
Ingenieros y desarrolladores buscan constantemente modelos eficientes que ofrezcan un alto rendimiento sin demandas excesivas de recursos. GLM-4.7-Flash surge como una opción convincente en este panorama. Este modelo Mixture-of-Experts (MoE) 30B-A3B, desarrollado por Zhipu AI (Z.ai), se destaca por su equilibrio entre potencia y eficiencia. Sobresale en los puntos de referencia de codificación, tareas de razonamiento e integración de herramientas, lo que lo hace adecuado para escenarios de implementación local.
Ejecutar GLM-4.7-Flash localmente permite a los usuarios mantener la privacidad de los datos, reducir la latencia y personalizar las integraciones. Herramientas como Ollama, LM Studio y Hugging Face simplifican este proceso.
A medida que avances en esta guía, obtendrás conocimientos prácticos sobre la instalación y el uso. Primero, considera los requisitos fundamentales del sistema.
¿Qué es GLM-4.7-Flash y por qué usarlo localmente?
GLM-4.7-Flash representa un avance en los modelos de lenguaje de código abierto. Construido sobre la arquitectura glm4_moe_lite, utiliza tipos de tensor BF16 y F32 bajo una licencia MIT. El artículo del modelo, "GLM-4.5: Modelos Fundacionales Agénticos, de Razonamiento y Codificación (ARC)", detalla su entrenamiento para el uso de herramientas y el razonamiento, basándose en arXiv:2508.06471.
Las características clave incluyen soporte para inglés y chino, generación de texto y tareas conversacionales. Maneja entradas multimodales como texto, pero se centra en salidas solo de texto. Las limitaciones surgen de su escala; aunque es eficiente, puede que no iguale a modelos más grandes en dominios de nicho sin un ajuste fino. Los detalles de los datos de entrenamiento siguen sin revelarse, pero las evaluaciones confirman su ventaja en escenarios de codificación y agénticos.
Los usuarios optan por ejecuciones locales para evitar los costos de la API. Z.ai ofrece un nivel gratuito para GLM-4.7-Flash a través de su plataforma, pero la implementación local elimina la dependencia de servicios externos. Este enfoque es adecuado para desarrolladores que construyen aplicaciones personalizadas, investigadores que prueban hipótesis o empresas que priorizan la seguridad. Por ejemplo, controlas los niveles de cuantificación para adaptarse a las restricciones de hardware, asegurando un rendimiento óptimo.
Requisitos del Sistema para Ejecutar GLM-4.7-Flash Localmente
El hardware juega un papel crucial en la inferencia del modelo. GLM-4.7-Flash exige al menos 16 GB de memoria del sistema para operaciones básicas, según lo especificado en las directrices de LM Studio. Sin embargo, la aceleración de la GPU mejora significativamente la velocidad.
Para las variantes de Ollama:
- q4_K_M: 19 GB VRAM
- q8_0: 32 GB VRAM
- bf16: 60 GB VRAM
Hugging Face recomienda torch.bfloat16 para mayor eficiencia, lo que requiere GPUs NVIDIA compatibles (arquitecturas Ampere o posteriores). La inferencia solo con CPU funciona, pero se ralentiza considerablemente para contextos grandes.
Los requisitos previos de software incluyen Python 3.8+, pip y Git. Frameworks como Transformers requieren instalaciones adicionales. Asegúrate de que tu sistema operativo sea compatible con CUDA para el uso de GPU; Ubuntu 20.04 o Windows con WSL2 funcionan bien.
Si los recursos son insuficientes, la cuantificación reduce el uso de memoria. Herramientas como llama.cpp o Unsloth ofrecen versiones de 4 bits o 2 bits, reduciendo los requisitos a 15-20 GB de VRAM. Esta flexibilidad permite la implementación en hardware de consumo como la RTX 4090.
Una vez cumplidos los requisitos, explora los métodos de instalación. Comienza con Ollama por su simplicidad.
Cómo Instalar y Usar GLM-4.7-Flash con Ollama
Ollama proporciona una plataforma accesible para ejecutar modelos grandes localmente. Gestiona automáticamente la cuantificación y el servicio de API.
Primero, instala Ollama. Descarga el ejecutable para tu sistema operativo y ejecútalo.

Verifica la instalación con ollama --version, asegurándote de que sea la versión 0.14.3 o posterior, ya que GLM-4.7-Flash lo requiere.

Luego, descarga el modelo: ejecuta ollama pull glm-4.7-flash.

Elige variantes como glm-4.7-flash:q4_K_M para un menor uso de memoria. El comando descarga aproximadamente 19 GB para la versión q4.
Ejecuta el modelo de forma interactiva: escribe ollama run glm-4.7-flash. Ingresa indicaciones como "Generar código Python para una secuencia de Fibonacci". El modelo responde con salidas razonadas, aprovechando sus fortalezas de codificación.
Para acceso programático, usa la API. Envía una solicitud curl:
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role": "user", "content": "Explain quantum computing basics."}]
}'
Esto devuelve JSON con la respuesta. En Python, intégrate con la librería ollama:
from ollama import chat
response = chat(
model='glm-4.7-flash',
messages=[{'role': 'user', 'content': 'Solve this math problem: 2x + 3 = 7'}]
)
print(response['message']['content'])
JavaScript sigue un proceso similar con el paquete npm de ollama.
Personaliza las configuraciones editando Modelfile. Establece la temperatura en 0.7 para salidas deterministas en tareas de codificación. El modo más reciente de Ollama busca publicaciones recientes si es necesario, pero aquí nos centramos en la inferencia local.
Este método es adecuado para configuraciones rápidas. Sin embargo, para una interfaz gráfica, recurre a LM Studio.
Configurando GLM-4.7-Flash en LM Studio
LM Studio ofrece una GUI fácil de usar para la gestión de modelos. Descárgalo e instálalo.
Busca "zai-org/glm-4.7-flash" en el centro de modelos. Selecciona una versión cuantificada —MLX-4bit, 6bit u 8bit— de los repositorios vinculados de Hugging Face. La descarga se completa en la aplicación.
Carga el modelo: navega a la interfaz de chat, selecciona GLM-4.7-Flash y ajusta los parámetros. Habilita el "pensamiento" (por defecto: true) para un razonamiento paso a paso. Establece la temperatura en 1, top_k en 50, top_p en 0.95 y desactiva la penalización por repetición.
Prueba con indicaciones: "Diseña una API REST para autenticación de usuarios". LM Studio muestra las salidas con velocidades de token, lo que ayuda a la optimización del rendimiento.
Los campos personalizados como clear_thinking (por defecto: false) gestionan el historial. Para los modelos MoE, monitorea los expertos activos: A3B significa tres activos por pasada hacia adelante, optimizando la eficiencia.
LM Studio es compatible con enlaces profundos para acceso directo al modelo. Si surgen problemas, verifica la memoria del sistema: un mínimo de 16 GB evita bloqueos.
Esta herramienta es excelente para la experimentación. Para scripts avanzados, intégrala con Hugging Face.
Usando GLM-4.7-Flash con Hugging Face Transformers
Hugging Face proporciona librerías robustas para un control preciso. Instala Transformers desde la rama principal:
pip install git+https://github.com/huggingface/transformers.git
Carga el modelo:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "zai-org/GLM-4.7-Flash"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto"
)
Prepara las entradas:
messages = [{"role": "user", "content": "Write a function to sort an array."}]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
Generar:
generated_ids = model.generate(**inputs, max_new_tokens=512, do_sample=False)
output = tokenizer.decode(generated_ids[0][inputs['input_ids'].shape[1]:])
print(output)
Esta configuración admite la cuantificación a través de bitsandbytes para una VRAM más baja. Añade load_in_4bit=True al cargar el modelo.
Para el servicio, usa vLLM o SGLang. Instala vLLM:
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
Ejecuta un servidor:
python -m vllm.entrypoints.openai.api_server --model zai-org/GLM-4.7-Flash
Accede a través de endpoints compatibles con OpenAI. SGLang requiere instalación desde el código fuente y sigue pasos similares.
Estos frameworks permiten implementaciones de grado de producción. Ahora, considera las pruebas de API con Apidog.
Integrando Apidog para Pruebas de API con GLM-4.7-Flash Local
Una vez que sirvas GLM-4.7-Flash a través de Ollama o vLLM, prueba los endpoints de manera eficiente. Apidog, una plataforma de API todo en uno, facilita esto.
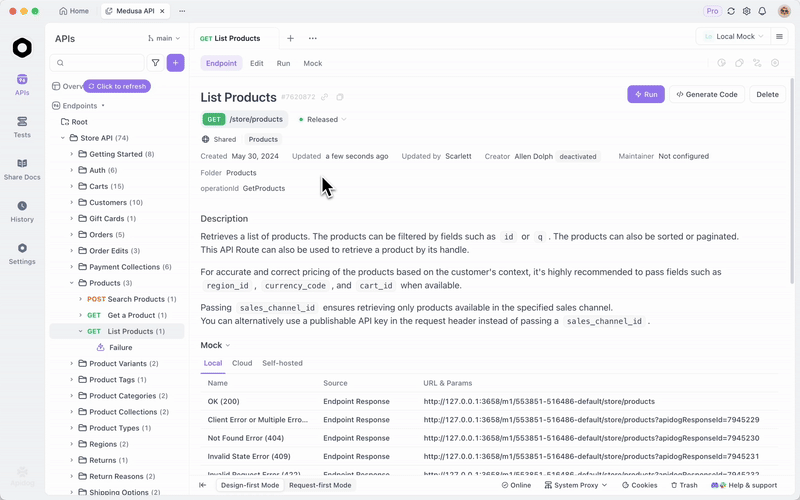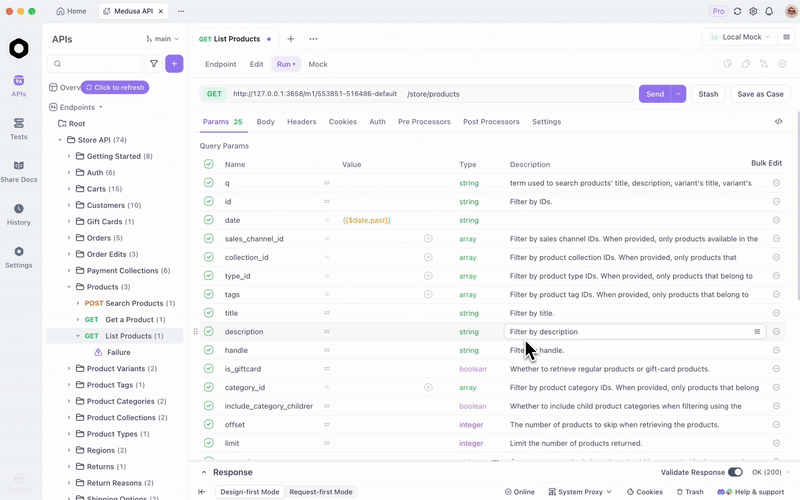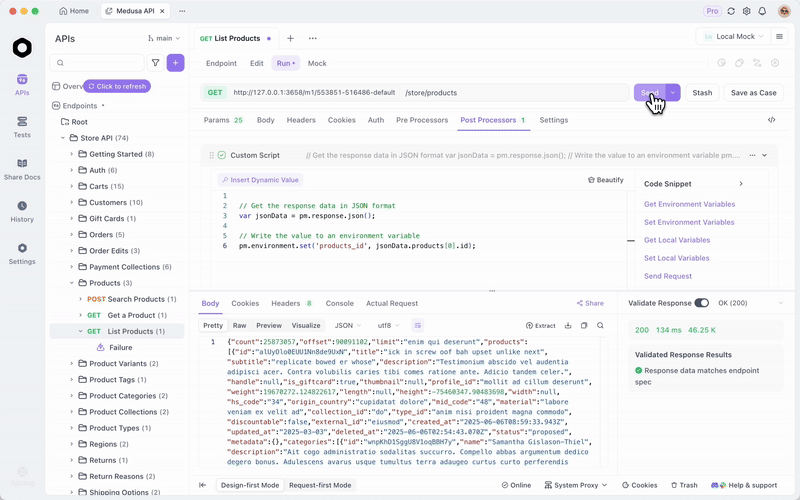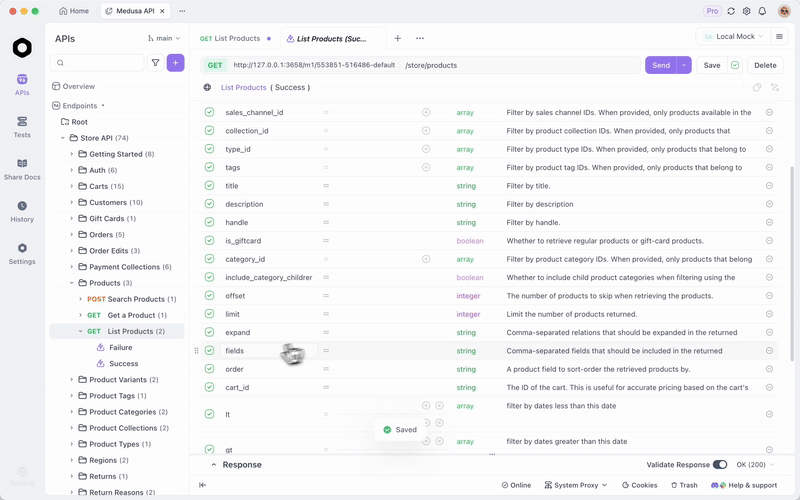
Descarga Apidog gratis. Es compatible con funciones de IA al configurar tu modelo local como proveedor; usa claves de API si corresponde, o endpoints directos.
El servidor MCP de Apidog se integra con IDEs como Cursor, utilizando especificaciones de API para la generación de código. Esto se relaciona con las capacidades de codificación de GLM-4.7-Flash: prueba directamente las salidas agénticas.
Por ejemplo, consulta tu servidor local y valida las respuestas. Esto garantiza la fiabilidad en las aplicaciones.
Partiendo de lo básico, avanza a la optimización.
Consejos Avanzados para Optimizar el Rendimiento de GLM-4.7-Flash
Ajusta los parámetros para las tareas. Establece la temperatura en 0.7 para codificación, 1.0 para escritura creativa. Usa top_p 0.95 para equilibrar la diversidad.
Cuantifica aún más con formatos GGUF a través de llama.cpp. Compila llama.cpp con CUDA, luego convierte:
./llama-gguf-split --model GLM-4.7-Flash.gguf
Ejecuta con --jinja para soporte de plantillas.
Maneja contextos largos: Divide las entradas si exceden los 128K. Habilita el "pensamiento" para consultas complejas.
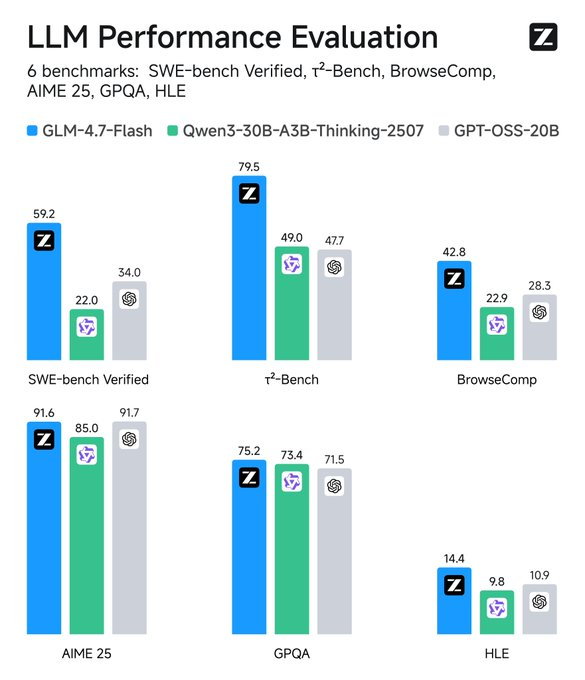
Monitorea métricas: Herramientas como TensorBoard rastrean la latencia. Compara con las líneas de base: GLM-4.7-Flash supera a sus pares en SWE-bench por 37.2 puntos.
Integra herramientas: Añade la llamada a funciones en los prompts para un comportamiento agéntico.
Seguridad: Ejecuta en entornos aislados para prevenir fugas de datos.
Estas estrategias maximizan la utilidad. Reflexiona sobre las aplicaciones a continuación.
Solución de Problemas Comunes
¿Encuentras errores de falta de memoria? Reduce el tamaño del lote o cuantifica a un nivel inferior.
¿Inferencia lenta? Actualiza la GPU o usa frameworks más rápidos como vLLM.
¿Problemas de compatibilidad? Actualiza Transformers a la rama principal.
Si Ollama falla, verifica la disponibilidad del puerto 11434.
¿LM Studio se bloquea? Verifica la integridad del modelo.
Aborda estos problemas de forma proactiva.
Conclusión: Potencia tu Flujo de Trabajo con GLM-4.7-Flash
Ejecutar GLM-4.7-Flash localmente desbloquea potentes capacidades de IA. Desde la facilidad de Ollama hasta la flexibilidad de Hugging Face, las opciones abundan. Incorpora Apidog para una gestión de API sin interrupciones; descárgalo gratis para elevar tu configuración.
A medida que la tecnología evoluciona, modelos como este unen rendimiento y accesibilidad. Implementa estos pasos y lograrás implementaciones de IA eficientes y privadas. Pequeños ajustes en los parámetros o herramientas producen mejoras significativas, transformando tareas rutinarias en procesos optimizados.