
Necesita herramientas eficientes para generar imágenes de alta calidad a partir de indicaciones de texto en aplicaciones modernas. La API Z-Image aborda esta demanda directamente. Los desarrolladores acceden a un potente modelo de texto a imagen a través de una interfaz sin costo que ofrece resultados fotorrealistas rápidamente. Esta API aprovecha el modelo de código abierto Z-Image-Turbo del equipo Tongyi-MAI de Alibaba, que opera bajo la licencia Apache 2.0. Se beneficia de una inferencia en menos de un segundo en hardware adecuado, lo que la hace ideal para funciones en tiempo real en aplicaciones web, herramientas móviles o flujos de trabajo automatizados.
A continuación, explorará la base de código abierto de Z-Image-Turbo. Luego, obtendrá información sobre los métodos de acceso a la API y confirmará su estructura de precios gratuita. Finalmente, implementará integraciones prácticas. Estos pasos lo equiparán para implementar capacidades de generación de imágenes de manera efectiva.
Comprendiendo el Modelo de Código Abierto Z-Image-Turbo
Comienza con la tecnología central detrás de la API Z-Image: el modelo Z-Image-Turbo. El equipo Tongyi-MAI de Alibaba lanza este modelo de 6 mil millones de parámetros como código completamente abierto bajo la licencia Apache 2.0. Esta licencia permite el uso comercial, las modificaciones y las distribuciones sin restricciones, lo que acelera su adopción en entornos de producción.
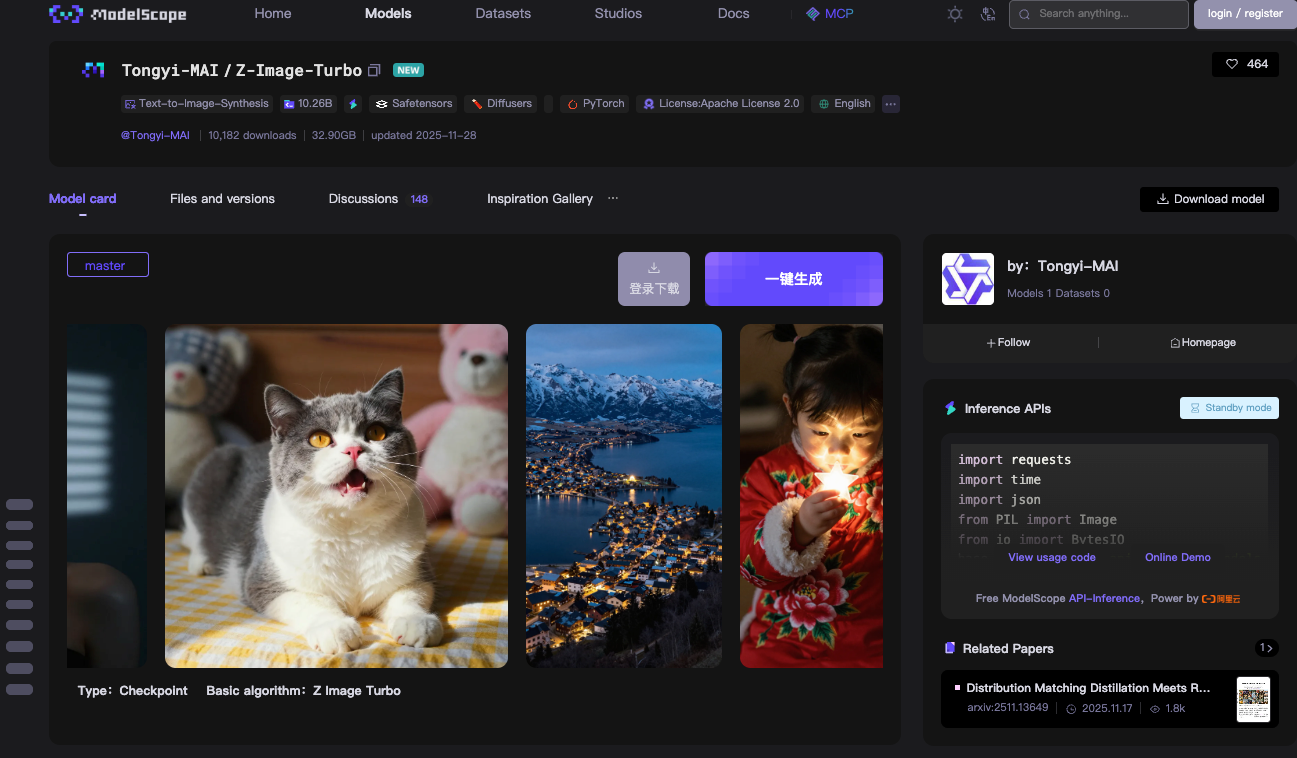
Z-Image-Turbo se basa en una arquitectura Scalable Single-Stream Diffusion Transformer (S3-DiT). Los modelos tradicionales de doble flujo separan el procesamiento de texto e imágenes, lo que desperdicia parámetros. Sin embargo, S3-DiT concatena tokens de texto, tokens semánticos visuales y tokens VAE de imagen en un solo flujo unificado. Este diseño maximiza la eficiencia. Como resultado, el modelo cabe dentro de 16 GB de VRAM en GPUs de consumo como las tarjetas NVIDIA RTX de la serie 40. Esto se logra sin sacrificar la calidad de la salida.
El modelo sobresale en la síntesis de imágenes fotorrealistas. Genera escenas detalladas, retratos y paisajes a partir de indicaciones descriptivas. Por ejemplo, una indicación como "a serene mountain lake at dusk with bilingual signage in English and Chinese" produce imágenes nítidas y contextualmente relevantes. Z-Image-Turbo maneja bien las instrucciones complejas, gracias a su Prompt Enhancer integrado. Este componente refina las entradas para una mejor adherencia, reduciendo los artefactos comunes en modelos de difusión anteriores.
La velocidad de inferencia define la ventaja de Z-Image-Turbo. Requiere solo 8 Evaluaciones de Número de Funciones (NFE), equivalentes a 9 pasos de inferencia en la práctica. En GPUs empresariales H800, se observa una latencia inferior al segundo, a menudo por debajo de los 500 ms por imagen. Las configuraciones de consumo logran de 2 a 5 segundos, dependiendo del hardware. Esta eficiencia proviene de técnicas de destilación como Decoupled-DMD y DMDR, que comprimen el modelo base Z-Image mientras preservan el rendimiento.
Puede descargar los pesos del modelo desde ModelScope o los repositorios de Hugging Face. La rama principal incluye archivos de punto de control que suman aproximadamente 24 GB. La compatibilidad con PyTorch garantiza una amplia integración. Para pruebas locales, instala las dependencias a través de pip: torch, torchvision y modelscope>=1.18.0. Un script de pipeline básico carga el modelo y genera una imagen en menos de 10 líneas de código.
Considere este ejemplo para inferencia local:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import torch
device = "cuda" if torch.cuda_is_available() else "cpu"
pipe = pipeline(Tasks.text_to_image_synthesis, model="Tongyi-MAI/Z-Image-Turbo", device=device)
output = pipe({
"text": "A photorealistic golden retriever playing in a sunlit park, 1024x1024",
"width": 1024,
"height": 1024,
"num_inference_steps": 9
})
output["output_imgs"][0].save("generated_image.png")
Este código inicializa el pipeline, procesa la indicación y guarda el resultado. Observará el parámetro num_inference_steps: 9, que activa la destilación de 8 pasos para una velocidad óptima. La escala de guía permanece en 0.0, ya que las variantes Turbo omiten la guía sin clasificador para mantener la velocidad.
Los benchmarks confirman la competitividad de Z-Image-Turbo. En AI Arena de Alibaba, obtiene una puntuación alta en las evaluaciones de preferencia humana basadas en Elo, superando a muchos pares de código abierto en fotorrealismo y fidelidad textual. En comparación con modelos como Stable Diffusion 3, utiliza menos pasos y menos memoria, pero ofrece un detalle comparable.
Sin embargo, existen limitaciones. El modelo prioriza la velocidad sobre las resoluciones extremas; ir más allá de 1536x1536 puede introducir desenfoque sin un ajuste fino. También carece de edición nativa de imagen a imagen en la variante Turbo, lo que corresponde a la próxima versión de Z-Image-Edit. Aun así, para las tareas de texto a imagen, Z-Image-Turbo proporciona una base sólida y accesible.
Usted extiende este modelo a través de la API Z-Image, que lo aloja en la infraestructura de ModelScope. Este cambio de local a la nube elimina las cargas de configuración. En consecuencia, se enfoca en la lógica de la aplicación en lugar de la optimización del hardware.
Accediendo a la API Gratuita Z-Image: Configuración Paso a Paso
Transiciona sin problemas a la integración de la API. La API Z-Image opera a través del servicio de inferencia de ModelScope, que aloja Z-Image-Turbo para llamadas remotas. Esta configuración requiere una configuración mínima, pero ofrece una fiabilidad de nivel empresarial.
Primero, regístrese en la plataforma ModelScope. Cree una cuenta con su correo electrónico o credenciales de GitHub. Una vez iniciado sesión, navegue a la sección de API bajo su perfil. Genere un Token de ModelScope; este actuará como su clave de autenticación Bearer. Guárdelo de forma segura, ya que todas las solicitudes lo exigen en el encabezado de Autorización.
El endpoint de la API se centra en el procesamiento asíncrono, lo que se adapta a las necesidades de alto rendimiento. Usted envía tareas de generación mediante POST a https://api-inference.modelscope.cn/v1/images/generations. Las respuestas devuelven un task_id inmediatamente. Luego, consulta https://api-inference.modelscope.cn/v1/tasks/{task_id} cada 5-10 segundos hasta su finalización. Este diseño previene los tiempos de espera en generaciones largas, aunque la velocidad de Z-Image-Turbo mantiene las esperas breves, típicamente de 5 a 15 segundos de principio a fin.
Los encabezados clave incluyen:
Authorization: Bearer {su_token}Content-Type: application/jsonX-ModelScope-Async-Mode: true(para envío)X-ModelScope-Task-Type: image_generation(para verificaciones de estado)
El cuerpo de la solicitud especifica parámetros como el ID del modelo, la indicación, las dimensiones y los pasos. Establece "model": "Tongyi-MAI/Z-Image-Turbo" para apuntar a esta variante. Las dimensiones predeterminadas son 1024x1024, pero ajusta height y width para relaciones de aspecto personalizadas. Mantenga guidance_scale: 0.0 y num_inference_steps: 9 para obtener los mejores resultados.
Un ejemplo completo de curl ilustra el proceso:
# Paso 1: Enviar tarea
curl -X POST "https://api-inference.modelscope.cn/v1/images/generations" \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "Content-Type: application/json" \
-H "X-ModelScope-Async-Mode: true" \
-d '{
"model": "Tongyi-MAI/Z-Image-Turbo",
"prompt": "A futuristic cityscape at night with neon signs in Chinese and English",
"height": 1024,
"width": 1024,
"num_inference_steps": 9,
"guidance_scale": 0.0
}'
# Extraer task_id de la respuesta, ej., {"task_id": "abc123"}
# Paso 2: Consultar estado
curl -X GET "https://api-inference.modelscope.cn/v1/tasks/abc123" \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "X-ModelScope-Task-Type: image_generation"
Si tiene éxito, la respuesta de estado incluye "task_status": "SUCCEED" y una matriz output_images con una URL descargable. Usted obtiene la imagen vía GET, guardándola como PNG o JPEG.
Para alternativas síncronas, ModelScope ofrece una demostración en línea en modelscope.cn/aigc/imageGeneration. Seleccione Z-Image-Turbo como modelo predeterminado. El Modo Rápido genera imágenes sin parámetros, mientras que el Modo Avanzado expone todos los controles. Esta interfaz sirve para prototipos, pero usted prefiere la API para la automatización.
El manejo de errores resulta esencial. Los códigos comunes incluyen 401 (token inválido), 429 (límites de tasa) y 500 (problemas del servidor). Implemente reintentos con retroceso exponencial en el código de producción. Los límites de tasa rondan las 10-20 solicitudes por minuto para los niveles gratuitos, aunque las cuotas exactas varían según la cuenta.
Usted integra esta API en diversos entornos. Los desarrolladores de Python utilizan requests para llamadas HTTP, como se mostró anteriormente. Los usuarios de Node.js aprovechan axios para el sondeo basado en promesas. Incluso las funciones sin servidor en AWS Lambda o Vercel se implementan fácilmente, dados los payloads ligeros.
Apidog mejora esta fase de acceso. Importe la especificación de la API en Apidog, que autogenera documentación y casos de prueba. Usted simula respuestas, encadena solicitudes para el sondeo y exporta colecciones para compartir con el equipo. Esta plataforma reduce el tiempo de depuración, permitiéndole centrarse en la ingeniería de prompts.
A través de estos pasos, establece una conexión fiable con la API Z-Image. Ahora, examina su precio para confirmar su rentabilidad.
Precios y Cuotas para la API Z-Image
A continuación, confirma la asequibilidad. La API Z-Image no incurre en cargos por inferencia. ModelScope proporciona computación gratuita ilimitada para las llamadas a Z-Image-Turbo, según lo anunciado en su publicación oficial de X. Este modelo de costo cero incluye alojamiento, ancho de banda y recursos de GPU, una rareza entre los servicios de IA.
Sin embargo, se aplican cuotas para evitar el abuso. Las cuentas gratuitas tienen límites flexibles: aproximadamente 50-100 generaciones por hora, que se restablecen periódicamente. Usted monitorea el uso a través del panel de ModelScope. Exceder los límites activa una limitación temporal, pero puede actualizar a niveles pro para volúmenes más altos si es necesario. Los planes pro comienzan con tarifas bajas, pero el nivel gratuito es suficiente para la mayoría de los desarrolladores y aficionados.
Mejores Prácticas para Optimizar el Rendimiento de la API Z-Image
Usted refina su uso con estrategias específicas. Primero, seleccione los parámetros óptimos. Adhiérase a 1024x1024 para el equilibrio; escale después de la generación si es necesario. Limite los pasos a 9; valores más altos ralentizan la inferencia sin mejoras.
La aceleración de hardware impulsa los híbridos locales. Habilite Flash Attention en Diffusers: pipe.transformer.set_attention_backend("flash"). Esto reduce la memoria en un 20-30% en GPUs Ampere.
La ingeniería de prompts eleva la calidad. Estructure las entradas como "sujeto + acción + entorno + estilo". Pruebe variaciones en el modo de simulación de Apidog para iterar rápidamente.
Las prácticas de seguridad protegen las integraciones. Nunca exponga tokens en el código del lado del cliente; use proxies de servidor. Valide las entradas para prevenir ataques de inyección.
Las herramientas de monitoreo rastrean métricas. Registre los tiempos de generación, las tasas de éxito y el uso de tokens. Herramientas como Prometheus se integran fácilmente para paneles de control.
Conclusión
Ahora domina completamente la API Z-Image. Desde comprender la arquitectura de código abierto de Z-Image-Turbo hasta ejecutar llamadas a la API y optimizar flujos de trabajo, esta guía lo arma para el éxito. El modelo de precios gratuito democratiza la generación avanzada de imágenes, mientras que herramientas como Apidog agilizan el desarrollo.
Implemente estas técnicas en su próximo proyecto. Experimente con prompts, escale integraciones y contribuya al ecosistema. A medida que la IA evoluciona, Z-Image-Turbo lo posiciona a la vanguardia de las herramientas eficientes y creativas.