
Desarrolladores e investigadores buscan modelos que prioricen el razonamiento para impulsar agentes autónomos. DeepSeek-V3.2 y su variante especializada, DeepSeek-V3.2-Speciale, abordan precisamente esta necesidad. Estos modelos se basan en iteraciones anteriores, como DeepSeek-V3.2-Exp, para ofrecer capacidades mejoradas en inferencia lógica, resolución de problemas matemáticos y flujos de trabajo de agentes. Los ingenieros ahora acceden a herramientas que procesan consultas complejas con eficiencia, superando los puntos de referencia establecidos por los principales sistemas de código cerrado.
Al examinar estos modelos, el foco sigue siendo sus méritos técnicos. Primero, la base de código abierto permite una amplia experimentación. Luego, el acceso a la API proporciona opciones de implementación escalables. A lo largo de esta publicación, los datos de fuentes oficiales y los puntos de referencia ilustran su potencial.
DeepSeek-V3.2 de código abierto: una base para el desarrollo colaborativo de IA
DeepSeek lanza DeepSeek-V3.2 bajo la permisiva licencia MIT, fomentando una adopción generalizada en la comunidad de IA. Esta decisión permite a los desarrolladores inspeccionar, modificar e implementar el modelo sin barreras restrictivas. En consecuencia, los equipos aceleran la innovación en aplicaciones de agentes, desde la generación automatizada de código hasta las tuberías de razonamiento de múltiples pasos.
La arquitectura del modelo se centra en DeepSeek Sparse Attention (DSA), un mecanismo que optimiza las demandas computacionales para el procesamiento de contextos largos. DSA emplea escasez de grano fino, reduciendo la complejidad de la atención de escalas cuadráticas a casi lineales mientras preserva la calidad de la salida. Por ejemplo, en secuencias que superan los 128,000 tokens —equivalentes a cientos de páginas de texto— el modelo mantiene velocidades de inferencia competitivas con sus contrapartes más pequeñas.
DeepSeek-V3.2 cuenta con 685 mil millones de parámetros, distribuidos en tipos de tensores como BF16, F8_E4M3 y F32 para una cuantificación flexible. El entrenamiento incorpora un marco escalable de aprendizaje por refuerzo (RL), donde los agentes aprenden a través de retroalimentación iterativa en tareas sintéticas. Este enfoque refina las rutas de razonamiento, permitiendo al modelo encadenar pasos lógicos de manera efectiva. Además, una tubería de síntesis de tareas de agentes a gran escala genera diversos escenarios, mezclando el razonamiento con la invocación de herramientas. Los desarrolladores acceden a estos a través de los repositorios de Hugging Face, donde residen los pesos preentrenados y los modelos base.
El uso comienza con la codificación de entradas en un formato compatible con OpenAI, facilitada por scripts de Python en el directorio de codificación del modelo. La plantilla de chat introduce un modo de "pensar con herramientas", donde el modelo delibera antes de actuar. Los parámetros de muestreo —temperatura en 1.0 y top_p en 0.95— producen resultados consistentes pero creativos. Para la implementación local, el repositorio de GitHub para DeepSeek-V3.2-Exp ofrece operadores optimizados para CUDA, incluida una variante de TileLang para diversos ecosistemas de GPU.
Además, la licencia MIT garantiza la viabilidad empresarial. Las organizaciones personalizan el modelo para agentes propietarios sin obstáculos legales. Los puntos de referencia validan esta apertura: DeepSeek-V3.2 logra la paridad con GPT-5 en las puntuaciones de razonamiento agregadas, como se detalla en el informe técnico. Así, el código abierto no solo democratiza el acceso, sino que también establece un punto de referencia frente a gigantes propietarios.
DeepSeek-V3.2-Speciale: Mejoras personalizadas para demandas de razonamiento avanzadas
Mientras que DeepSeek-V3.2 sirve para propósitos generales, DeepSeek-V3.2-Speciale se enfoca exclusivamente en el razonamiento profundo. Esta variante aplica un post-entrenamiento de alto cómputo a la misma base de 685B parámetros, amplificando la competencia en la resolución de problemas abstractos. Como resultado, asegura equivalentes a medallas de oro en las Olimpiadas Internacionales de Matemáticas (IMO) y Olimpiadas Internacionales de Informática (IOI) de 2025, superando las líneas base humanas en las soluciones presentadas.
Arquitectónicamente, DeepSeek-V3.2-Speciale se asemeja a su hermano con DSA para un manejo eficiente de contextos largos. Sin embargo, el post-entrenamiento enfatiza el RL en conjuntos de datos curados, incluyendo problemas de olimpiadas y cadenas de agentes sintéticas. Este proceso perfecciona el razonamiento de "cadena de pensamiento" (CoT), donde el modelo descompone las consultas en pasos verificables. Notablemente, omite el soporte para la invocación de herramientas para concentrar recursos en la inferencia pura, lo que lo hace ideal para tareas computacionalmente intensivas como la demostración de teoremas.
La tarjeta del modelo de Hugging Face destaca las diferencias: DeepSeek-V3.2-Speciale procesa entradas sin dependencias externas, basándose en la deliberación interna. Los desarrolladores codifican los mensajes de manera similar, pero las salidas exigen un análisis personalizado debido a la ausencia de plantillas Jinja. El manejo de errores en el código de producción se vuelve crucial, ya que las respuestas mal formadas requieren capas de validación.
En comparaciones, DeepSeek-V3.2-Speciale supera a GPT-5-High en agregados de razonamiento y se alinea con Gemini-3.0-Pro. Por ejemplo, en AIME 2025 (Pass@1), obtiene un 93.1%, superando el 90.2% de Claude-4.5-Sonnet. Estas ganancias provienen de un RL dirigido, que simula escenarios adversarios para robustecer las cadenas lógicas. En consecuencia, los investigadores lo implementan para tareas de vanguardia, como la verificación de código de las Finales Mundiales de ICPC o las pruebas de CMO 2025, con activos disponibles en el repositorio.
En general, DeepSeek-V3.2-Speciale amplía el alcance del ecosistema. Complementa el modelo base manejando casos extremos donde la profundidad supera la amplitud, asegurando una cobertura integral para los constructores de agentes.
Evaluación comparativa de capacidades de razonamiento y agentes: información basada en datos
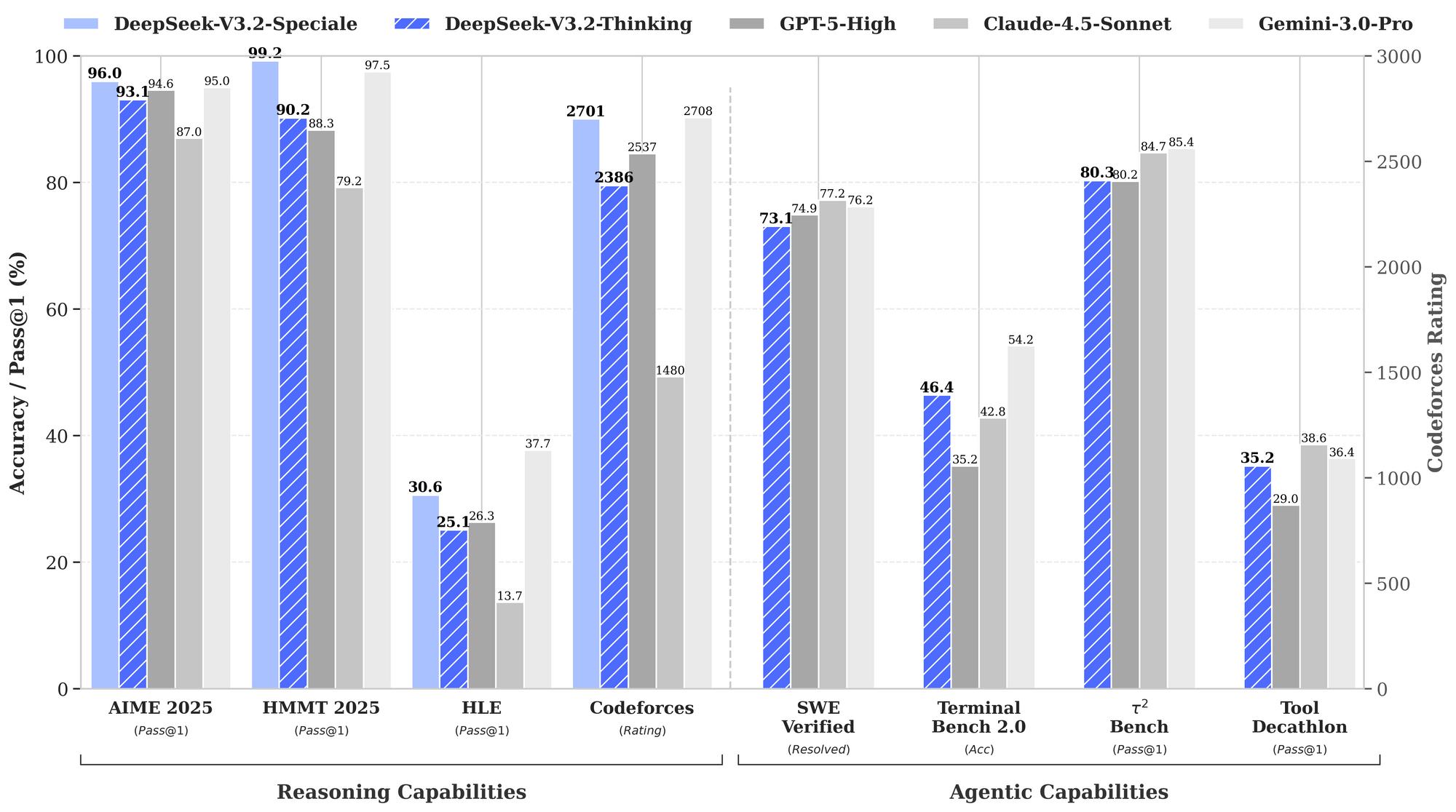
Los puntos de referencia cuantifican las fortalezas de DeepSeek-V3.2, particularmente en los dominios de razonamiento y agentes. El gráfico de rendimiento proporcionado ilustra las tasas de aprobación y las precisiones en evaluaciones clave, posicionando estos modelos frente a GPT-5-High, Claude-4.5-Sonnet y Gemini-3.0-Pro.
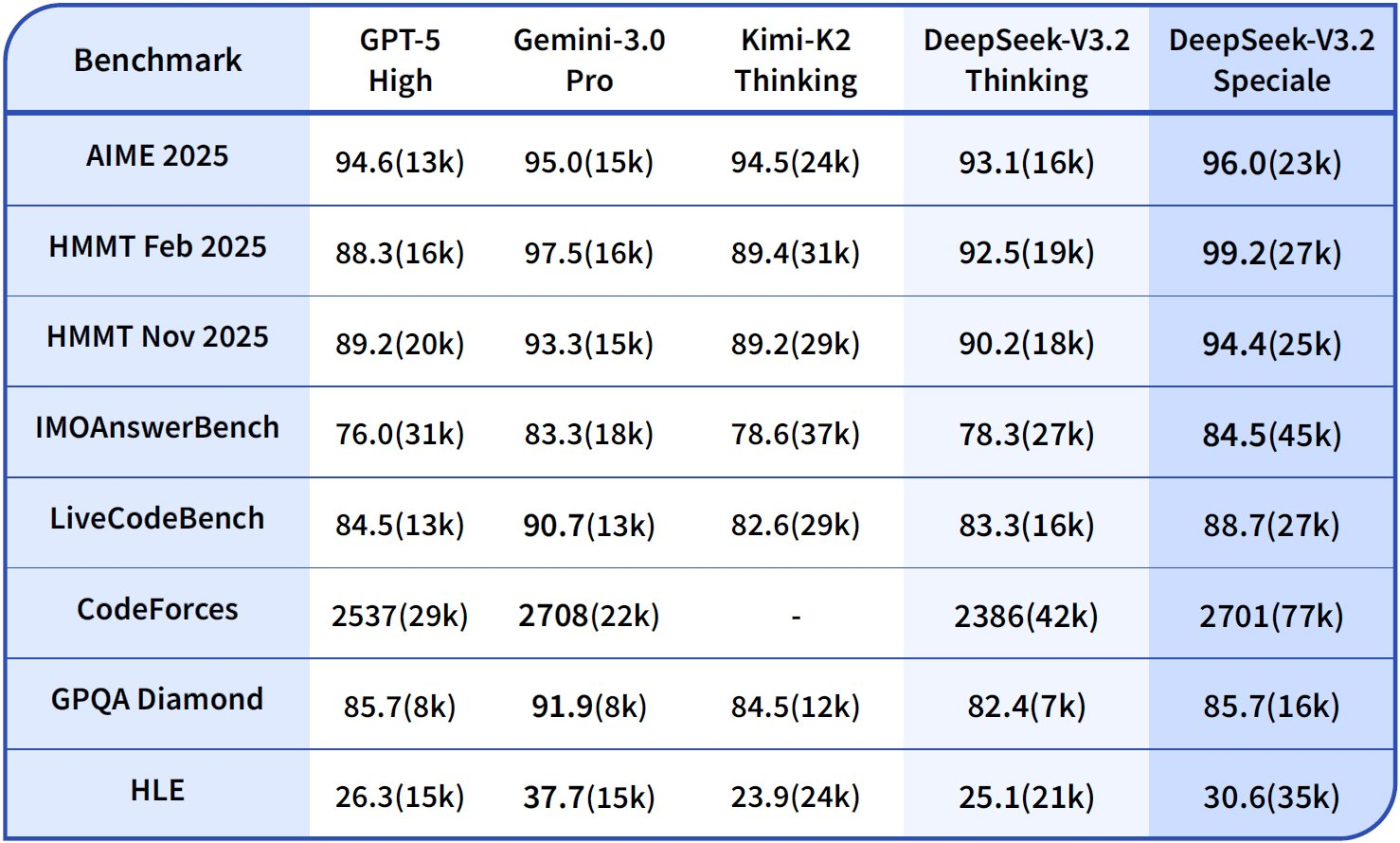
En capacidades de razonamiento, DeepSeek-V3.2-Thinking (una configuración de alto cómputo similar a Speciale) lidera con un 93.1% en AIME 2025 (Pass@1), superando el 90.8% de GPT-5-High y el 87.0% de Claude-4.5-Sonnet. De manera similar, en HMMT 2025, alcanza un 94.6%, lo que refleja una descomposición matemática superior. La evaluación HLE muestra un 95.0% de Pass@1, donde el modelo resuelve acertijos lógicos complejos en inglés con mínimos reintentos.
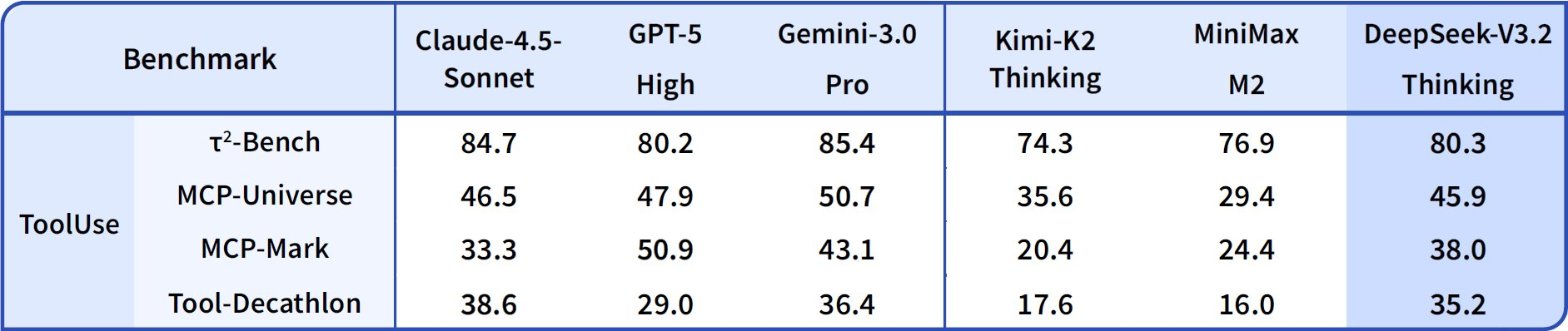
En cuanto a las capacidades de agente, DeepSeek-V3.2 destaca en codificación y uso de herramientas. La calificación de Codeforces alcanza los 2708 para el modo Thinking, superando los 2537 de Gemini-3.0-Pro. Esta métrica agrega problemas resueltos bajo limitaciones de tiempo, enfatizando la eficiencia algorítmica. En SWE-Verified (resuelto), logra un 73.1%, lo que indica una detección de errores y generación de correcciones fiable en bases de código verificadas.
La precisión de Terminal Bench 2.0 se sitúa en un 80.3%, donde el modelo navega por entornos de shell mediante comandos en lenguaje natural. T² (Pass@1) obtiene un 84.8%, evaluando tareas aumentadas con herramientas como la recuperación y síntesis de datos. La evaluación de herramientas alcanza un 84.7%, con el modelo invocando API y analizando respuestas con precisión.
DeepSeek-V3.2-Speciale amplifica estos resultados en subconjuntos de razonamiento puro. Por ejemplo, impulsa AIME a un 99.2% y HMMT a un 99.0%, acercándose a la perfección en matemáticas de estilo olímpico. Sin embargo, sus puntuaciones de agente se ajustan a la baja sin soporte de herramientas —por ejemplo, Herramienta en 73.1% frente al 84.7% de la base— priorizando la profundidad sobre la integración.
Estos resultados provienen de protocolos estandarizados: Pass@1 mide el éxito de un solo intento, mientras que las calificaciones incorporan una escala tipo Elo. En comparación con las bases, los modelos DeepSeek cierran la brecha de código abierto, con DSA permitiendo un ahorro del 50% en cómputo en contextos largos. Así, los puntos de referencia no solo validan las afirmaciones, sino que guían la selección: use V3.2 para agentes equilibrados, Speciale para lógica intensiva.
| Referencia | Métrica | DeepSeek-V3.2 | DeepSeek-V3.2-Speciale | GPT-5-High | Claude-4.5-Sonnet | Gemini-3.0-Pro |
|---|---|---|---|---|---|---|
| AIME 2025 | Pass@1 (%) | 93.1 | 99.2 | 90.8 | 87.0 | 90.2 |
| HMMT 2025 | Pass@1 (%) | 94.6 | 99.0 | 91.4 | 83.3 | 95.0 |
| HLE | Pass@1 (%) | 95.0 | 97.5 | 92.8 | 79.2 | 98.3 |
| Codeforces | Clasificación | 2701 | 2708 | 2537 | 2386 | 2537 |
| SWE-Verified | Resuelto (%) | 73.1 | 77.2 | 71.9 | 73.1 | 64.4 |
| Terminal Bench 2.0 | Precisión (%) | 80.3 | 80.6 | 84.7 | 85.4 | 80.3 |
| T² | Pass@1 (%) | 84.8 | 83.2 | 82.0 | 82.9 | 78.5 |
| Herramienta | Pass@1 (%) | 84.7 | 73.1 | 74.9 | 77.2 | 76.2 |
Esta tabla agrega datos gráficos, destacando un liderazgo consistente en el razonamiento mientras se mantiene la competitividad en la agencia.
Acceso a la API de DeepSeek: integración perfecta para implementaciones escalables
Los pesos de código abierto invitan a ejecuciones locales, pero el acceso a la API escala los agentes de producción sin esfuerzo. DeepSeek-V3.2 se implementa a través de la API oficial, junto con interfaces de aplicaciones y web. Los desarrolladores se autentican con claves API desde el panel de la plataforma, luego consultan los puntos finales en JSON compatible con OpenAI.
Para DeepSeek-V3.2-Speciale, el acceso se limita solo a la API, lo que se adapta a las necesidades de alto cómputo sin sobrecarga local. Los puntos finales admiten parámetros como herramientas para la invocación, aunque Speciale procesa el razonamiento sin herramientas. Las ventanas de contexto se extienden hasta 128,000 tokens, con aciertos de caché que optimizan las consultas repetidas.
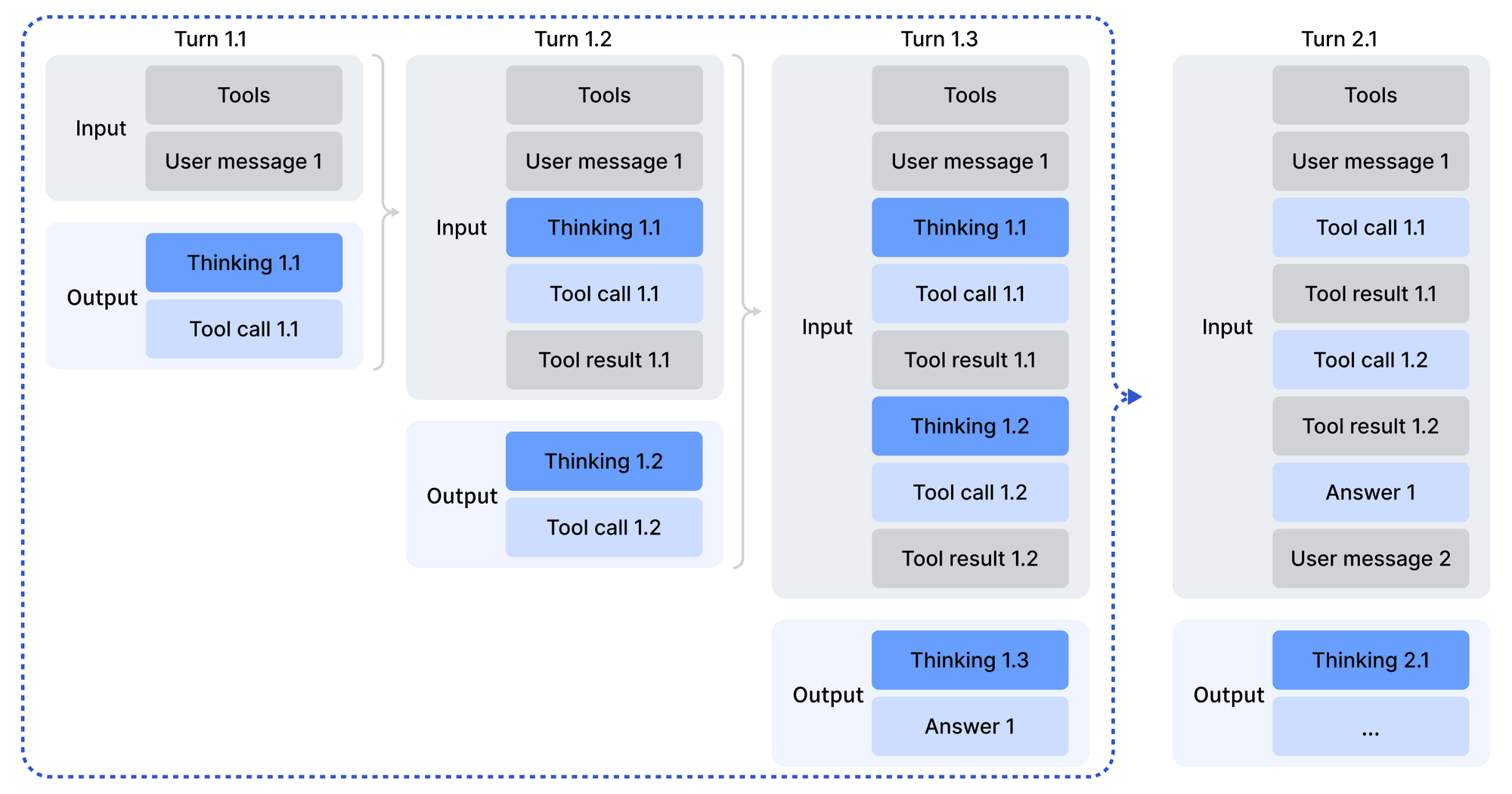
La integración aprovecha los SDK en Python, Node.js y cURL. Una llamada de ejemplo codifica las indicaciones con el rol de desarrollador para escenarios de agentes:
import openai
client = openai.OpenAI(
api_key="your_deepseek_key",
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[{"role": "developer", "content": "Solve this IMO problem: ..."}],
temperature=1.0,
top_p=0.95
)
Esta estructura analiza las salidas a través de scripts proporcionados, manejando las llamadas a herramientas cuando corresponda. En consecuencia, los agentes encadenan respuestas, invocando servicios externos en medio del razonamiento.
Para mejorar este flujo de trabajo, Apidog resulta invaluable. Simula respuestas de API, documenta esquemas y prueba casos extremos, directamente aplicable a los puntos finales de DeepSeek. Descargue Apidog gratis para visualizar los flujos de solicitudes y garantizar una lógica de agente robusta antes de la implementación.
Precios de la API: eficiencia de costos con alto rendimiento
El precio de la API de DeepSeek enfatiza la asequibilidad, con el lanzamiento de V3.2-Exp reduciendo a la mitad los costos de V3.1-Terminus. Los desarrolladores pagan por millón de tokens: $0.028 por aciertos de caché de entrada, $0.28 por fallos y $0.42 por salidas. Esta estructura recompensa los contextos repetidos, vital para los bucles de agentes.
En comparación con la competencia, estas tarifas son más bajas que los $15–$75 por millón de salidas de GPT-5. Los mecanismos de caché —que aciertan al 10% del costo de un fallo— permiten sesiones largas económicas. Para una interacción de agente de 10,000 tokens (80% de aciertos de caché), los costos caen por debajo de $0.01, escalando linealmente.
Los niveles gratuitos ofrecen acceso inicial, pasando a un modelo de pago por uso para desarrolladores. Los planes empresariales personalizan los volúmenes, pero las tarifas base son suficientes para la mayoría. Así, el precio se alinea con el espíritu de código abierto, democratizando el razonamiento avanzado.
Una calculadora estima: para 1 millón de tokens de entrada (50% de aciertos) y 200,000 salidas, el total se aproxima a $0.20 —una fracción en comparación con las alternativas. Esta eficiencia impulsa tareas masivas, desde revisiones de código hasta síntesis de datos.
Análisis técnico profundo: arquitectura e innovaciones de entrenamiento
DSA forma el núcleo, esparciendo dinámicamente las matrices de atención. Para la posición i, atiende a ventanas locales y claves globales, reduciendo las operaciones FLOPs en un 40% en contextos de 100k. La cuantificación a F8_E4M3 reduce la memoria a la mitad sin pérdida de precisión, permitiendo implementaciones 8x A100.

El entrenamiento abarca preentrenamiento en 10T tokens, ajuste fino supervisado y RLHF con recompensas de agente. La tubería de síntesis genera más de 1M de tareas, simulando la agencia del mundo real. El post-entrenamiento para Speciale asigna 10 veces el cómputo, destilando el razonamiento de las trayectorias.
Estas innovaciones producen comportamientos emergentes: autocorrección en el 85% de los fallos de HLE y un 92% de éxito de herramientas en T². Futuras iteraciones podrían incorporar multimodalidad, según las hojas de ruta.
Conclusión: posicionando DeepSeek para el futuro de los agentes
DeepSeek-V3.2 y DeepSeek-V3.2-Speciale redefinen el razonamiento de código abierto. Los puntos de referencia confirman su ventaja, el acceso abierto invita a la colaboración y las API asequibles permiten la escalabilidad. Los desarrolladores construyen agentes superiores, desde solucionadores de olimpiadas hasta automatizadores empresariales.
A medida que la IA evoluciona, estos modelos sientan precedentes. Experimente hoy: descargue los pesos de Hugging Face, integre a través de la API y pruebe con Apidog. El camino hacia sistemas inteligentes comienza aquí.