
Los desarrolladores buscan constantemente herramientas potentes para construir aplicaciones inteligentes. OpenAI aborda esta necesidad con el lanzamiento de GPT-OSS, una serie de modelos de lenguaje de peso abierto que proporcionan capacidades avanzadas de razonamiento. Estos modelos, incluyendo gpt-oss-120b y gpt-oss-20b, permiten la personalización y el despliegue en diversos entornos. Los usuarios acceden a ellos a través de APIs proporcionadas por plataformas de alojamiento, lo que permite una integración perfecta en los proyectos.
Para empezar a trabajar con la API de GPT-OSS, los desarrolladores obtienen acceso a través de proveedores como OpenRouter o Together AI. Estas plataformas alojan los modelos y exponen puntos finales estándar compatibles con el formato de API de OpenAI. Esta compatibilidad simplifica la migración desde modelos propietarios.
¿Qué es GPT-OSS? Características y Capacidades Clave
OpenAI diseña GPT-OSS como una familia de modelos de Mezcla de Expertos (MoE). Esta arquitectura activa solo un subconjunto de parámetros por token, aumentando la eficiencia. Por ejemplo, gpt-oss-120b cuenta con 117 mil millones de parámetros totales, pero activa solo 5.1 mil millones por token. De manera similar, gpt-oss-20b utiliza 21 mil millones de parámetros con 3.6 mil millones activos.
Los modelos emplean estructuras basadas en Transformer con capas de atención densas y dispersas alternas. Incorporan incrustaciones posicionales rotativas (RoPE) para manejar contextos largos de hasta 128,000 tokens. Los desarrolladores se benefician de esto en aplicaciones que requieren una entrada extensa, como el resumen de documentos.
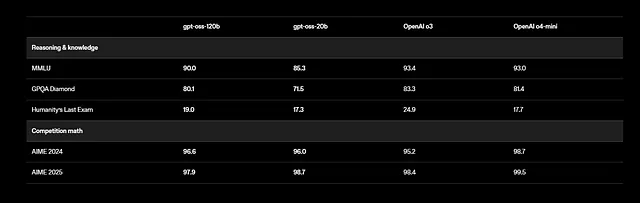
Además, GPT-OSS admite tareas multilingües, aunque el entrenamiento se centra en inglés con énfasis en datos STEM y de codificación. Los puntos de referencia muestran resultados impresionantes: gpt-oss-120b obtiene un 94.2% en MMLU (Massive Multitask Language Understanding) y un 96.6% en AIME (American Invitational Mathematics Examination). Supera a modelos como o4-mini en consultas relacionadas con la salud y matemáticas de competición.
Los desarrolladores utilizan funciones de llamada a herramientas, donde el modelo invoca funciones externas como la búsqueda web o la ejecución de código. Esta capacidad de agente permite construir sistemas autónomos. Por ejemplo, el modelo encadena múltiples llamadas a herramientas en una sola respuesta para resolver problemas paso a paso.
Además, los modelos se adhieren a la licencia Apache 2.0, lo que permite la modificación y el despliegue gratuitos. OpenAI proporciona pesos en Hugging Face, cuantificados en formato MXFP4 para reducir el uso de memoria. Los usuarios pueden ejecutarlos localmente o a través de proveedores de la nube.
Sin embargo, se aplican consideraciones de seguridad. OpenAI realiza evaluaciones bajo su Marco de Preparación, probando riesgos como la desinformación. Los desarrolladores implementan salvaguardas, como el filtrado de salidas, para mitigar problemas.
En esencia, GPT-OSS combina potencia con accesibilidad. Su naturaleza abierta fomenta las contribuciones de la comunidad, lo que lleva a mejoras rápidas. A continuación, identifique los proveedores que ofrecen acceso API a estos modelos.
Elección de Proveedores para el Acceso a la API de GPT-OSS
Varias plataformas alojan modelos GPT-OSS y proporcionan puntos finales de API. Los desarrolladores seleccionan en función de necesidades como la velocidad, el costo y la escalabilidad. OpenRouter, por ejemplo, ofrece gpt-oss-120b con precios competitivos y fácil integración.
Together AI ofrece otra opción, enfatizando los despliegues listos para empresas. Admite el modelo a través de un punto final /v1/chat/completions, compatible con los clientes de OpenAI. Los desarrolladores envían cargas útiles JSON especificando mensajes, max_tokens y temperatura.
Además, Fireworks AI y Cerebras ofrecen inferencia de alta velocidad. Cerebras logra hasta 3,000 tokens por segundo, ideal para aplicaciones en tiempo real. Los precios varían: OpenRouter cobra alrededor de $0.15 por millón de tokens de entrada, mientras que Together AI ofrece tarifas similares con descuentos por volumen.
Los desarrolladores también consideran el autoalojamiento por privacidad. Herramientas como vLLM u Ollama permiten ejecutar GPT-OSS en servidores locales, exponiendo una API. Por ejemplo, vLLM sirve el modelo con rutas compatibles con OpenAI, requiriendo un solo comando para iniciar.
Sin embargo, los proveedores de la nube simplifican el escalado. AWS, Azure y Vercel integran GPT-OSS a través de asociaciones con OpenAI. Estas opciones manejan el equilibrio de carga y el autoescalado automáticamente.
Además, evalúe la latencia. gpt-oss-20b se adapta a dispositivos de borde con requisitos más bajos, mientras que gpt-oss-120b exige GPU como NVIDIA H100. Los proveedores optimizan el hardware, asegurando un rendimiento consistente.
En resumen, el proveedor adecuado se alinea con los objetivos del proyecto. Una vez elegido, proceda a obtener las credenciales de la API.
Obtención de Acceso a la API y Configuración de su Entorno
Los desarrolladores comienzan registrándose en el sitio de un proveedor. Para OpenRouter, visite openrouter.ai, cree una cuenta y navegue a la sección Claves. Genere una nueva clave API, nombrándola para referencia, y cópiela de forma segura.
A continuación, instale las bibliotecas cliente. En Python, use pip para agregar openai: pip install openai. Configure el cliente con la URL base y la clave. Por ejemplo:
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="your_api_key_here"
)
Esta configuración permite enviar solicitudes a los modelos gpt-oss.
Además, para Together AI, use su SDK: pip install together. Inicialice con:
import together
together.api_key = "your_together_api_key"
Pruebe la conexión listando modelos o enviando una consulta simple.
Sin embargo, verifique el hardware si se autoaloja. Descargue los pesos de Hugging Face: huggingface-cli download openai/gpt-oss-120b. Luego, use vLLM para servir: vllm serve openai/gpt-oss-120b.
Además, establezca variables de entorno para la seguridad. Almacene las claves en archivos .env y cárguelas con la biblioteca dotenv.
En caso de problemas, consulte la documentación del proveedor para límites de velocidad o errores de autenticación. Esta preparación asegura interacciones fluidas con la API.
Realizando su Primera Llamada a la API de GPT-OSS
Los desarrolladores elaboran solicitudes utilizando el punto final de finalización de chat. Especifique el modelo, como "openai/gpt-oss-120b", en la carga útil.
Para una llamada básica, prepare los mensajes como una lista de diccionarios. Cada uno incluye el rol (sistema, usuario, asistente) y el contenido.
Aquí tiene un ejemplo en Python:
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum superposition."}
],
max_tokens=200,
temperature=0.7
)
print(completion.choices[0].message.content)
Esto genera una respuesta que explica el concepto técnicamente.
Además, ajuste los parámetros para el control. La temperatura influye en la creatividad; valores más bajos producen resultados deterministas. Top_p limita el muestreo de tokens, mientras que presence_penalty desaconseja la repetición.
A continuación, incorpore la llamada a herramientas. Defina las herramientas en la solicitud:
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location"]
}
}
}
]
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[{"role": "user", "content": "What's the weather like in Boston?"}],
tools=tools,
tool_choice="auto"
)
El modelo responde con una llamada a herramienta, que los desarrolladores ejecutan y retroalimentan.
Sin embargo, maneje las respuestas con cuidado. Analice el JSON para obtener el contenido, finish_reason y estadísticas de uso como el recuento de tokens.
Además, para la cadena de pensamiento, solicite con "Piensa paso a paso". Establezca el esfuerzo de razonamiento en los mensajes del sistema: "reasoning_effort: medium".
Experimente con gpt-oss-20b para pruebas más rápidas: Reemplace el nombre del modelo en las llamadas.
En escenarios avanzados, transmita respuestas usando stream=True para salida en tiempo real.
Estos pasos construyen habilidades fundamentales. Ahora, integre herramientas de prueba como Apidog.
Integrando Apidog para una Prueba Eficiente de la API de GPT-OSS
Los desarrolladores confían en Apidog para probar y depurar interacciones de API. Esta herramienta proporciona una interfaz fácil de usar para enviar solicitudes a los puntos finales de gpt-oss.
Primero, instale Apidog desde su sitio web. Cree un nuevo proyecto y agregue un punto final de API, como https://openrouter.ai/api/v1/chat/completions.
A continuación, configure los encabezados: Agregue Autorización con token Bearer y Content-Type como application/json.
Además, construya el cuerpo de la solicitud. Use el editor JSON de Apidog para ingresar el modelo, los mensajes y los parámetros. Por ejemplo, pruebe una llamada a gpt-oss para la generación de código.
Apidog visualiza las respuestas, destacando errores o éxitos. Admite variables de entorno para cambiar las claves API entre proveedores.
Sin embargo, aproveche las colecciones para organizar las pruebas. Agrupe las consultas de GPT-OSS por tarea, como razonamiento o uso de herramientas, y ejecútelas en lotes.
Además, Apidog genera fragmentos de código en lenguajes como Python o cURL a partir de sus solicitudes, acelerando el desarrollo.
Para la colaboración, comparta proyectos con los equipos. Esto asegura pruebas consistentes de las integraciones de gpt-oss.
En la práctica, use Apidog para monitorear el uso de tokens y optimizar las indicaciones, reduciendo costos.
En general, Apidog mejora la productividad al trabajar con la API de GPT-OSS.
Uso Avanzado: Ajuste Fino y Despliegue
Los desarrolladores ajustan finamente GPT-OSS para dominios específicos. Utilice la biblioteca transformers de Hugging Face para cargar pesos y entrenar en conjuntos de datos personalizados.
Por ejemplo, prepare datos en formato JSONL con pares de prompt-completion. Ejecute scripts de ajuste fino desde el repositorio de GitHub.
Además, despliegue modelos ajustados a través de vLLM para el servicio de API. Esto admite cargas de producción con características como el procesamiento por lotes dinámico.
A continuación, explore las extensiones multimodales. Aunque se centran en el texto, intégrelas con modelos de visión para aplicaciones híbridas.
Sin embargo, supervise el sobreajuste durante el ajuste fino. Utilice conjuntos de validación y detención temprana.
Además, escale con inferencia distribuida en clústeres. Proveedores como AWS ofrecen opciones gestionadas.
En configuraciones de agente, encadene GPT-OSS con APIs externas para flujos de trabajo como la investigación automatizada.
Estas técnicas amplían las capacidades más allá de las llamadas básicas.
Mejores Prácticas, Limitaciones y Solución de Problemas
Los desarrolladores siguen las mejores prácticas para obtener resultados óptimos. Elabore indicaciones claras, use ejemplos de pocas tomas e itere en función de los resultados.
Además, respete los límites de velocidad: consulte los paneles del proveedor para evitar la limitación.
Sin embargo, reconozca las limitaciones: GPT-OSS puede alucinar, así que valide las respuestas críticas. Carece de actualizaciones de conocimiento en tiempo real.
Además, asegure las claves API y registre el uso para el control de costos.
Solucione problemas revisando los códigos de error; 401 indica autenticación no válida, 429 significa que se alcanzó el límite de velocidad.
En resumen, adhiérase a estas pautas para un rendimiento fiable.
Conclusión: Potencie sus Proyectos con la API de GPT-OSS
Los desarrolladores ahora poseen las herramientas para integrar GPT-OSS de manera efectiva. Desde la configuración hasta las funciones avanzadas, esta guía lo equipa para el éxito. Experimente, refine e innove con gpt-oss y Apidog para crear soluciones de IA impactantes.