
Los desarrolladores buscan constantemente formas eficientes de integrar modelos avanzados de IA en aplicaciones. La API de Gemini 3 Flash ofrece una opción potente que equilibra una alta inteligencia con velocidad y rentabilidad.
Google continúa avanzando en sus ofertas de IA generativa. Además, el modelo Gemini 3 Flash destaca en la línea actual. Los ingenieros acceden a él a través de la API de Gemini, lo que permite un prototipado rápido y la implementación en producción.
Obteniendo tu Clave de API de Gemini
Comienzas adquiriendo una clave de API. Primero, navega a Google AI Studio en aistudio.google.com. Inicia sesión con tu cuenta de Google si es necesario. A continuación, selecciona el modelo de vista previa Gemini 3 Flash de las opciones disponibles. Luego, haz clic en la opción para generar una clave de API.
Google proporciona esta clave al instante. Además, guárdala de forma segura; trátala como credenciales sensibles. La utilizas en el encabezado x-goog-api-key para todas las solicitudes. Alternativamente, configúrala como una variable de entorno para mayor comodidad en los scripts.
Sin una clave válida, las solicitudes fallarán inmediatamente con errores de autenticación. Por lo tanto, verifica la funcionalidad de la clave temprano probando en la interfaz interactiva de Google AI Studio.
Comprendiendo las Capacidades de Gemini 3 Flash
Gemini 3 Flash ofrece inteligencia de nivel Pro a velocidades Flash. Específicamente, la ID del modelo sigue siendo gemini-3-flash-preview durante su fase de vista previa. Soporta una ventana de contexto de entrada masiva de 1,048,576 tokens y un límite de salida de 65,536 tokens.
Además, maneja las entradas multimodales de manera efectiva. Proporcionas texto, imágenes, videos, audio y PDFs. Las salidas consisten principalmente en texto, con opciones para JSON estructurado mediante la aplicación de esquemas.
Las características clave incluyen control de razonamiento incorporado. Los desarrolladores ajustan la profundidad del pensamiento utilizando el parámetro thinking_level: minimal, low, medium, o high (predeterminado). High maximiza la calidad del razonamiento, mientras que los niveles más bajos priorizan la latencia para escenarios de alto rendimiento.
Además, controla la resolución de medios para tareas de visión. Las opciones van desde low hasta ultra_high, influyendo en el consumo de tokens por fotograma o imagen. Elige apropiadamente: high para imágenes detalladas, medium para documentos.
El modelo integra herramientas como el anclaje a Google Search, la ejecución de código y la invocación de funciones. Sin embargo, excluye la generación de imágenes y ciertas herramientas avanzadas de robótica.
Precios para la API de Gemini 3 Flash
La gestión de costos es importante en las integraciones de API. Gemini 3 Flash opera con un modelo de pago por uso. Los tokens de entrada cuestan $0.50 por millón, mientras que los tokens de salida (incluidos los tokens de pensamiento) cuestan $3 por millón.
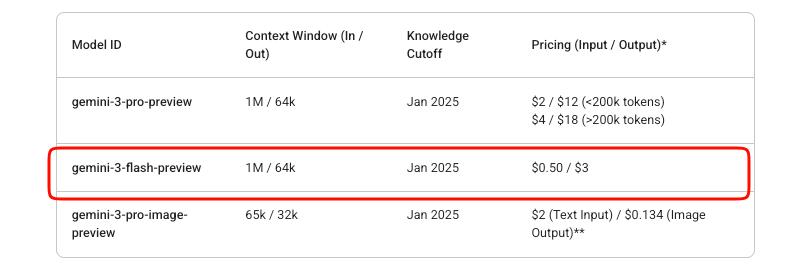
Google ofrece experimentación gratuita en AI Studio. Sin embargo, el uso de la API en producción incurre en cargos una vez que se habilita la facturación. No existe un nivel gratuito más allá de las pruebas de Studio para este modelo de vista previa.
El almacenamiento en caché de contexto y el procesamiento por lotes ayudan a optimizar aún más los costos. El almacenamiento en caché reduce el procesamiento redundante de tokens para contextos repetidos. La API por lotes es adecuada para trabajos asíncronos de alto volumen.
Supervisa el uso a través de los paneles de facturación de Google Cloud. Los picos repentinos a menudo se deben a configuraciones de `media_resolution` altas o a un razonamiento extenso.
Realizando tu Primera Solicitud a la API
Comienzas con la generación de texto simple. El punto final es https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent.
Construye una solicitud POST. Incluye tu clave de API en los encabezados. El cuerpo contiene los contenidos como un array de objetos `role-part`.
Aquí tienes un ejemplo básico de cURL:
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Explica brevemente el entrelazamiento cuántico."}]
}]
}'
La respuesta devuelve candidatos con partes de texto. Además, maneja los metadatos de uso para los recuentos de tokens.
Para respuestas en streaming, usa el punto final :streamGenerateContent. Esto produce resultados parciales de forma incremental, mejorando la latencia percibida en las aplicaciones.
Integración con SDKs Oficiales
Google mantiene SDKs que simplifican las interacciones. Instala el paquete de Python a través de pip install google-generativeai.
Inicializa el cliente:
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel("gemini-3-flash-preview")
response = model.generate_content("Resume los avances recientes en IA.")
print(response.text)
El SDK gestiona automáticamente las firmas de pensamiento para conversaciones de múltiples turnos y el uso de herramientas. En consecuencia, prefiere los SDKs sobre el HTTP puro para el código de producción.
Los usuarios de Node.js acceden a una conveniencia similar a través de @google/generative-ai.
Manejo de Entradas Multimodales
Gemini 3 Flash sobresale en el procesamiento multimodal. Sube archivos o proporciona URIs de datos en línea.
En Python:
model = genai.GenerativeModel("gemini-3-flash-preview")
image = genai.upload_file("diagram.png")
response = model.generate_content(["Describe esta imagen en detalle.", image])
print(response.text)
Ajusta media_resolution en la configuración de generación para la eficiencia de tokens:
generation_config = {
"media_resolution": "media_resolution_high"
}
Los videos y PDFs siguen patrones similares. Además, combina múltiples modalidades en una sola solicitud para tareas de análisis complejas.
Características Avanzadas: Niveles de Pensamiento y Herramientas
Controla el razonamiento explícitamente. Establece thinking_level a "low" para respuestas rápidas:
"generationConfig": {
"thinking_level": "low"
}
Un pensamiento `high` permite un procesamiento interno más profundo de la cadena de pensamiento.
Habilita herramientas como la invocación de funciones. Define funciones en la solicitud; el modelo devuelve llamadas cuando es apropiado.
Las salidas estructuradas imponen esquemas JSON:
"generationConfig": {
"response_mime_type": "application/json",
"response_schema": {...}
}
Combina esto para flujos de trabajo basados en agentes. Por ejemplo, fundamenta las respuestas con búsquedas en tiempo real.
Pruebas y Depuración con Apidog
Las pruebas efectivas aseguran integraciones fiables. Apidog se erige como una herramienta robusta para este propósito. Combina el diseño de API, la depuración, la simulación (mocking) y las pruebas automatizadas en una sola plataforma.
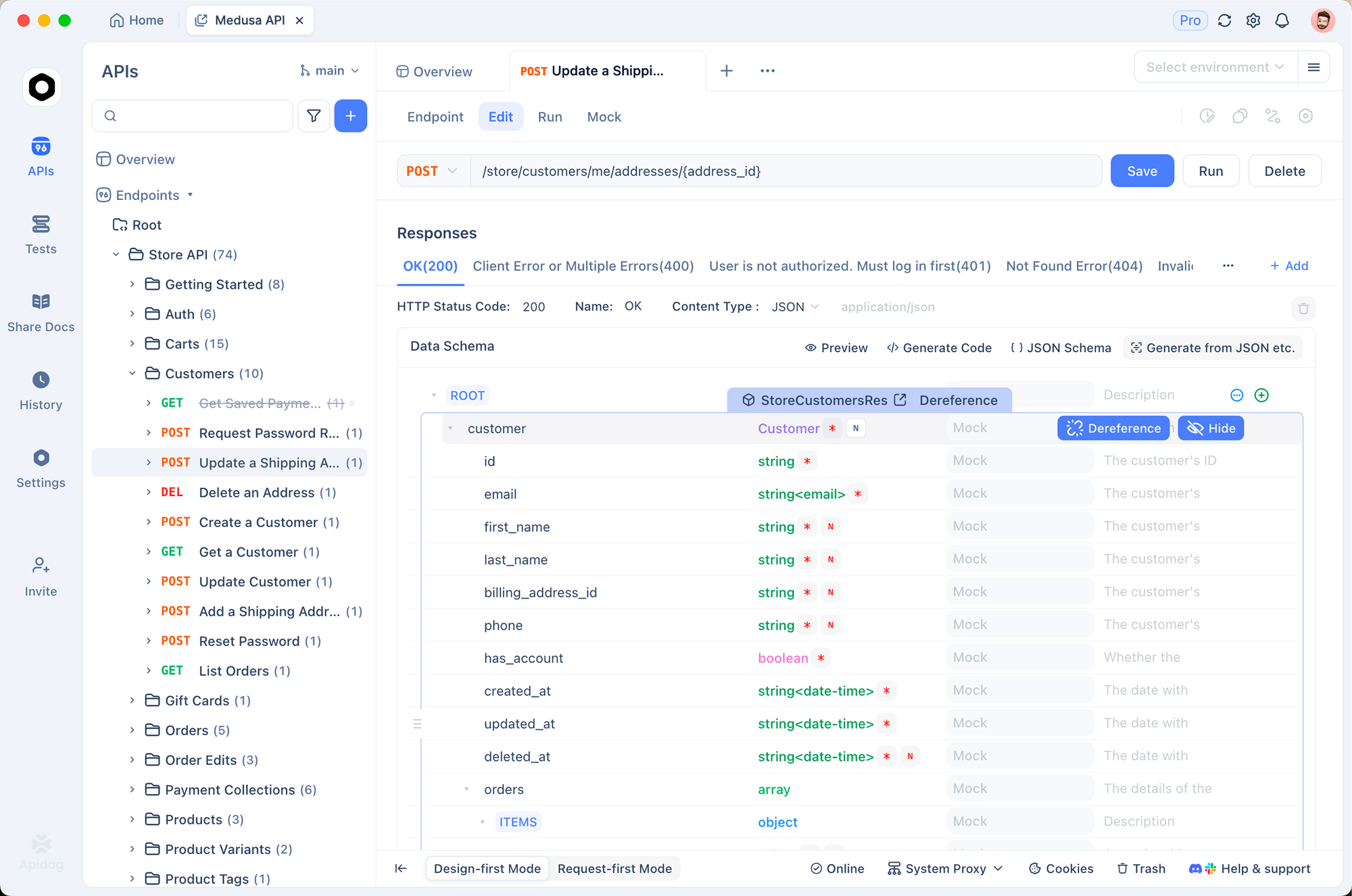
Primero, importa el punto final de Gemini a Apidog. Crea una nueva solicitud que apunte al método `generateContent`. Almacena tu clave de API como una variable de entorno; Apidog soporta múltiples entornos para desarrollo (dev), staging y producción (prod).
Envía solicitudes visualmente. Apidog muestra las respuestas claramente, destacando el uso de tokens y los errores. Además, configura aserciones para validar automáticamente las estructuras de respuesta.
Para chats de múltiples turnos, mantén el historial de conversación entre solicitudes utilizando los scripts o variables de Apidog. Esto simula sesiones de usuario reales de manera eficiente.
Apidog también genera servidores simulados (mock servers). Simula las respuestas de Gemini durante el desarrollo frontend sin consumir cuota.
Además, automatiza suites de prueba. Define escenarios que cubran diferentes niveles de pensamiento, entradas multimodales y casos de error. Ejecútalos en pipelines de CI/CD.
Muchos desarrolladores encuentran que Apidog reduce significativamente el tiempo de depuración en comparación con cURL puro o clientes básicos. Su interfaz intuitiva maneja cuerpos JSON complejos sin esfuerzo.
Mejores Prácticas para Uso en Producción
Implementa lógica de reintento con retroceso exponencial. Se aplican límites de tasa, especialmente en la vista previa.
Almacena en caché los contextos siempre que sea posible para minimizar los tokens. Usa firmas de pensamiento con precisión en las solicitudes directas para evitar errores de validación.
Supervisa los costos de forma proactiva. Registra los recuentos de tokens de entrada/salida por solicitud.
Mantén la temperatura en el valor predeterminado 1.0; las desviaciones degradan el rendimiento del razonamiento.
Finalmente, mantente actualizado a través de la documentación oficial. Los modelos de vista previa evolucionan; planifica posibles cambios importantes.
Conclusión
Ahora posees el conocimiento para integrar Gemini 3 Flash de manera efectiva. Comienza con solicitudes simples, luego escala a aplicaciones multimodales y mejoradas con herramientas. Aprovecha herramientas como Apidog para optimizar los flujos de trabajo de desarrollo.
Gemini 3 Flash empodera a los desarrolladores para crear sistemas inteligentes y responsivos de forma asequible. Experimenta libremente en AI Studio y luego haz la transición a la API para la implementación.