: Características y Capacidades
Los ingenieros de OpenAI desarrollaron gpt-oss-safeguard como modelos de razonamiento de peso abierto adaptados para la clasificación de seguridad. Optimizan estos modelos a partir de la base gpt-oss, lanzándolos bajo la licencia Apache 2.0. Los desarrolladores descargan los modelos de Hugging Face y los implementan libremente. La línea incluye gpt-oss-safeguard-20b y gpt-oss-safeguard-120b, donde los números indican las escalas de parámetros.
Estos modelos procesan dos entradas principales: una política definida por el desarrollador y el contenido para su evaluación. El sistema aplica el razonamiento de cadena de pensamiento para interpretar la política y clasificar el contenido. Por ejemplo, determina si un mensaje de usuario viola las reglas sobre trampas en foros de juegos. Este enfoque permite actualizaciones dinámicas de políticas sin reentrenamiento, lo que exigen los clasificadores tradicionales.
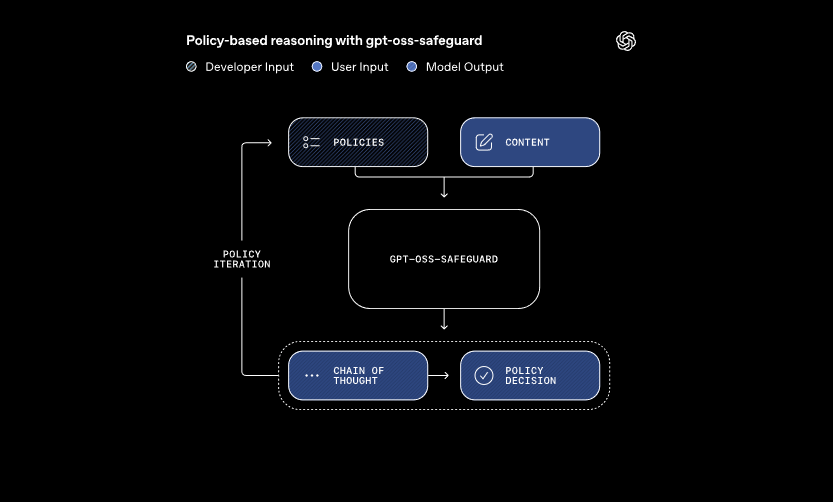
Además, gpt-oss-safeguard admite múltiples políticas simultáneamente. Los desarrolladores introducen varias reglas en una sola llamada de inferencia, y el modelo evalúa el contenido contra todas ellas. Esta capacidad agiliza los flujos de trabajo para plataformas que manejan diversos riesgos, como la desinformación o el discurso dañino. Sin embargo, el rendimiento puede disminuir ligeramente con políticas adicionales, por lo que los equipos prueban las configuraciones a fondo.
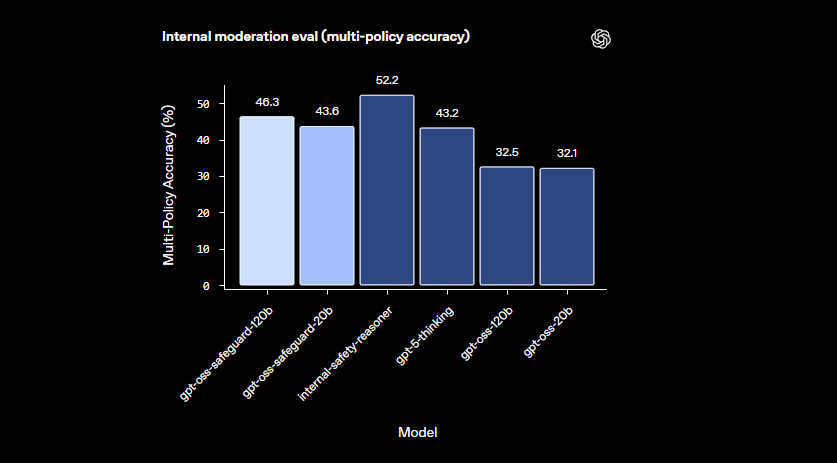
Los modelos sobresalen en dominios matizados donde los clasificadores más pequeños fallan. Manejan daños emergentes adaptándose rápidamente a políticas revisadas. Además, la salida de cadena de pensamiento proporciona transparencia: los desarrolladores revisan el rastro de razonamiento para auditar las decisiones. Esta característica resulta invaluable para los equipos de cumplimiento que requieren IA explicable.
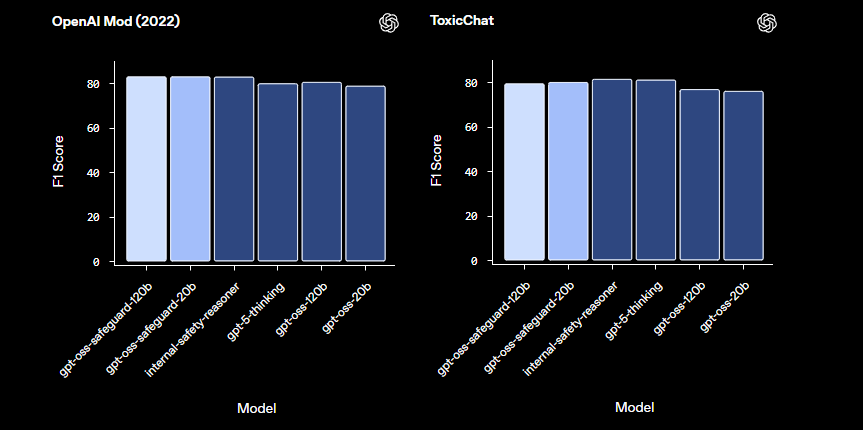
En comparación con los modelos de seguridad predefinidos como LlamaGuard, gpt-oss-safeguard ofrece una mayor personalización. Evita taxonomías fijas, lo que permite a las organizaciones definir sus propios umbrales. En consecuencia, la integración es adecuada para ingenieros de Confianza y Seguridad que construyen pipelines de moderación escalables. Ahora que comprendemos los fundamentos, procedamos a la configuración del entorno.
Configuración de su entorno para el acceso a la API de GPT-OSS-Safeguard
Los desarrolladores comienzan preparando sus sistemas para ejecutar gpt-oss-safeguard. Dado que los modelos son de peso abierto, puede implementarlos localmente o a través de proveedores alojados. Esta flexibilidad se adapta a varias configuraciones de hardware, desde máquinas personales hasta servidores en la nube.
Primero, instale las dependencias necesarias. Python 3.10 o superior sirve como base. Use pip para agregar bibliotecas como Hugging Face Transformers: pip install transformers. Para una inferencia acelerada, incluya torch con soporte CUDA si posee una GPU compatible. Los ingenieros con hardware NVIDIA habilitan esto para un procesamiento más rápido.
A continuación, descargue los modelos de Hugging Face. Acceda a la colección. Seleccione gpt-oss-safeguard-20b para necesidades de recursos más ligeras o gpt-oss-safeguard-120b para una precisión superior. El comando transformers-cli download openai/gpt-oss-safeguard-20b recupera los archivos.
Para exponer una API, ejecute un servidor local. Herramientas como vLLM manejan esto de manera eficiente. Instale vLLM con pip install vllm. Luego, inicie el servidor: vllm serve openai/gpt-oss-safeguard-20b. Este comando inicia un endpoint compatible con OpenAI en http://localhost:8000/v1. De manera similar, Ollama simplifica la implementación: ollama run gpt-oss-safeguard:20b. Proporciona APIs REST para la integración.
Para pruebas locales, LM Studio ofrece una interfaz fácil de usar. Ejecute lms get openai/gpt-oss-safeguard-20b para obtener el modelo. El software emula la API de Chat Completions de OpenAI, lo que permite transiciones de código fluidas a producción.
Las opciones alojadas eliminan las preocupaciones de hardware. Proveedores como Groq admiten gpt-oss-safeguard-20b a través de su API. Regístrese en https://console.groq.com, genere una clave API y dirija el modelo en las solicitudes. El precio comienza en $0.075 por millón de tokens de entrada. OpenRouter también lo aloja.
Una vez configurado, verifique la instalación. Envíe una solicitud de prueba a través de curl: curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "openai/gpt-oss-safeguard-20b", "messages": [{"role": "system", "content": "Test policy"}, {"role": "user", "content": "Test content"}]}'. Una respuesta exitosa confirma la preparación. Con el entorno configurado, a continuación, elaborará las políticas.
Elaboración de políticas efectivas para GPT-OSS-Safeguard
Las políticas forman la columna vertebral de las operaciones de gpt-oss-safeguard. Los desarrolladores las escriben como prompts estructurados que guían la clasificación. Una política bien diseñada maximiza el poder de razonamiento del modelo, asegurando resultados precisos y explicables.
Estructure su política con secciones distintas. Comience con Instrucciones, especificando las tareas del modelo. Por ejemplo, indíquele que clasifique el contenido como infractor (1) o seguro (0). Siga con Definiciones, aclarando términos clave como "lenguaje deshumanizador". Luego, describa los Criterios para violaciones y contenido seguro. Finalmente, incluya Ejemplos: proporcione 4-6 casos límite etiquetados en consecuencia.
Use voz activa en las políticas: "Marcar contenido que promueva la violencia" en lugar de alternativas pasivas. Mantenga el lenguaje preciso; evite ambigüedades como "generalmente inseguro". Si surgen conflictos entre reglas, defina la precedencia explícitamente. Para escenarios de múltiples políticas, concaténelas en el mensaje del sistema.
Controle la profundidad del razonamiento a través del parámetro "reasoning_effort": configúrelo en "high" para casos complejos o "low" para mayor velocidad. El formato harmony, integrado en gpt-oss-safeguard, separa el razonamiento de la salida final. Esto asegura respuestas de API limpias mientras se conservan los registros de auditoría.
Optimice la longitud de la política en torno a 400-600 tokens. Las políticas más cortas corren el riesgo de una simplificación excesiva, mientras que las más largas pueden confundir al modelo. Pruebe iterativamente: clasifique contenido de muestra y refine basándose en los resultados. Herramientas como los contadores de tokens en Hugging Face ayudan aquí.
Para formatos de salida, elija binario para mayor simplicidad: Return exactly 0 or 1. Agregue una justificación para la profundidad: {"violation": 1, "rationale": "Explanation here"}. Esta estructura JSON se integra fácilmente con sistemas posteriores. A medida que refine las políticas, haga la transición a la implementación de la API.
Implementación de llamadas a la API con GPT-OSS-Safeguard
Los desarrolladores interactúan con gpt-oss-safeguard a través de endpoints compatibles con OpenAI. Ya sea local o alojado, el proceso sigue patrones estándar de finalización de chat.
Prepare su cliente. En Python, importe OpenAI: from openai import OpenAI. Inicialice con la URL base y la clave: client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy") para uso local, o valores específicos del proveedor.
Construya mensajes. El rol del sistema contiene la política: {"role": "system", "content": "Your detailed policy here"}. El rol del usuario contiene el contenido: {"role": "user", "content": "Content to classify"}.
Llame a la API: completion = client.chat.completions.create(model="openai/gpt-oss-safeguard-20b", messages=messages, max_tokens=500, temperature=0.0). Una temperatura de 0 asegura resultados deterministas para tareas de seguridad.
Analice la respuesta: result = completion.choices[0].message.content. Para salidas estructuradas, use el análisis JSON. Groq mejora esto con el almacenamiento en caché de prompts, reutilizando políticas en todas las llamadas para reducir costos en un 50%.
Maneje el streaming para retroalimentación en tiempo real: configure stream=True e itere sobre los fragmentos. Esto es adecuado para la moderación de alto volumen.
Incorpore herramientas si es necesario, aunque gpt-oss-safeguard se enfoca en la clasificación. Defina funciones en el parámetro tools para capacidades extendidas, como la obtención de datos externos.
Monitoree el uso de tokens: la entrada incluye la política más el contenido, las salidas agregan razonamiento. Limite max_tokens para evitar desbordamientos. Una vez dominadas las llamadas, explore los ejemplos.
Características avanzadas en la API de GPT-OSS-Safeguard
gpt-oss-safeguard ofrece herramientas avanzadas para un control refinado. El almacenamiento en caché de prompts en Groq reutiliza las políticas, reduciendo la latencia y los costos.
Ajuste reasoning_effort en el mensaje del sistema: "Reasoning: high" para un análisis profundo. Esto maneja mejor el contenido ambiguo.
Aproveche la ventana de contexto de 128k para chats o documentos largos. Alimente conversaciones enteras para una clasificación holística.
Integre con sistemas más grandes: Envíe las salidas a colas de escalada o registro. Use webhooks para alertas en tiempo real.
Ajuste aún más si es necesario, aunque la base sobresale en el seguimiento de políticas. Combine con modelos más pequeños para prefiltrado, optimizando el cómputo.
La seguridad importa: Proteja las claves API y monitoree las inyecciones de prompts. Valide las entradas para prevenir exploits.
Escalado: Implemente en clústeres con vLLM para un alto rendimiento. Proveedores como Groq ofrecen más de 1000 tokens/segundo.
Estas características elevan gpt-oss-safeguard de clasificador básico a herramienta empresarial. Sin embargo, siga las mejores prácticas para obtener resultados óptimos.
Mejores prácticas y optimización para GPT-OSS-Safeguard
Los ingenieros optimizan gpt-oss-safeguard iterando sobre las políticas. Pruebe con diversos conjuntos de datos, midiendo la precisión mediante métricas como el F1-score.
Equilibre el tamaño del modelo: Use 20b para velocidad, 120b para precisión. Cuantifique los pesos para reducir la huella de memoria.
Monitoree el rendimiento: Registre los rastros de razonamiento para auditorías. Ajuste la temperatura mínimamente: 0.0 se adapta a las necesidades deterministas.
Maneje las limitaciones: El modelo puede tener dificultades con dominios altamente especializados; complemente con datos del dominio.
Asegure el uso ético: Alinee las políticas con las regulaciones. Evite sesgos diversificando los ejemplos.
Actualice regularmente: A medida que OpenAI evoluciona gpt-oss-safeguard, incorpore mejoras.
Gestión de costos: Para APIs alojadas, rastree el gasto de tokens. Las implementaciones locales minimizan los gastos.
Al aplicar estas prácticas, maximizará la eficiencia. En resumen, gpt-oss-safeguard potencia sistemas de seguridad robustos.
Conclusión: Integración de GPT-OSS-Safeguard en su flujo de trabajo
Los desarrolladores aprovechan gpt-oss-safeguard para construir clasificadores de seguridad adaptables. Desde la configuración hasta el uso avanzado, esta guía le proporciona los conocimientos técnicos. Implemente políticas, ejecute llamadas a la API y optimice según sus necesidades. A medida que las plataformas evolucionan, gpt-oss-safeguard se adapta sin problemas, garantizando entornos seguros.