
Mientras Google lanza silenciosamente Gemini 3.0 a través de implementaciones en la sombra y puntos finales de vista previa, los desarrolladores obtienen oportunidades tempranas para probar su razonamiento mejorado y rendimiento multimodal.
Investigadores e ingenieros de Google DeepMind han posicionado a Gemini 3.0 como la familia de modelos más capaz de la compañía hasta la fecha. Además, avanza más allá de las actualizaciones incrementales al introducir comportamientos agénticos nativos y una integración de herramientas más profunda.
Cronología de lanzamiento y estrategia de despliegue de Gemini 3.0
Google adopta un enfoque de implementación por fases para las principales actualizaciones de modelos. En consecuencia, Gemini 3.0 apareció por primera vez en entornos controlados sin un anuncio tradicional en una presentación principal.
El modelo apareció inicialmente en AI Studio bajo el identificador "gemini-3-pro-preview" alrededor de mediados de noviembre de 2025. Además, selectos suscriptores de Gemini Advanced recibieron notificaciones en la aplicación que decían: "Te hemos actualizado del modelo anterior a 3.0 Pro, nuestro modelo más inteligente hasta ahora". Este lanzamiento en la sombra permite a Google recopilar telemetría de producción mientras mantiene la continuidad de la interfaz.
Vertex AI y el registro de cambios de la API de Gemini ahora listan puntos finales de vista previa como gemini-3-pro-preview-11-2025. Además, los nombres clave internos como "lithiumflow" y "orionmist" que dominaron las tablas de clasificación de LM Arena en octubre de 2025 han sido confirmados como puntos de control tempranos de Gemini 3.0.
Google DeepMind reconoció públicamente a la familia en un hilo de noviembre de 2025, describiendo a Gemini 3 como un modelo que ofrece "capacidades de razonamiento de última generación, comprensión multimodal líder a nivel mundial y nuevas experiencias de codificación agénticas". Se espera el lanzamiento estable completo, incluyendo una mayor disponibilidad de la API de Gemini 3, antes de finales de 2025.
Avances arquitectónicos clave en Gemini 3.0
Gemini 3.0 se basa en la base de la mezcla de expertos (MoE) establecida en generaciones anteriores. Sin embargo, incorpora varias mejoras críticas que impactan directamente en la calidad y eficiencia de la inferencia.
Primero, el modelo amplía el soporte de la ventana de contexto más allá de los 2 millones de tokens disponibles en Gemini 2.5 Pro, con instancias de vista previa manejando sesiones extendidas de manera más coherente. Segundo, el entrenamiento en conjuntos de datos multimodales mucho más grandes mejora la alineación transmodal: el modelo ahora procesa texto, código, imágenes y datos estructurados entrelazados con una pérdida de modalidad reducida.
Los investigadores introducen mecanismos de atención refinados que priorizan las dependencias de largo alcance durante las cadenas de razonamiento. Como resultado, Gemini 3.0 exhibe menos problemas de deriva de contexto en interacciones de múltiples turnos que exceden los 100 intercambios.
La familia incluye al menos dos variantes primarias en vista previa:
- Gemini 3.0 Pro: El modelo insignia optimizado para máxima inteligencia y resolución de problemas complejos.
- Gemini 3.0 Flash: Una versión destilada y centrada en la latencia que mantiene una alta capacidad mientras logra tiempos de respuesta de menos de un segundo en la infraestructura TPU.
La instrumentación temprana revela que Pro opera a una temperatura de 1.0 por defecto, con documentación que advierte que valores más bajos pueden degradar el rendimiento del "pensamiento en cadena" (chain-of-thought), una desviación de modelos anteriores donde una temperatura de 0.7 a menudo producía resultados óptimos.
Capacidades de comprensión y generación multimodal
Gemini 3.0 fortalece significativamente el procesamiento multimodal nativo. Los ingenieros entrenan el modelo de extremo a extremo con diversos tipos de datos, lo que le permite razonar a través de la visión, el audio y el texto sin codificadores separados.
Por ejemplo, el modelo analiza capturas de pantalla de interfaces de usuario, extrae especificaciones funcionales y genera código React o Flutter completo con animaciones incrustadas en una sola pasada. Además, interpreta diagramas científicos, deriva ecuaciones subyacentes y simula resultados utilizando conocimientos de física integrados.
Los usuarios de la vista previa informan de un rendimiento revolucionario en tareas de razonamiento visual:
- Interpretación precisa de gráficos complejos que contienen anotaciones superpuestas
- Generación de código SVG que respeta las restricciones matemáticas (por ejemplo, círculos perfectos, escalado proporcional)
- Creación de experiencias interactivas de Canvas que combinan prosa, ejecución de código y salida visual
Además, las extensiones agénticas permiten al modelo orquestar llamadas a herramientas de forma autónoma. Los desarrolladores observan que Gemini 3.0 Pro planifica interacciones de navegador o secuencias de API de varios pasos sin una indicación explícita, una capacidad que antes estaba limitada a modos experimentales.
Mejoras en el razonamiento y el comportamiento agéntico
Google enfatiza "Deep Think" como un paradigma central en Gemini 3.0. El modelo descompone internamente los problemas en subproblemas, evalúa múltiples rutas de solución y se autocorrige antes de la salida final.
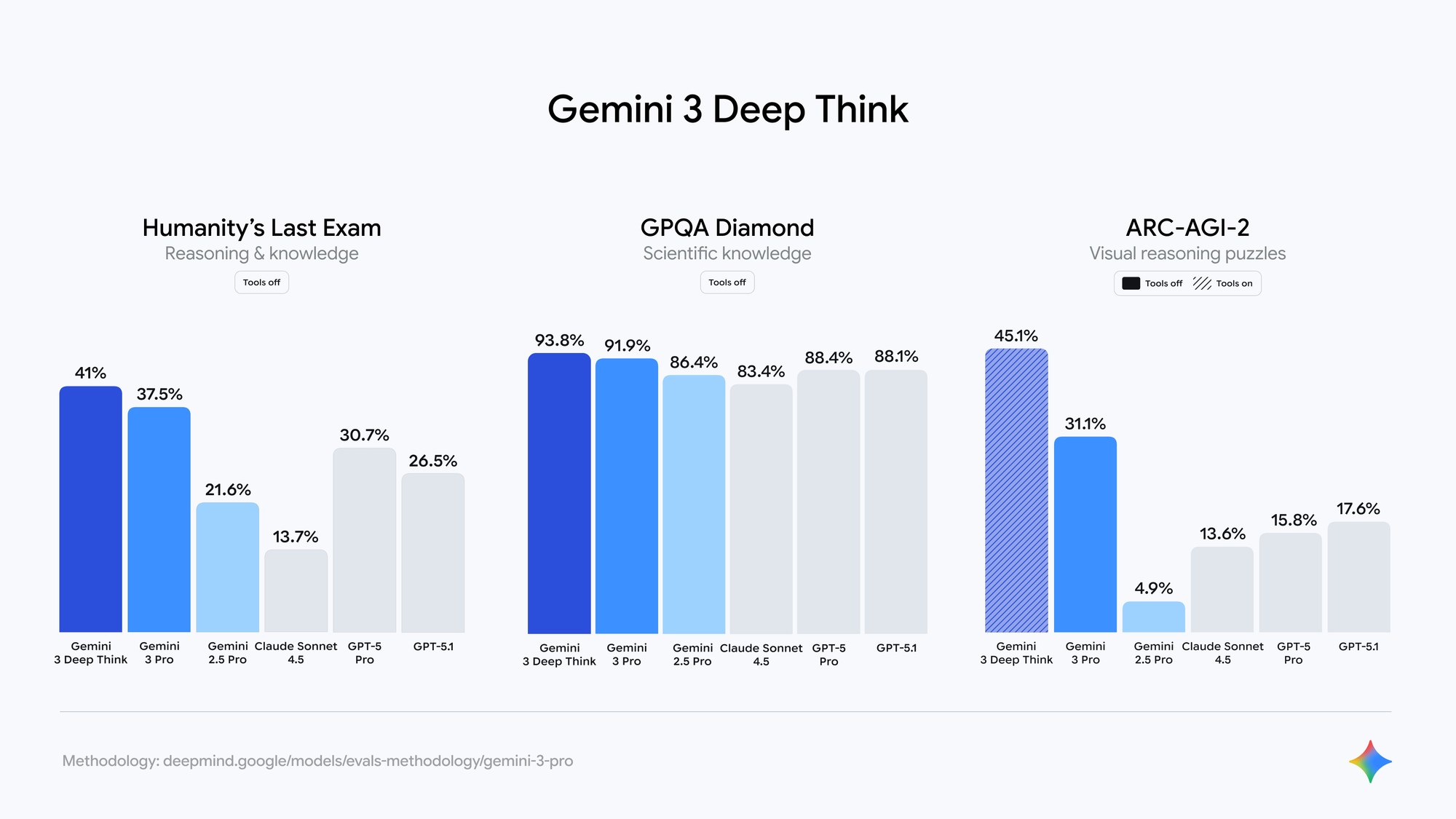
Evaluaciones independientes en puntos de control cerrados de LM Arena (ampliamente aceptados como variantes de Gemini 3.0) muestran:
- Puntuaciones de SimpleBench que se acercan al 90-100% (frente al 62,4% para Gemini 2.5 Pro)
- Ganancias sustanciales en GPQA Diamond, AIME 2024 y SWE-bench Verified
- Mayor coherencia fáctica en la generación de formato largo
Además, el modelo demuestra habilidades de planificación emergentes. Cuando se le encarga el diseño de sistemas, produce diagramas arquitectónicos completos, contratos de API y scripts de implementación, al mismo tiempo que anticipa casos extremos.
Acceso a la API de Gemini 3 en vista previa
Los desarrolladores actualmente acceden a Gemini 3.0 a través de los puntos finales de vista previa de la API de Gemini. Google mantiene la compatibilidad con versiones anteriores de los SDK existentes, requiriendo solo una actualización del nombre del modelo.
Los cambios clave en los puntos finales incluyen:
# El código existente de Gemini 2.5 sigue funcionando
import google.generativeai as genai
genai.configure(api_key="TU_CLAVE_API")
# Cambiar al modelo de vista previa
model = genai.GenerativeModel("gemini-3-pro-preview-11-2025")
response = model.generate_content(
"Explica el entrelazamiento cuántico con una simulación de Python funcional",
generation_config=genai.types.GenerationConfig(
temperature=1.0,
max_output_tokens=8192
)
)
La API de Gemini 3 es compatible con las mismas configuraciones de seguridad, llamada de funciones y características de fundamentación que las versiones anteriores. Sin embargo, las cuotas de la vista previa siguen siendo conservadoras y se aplican límites de tasa por proyecto.
Para pruebas de calidad de producción, herramientas como Apidog resultan invaluables. Apidog importa automáticamente las especificaciones OpenAPI de Gemini, permite la simulación de solicitudes para el desarrollo sin conexión y proporciona una validación detallada de las respuestas, algo esencial al experimentar con nuevos comportamientos de razonamiento que pueden producir longitudes de salida variables.
Rendimiento de referencia y posicionamiento competitivo
Aunque Google aún no ha publicado tarjetas oficiales, los resultados verificados por la comunidad a partir del acceso anticipado y las implementaciones en la sombra indican que Gemini 3.0 Pro lidera a los modelos públicos actuales en varias fronteras:
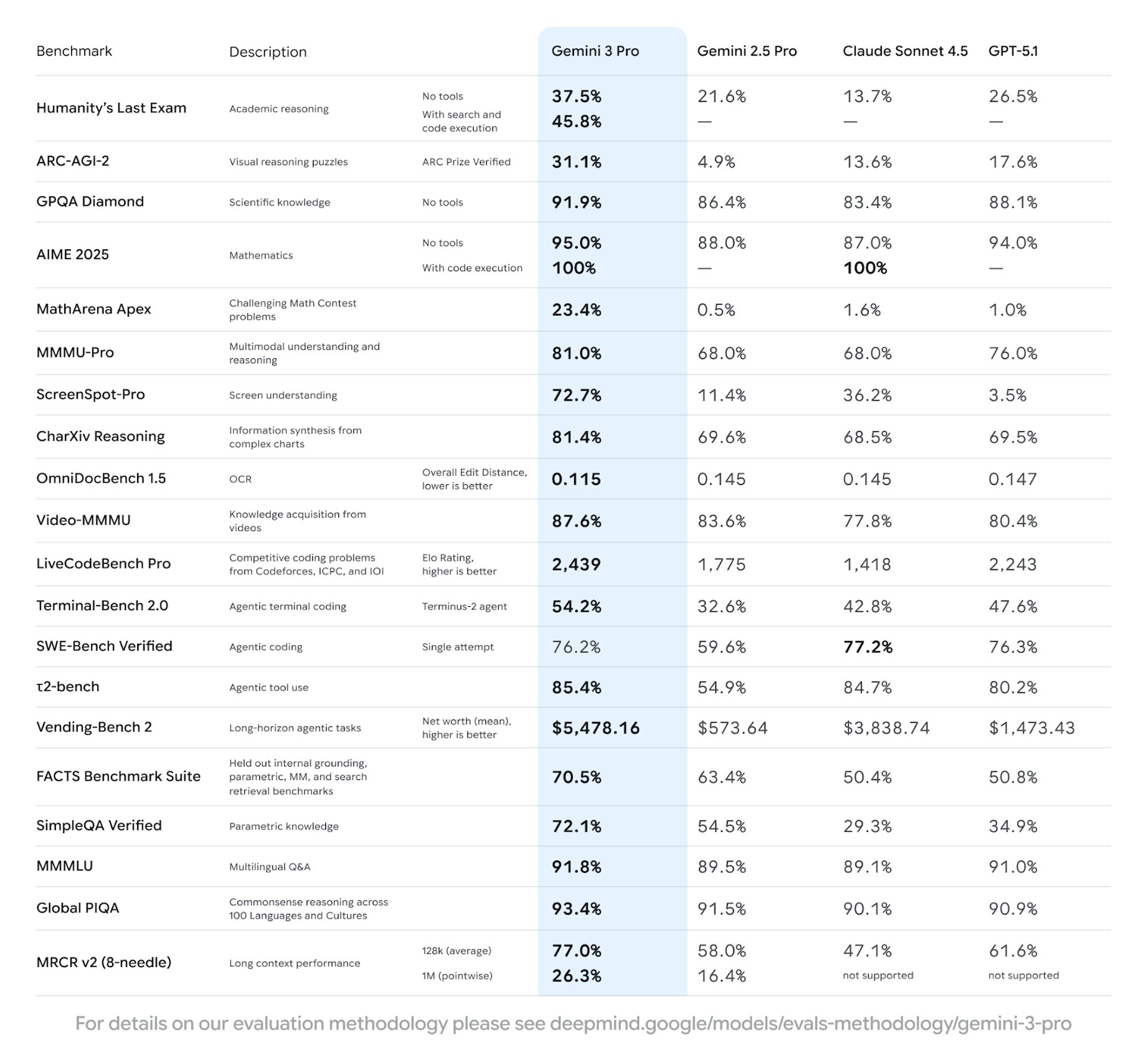
Estas cifras posicionan a Gemini 3.0 por delante de los equivalentes contemporáneos Claude 4 Opus y GPT-4.1 en densidad de razonamiento y calidad de código.
Patrones de integración práctica con la API de Gemini 3
La adopción exitosa requiere comprender las nuevas características de comportamiento. Los desarrolladores deben tener en cuenta tiempos de pensamiento más largos en las indicaciones complejas: el modelo a menudo gasta tokens adicionales en la deliberación interna antes de responder.
Mejores prácticas que surgen del uso de la vista previa:
- Establecer la temperatura en 1.0 para tareas de razonamiento intensivo
- Usar instrucciones del sistema para forzar una salida estructurada (JSON, YAML)
- Aprovechar el contexto expandido para cargas completas de bases de código
- Encadenar llamadas a herramientas explícitamente cuando se requiere un comportamiento determinista
Además, combine la API de Gemini 3 con capas de orquestación externas para bucles de agente confiables. Apidog sobresale aquí al proporcionar colecciones específicas del entorno que cambian sin problemas entre los puntos finales de gemini-2.5-pro y gemini-3-pro-preview.
Limitaciones y problemas conocidos en la vista previa
Las versiones preliminares exhiben inestabilidad ocasional. Los usuarios encuentran pérdida de contexto en sesiones extremadamente largas (>150k tokens) y alucinaciones raras en dominios específicos. Además, la generación de imágenes sigue ligada a puntos finales separados de Imagen/Nano Banana en lugar de una integración nativa.
Google itera activamente basándose en la telemetría. La mayoría de los problemas reportados se resuelven a los pocos días de su descubrimiento, lo que refleja las ventajas de la implementación en la sombra.
Perspectivas futuras e impacto en el ecosistema
Gemini 3.0 establece una nueva línea de base para los agentes multimodales. A medida que la API de Gemini 3 adquiera un estado estable, se espera una rápida integración en Google Workspace, Android y los agentes de Vertex AI.
Las empresas se beneficiarán de instancias privadas con alineación personalizada, mientras que los desarrolladores obtendrán acceso a una profundidad de razonamiento que antes requería múltiples llamadas al modelo.
La combinación de inteligencia bruta, comprensión nativa de herramientas e implementación eficiente posiciona a Gemini 3.0 como la base para las aplicaciones de IA de próxima generación.
Los desarrolladores listos para experimentar con estas capacidades deberían comenzar a migrar sus conjuntos de pruebas a la vista previa de la API de Gemini 3 de inmediato. Herramientas como Apidog reducen drásticamente la fricción durante esta transición al ofrecer un cambio de punto final con un solo clic y una depuración integral.
El despliegue medido de Google demuestra madurez en la implementación de modelos grandes. En consecuencia, cuando Gemini 3.0 alcance la disponibilidad general, el ecosistema estará preparado para un uso productivo inmediato.