
Si ha estado prestando atención a los desarrollos de IA en 2025, probablemente haya escuchado mucho revuelo en torno a Google Gemini 3, el modelo de IA multimodal de próxima generación diseñado para competir con (y a veces superar) GPT-5. Ya sea que sea un ingeniero de software, un fundador de una startup, un entusiasta de la IA o simplemente alguien curioso sobre lo que Gemini 3 puede hacer, aprender a trabajar con la API de Google Gemini 3 abre la puerta a la creación de aplicaciones mucho más inteligentes y dinámicas.
Pero seamos honestos; la documentación de Google puede ser un poco densa si recién está comenzando. Así que, en esta guía, vamos a desglosar todo de una manera clara, amigable y fácil de entender para principiantes.
Ahora, ¡desbloqueemos el poder del modelo de IA más avanzado de Google!
¿Qué es Google Gemini 3?
Google Gemini 3 es el último modelo de la familia de IA multimodal de Google. A diferencia de los modelos anteriores, Gemini 3 está optimizado para:
- razonamiento y resolución de problemas
- entrada/salida multimodal (texto, imágenes, audio, incrustaciones de video)
- uso de herramientas y flujos de trabajo agenciales
- inferencia rápida con puntos finales de baja latencia
- cambio dinámico de modelo según su tarea
Pero lo más destacado es esto:
Gemini 3 introduce dos "modos de pensamiento" principales:
El parámetro thinking_level controla la profundidad máxima del proceso de razonamiento interno del modelo antes de que produzca una respuesta. Gemini 3 trata estos niveles como permisos relativos para pensar en lugar de garantías estrictas de tokens. Si no se especifica thinking_level, Gemini 3 Pro tomará por defecto high.
- Pensamiento Alto/Dinámico: Maximiza la profundidad del razonamiento. El modelo puede tardar mucho más en generar un primer token, pero la salida estará más cuidadosamente razonada.
- Pensamiento Bajo: Minimiza la latencia y el costo. Ideal para seguir instrucciones simples, chatear o aplicaciones de alto rendimiento.
Muchos principiantes aún no lo saben, pero elegir el modo correcto mejora drásticamente la calidad de la salida y ayuda a controlar sus costos.
En breve veremos cómo elegir un modo usando la API.
¿Por qué usar la API de Gemini 3 en lugar de una herramienta de interfaz de usuario?
Claro, podrías usar Gemini dentro de Google AI Studio. Pero si quieres:
- construir aplicaciones
- automatizar tareas
- integrar el modelo en flujos de trabajo
- crear chatbots
- procesar datos
- entrenar agentes
- ejecutar tareas multimodales
necesitarás la API de Gemini 3.
Esta guía se centra en la API REST porque:
- es más fácil para principiantes
- no se necesitan bibliotecas cliente
- se puede probar rápidamente en Apidog o Postman
- funciona en cualquier entorno backend
Cómo funciona la API de Gemini 3 (descripción general simple)
Aunque Gemini tiene capacidades avanzadas, la API en sí es bastante sencilla.
Envías una solicitud POST a…
<https://generativelanguage.googleapis.com/v1beta/models/{MODEL_ID}:generateContent?key=YOUR_API_KEY>
Incluyes JSON como:
- el prompt de texto
- una lista de mensajes (opcional)
- configuración del modelo
- configuración de seguridad
Recibes…
- texto de salida del modelo
- estructura de razonamiento (para pensamiento Alto/Dinámico)
- citas
- metadatos
- objetos multimodales (si aplica)
Una vez que entiendes esta estructura, todo lo demás se vuelve más fácil.
Primeros pasos: tus primeros pasos con la API de Gemini
Paso 1: Obtén tu clave de API
Piensa en tu clave de API como una contraseña especial que le dice a Google: "Sí, se me permite usar Gemini". Así es como puedes conseguir una:
- Ve a Google AI Studio
- Inicia sesión con tu cuenta de Google
- Haz clic en "Crear clave de API" en la barra lateral izquierda
- Ponle un nombre a tu clave y créala
- ¡Copia y guarda esta clave en un lugar seguro! No podrás verla de nuevo.
Importante: Nunca compartas tu clave de API ni la subas a repositorios de código públicos. Trátala como tu contraseña.
Paso 2: Elige tu enfoque
Puedes interactuar con Gemini de dos formas principales:
- API REST: El enfoque universal. Funciona con cualquier lenguaje de programación que pueda realizar solicitudes HTTP. Nos centraremos en este método.
- SDK oficiales: Google proporciona bibliotecas convenientes para Python, Node.js y otros lenguajes que manejan los detalles de HTTP por ti.
Dado que nos centramos en los fundamentos, utilizaremos el enfoque de la API REST, funciona en todas partes y te ayuda a comprender lo que sucede internamente.
Comprendiendo los modos de pensamiento de Gemini
Una de las características más poderosas de Gemini es su capacidad para operar en diferentes "modos de pensamiento". Esto no es solo marketing, cambia fundamentalmente cómo el modelo procesa tus solicitudes.
Pensamiento bajo (El demonio de la velocidad)
Cuándo usarlo: Para tareas simples, respuestas rápidas y cuando optimizas la velocidad y el costo.
- Velocidad: Respuestas muy rápidas
- Costo: Más asequible
- Casos de uso: Preguntas y respuestas simples, clasificación de texto, resumen básico, traducciones sencillas
Por ejemplo:
gemini-3-flash
gemini-3-mini
Piensa en el modo de Pensamiento Bajo como tener una conversación rápida con un amigo informado que te da respuestas inmediatas.
Pensamiento alto/dinámico (El analista reflexivo)
Cuándo usarlo: Para razonamientos complejos, problemas de varios pasos y tareas que requieren un análisis profundo.
- Velocidad: Más lento (piensa más antes de responder)
- Costo: Más caro
- Casos de uso: Problemas matemáticos complejos, razonamiento lógico, depuración de código, escritura creativa, planificación estratégica
El Pensamiento Alto/Dinámico es como consultar a un experto que se toma su tiempo para considerar todos los ángulos antes de darte una respuesta bien razonada.
Por ejemplo:
gemini-3-pro
gemini-3-pro-thinking
Estos modelos ofrecen un razonamiento más profundo, ventanas de atención más largas y mejores capacidades de planificación.
Lo bueno es que puedes elegir ambos modelos: Pensamiento Alto/Dinámico y Pensamiento Bajo, según tus necesidades específicas. Para la mayoría de las aplicaciones simples, el Pensamiento Bajo es perfecto. Cuando necesites un razonamiento más profundo, cambia a Pensamiento Alto.
Como regla general:
| Tipo de Tarea | Modo del Modelo |
|---|---|
| Investigación | Pensamiento Alto/Dinámico |
| Matemáticas/Lógica | Pensamiento Alto/Dinámico |
| Generación de Código | Pensamiento Alto/Dinámico |
| Chat con el cliente | Pensamiento Bajo |
| Generación de texto básica | Pensamiento Bajo |
| Asistentes de interfaz de usuario | Pensamiento Bajo |
| Aplicaciones en tiempo real | Pensamiento Bajo |
Te mostraremos cómo seleccionar cada modelo en la API REST.
Crea tu primera llamada a la API REST de Gemini 3
Comencemos con el ejemplo más simple posible.
Endpoint
POST <https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro:generateContent?key=YOUR_API_KEY>
Ejemplo de cuerpo de solicitud (JSON)
{
"contents": [
{ "role": "user",
"parts": [{ "text": "Explica cómo vuelan los aviones." }]
}
]
}
Ejemplo de comando Curl
curl -X POST \\
-H "Content-Type: application/json" \\
-d '{
"contents": [
{
"role": "user",
"parts": [{ "text": "Explica cómo vuelan los aviones." }]
}
]
}' \\
"<https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro:generateContent?key=YOUR_API_KEY>"
Usando el modo de Pensamiento Alto/Dinámico
Para activar el modo de razonamiento, debes usar un modelo que lo admita, como gemini-3-pro-thinking.
Ejemplo de API REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Encuentra la condición de carrera en este fragmento de C++ multi-hilo: [código aquí]"}]
}]
}'Cuando utilizas el modo de Pensamiento Alto/Dinámico, a menudo recibirás:
- estructuras de cadena de pensamiento (ocultas a menos que se soliciten)
- respuestas más coherentes
- tiempos de respuesta más lentos
- costos de inferencia más caros
Recomiendo usar este modo solo cuando realmente importa, como para un razonamiento extenso o la planificación de código.
Usando el modo de pensamiento bajo
Los modelos de Pensamiento Bajo están optimizados para la velocidad y son perfectos para:
- autocompletado
- mensajes cortos
- respuestas de UI
- pequeños asistentes
- funciones secundarias de chatbot
Ejemplo de API REST usando “Flash”
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "¿Cómo funciona la IA?"}]
}],
"generationConfig": {
thinkingConfig: {
thinkingLevel: "low"
}
}
}'Los modelos de Pensamiento Bajo cuestan mucho menos y devuelven respuestas casi instantáneas.
Manejo de entradas multimodales (imágenes, PDFs, audio, video)
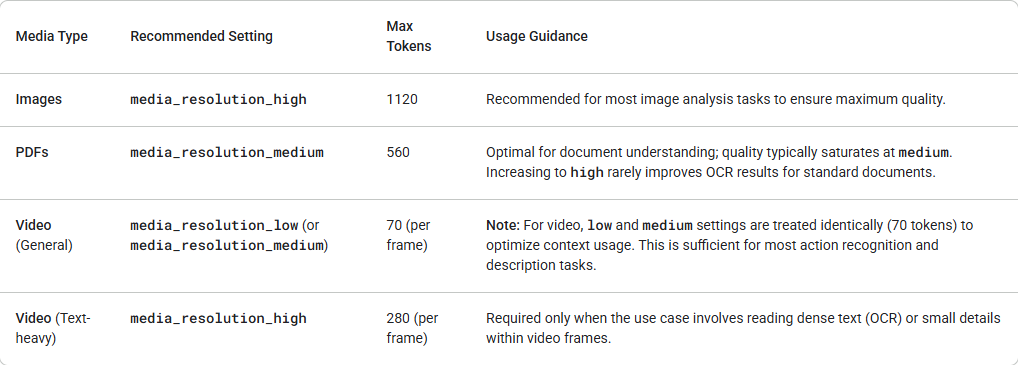
Gemini 3 introduce un control granular sobre el procesamiento de visión multimodal a través del parámetro media_resolution. Resoluciones más altas mejoran la capacidad del modelo para leer texto fino o identificar pequeños detalles, pero aumentan el uso de tokens y la latencia. El parámetro media_resolution determina el número máximo de tokens asignados por imagen de entrada o fotograma de video.
Ahora puedes establecer la resolución en media_resolution_low, media_resolution_medium o media_resolution_high por cada parte multimedia individual o globalmente (a través de generation_config). Si no se especifica, el modelo utiliza los valores predeterminados óptimos según el tipo de medio.
Gemini 3 admite incrustaciones multimodales en:
- imágenes
- audio
- fotogramas de video
- documentos
Ejemplo para subir una imagen (base64):
curl "https://generativelanguage.googleapis.com/v1alpha/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [
{ "text": "¿Qué hay en esta imagen?" },
{
"inlineData": {
"mimeType": "image/jpeg",
"data": "..."
},
"mediaResolution": {
"level": "media_resolution_high"
}
}
]
}]
}'Pruebas y depuración con Apidog
Si bien los comandos curl son excelentes para pruebas rápidas, se vuelven engorrosos cuando estás desarrollando una aplicación real. Aquí es donde Apidog brilla.
Con Apidog, puedes:
- Guardar tu configuración de API: Configura tu endpoint de Gemini y la clave de API una vez, luego reutilízala en todas tus pruebas.
- Crear plantillas de solicitud: Guarda diferentes tipos de prompts (iniciadores de conversación, solicitudes de análisis, escritura creativa) como plantillas.
- Probar modos de pensamiento lado a lado: Cambia fácilmente entre los modos de Pensamiento Bajo y Alto para comparar respuestas y rendimiento.
- Gestionar el historial de conversaciones: Utiliza las variables de entorno de Apidog para mantener el contexto de la conversación en múltiples solicitudes.
- Automatizar pruebas: Crea suites de prueba que verifiquen que tu integración de Gemini funciona correctamente.
Así es como podrías configurar una solicitud Gemini en Apidog:
- Crea una nueva solicitud POST a:
https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash:generateContent?key={{api_key}} - Configura una variable de entorno
api_keycon tu clave de API real - En el cuerpo, usa JSON:
{
"contents": [{
"parts": [{
"text": "{{prompt}}"
}]
}],
"generationConfig": {
"temperature": 0.7,
"maxOutputTokens": 800
}
}
4. Establece otra variable de entorno prompt con lo que quieras preguntarle a Gemini
Este enfoque hace que la experimentación sea mucho más rápida y organizada.
Mejores prácticas para la API de Gemini
1. Manejar los errores con elegancia
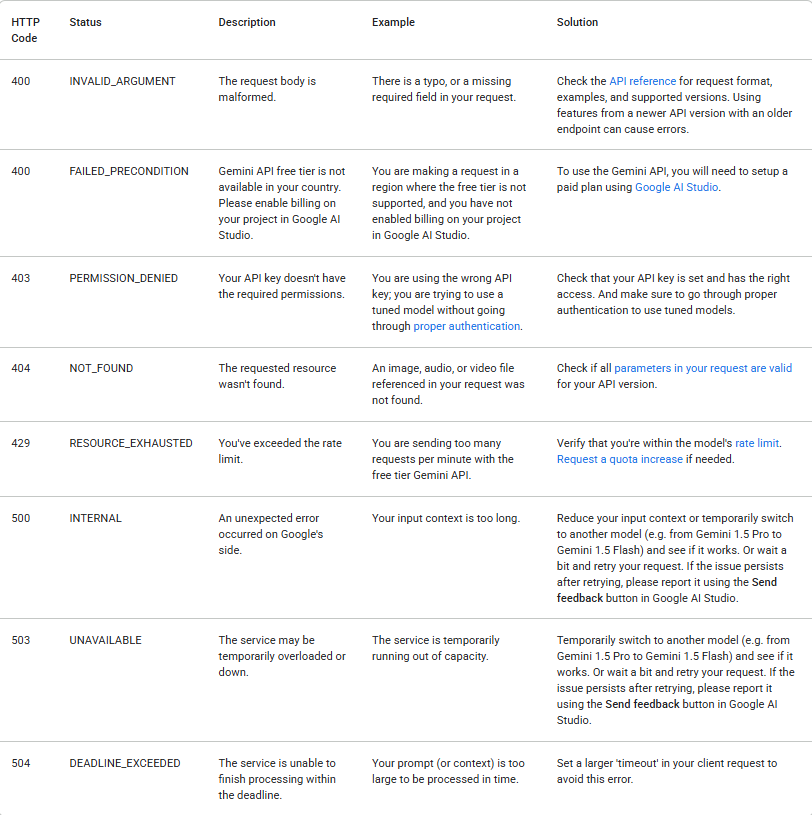
Las llamadas a la API pueden fallar por muchas razones. Siempre verifica el estado de la respuesta y maneja los errores de manera apropiada. La siguiente tabla enumera los códigos de error comunes del backend que puedes encontrar, junto con explicaciones de sus causas y pasos para solucionar problemas:
2. Gestiona tus costos
El uso de la API de Gemini es medido y cuesta dinero (después de los límites del nivel gratuito). Ten en cuenta estos consejos:
- Comienza con el nivel gratuito para experimentar
- Usa el modo de Pensamiento Bajo siempre que sea posible para tareas simples
- Establece límites razonables para
maxOutputTokens - Supervisa tu uso en Google AI Studio
Los tokens pueden ser caracteres individuales como z o palabras completas como gato. Las palabras largas se dividen en varios tokens. El conjunto de todos los tokens utilizados por el modelo se llama vocabulario, y el proceso de dividir el texto en tokens se llama tokenización.
Cuando la facturación está habilitada, el costo de una llamada a la API de Gemini se determina en parte por el número de tokens de entrada y salida, por lo que saber cómo contar los tokens puede ser útil.
3. Elabora mejores prompts
La calidad de tu salida depende en gran medida de tu entrada. Aquí tienes algunos consejos de ingeniería de prompts:
En lugar de: "Escribe sobre perros"
Intenta: "Escribe una entrada de blog educativa de 200 palabras sobre los beneficios de adoptar perros de rescate, con un tono amigable y alentador para posibles dueños de mascotas."
En lugar de: "Arregla este código"
Intenta: "Por favor, depura esta función de Python que debería calcular el factorial pero devuelve resultados incorrectos para la entrada 5. Explica qué está mal y proporciona el código corregido."

4. Elige el modelo correcto
Google ofrece varios modelos Gemini, cada uno con diferentes fortalezas. Verifica que los parámetros de tu modelo estén dentro de los siguientes valores:
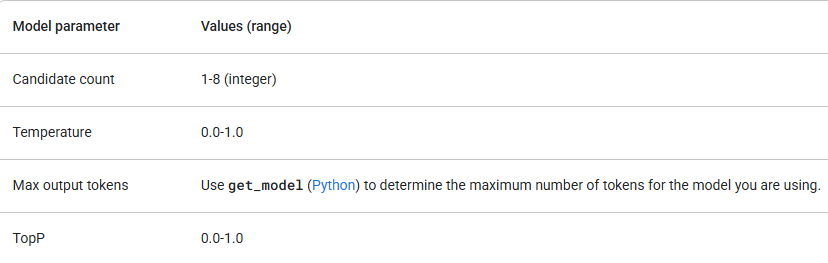
Comienza con gemini-1.5-flash y solo actualiza si necesitas una mayor capacidad de razonamiento. Además de verificar los valores de los parámetros, asegúrate de usar la versión de API correcta (por ejemplo, /v1 o /v1beta) y el modelo que admita las características que necesitas. Por ejemplo, si una característica está en versión Beta, solo estará disponible en la versión de API /v1beta.
Conclusión: Tu viaje en la IA comienza
Ahora tienes todo lo que necesitas para empezar a construir con la API de Google Gemini. Has aprendido a obtener una clave de API, hacer solicitudes básicas, comprender los diferentes modos de pensamiento e incluso has visto algunos ejemplos avanzados.
Recuerda que trabajar con las API de IA es un proceso iterativo. Mejorarás en la creación de prompts y en la elección de la configuración correcta con la práctica. No tengas miedo de experimentar, así es como descubrirás todo el potencial de lo que puedes construir.
El siguiente paso más importante es comenzar a experimentar. Toma los ejemplos de esta guía, modifícalos, rómpelos y mira qué sucede. La mejor manera de aprender es haciendo.
Para los principiantes, recomiendo encarecidamente usar Apidog como su herramienta de prueba de API REST. Te ayuda a:
- depurar solicitudes
- almacenar variables de entorno
- ejecutar colecciones
- comparar rápidamente las salidas del modelo
- compartir tus casos de prueba de API con los miembros del equipo
Y como es gratis, no hay ningún inconveniente.