
Los desarrolladores recurren cada vez más a las plataformas sin servidor para la inferencia de IA, y la API de Fal.ai destaca como una opción robusta para medios generativos. Esta API le permite ejecutar modelos para la generación de imágenes, vídeo, voz y código sin necesidad de gestionar la infraestructura. Accede a más de 600 modelos listos para producción a través de una interfaz unificada, que escala eficientemente con GPU bajo demanda.
A continuación, exploramos los fundamentos de la API de Fal.ai y le guiamos a través de su acceso y uso.
¿Qué es la API de Fal.ai?
La API de Fal.ai proporciona una plataforma de medios generativos que impulsa aplicaciones con inferencia de IA rápida. Los ingenieros la utilizan para integrar modelos de vanguardia en el software, evitando la necesidad de gestionar servidores. La plataforma ofrece un rendimiento 10 veces más rápido en comparación con las configuraciones tradicionales, gracias a las GPU sin servidor optimizadas que escalan a miles de equivalentes H100.

En su esencia, la API de Fal.ai se centra en la generación de medios. Por ejemplo, puede generar imágenes de alta calidad a partir de indicaciones de texto utilizando modelos como FLUX.1. Además, es compatible con la animación de vídeo, la conversión de voz a texto y las interacciones con grandes modelos de lenguaje. Sin embargo, la API enfatiza la preparación para la producción, con características como la inferencia por streaming y el soporte de webhooks para tareas asíncronas.
Además, la API de Fal.ai funciona con un modelo de pago por uso, lo que mantiene los costes predecibles. Usted solo paga por la computación que consume, lo que la hace adecuada tanto para prototipos como para aplicaciones a escala. Pasando a los detalles, examinemos cómo registrarse.
¿Cómo me registro en la API de Fal.ai?
Empieza creando una cuenta en el sitio web de Fal.ai. Navegue a fal.ai y localice el botón de registro en la esquina superior derecha. Proporcione su dirección de correo electrónico, establezca una contraseña y verifique su cuenta a través del correo electrónico de confirmación. Este proceso tarda menos de un minuto.
Una vez registrado, accederá al panel de control. Aquí, puede gestionar modelos, ver estadísticas de uso y generar claves API. Fal.ai no requiere tarjeta de crédito para el registro inicial, pero puede añadir detalles de pago más tarde para las funciones de pago. Además, la plataforma ofrece un nivel gratuito con créditos limitados, lo que le permite probar las funcionalidades básicas.
Después del registro, explore el catálogo de modelos. Puede seleccionar entre categorías como texto a imagen o texto a vídeo. Este paso le familiariza con los puntos finales disponibles. Ahora, con una cuenta lista, proceda a obtener su clave API.
¿Cómo obtener su clave API de Fal.ai?
La API de Fal.ai se basa en claves API para la autenticación. Puede generar una desde el panel de control. Primero, inicie sesión y haga clic en la sección "Keys" (Claves) bajo su perfil. Luego, seleccione "Generate New Key" (Generar nueva clave) y nómbrela para referencia, como "Development Key" (Clave de desarrollo).
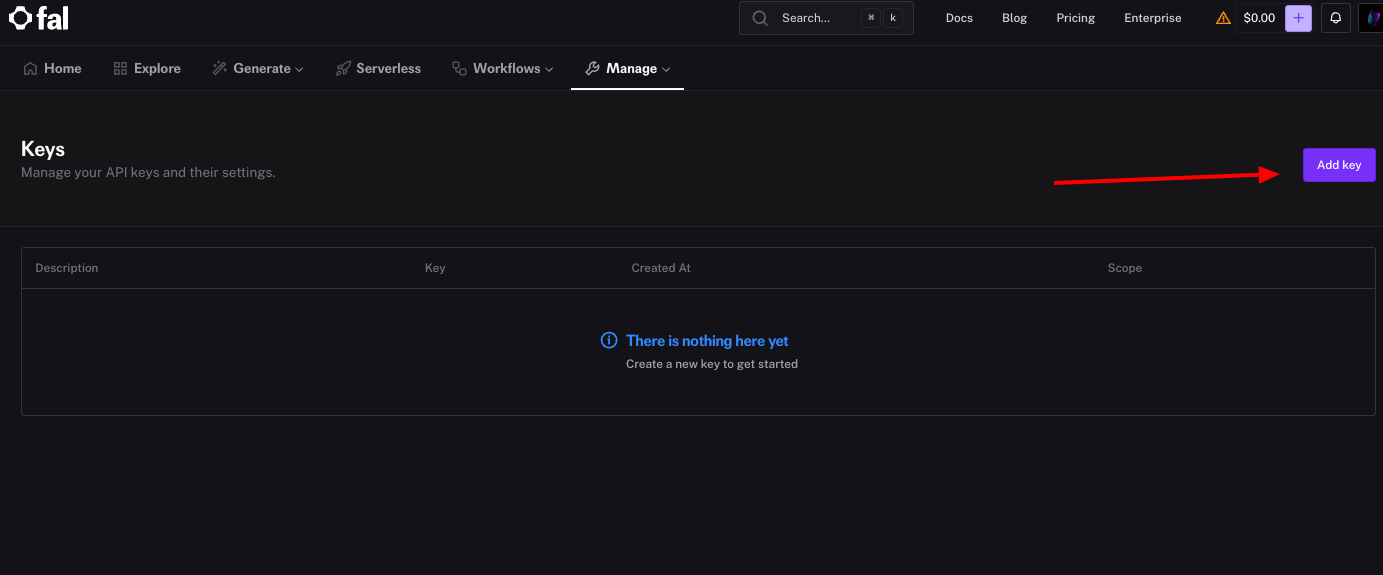
El sistema muestra la clave inmediatamente; cópiela y guárdela de forma segura, ya que Fal.ai no la mostrará de nuevo. Puede establecer esta clave como una variable de entorno, como export FAL_KEY="your_key_here", para evitar codificarla directamente en los scripts.
Si trabaja con múltiples proyectos, genere claves separadas para cada uno. Esta práctica mejora la seguridad al permitir la revocación sin afectar otras integraciones. Además, supervise el uso de las claves en el panel de control para detectar anomalías. Con la clave en mano, el siguiente paso es instalar la biblioteca cliente.
¿Cómo instalar el cliente de Fal.ai?
Fal.ai proporciona bibliotecas cliente oficiales para una integración más sencilla. Para entornos JavaScript o Node.js, instale el cliente a través de npm. Ejecute el comando npm install --save @fal-ai/client en el directorio de su proyecto.
Esta biblioteca se encarga de la autenticación, el envío de solicitudes y el análisis de respuestas. Sustituye a la obsoleta @fal-ai/serverless-client, así que asegúrese de utilizar la última versión. Para los usuarios de Python, instale fal-client con pip install fal-client.
Una vez instalada, importe la biblioteca en su código. Por ejemplo, en JavaScript: import { fal } from "@fal-ai/client";. Si no utiliza variables de entorno, configúrela con sus credenciales. Esta configuración simplifica las llamadas a los puntos finales de la API de Fal.ai. A continuación, la autenticación se convierte en el siguiente paso crítico.
¿Cómo autenticar solicitudes con la API de Fal.ai?
La autenticación asegura sus interacciones con la API de Fal.ai. Principalmente, utiliza la clave API en los encabezados o en las variables de entorno. Para solicitudes HTTP directas, incluya Authorization: Key your_fal_key en el encabezado.
Sin embargo, la biblioteca cliente automatiza esto. Confígurela una vez: fal.config({ credentials: "your_fal_key" });. Este enfoque evita la exposición en el código del lado del cliente; siempre utilice un proxy para las solicitudes si está creando aplicaciones web.
Actualmente, la API de Fal.ai no admite otros métodos de autenticación como OAuth. Pruebe la autenticación realizando una solicitud simple; un error 401 indica problemas. Además, rote las claves periódicamente para seguir las mejores prácticas de seguridad. Una vez autenticado, puede explorar los modelos disponibles.
¿Cuáles son los modelos disponibles en la API de Fal.ai?
La API de Fal.ai alberga una diversa biblioteca de modelos. Las categorías clave incluyen texto a imagen, texto a vídeo, voz a texto y grandes modelos de lenguaje. Por ejemplo, FLUX.1 [dev] genera imágenes a partir de indicaciones con su transformador de 12 mil millones de parámetros.
Otros modelos notables: FLUX.1 [schnell] para generación rápida en 1-4 pasos, Stable Diffusion 3.5 para imágenes ricas en tipografía, y Whisper para transcripción de audio. Se accede a ellos a través de IDs únicos como "fal-ai/flux/dev".
Navegue por el 'model playground' en fal.ai/models para probar de forma interactiva. Cada página de modelo detalla parámetros, ejemplos y precios. Esta variedad permite selecciones personalizadas. Por ejemplo, elija Recraft V3 para arte vectorial. Una vez identificados los modelos, aprenderá a generar imágenes.
¿Cómo generar imágenes usando la API de Fal.ai?
Genera imágenes suscribiéndose a un punto final del modelo. Utilice el cliente para enviar una solicitud POST con parámetros de entrada. Para FLUX.1 [dev], el código se ve así:
import { fal } from "@fal-ai/client";
const result = await fal.subscribe("fal-ai/flux/dev", {
input: {
prompt: "A futuristic cityscape at dusk, with neon lights and flying cars",
image_size: "landscape_16_9",
num_inference_steps: 28,
guidance_scale: 3.5
}
});
console.log(result.images[0].url);
Esta solicitud produce una URL de imagen. La API procesa la indicación y devuelve metadatos como tiempos y semilla. Además, habilite las comprobaciones de seguridad para filtrar contenido NSFW: enable_safety_checker: true.
Pruebe variaciones ajustando las indicaciones. Para la generación por lotes, establezca num_images: 4. Las salidas incluyen URLs, dimensiones y tipos de contenido. Este método constituye la base para las tareas multimedia. A continuación, personalice con parámetros avanzados.
Uso avanzado: Parámetros y personalización en la API de Fal.ai
La API de Fal.ai ofrece amplios parámetros para el ajuste fino. Para la generación de imágenes, prompt dirige el contenido, mientras que guidance_scale controla la adherencia; valores más altos producen resultados más estrictos, típicamente entre 1.0 y 20.0.
Establezca image_size como enumeraciones como "square_hd" u objetos personalizados: { width: 1024, height: 768 }. Los pasos de inferencia (num_inference_steps) equilibran velocidad y calidad; 20-50 funciona bien. La semilla asegura la reproducibilidad: proporcione un entero para resultados consistentes.
Los modos de aceleración ("none", "regular", "high") optimizan el tiempo de ejecución. Para la salida, elija "jpeg" o "png" a través de output_format. Gestione los archivos subiéndolos mediante fal.storage.upload(file) o utilizando URLs/base64.
Personalice aún más con webhooks para las notificaciones. Estas opciones mejoran el control. Sin embargo, supervise los costes, ya que más pasos aumentan la facturación. Pasando a la eficiencia, a continuación se describe el manejo asíncrono.
¿Cómo gestionar solicitudes asíncronas y colas en la API de Fal.ai?
La API de Fal.ai soporta colas para tareas largas. Envíe a través de fal.queue.submit(model_id, { input: {...} }), recibiendo un request_id. Consulte el estado: fal.queue.status(model_id, { requestId: "id" }).
Recupere resultados: fal.queue.result(model_id, { requestId: "id" }). Incluya webhookUrl para las devoluciones de llamada. Esto desacopla el envío de la espera, ideal para el procesamiento por lotes.
const stream = await fal.stream("fal-ai/flux/dev", { input: {...} });
for await (const event of stream) {
console.log(event);
}
const result = await stream.done();
Las colas evitan los tiempos de espera. Además, los registros (logs: true) ayudan a la depuración. Una vez dominado el manejo asíncrono, integre herramientas de prueba como Apidog.
¿Cómo integrar la API de Fal.ai con Apidog?
Apidog mejora el desarrollo de la API de Fal.ai al proporcionar una plataforma unificada para pruebas. Primero, cree un proyecto en Apidog e importe el esquema OpenAPI desde fal.ai/docs (por ejemplo, /api/openapi/queue/openapi.json?endpoint_id=fal-ai/flux/dev).
Configure la autenticación: Añada Authorization: Key your_fal_key en los encabezados. Configure las solicitudes para puntos finales como POST a "fal-ai/flux/dev", incluyendo cargas JSON con prompt y parámetros.
Apidog simula respuestas, simulando retrasos y salidas de GPU. Suba archivos para ediciones de imágenes o pruebe casos extremos. Ejecute colecciones para cubrir escenarios, depurando las indicaciones de forma iterativa.
Los beneficios incluyen iteraciones más rápidas (hasta un 40% reportado), ahorro de costes mediante simulaciones y detección de errores (por ejemplo, límites de tasa 429). Las características de colaboración en equipo aseguran la consistencia. Esta integración optimiza los flujos de trabajo. A continuación, adopte las mejores prácticas.
Mejores prácticas para usar la API de Fal.ai
Optimice el rendimiento seleccionando modelos adecuados: use variantes "schneller" para mayor velocidad. Limite los puntos de datos en las solicitudes para evitar la latencia. Además, implemente el almacenamiento en caché para indicaciones repetidas.
Proteja las claves con variables de entorno y proxies. Supervise el uso a través del panel para controlar los costes. Agrupe las solicitudes cuando sea posible, pero respete los límites de tasa.
Para producción, utilice clústeres dedicados para cargas pesadas. Pruebe a fondo con simulaciones en Apidog. Además, únase al Discord de Fal.ai para obtener información de la comunidad. Estas prácticas aseguran integraciones fiables. Sin embargo, se producen errores, así que manéjelos adecuadamente.
¿Cómo gestionar errores en la API de Fal.ai?
La API de Fal.ai devuelve errores estructurados. Los problemas del cliente (por ejemplo, validación) producen códigos 4xx con detalles como "Invalid prompt" (Indicación no válida). Los errores del servidor son 5xx, a menudo transitorios; reintente con retroceso exponencial.
Errores comunes: 401 (autenticación fallida): compruebe la clave; 429 (límite de tasa): espere y reduzca la frecuencia; 400 (entrada incorrecta): valide los parámetros.
try {
const result = await fal.subscribe(...);
} catch (error) {
console.error(error.response.data);
}
Los registros ayudan a diagnosticar. Apidog simula errores para las pruebas. Un manejo adecuado mantiene la robustez. Finalmente, considere los precios.
¿Cuál es el precio de la API de Fal.ai?
La API de Fal.ai utiliza precios de pago por uso. Sin servidor cobra por salida, por ejemplo, $0.0001 por megapixel para imágenes. Los modelos de vídeo como Veo 3 cuestan $0.20/segundo (audio apagado).
El nivel gratuito proporciona créditos iniciales. Actualice para obtener más a través del panel de control. El precio por hora de GPU comienza en $1.2 para H100s en modo Compute.
Realice un seguimiento de los gastos en el panel de control. Optimice reduciendo pasos o usando modelos más rápidos. Este modelo se adapta a cargas de trabajo variables. En resumen, la API de Fal.ai impulsa un desarrollo eficiente de la IA.
Conclusión
Ahora comprende cómo acceder y utilizar la API de Fal.ai de forma exhaustiva. Desde el registro y la generación de claves hasta integraciones avanzadas con Apidog, esta guía le equipa para aplicaciones listas para producción. Experimente con modelos, gestione errores diligentemente y supervise los costes. A medida que la IA evoluciona, la API de Fal.ai sigue siendo una herramienta versátil. Empiece a construir hoy mismo.