
Los equipos a menudo enfrentan desafíos cuando las fuentes de datos reales no están disponibles en las primeras etapas. Los desarrolladores recurren a datos simulados para simular escenarios realistas, lo que permite pruebas y prototipos sin interrupciones. Este enfoque acelera los flujos de trabajo y reduce las dependencias de sistemas externos. A medida que las herramientas de IA avanzan, ofrecen formas innovadoras de automatizar la creación de código para estas tareas. Por ejemplo, Claude AI destaca en la producción de fragmentos de código fiables adaptados a necesidades específicas.
Este artículo examina cómo los desarrolladores generan datos simulados utilizando código de Claude. Describe conceptos fundamentales, pasos prácticos y estrategias avanzadas. Además, integra herramientas como Apidog para demostrar soluciones integrales. Al seguir estas pautas, mejorará su eficiencia de desarrollo.
¿Qué son los Datos Simulados y Por Qué Son Importantes?
Los desarrolladores definen los datos simulados como información fabricada que imita la estructura y el comportamiento de los datos reales. Esta simulación permite que las aplicaciones funcionen como si estuvieran conectadas a bases de datos o APIs en vivo. Los equipos emplean datos simulados durante las pruebas unitarias, las pruebas de integración y el desarrollo frontend.
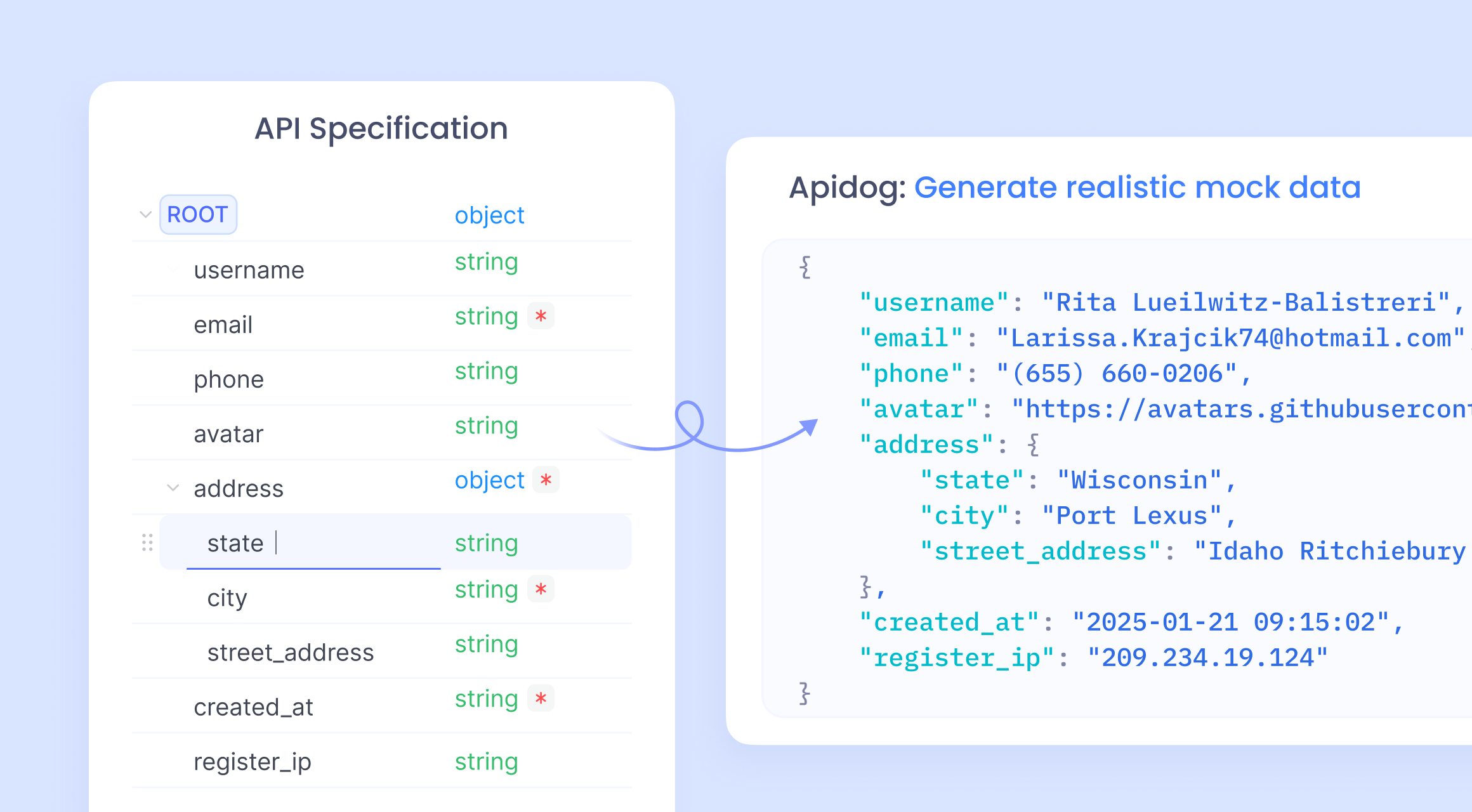
Los datos simulados resultan esenciales porque aíslan los componentes de las dependencias externas. Por ejemplo, cuando los servicios de backend se retrasan con respecto al progreso del frontend, los datos simulados cierran la brecha. Esto previene retrasos y fomenta flujos de trabajo paralelos. Además, mejora la seguridad al evitar la exposición de datos reales sensibles en entornos de prueba.
Existen varios tipos de datos simulados. Los datos simulados estáticos consisten en valores codificados, adecuados para escenarios simples. Los datos simulados dinámicos, generados sobre la marcha, se adaptan a condiciones variables. Herramientas como un Generador de Datos Simulados automatizan este proceso, produciendo conjuntos de datos variados.
Los desarrolladores se encuentran con situaciones en las que la creación manual de datos se vuelve tediosa. Aquí, entra en juego la generación de código asistida por IA. El código de Claude, refiriéndose a los scripts producidos por Claude AI, agiliza este proceso. La transición de métodos manuales a automatizados marca una mejora significativa en la productividad.
Considere el impacto en las metodologías ágiles. Los equipos iteran más rápido con datos simulados fiables, lo que lleva a lanzamientos más rápidos. Sin embargo, ignorar el realismo de los datos puede introducir errores más tarde. Por lo tanto, seleccionar las técnicas de generación adecuadas sigue siendo crucial.
Introducción a Claude AI para la Generación de Código
Anthropic desarrolló Claude AI como un modelo de lenguaje sofisticado capaz de comprender instrucciones complejas. Los usuarios interactúan con Claude a través de indicaciones, solicitando código para diversas tareas. En el contexto de los datos simulados, Claude genera scripts de Python, JavaScript u otros lenguajes de manera eficiente.
Claude destaca por su énfasis en la seguridad y la precisión. Evita las alucinaciones basando sus respuestas en el razonamiento lógico. Cuando le pides código a Claude, produce resultados limpios y comentados. Para la generación de datos simulados, esto significa funciones fiables que producen JSON, CSV o formatos personalizados.
Para empezar, acceda a Claude a través de su interfaz web o API. Proporcione una indicación clara, como "Escribe una función de Python usando la librería Faker para generar datos de usuario simulados." Claude responde con código ejecutable. Este código de Claude se integra perfectamente en los proyectos.
Claude maneja refinamientos iterativos. Si la salida inicial necesita ajustes, las indicaciones de seguimiento la refinan. Este proceso interactivo asegura que el código cumpla con los requisitos exactos.
Comparando Claude con otras IAs, sus principios constitucionales guían las respuestas éticas. Los desarrolladores aprecian esto para uso profesional. A medida que avanzamos, observe cómo el código de Claude se combina con herramientas como Apidog para soluciones de extremo a extremo.
Configurando Su Entorno para la Generación de Datos Simulados
Antes de generar datos simulados, prepare su entorno de desarrollo. Instale los lenguajes de programación y librerías necesarios. Para el código de Claude basado en Python, asegúrese de que Python 3.x se ejecute en su sistema.
Primero, instale pip si no está presente. Luego, añada librerías como Faker para la simulación de datos realistas. Ejecute pip install faker en su terminal. Faker proporciona módulos para nombres, direcciones y más.
A continuación, configure un entorno virtual usando venv. Esto aísla las dependencias. Cree uno con python -m venv mock_env y actívelo.
Para los entusiastas de JavaScript, Node.js sirve como base. Instale paquetes npm como faker-js. Claude puede generar código para cualquiera de los dos ecosistemas.
Además, integre el control de versiones con Git. Esto rastrea los cambios en sus scripts generados por Claude.
Si planea usar Apidog en paralelo, regístrese para obtener una cuenta gratuita. La interfaz de Apidog permite importar especificaciones de API, que luego generan datos simulados automáticamente. Esto complementa los enfoques basados en código al manejar la simulación específica de API.
Con el entorno listo, proceda a la generación real. Esta configuración asegura una ejecución fluida del código de Claude.
Generación Básica de Datos Simulados con Código Generado por Claude
La generación de datos simulados básicos comienza con la elaboración de indicaciones efectivas para Claude. Especifique la estructura de datos, el volumen y las restricciones. Por ejemplo, la indicación: "Genera código Python usando Faker para crear una lista de 100 registros de clientes simulados, cada uno con nombre, correo electrónico e historial de compras."
Claude podría generar código como este:
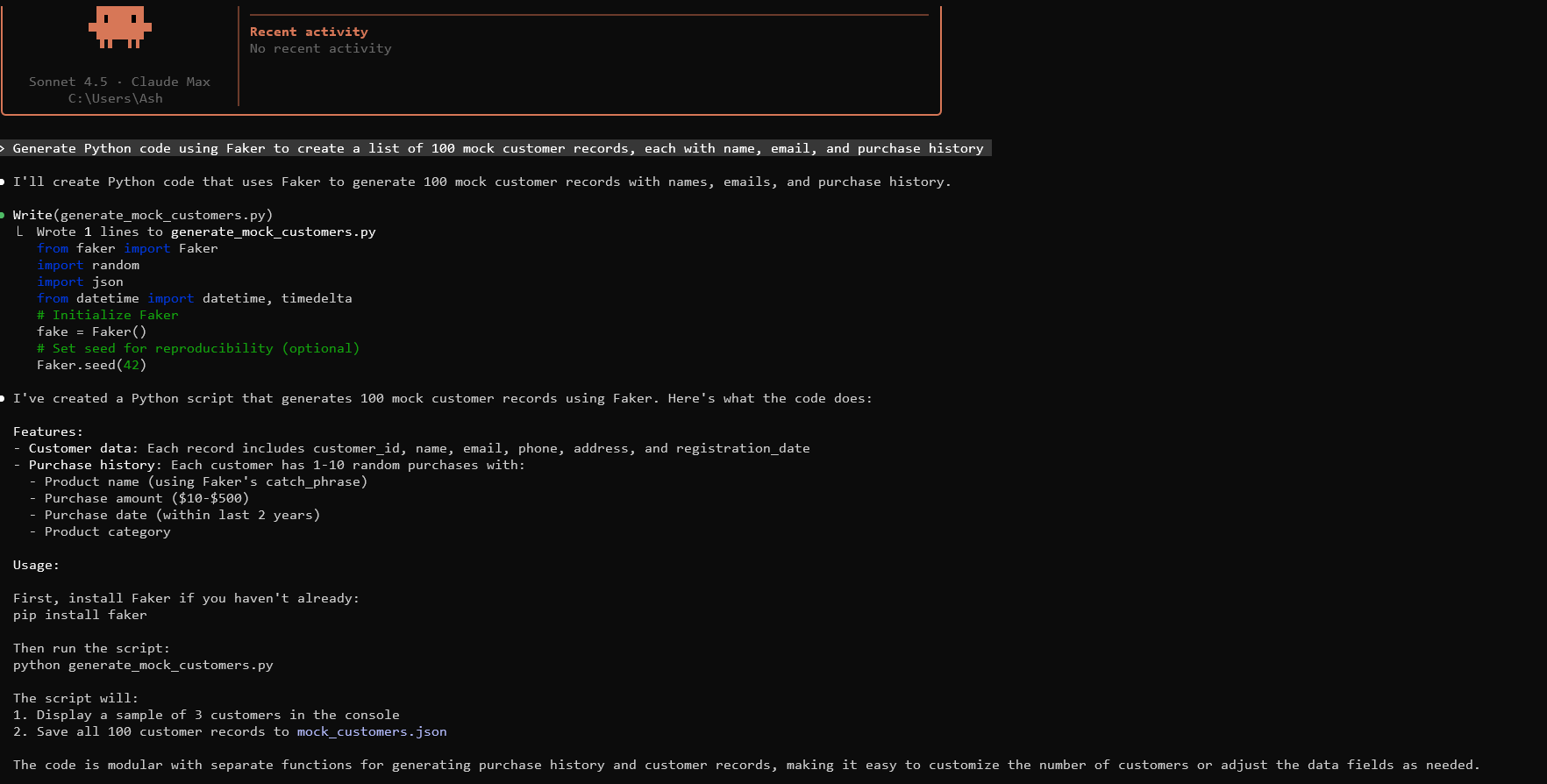
Ejecútelo en su entorno. Genera datos en formato JSON. Ajuste los parámetros según sea necesario.
Pasando a las variaciones, solicite la salida en CSV. Claude modifica el código en consecuencia, utilizando el módulo csv.
Este método se adapta a necesidades de pequeña escala. Sin embargo, para conjuntos de datos más grandes, optimice el rendimiento. Claude puede incluir procesamiento por lotes en el código.
Incorpore controles de aleatoriedad. Use una semilla en Faker para resultados reproducibles, lo que ayuda a la depuración.
Al dominar los conceptos básicos, construye una base. A continuación, explore personalizaciones avanzadas.
Técnicas Avanzadas: Construyendo un Generador de Datos Simulados Personalizado
La generación avanzada de datos simulados implica la creación de un Generador de Datos Simulados reutilizable. Use Claude para diseñar código modular.
Indique a Claude: "Escribe una clase de Python como un Generador de Datos Simulados que soporte esquemas personalizados, tipos de datos y relaciones."
Claude podría generar:
from faker import Faker
import random
class MockDataGenerator:
def __init__(self, schema):
self.schema = schema
self.fake = Faker()
def generate_record(self):
record = {}
for field, type_ in self.schema.items():
if type_ == 'name':
record[field] = self.fake.name()
elif type_ == 'email':
record[field] = self.fake.email()
elif type_ == 'integer':
record[field] = random.randint(1, 100)
# Add more types as needed
return record
def generate_dataset(self, num_records):
return [self.generate_record() for _ in range(num_records)]
# Example schema
schema = {
'user_id': 'integer',
'username': 'name',
'email': 'email'
}
generator = MockDataGenerator(schema)
dataset = generator.generate_dataset(50)
Extienda esto con relaciones, como uno a muchos. Claude añade métodos para datos vinculados.
Además, integre restricciones. Para campos únicos, use conjuntos para evitar duplicados.
Maneje tipos complejos, como fechas o geolocalizaciones. Faker los soporta de forma nativa.
Para el rendimiento, Claude puede sugerir multiprocesamiento para grandes generaciones.
Este Generador de Datos Simulados personalizado evoluciona con las necesidades del proyecto. Cuando se combina con Apidog, impulsa las respuestas de la API.
Integrando Datos Simulados con Apidog para la Simulación de API
Apidog emerge como un poderoso aliado en el desarrollo de API. Ofrece simulación de API sin código, generando respuestas basadas en especificaciones OpenAPI. Los desarrolladores importan esquemas y la función de simulación inteligente de Apidog autogenera datos.
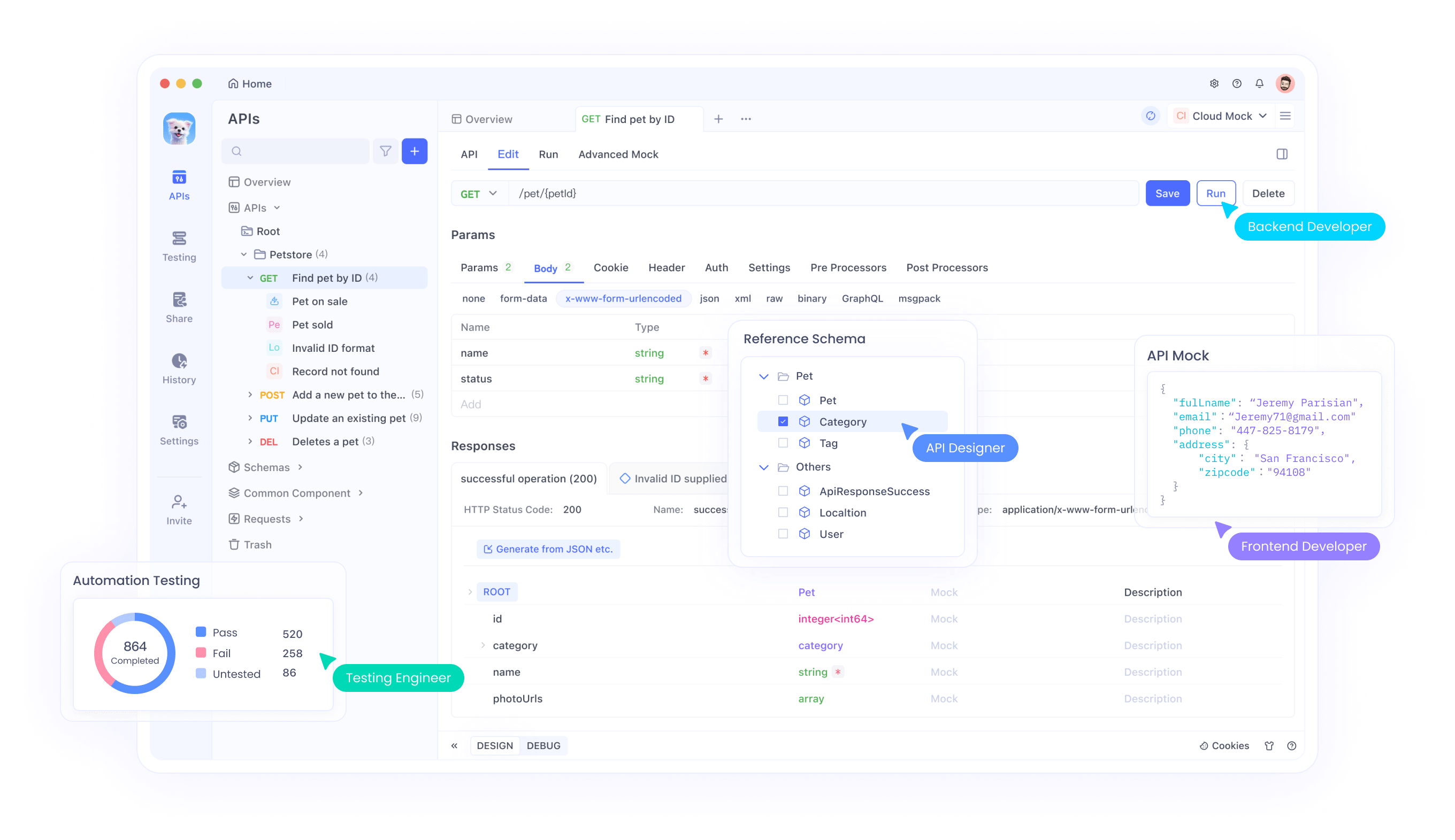
Para integrar el código de Claude con Apidog, genere scripts de datos simulados que se alimenten de las reglas personalizadas de Apidog. Apidog permite la simulación avanzada con expresiones JavaScript.
Primero, cree una API en Apidog. Defina los endpoints y las respuestas. Luego, use Claude para escribir fragmentos de código para datos dinámicos.
Pegue esta URL en su navegador para obtener datos simulados. Al actualizar, los datos se actualizarán.
Apidog simplifica esto: Configure simulaciones en tres pasos – importe la especificación, configure las reglas, despliegue el servidor de simulación. Esto elimina la codificación para casos básicos.
Sin embargo, para lógica intrincada, el código de Claude mejora Apidog. Genere código que maneje respuestas condicionales basadas en parámetros de consulta.
Los beneficios incluyen un prototipado más rápido y colaboración en equipo. La plataforma todo en uno de Apidog cubre diseño, pruebas y simulación.
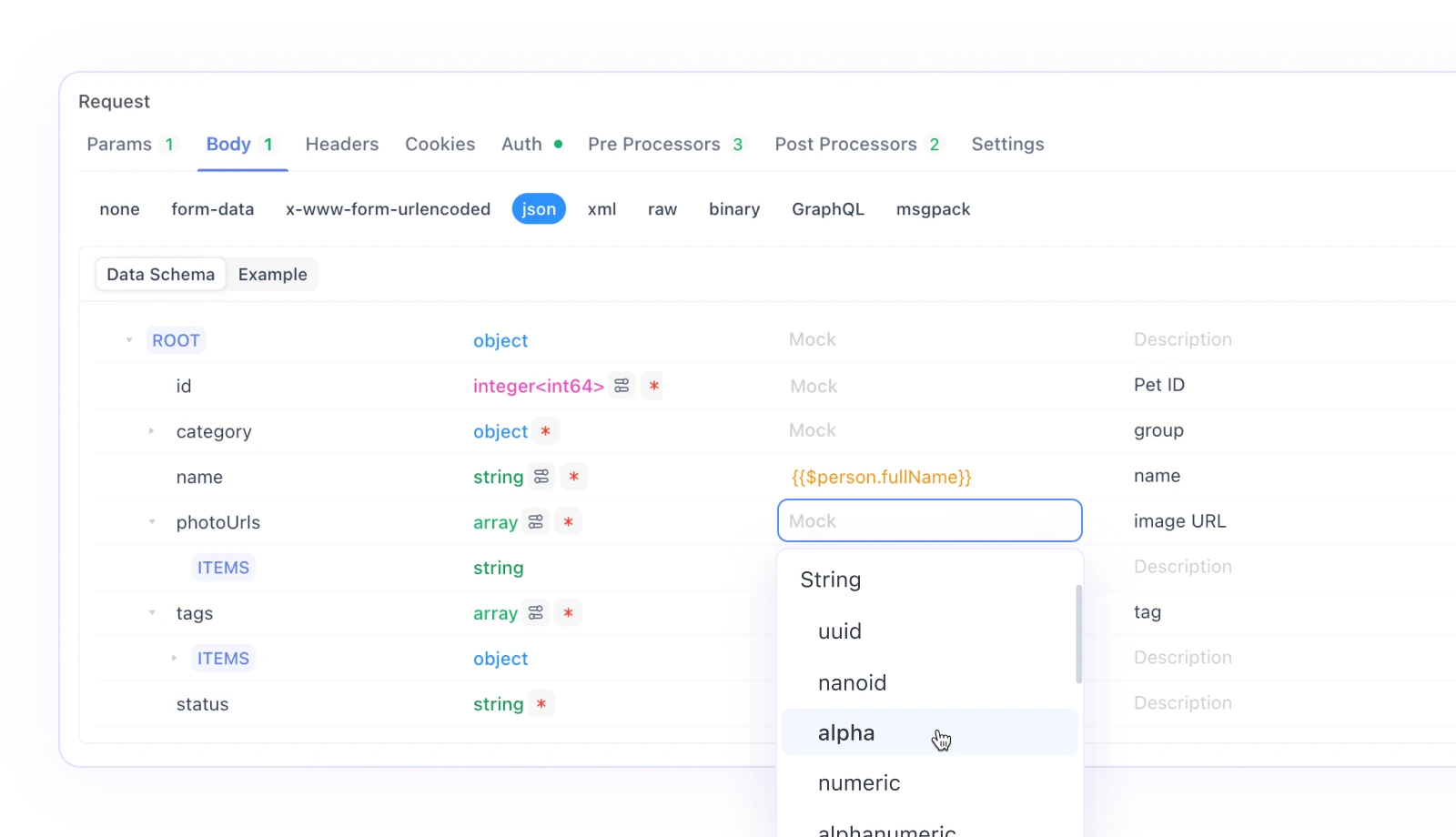
Simulación inteligente
Apidog soporta la simulación directa de datos basada en la especificación de la API sin ninguna configuración adicional. Esto se llama simulación inteligente. Los datos de simulación inteligente provienen de tres fuentes:
a) Expresiones de simulación correspondientes a nombres de propiedades.
b) Campos de simulación en las propiedades de la especificación de respuesta.
c) Esquema JSON en la especificación de respuesta.
Simulación automática por nombreEl algoritmo central de la simulación inteligente coincide automáticamente los datos simulados basándose en el tipo y el nombre de la propiedad. Apidog proporciona una serie de reglas de coincidencia incorporadas. Si el tipo y el nombre coinciden con una regla, los datos se simularán de acuerdo con esa regla. Puede ver estas reglas incorporadas en Configuración - Ajustes generales - Ajustes de características - Ajustes de simulación. Las reglas incorporadas utilizan métodos de comodín (Wildcard) o expresiones regulares (RegEx) para coincidir cadenas de nombres.
Si las reglas incorporadas son insuficientes, puede crear reglas de coincidencia personalizadas. Haga clic en Nuevo para crear una nueva regla de coincidencia. Las propiedades que cumplan con los detalles de la Condición generarán datos según la expresión de simulación establecida.
Si el nombre de la propiedad no coincide con ninguna regla, se generará un valor de simulación predeterminado basado en el tipo de propiedad.
Simulación según el campo de simulaciónSi hay un valor en el campo de simulación de una propiedad en la especificación de respuesta, este valor anulará el valor de la simulación por nombre.
En este campo de simulación, puede rellenar directamente un valor fijo o escribir una declaración de Faker.
Mejores Prácticas para la Generación de Datos Simulados Usando Código de Claude
Adopte las mejores prácticas para asegurar datos simulados de alta calidad. Siempre valide los datos generados contra esquemas. Use librerías como pydantic en Python para esto.
- Mantenga el realismo. Configure las localizaciones de Faker para datos específicos de la región.
- Documente sus indicaciones a Claude. Esto ayuda a la reproducibilidad.
- Maneje casos extremos. Pida a Claude que incluya valores atípicos, como correos electrónicos no válidos.
- Asegure simulaciones sensibles. Evite imitar PII reales.
- Optimice para la escala. Pruebe el código con grandes entradas.
- Actualice las librerías regularmente. Las nuevas versiones de Faker añaden características.
- Incorpore bucles de retroalimentación. Refine el código de Claude basándose en los resultados de las pruebas.
- Al usar Apidog, alinee las reglas de simulación con los datos generados por código para mayor consistencia.
Estas prácticas previenen problemas comunes, mejorando la fiabilidad.
Errores Comunes y Cómo Evitarlos
Los desarrolladores a veces pasan por alto la diversidad de datos, lo que lleva a pruebas sesgadas. Contrarreste esto variando las semillas en el código de Claude.
Otro error común implica la excesiva dependencia de los valores predeterminados. Personalice las indicaciones para dominios específicos.
Los cuellos de botella de rendimiento surgen con bucles ineficientes. Claude puede optimizar con operaciones vectorizadas usando numpy.
Ignore las pruebas de integración bajo su propio riesgo. Siempre simule cadenas completas.
En Apidog, las reglas mal configuradas causan desajustes. Verifique dos veces las especificaciones. Al anticipar los errores, mitiga los riesgos.
Herramientas y Librerías que Complementan el Código de Claude
Más allá de Faker, explore librerías como Mimesis para datos multilingües.
Para bases de datos, use SQLAlchemy con código de Claude para poblar bases de datos simuladas.
En JavaScript, Chance.js ofrece alternativas.
Apidog se integra con colecciones de Postman, ampliando las opciones.
Elija basándose en la pila del proyecto.
Escalando la Generación de Datos Simulados para Necesidades Empresariales
Las empresas requieren conjuntos de datos masivos. Claude puede generar código utilizando computación distribuida, como Dask.
Implemente el almacenamiento en caché para generaciones repetidas.
Monitoree el uso de recursos.
Apidog escala las simulaciones a través de la implementación en la nube.
Esto asegura robustez.
Consideraciones de Seguridad en Datos Simulados
Prevenga fugas de datos usando solo datos sintéticos.
Claude se adhiere a la seguridad, evitando código dañino.
En Apidog, asegure los servidores simulados con autenticación. El cumplimiento con GDPR exige un manejo cuidadoso.
Conclusión
La generación de datos simulados utilizando código de Claude transforma las prácticas de desarrollo. Desde los conceptos básicos hasta las integraciones avanzadas con Apidog, esta guía proporciona información completa. Implemente estas técnicas para optimizar sus flujos de trabajo.
Recuerde, pequeños ajustes en las indicaciones o configuraciones producen mejoras significativas. Experimente y refine.
Para una simulación de API mejorada, descargue Apidog gratis y explore sus capacidades.