
Los desarrolladores que crean aplicaciones inteligentes demandan cada vez más modelos que manejen diversos tipos de datos sin comprometer la velocidad ni la precisión. GLM-4.6V aborda esta necesidad directamente. Z.ai lanza esta serie como un modelo de lenguaje grande multimodal de código abierto, que combina texto, imágenes, videos y archivos en interacciones fluidas. La API le permite integrar estas capacidades directamente en sus proyectos, ya sea para análisis de documentos o agentes de búsqueda visual.
A medida que examinemos la arquitectura, los métodos de acceso y los precios de GLM-4.6V, verá cómo supera a sus pares en los benchmarks. Además, los consejos de integración con herramientas como Apidog le ayudarán a implementar más rápido. Comencemos con el diseño central del modelo.
Entendiendo GLM-4.6V: Arquitectura y Capacidades Centrales
Z.ai diseña GLM-4.6V para procesar entradas multimodales de forma nativa, generando respuestas de texto estructuradas. Esta serie de modelos incluye dos variantes: el buque insignia GLM-4.6V (106B parámetros) para tareas de alto rendimiento y GLM-4.6V-Flash (9B parámetros) para implementaciones locales eficientes. Ambos soportan una ventana de contexto de 128K tokens, lo que permite el análisis de documentos extensos —hasta 150 páginas— o videos de una hora en una sola pasada.

En su esencia, GLM-4.6V incorpora un codificador visual alineado con protocolos de contexto largo. Esta alineación asegura que el modelo retenga detalles finos en todas las entradas. Por ejemplo, maneja secuencias de texto e imágenes intercaladas, basando las respuestas en elementos visuales específicos como las coordenadas de objetos en fotos. La llamada a funciones nativa lo distingue; los desarrolladores invocan herramientas directamente con parámetros de imagen, y el modelo interpreta los bucles de retroalimentación visual.
Además, el aprendizaje por refuerzo refina la invocación de herramientas. El modelo aprende a encadenar acciones, como consultar una herramienta de búsqueda con una captura de pantalla y razonar sobre los resultados. Esto da como resultado flujos de trabajo de extremo a extremo, desde la percepción hasta la toma de decisiones. En consecuencia, las aplicaciones ganan autonomía sin un procesamiento posterior frágil.

En la práctica, estas características se traducen en un manejo robusto de datos del mundo real. El modelo sobresale en la creación de texto enriquecido, generando salidas intercaladas de imagen-texto para informes o infografías. También es compatible con el Protocolo de Contexto de Modelo Extendido (MCP), lo que permite entradas multimodales basadas en URL para un procesamiento escalable.
Benchmarks y Rendimiento: Midiendo GLM-4.6V frente a sus Pares
Los datos cuantitativos validan la ventaja de GLM-4.6V. En MMBench, obtiene un 82.5% en QA multimodal, superando a LLaVA-1.6 por 4 puntos. MathVista revela un 68% de precisión en ecuaciones visuales, gracias a codificadores alineados.
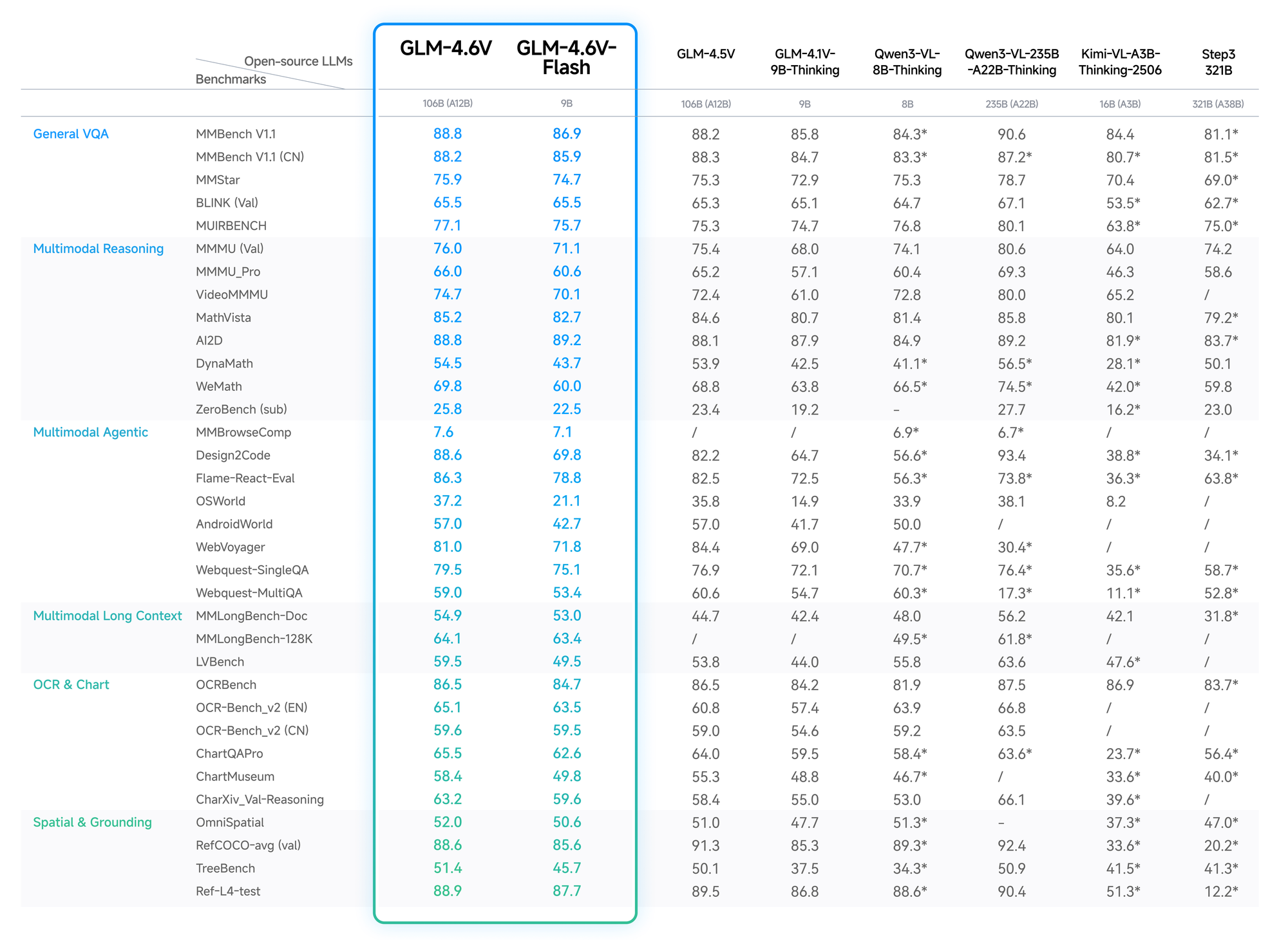
Las pruebas de OCRBench arrojan un 91% para la extracción de texto de imágenes distorsionadas, superando a GPT-4V en las clasificaciones de código abierto. Las evaluaciones de contexto largo, como Video-MME, alcanzan el 75% para clips de una hora, reteniendo detalles a través de los fotogramas.
La variante Flash sacrifica una ligera precisión (caída del 2-3%) por una aceleración de 5x, ideal para aplicaciones en tiempo real. El blog de Z.ai detalla esto, con configuraciones reproducibles en Hugging Face.
Así, los desarrolladores eligen GLM-4.6V por su rendimiento fiable y rentable.
Características Clave de la Serie de Modelos GLM-4.6V
GLM-4.6V incorpora características avanzadas que elevan la IA multimodal. Primero, sus modalidades de entrada cubren texto, imágenes, videos y archivos, con salidas centradas en la generación precisa de texto. Los desarrolladores aprecian la flexibilidad: cargan un PDF financiero y el modelo extrae tablas, razona sobre tendencias y sugiere visualizaciones.
El uso nativo de herramientas representa un gran avance. A diferencia de los modelos tradicionales que requieren orquestación externa, GLM-4.6V incorpora la llamada a funciones. Usted define herramientas en las solicitudes —por ejemplo, un recortador para imágenes— y el modelo pasa los datos visuales como parámetros. Luego comprende los resultados, iterando si es necesario. Esto cierra el ciclo para tareas como la búsqueda visual en la web: reconoce la intención de una imagen de consulta, planifica la recuperación, fusiona los resultados y genera información razonada.
Además, el contexto de 128K permite un análisis de formato largo. Procese 200 diapositivas de una presentación; el modelo resume los temas clave mientras marca los eventos de video, como goles en un partido de fútbol. Para el desarrollo frontend, replica interfaces de usuario a partir de capturas de pantalla, generando código HTML/CSS/JS con precisión de píxeles. Las ediciones en lenguaje natural siguen, refinando prototipos de forma interactiva.
La variante Flash optimiza la latencia. Con 9B parámetros, se ejecuta en hardware de consumo a través de motores de inferencia vLLM o SGLang. Los pesos disponibles en Hugging Face permiten el ajuste fino, aunque la colección se centra en modelos base sin estadísticas extensas aún. En general, estas características posicionan a GLM-4.6V como un pilar versátil para agentes en inteligencia de negocios o herramientas creativas.
Cómo Acceder a la API de GLM-4.6V: Configuración Paso a Paso
Acceder a la API de GLM-4.6V resulta sencillo, gracias a su interfaz compatible con OpenAI. Comience registrándose en el portal de desarrolladores de Z.ai (z.ai). Genere una clave API en el panel de su cuenta; este token Bearer autentica todas las solicitudes.
El endpoint base se encuentra en https://api.z.ai/api/paas/v4/chat/completions. Use el método POST con payloads JSON. Los encabezados de autenticación incluyen Authorization: Bearer <su-clave-api> y Content-Type: application/json. Los arreglos de mensajes estructuran las conversaciones, admitiendo contenido multimodal.
Por ejemplo, envíe una URL de imagen junto con mensajes de texto. El payload especifica "model": "glm-4.6v" o "glm-4.6v-flash". Habilite los pasos de pensamiento con "thinking": {"type": "enabled"} para rastros de razonamiento transparentes. El modo de transmisión agrega "stream": true para respuestas en tiempo real a través de eventos enviados por el servidor.
import requests
import json
url = "https://api.z.ai/api/paas/v4/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
payload = {
"model": "glm-4.6v",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://example.com/image.jpg"}
},
{"type": "text", "text": "Describe the key elements in this image and suggest improvements."}
]
}
],
"thinking": {"type": "enabled"}
}
response = requests.post(url, headers=headers, data=json.dumps(payload))
print(response.json())
Este código obtiene una descripción con justificación. Para videos o archivos, extienda el arreglo de contenido de manera similar; las URL o las codificaciones base64 funcionan. Los límites de tasa se aplican según su plan; supervise a través del panel.
Apidog mejora este proceso. Importe la especificación OpenAPI de la documentación de Z.ai a Apidog, luego simule solicitudes visualmente. Pruebe las llamadas a funciones sin código, validando las cargas antes de la producción. Como resultado, itera más rápido, detectando errores a tiempo.
El acceso local complementa el uso en la nube. Descargue los pesos de la colección GLM-4.6V de Hugging Face y sírvalos a través de marcos compatibles. Esta configuración se adapta a aplicaciones sensibles a la privacidad, aunque exige recursos de GPU para el modelo de 106B.
Desglose de Precios: Escalado Rentable con GLM-4.6V
Z.ai estructura los precios de GLM-4.6V para equilibrar accesibilidad y rendimiento. El modelo insignia cobra $0.6 por millón de tokens de entrada y $0.9 por millón de tokens de salida. Este modelo escalonado considera la complejidad multimodal: las imágenes y videos consumen tokens según la resolución y la duración.
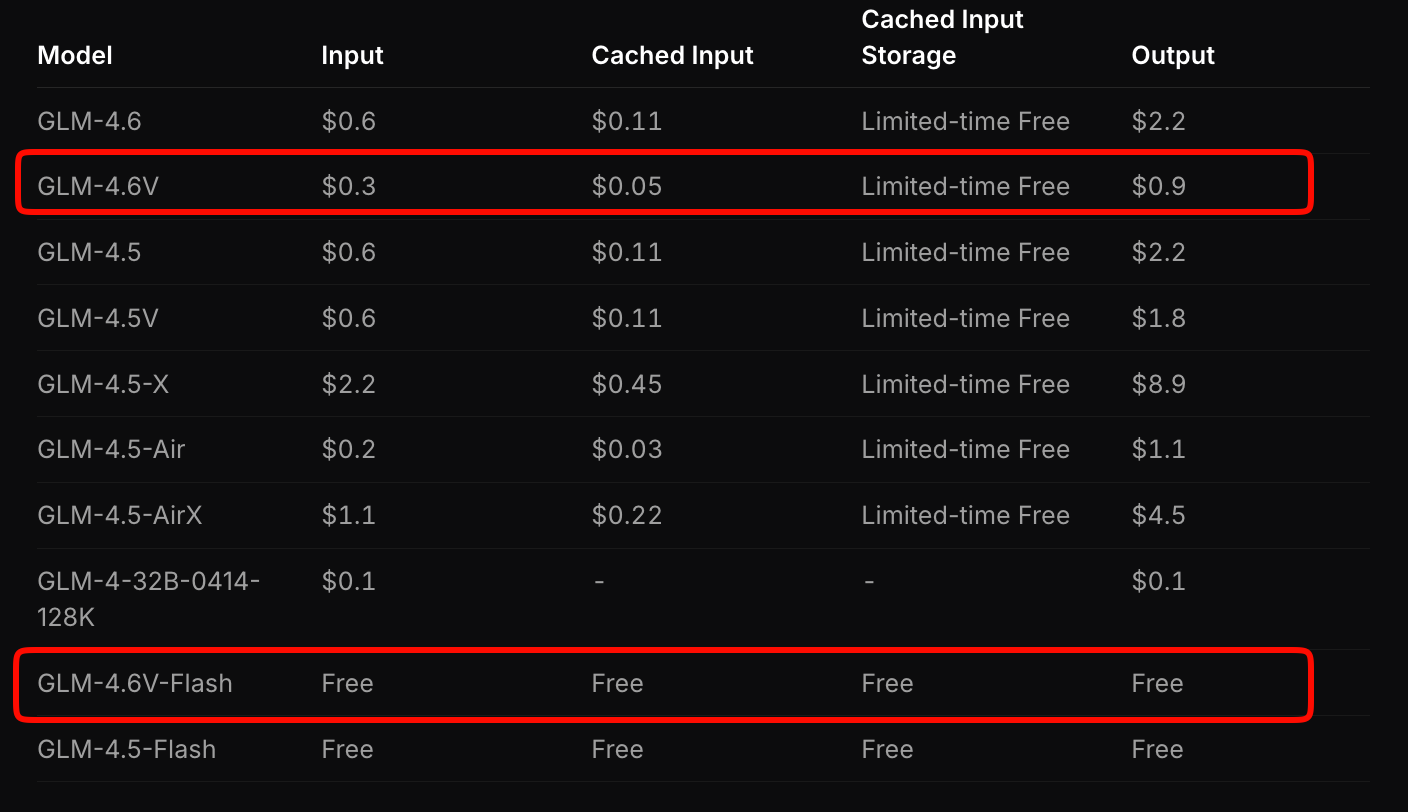
En contraste, GLM-4.6V-Flash ofrece acceso gratuito, ideal para prototipos o implementaciones de borde. No se aplican tarifas de tokens, aunque los costos de inferencia se vinculan a su hardware. Una promoción por tiempo limitado triplica las cuotas de uso a un séptimo del costo para los niveles de pago, lo que hace que la experimentación sea asequible.
Compare esto con la competencia: GLM-4.6V subcotiza APIs multimodales similares en un 20-30% mientras ofrece benchmarks superiores. Para aplicaciones de alto volumen, calcule los costos a través de la herramienta de estimación de Z.ai. Ingrese una carga de trabajo de muestra, digamos, 100 análisis de documentos diarios, y proyectará los gastos mensuales.
Además, los pesos de código abierto mitigan los costos a largo plazo. Realice un ajuste fino en sus datos para reducir la dependencia de las llamadas a la nube. En general, este modelo de precios permite a las startups escalar sin restricciones presupuestarias.
Integrando la API de GLM-4.6V con Apidog: Optimización Práctica del Flujo de Trabajo
Apidog transforma la integración de GLM-4.6V de una tarea manual tediosa a una colaboración eficiente. Como cliente API y herramienta de diseño, importa la especificación de Z.ai, generando automáticamente plantillas de solicitud. Puede arrastrar y soltar payloads multimodales, previsualizar respuestas y exportar fragmentos de código en Python, Node.js o cURL.
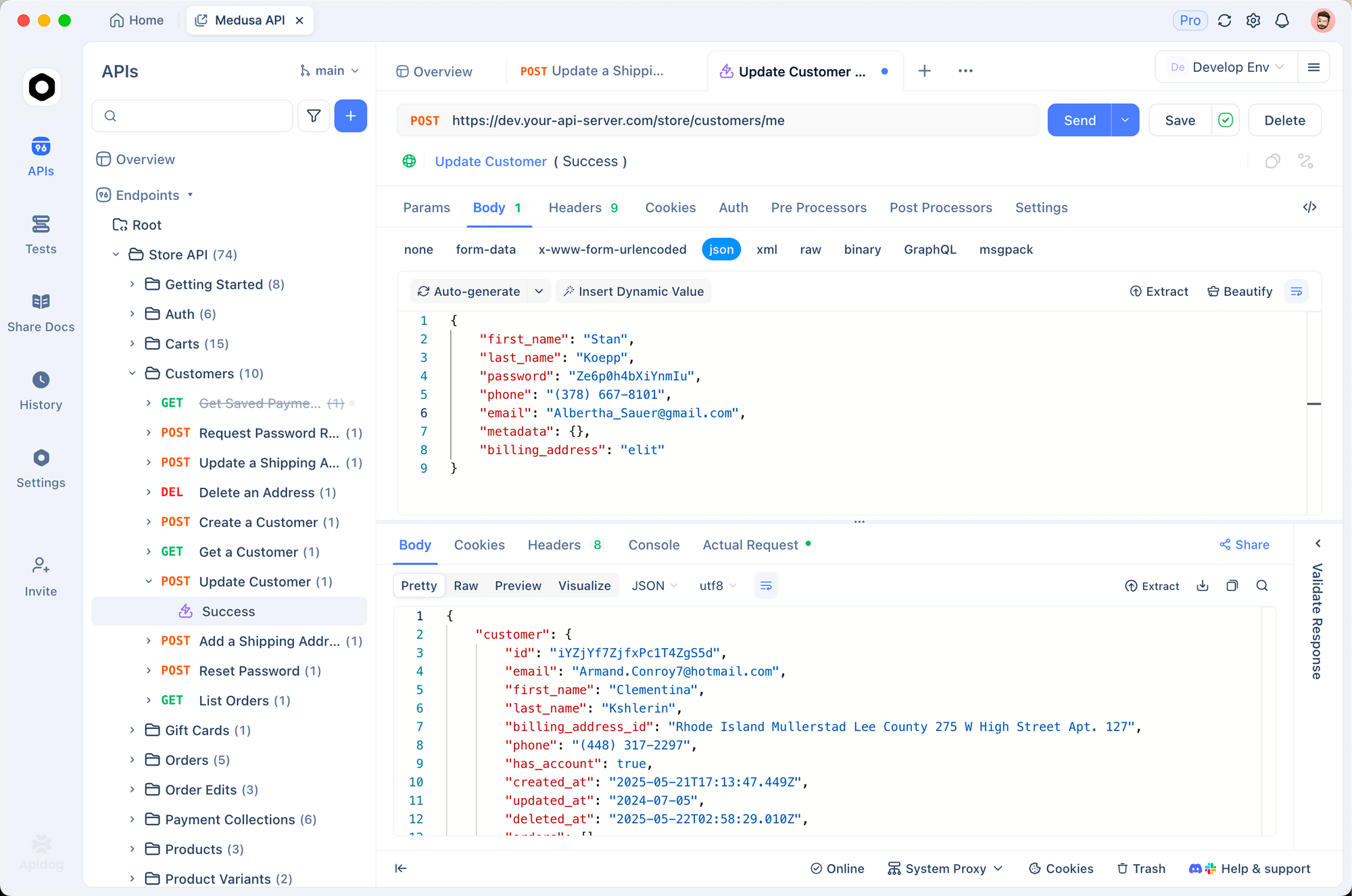
Comience creando un nuevo proyecto en Apidog. Pegue la URL del endpoint y autentíquese con su clave. Para una tarea de fundamentación visual, construya una solicitud: agregue un tipo `image_url`, ingrese la solicitud de coordenadas y presione enviar. Apidog visualiza las salidas, resaltando los pasos de pensamiento.
La colaboración brilla aquí. Comparta colecciones con equipos; controle las versiones de los endpoints a medida que agrega herramientas. Las variables de entorno aseguran las claves en desarrollo, staging y producción. En consecuencia, los ciclos de implementación se acortan: pruebe una cadena completa de agentes en minutos.
Extienda al monitoreo: Apidog registra latencias y errores, identificando cuellos de botella en flujos multimodales. Combínelo con GLM-4.6V-Flash para pruebas locales gratuitas, luego escale a la nube. Los desarrolladores informan un prototipado un 40% más rápido con dichas herramientas.
Casos de Uso en el Mundo Real: Aplicando GLM-4.6V en Producción
GLM-4.6V brilla en industrias con gran cantidad de documentos. Los analistas financieros cargan informes; el modelo analiza gráficos, calcula ratios y genera resúmenes ejecutivos con elementos visuales incrustados. Una firma redujo el tiempo de análisis de horas a minutos, aprovechando el contexto de 128K para informes anuales.
En el comercio electrónico, se activan los agentes de búsqueda visual. Los clientes suben fotos de productos; GLM-4.6V planifica consultas, recupera coincidencias y razona sobre atributos como variantes de color. Esto aumenta la conversión en un 15%, según los primeros adoptantes.

Los equipos de frontend aceleran el prototipado. Ingrese una captura de pantalla; reciba código editable. Itere con indicaciones como "Agregar una barra de navegación adaptable". La fidelidad a nivel de píxel del modelo minimiza las revisiones, reduciendo a la mitad el tiempo de diseño a implementación.

Las plataformas de video se benefician del razonamiento temporal. Resuma conferencias con marcas de tiempo o detecte eventos en feeds de vigilancia. El uso nativo de herramientas se integra con bases de datos, marcando anomalías automáticamente.
Estos casos demuestran la versatilidad de GLM-4.6V. Sin embargo, el éxito depende de la ingeniería de prompts, es decir, de elaborar instrucciones claras para maximizar la precisión.
Desafíos y Mejores Prácticas para el Uso de la API de GLM-4.6V
A pesar de sus fortalezas, los modelos multimodales enfrentan obstáculos. Las entradas de alta resolución inflan el recuento de tokens, aumentando los costos; comprima las imágenes a 512x512 píxeles primero. El desbordamiento de contexto corre el riesgo de alucinaciones; divida los videos largos en segmentos.
Las mejores prácticas mitigan estos problemas. Use el modo de pensamiento para depurar; expone los pasos intermedios. Valide las salidas de las herramientas con aserciones en su código. Para los usuarios de Apidog, configure pruebas automatizadas en los endpoints para hacer cumplir los esquemas.
Monitoree de cerca las cuotas: Flash gratuito evita sorpresas, pero los niveles de pago necesitan presupuestación. Finalmente, ajuste el modelo con datos de dominio a través de pesos abiertos para aumentar la especificidad.
Conclusión: Eleve sus Proyectos con GLM-4.6V Hoy
GLM-4.6V redefine la IA multimodal a través de herramientas nativas, vasto contexto y accesibilidad abierta. Su API, con un precio competitivo de $0.6/M de entrada para el modelo completo y gratuita para Flash, se integra sin problemas con plataformas como Apidog. Desde agentes de documentos hasta generadores de interfaz de usuario, impulsa la innovación.
Implemente estos conocimientos ahora: obtenga su clave API, pruebe en Apidog y construya. El futuro de la IA favorece a quienes aprovechan estas capacidades tempranamente. ¿Qué aplicación transformará a continuación?