
DeepSeek continúa avanzando en los modelos de lenguaje grandes con lanzamientos que priorizan el razonamiento y la eficiencia. Ingenieros e investigadores ahora acceden a DeepSeek-V3.2 y DeepSeek-V3.2-Speciale, modelos que sobresalen en la resolución de problemas complejos y en flujos de trabajo basados en agentes. Estas herramientas se integran a la perfección en las aplicaciones, pero los desarrolladores a menudo enfrentan desafíos en la configuración, autenticación y optimización. Este artículo proporciona una guía técnica paso a paso para aprovechar estos modelos de manera efectiva.
Entendiendo DeepSeek-V3.2: La Base de Código Abierto para el Razonamiento Avanzado
Los desarrolladores construyen sistemas robustos de IA sobre modelos de código abierto porque ofrecen transparencia, personalización y mejoras impulsadas por la comunidad. DeepSeek-V3.2 se erige como el sucesor oficial de la variante experimental V3.2-Exp, que DeepSeek lanzó anteriormente para probar mecanismos de atención dispersa. Este modelo activa 37 mil millones de parámetros de un total de 671 mil millones en su arquitectura Mixture-of-Experts (MoE), entrenado con 14.8 billones de tokens de alta calidad. Tal escala permite a DeepSeek-V3.2 manejar diversas tareas, desde la generación de lenguaje natural hasta intrincadas pruebas matemáticas.
La innovación central del modelo reside en DeepSeek Sparse Attention (DSA), un mecanismo de grano fino que reduce la sobrecarga computacional durante la inferencia, especialmente para contextos largos de hasta 128.000 tokens. Los ingenieros aprecian esto porque mantiene la calidad de la salida al tiempo que reduce la latencia, algo crítico para aplicaciones en tiempo real como chatbots o asistentes de código. Además, DeepSeek-V3.2 integra modos de "pensamiento", donde el modelo genera pasos de razonamiento intermedios antes de las salidas finales, lo que aumenta la precisión en puntos de referencia como AIME 2025 y HMMT 2025.
Acceda a la versión de código abierto en Hugging Face en deepseek-ai/DeepSeek-V3.2. Los desarrolladores descargan pesos y configuraciones directamente, lo que permite la implementación local en clústeres de GPU. Por ejemplo, use la biblioteca Transformers para cargar el modelo:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "deepseek-ai/DeepSeek-V3.2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "Solve this equation: x^2 + 3x - 4 = 0"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200, do_sample=False)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
Este fragmento de código inicializa el modelo con precisión bfloat16 para mayor eficiencia en las GPU NVIDIA modernas. Sin embargo, las ejecuciones locales exigen un hardware sustancial, se recomiendan al menos 8 GPU A100 para una precisión total. En consecuencia, muchos equipos optan por versiones cuantificadas a través de bibliotecas como bitsandbytes para adaptarse al hardware de consumo.
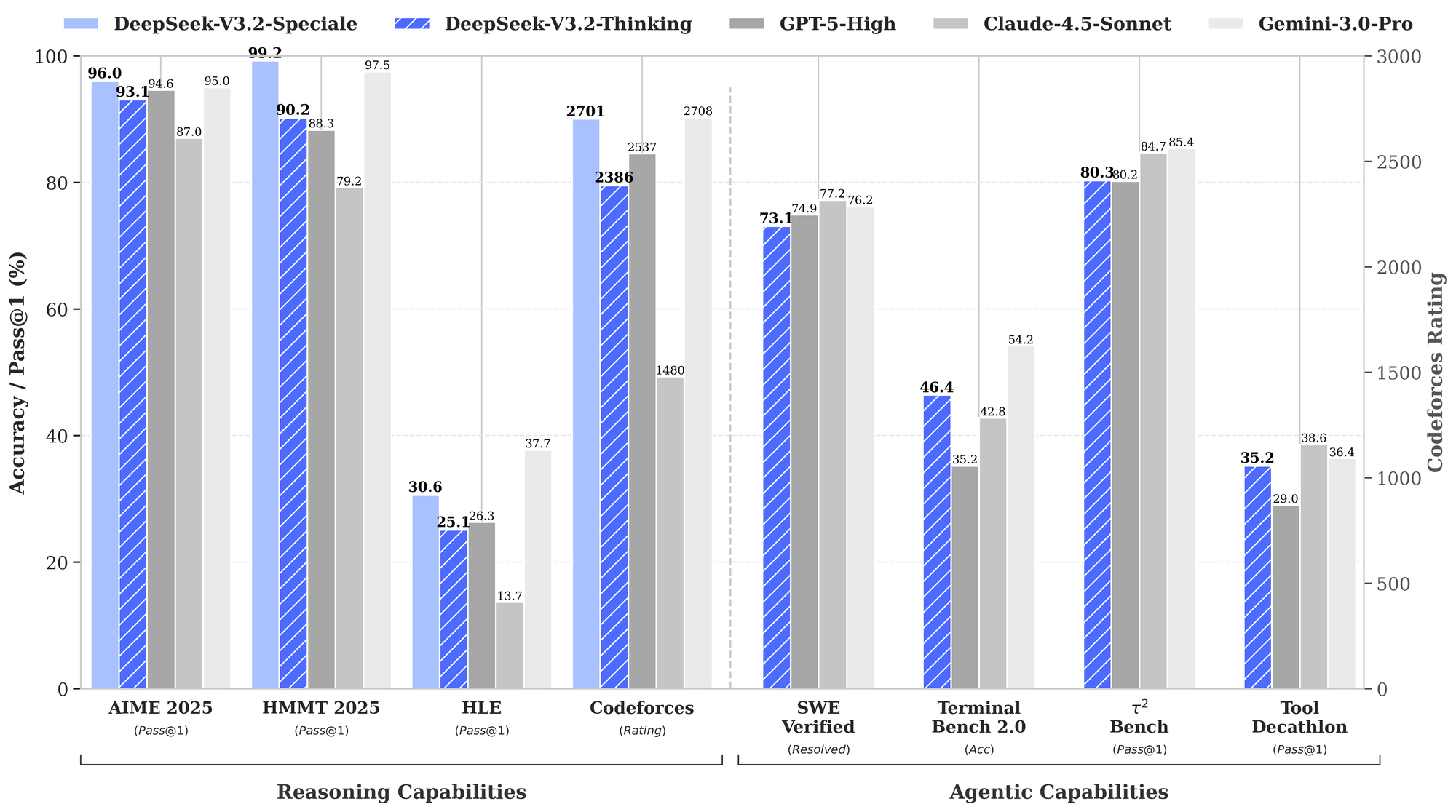
Los puntos de referencia destacan las fortalezas de DeepSeek-V3.2. En tareas de razonamiento, logra un 93.1% en AIME 2025 (pass@1), superando el 90.2% de GPT-5-High. Para capacidades de agente, resuelve 2,537 problemas en SWE-Bench Verified, superando por poco los 2,536 de Claude-4.5-Sonnet. Estas métricas posicionan a DeepSeek-V3.2 como un "conductor diario" equilibrado para entornos de producción, donde la velocidad de inferencia importa tanto como la inteligencia bruta.
Además, el modelo admite extensiones multimodales en futuras actualizaciones, pero las versiones actuales se centran en el razonamiento basado en texto. Los ingenieros lo afinan en conjuntos de datos específicos del dominio utilizando adaptadores LoRA, preservando las capacidades base mientras se adaptan a nichos como el análisis legal o la simulación científica. Como resultado, el acceso de código abierto permite la creación rápida de prototipos sin dependencia del proveedor.
Explorando DeepSeek-V3.2-Speciale: Optimizado para un Rendimiento de Razonamiento Máximo
Mientras que DeepSeek-V3.2 ofrece una amplia utilidad, DeepSeek-V3.2-Speciale está dirigido a escenarios que exigen la máxima profundidad cognitiva. Esta variante empuja los límites del razonamiento, rivalizando con Gemini-3.0-Pro en competiciones de élite. Alcanza resultados de medalla de oro en IMO 2025, CMO, ICPC World Finals e IOI 2025, hazañas que requieren un encadenamiento lógico matizado y una resolución creativa de problemas.
DeepSeek-V3.2-Speciale se basa en la misma fundación MoE, pero incorpora etapas mejoradas de aprendizaje por refuerzo a partir de retroalimentación humana (RLHF), enfatizando los comportamientos de agente. A diferencia del modelo base, genera procesos de pensamiento internos más largos, que consumen más tokens pero producen una precisión superior en tareas como el uso de herramientas en entornos de varios pasos. Por ejemplo, sintetiza datos de entrenamiento en más de 1,800 mundos simulados y más de 85,000 instrucciones, lo que permite un manejo robusto de escenarios no vistos.
Consulte la tarjeta del modelo en Hugging Face en deepseek-ai/DeepSeek-V3.2-Speciale. La descarga sigue un proceso similar:
model_name = "deepseek-ai/DeepSeek-V3.2-Speciale"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto"
)
prompt = "Prove that the sum of angles in a triangle is 180 degrees."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=500, temperature=0.1)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
Observe el indicador trust_remote_code=True, ya que Speciale emplea implementaciones de atención personalizadas. Esta configuración exige aún más VRAM, hasta 1 TB para inferencia no cuantificada, lo que lo hace ideal para laboratorios de investigación en lugar de dispositivos de borde.
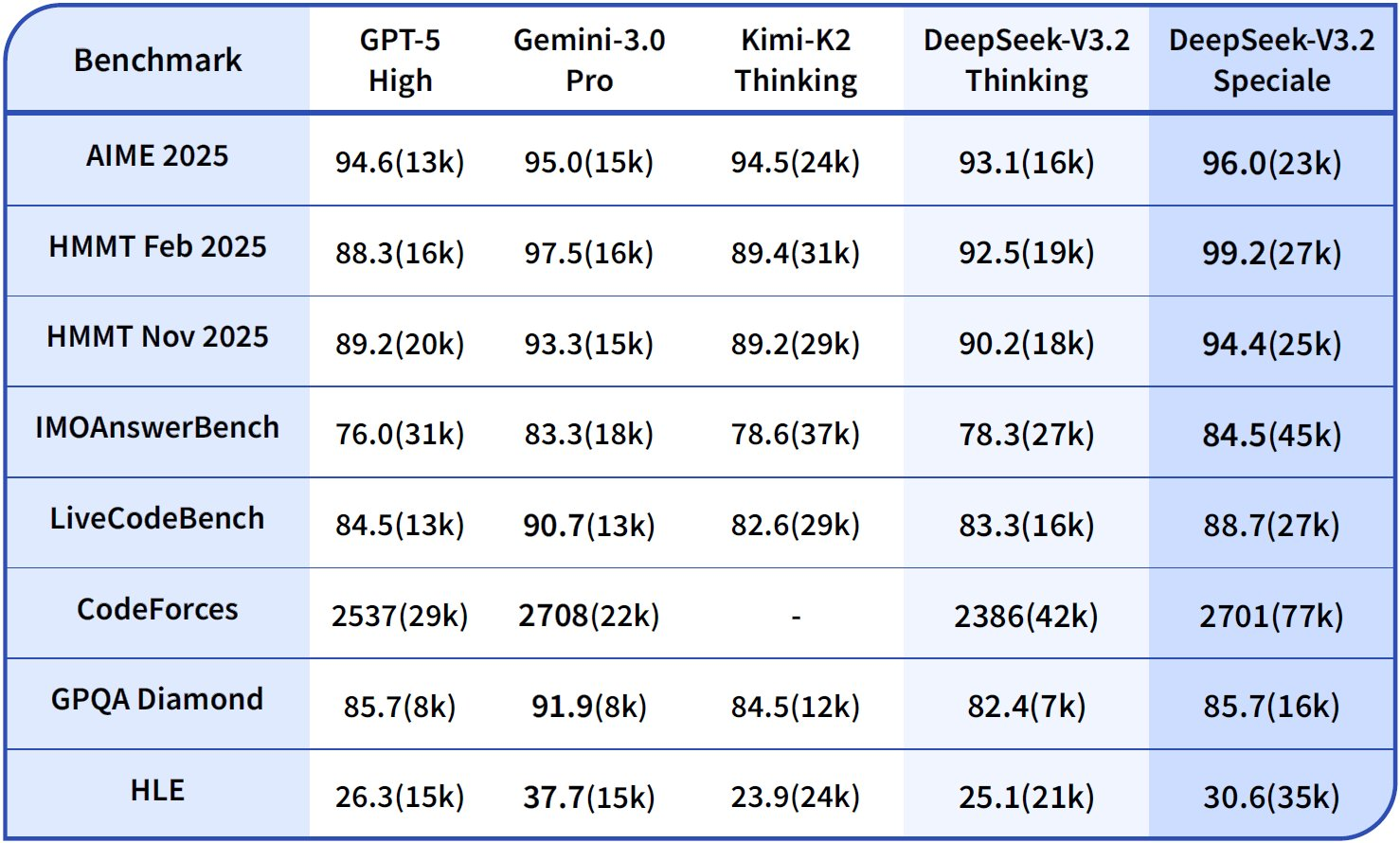
Los datos de rendimiento resaltan su ventaja. El gráfico de referencia proporcionado ilustra que DeepSeek-V3.2-Speciale (barras azules) lidera en razonamiento: 99.0% en HMMT 2025 (pass@1) frente al 97.5% de GPT-5-High, y 84.8% de precisión en Codeforces (rating) frente al 84.7% de Claude-4.5-Sonnet. En dominios de agente, sobresale en Terminal-Bench v0.2 (84.3% de precisión) y Tool-Use (pass@1), a menudo por márgenes estrechos que se acumulan en operaciones encadenadas. Sin embargo, un mayor uso de tokens, hasta un 50% más que V3.2, requiere una ingeniería de prompts cuidadosa para controlar los costos.
Dado que Speciale carece de uso nativo de herramientas en su lanzamiento inicial, los desarrolladores lo encadenan con API externas para agentes híbridos. Este enfoque brilla en las evaluaciones, donde supera a sus pares en más de 85k puntos de referencia de instrucciones. En general, DeepSeek-V3.2-Speciale es adecuado para aplicaciones de alto riesgo, como la demostración automatizada de teoremas o simulaciones de planificación estratégica.
Transición de Código Abierto a API: Por Qué Importa el Acceso Alojado
Las implementaciones locales ofrecen control, pero la escalabilidad introduce complejidades como el aprovisionamiento y mantenimiento de hardware. Los desarrolladores recurren a las API para un acceso instantáneo, una economía de pago por uso y una infraestructura gestionada. DeepSeek proporciona puntos finales alojados tanto para V3.2 como para V3.2-Speciale, lo que garantiza la compatibilidad con las interfaces estilo OpenAI. Este cambio acelera la creación de prototipos, ya que los equipos evitan los obstáculos de configuración y se centran en la integración.
Además, el acceso a la API desbloquea funciones empresariales, como la limitación de velocidad y el almacenamiento en caché, que optimizan las cargas de producción. Por ejemplo, los aciertos de caché reducen drásticamente los costos de entrada, lo que hace que las consultas repetidas sean económicas. Como resultado, las startups y las empresas adoptan estos puntos finales para implementaciones sensibles a los costos.
Acceso a la API de DeepSeek: Configuración Paso a Paso
Los ingenieros acceden a la API de DeepSeek a través de la plataforma oficial. Primero, cree una cuenta y genere una clave de API en la sección "API Keys". Esta clave autentica las solicitudes a través del encabezado Authorization: Bearer YOUR_API_KEY.
La URL base es https://api.deepseek.com/v1. Para DeepSeek-V3.2, use el identificador de modelo deepseek-v3.2. DeepSeek-V3.2-Speciale opera en un punto final temporal: https://api.deepseek.com/v3.2_speciale_expires_on_20251215, disponible hasta el 15 de diciembre de 2025, 15:59 UTC. Después de esta fecha, se fusionará con las ofertas estándar.
Instale el SDK de OpenAI para simplificar:
pip install openai
Luego, configure un cliente:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.deepseek.com/v1"
)
Envíe una solicitud de finalización para DeepSeek-V3.2:
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant focused on reasoning."},
{"role": "user", "content": "Explain quantum entanglement in simple terms."}
],
max_tokens=300,
temperature=0.7
)
print(response.choices[0].message.content)
Para DeepSeek-V3.2-Speciale, ajuste la base_url y el modelo:
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.deepseek.com/v3.2_speciale_expires_on_20251215"
)
response = client.chat.completions.create(
model="deepseek-v3.2-speciale",
messages=[{"role": "user", "content": "Solve: Integrate e^x sin(x) dx."}],
max_tokens=500
)
Estas llamadas devuelven respuestas JSON con estadísticas de uso, incluyendo tokens de prompt y de finalización. Maneje los errores mediante bloques try-except, verificando los límites de velocidad (por ejemplo, 10,000 RPM para V3.2).
Además, habilite los modos de pensamiento agregando /thinking al nombre del modelo, por ejemplo, deepseek-v3.2/thinking. Esto activa el razonamiento paso a paso, ideal para depurar consultas complejas.
Precios de la API: Escalado Rentable para DeepSeek-V3.2 y Speciale
La política de precios es un pilar fundamental para la adopción de la API, y DeepSeek la estructura de forma transparente por millón de tokens. Ambos modelos siguen las mismas tarifas, facturadas por entrada (acierto/fallo de caché) y salida. Los aciertos de caché se aplican a prefijos repetidos dentro de las sesiones, lo que reduce los costos para flujos de trabajo iterativos.
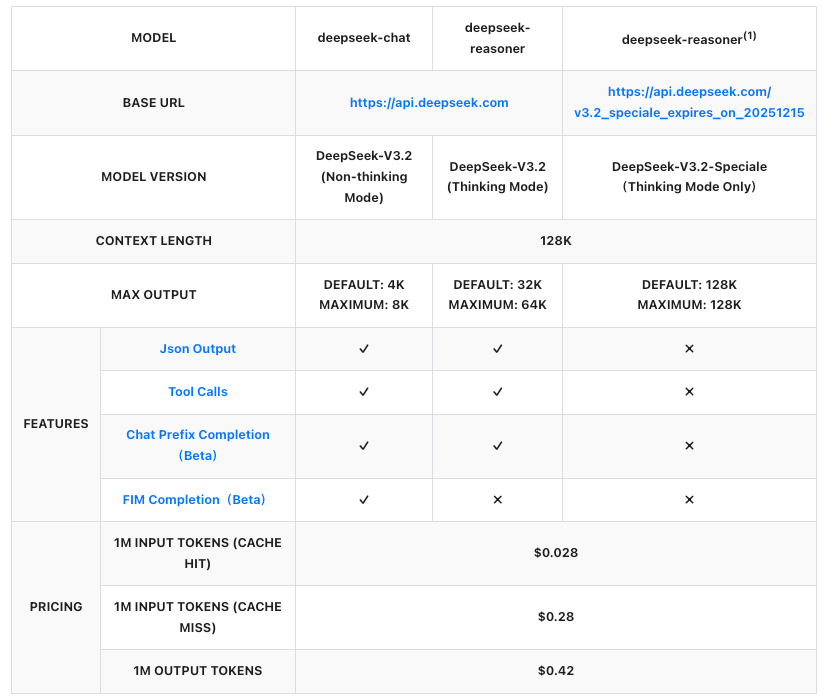
Estas cifras representan reducciones de más del 50% con respecto a versiones anteriores, lo que hace que DeepSeek sea competitivo con las API propietarias. Por ejemplo, generar una respuesta de 1,000 tokens en un prompt de 500 tokens (fallo de caché) cuesta aproximadamente $0.00035, insignificante para la mayoría de los casos de uso. Las empresas negocian planes personalizados para volúmenes más altos, pero el pago por uso se adapta a los desarrolladores.
En consecuencia, los equipos pronostican los gastos utilizando estimadores de tokens en el panel de DeepSeek. Tenga en cuenta el mayor consumo de tokens de Speciale; una consulta intensiva en razonamiento podría duplicar los costos, pero cuadruplicar la precisión en puntos de referencia como Tau² (29.0% pass@1 para Speciale vs. 25.1% para V3.2).
Integración con Apidog: Pruebas y Documentación Eficientes de la API
Los desarrolladores optimizan los flujos de trabajo con herramientas como Apidog, que diseña, prueba y documenta API sin código. Importe su clave API de DeepSeek a las variables de entorno de Apidog, luego cree una nueva colección de solicitudes para los puntos finales V3.2 y Speciale.
Cree una solicitud POST a /chat/completions:
- Encabezados:
Authorization: Bearer {{api_key}},Content-Type: application/json - Cuerpo: Carga JSON con modelo, mensajes y parámetros.
Ejecute pruebas en la interfaz de Apidog, que genera automáticamente respuestas y aserciones. Por ejemplo, valide que la salida de Speciale exceda los 200 tokens en prompts matemáticos. Además, Apidog exporta especificaciones OpenAPI, facilitando las entregas al equipo.
Esta integración reduce el tiempo de depuración en un 40%, ya que las diferencias visuales resaltan las discrepancias. Los equipos también simulan respuestas para el desarrollo sin conexión, asegurando la robustez antes de las implementaciones en vivo.
Técnicas Avanzadas: Uso de Herramientas y Flujos de Trabajo de Agente
DeepSeek-V3.2 introduce el pensamiento en el uso de herramientas, mezclando el razonamiento interno con llamadas externas. Especifique las herramientas en la carga útil de la API:
tools = [
{
"type": "function",
"function": {
"name": "calculator",
"description": "Perform basic math",
"parameters": {
"type": "object",
"properties": {"expression": {"type": "string"}}
}
}
}
]
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[{"role": "user", "content": "What is 15% of 250?"}],
tools=tools,
tool_choice="auto"
)
El modelo razona paso a paso y luego invoca la herramienta si es necesario. Speciale, actualmente sin herramientas, se combina bien como un oráculo de razonamiento en cadenas multimodelo.
Para los agentes, orquestre a través de LangChain: envuelva las llamadas de DeepSeek en agentes que dirijan las tareas dinámicamente. Esta configuración resuelve el 73.1% de los problemas verificados de SWE-Bench, según los puntos de referencia.
Mejores Prácticas para la Implementación en Producción
Optimice los prompts con plantillas de cadena de pensamiento para aprovechar los modos de pensamiento. Supervise el uso de tokens a través de los metadatos de la API, implementando alternativas para los límites de presupuesto. Escale con clientes asíncronos en Python para aplicaciones de alto rendimiento.
La seguridad exige la rotación de claves y el whitelisting de IP. Finalmente, evalúe iterativamente frente a puntos de referencia como los del informe técnico, ajustando los hiperparámetros para adaptarse al dominio.
Conclusión: Aproveche el Poder de DeepSeek Hoy
DeepSeek-V3.2 y DeepSeek-V3.2-Speciale redefinen el razonamiento de IA accesible. Desde la flexibilidad del código abierto hasta la eficiencia de la API, estos modelos empoderan a los desarrolladores para construir agentes más inteligentes. Comience con experimentos locales, migre a puntos finales alojados e integre Apidog para pruebas sin problemas. A medida que evolucionan los puntos de referencia, la trayectoria de DeepSeek promete capacidades aún mayores: posicione sus proyectos a la vanguardia.