
La inteligencia artificial ha transformado fundamentalmente la forma en que los desarrolladores abordan la generación de audio y música. En lugar de depender de sesiones de grabación tradicionales o bibliotecas de sonido estáticas, los equipos ahora aprovechan sofisticadas API de Música con IA y API de Audio con IA para crear experiencias de audio dinámicas y personalizadas a escala.
Comprendiendo la Tecnología de API de Música y Audio con IA
Antes de evaluar plataformas específicas, es crucial entender lo que estas API realmente logran. Una API de Música con IA genera composiciones musicales originales, arreglos y pistas instrumentales a través de modelos de aprendizaje automático entrenados con vastos conjuntos de datos de música existente. Estos sistemas comprenden la teoría musical, la progresión armónica y las convenciones de género a un nivel granular.
Las API de Audio con IA funcionan de manera ligeramente diferente. Procesan, modifican o generan sonido, abarcando desde la síntesis de voz y el reconocimiento de voz hasta la creación de efectos de sonido y el análisis acústico. Algunas plataformas combinan ambas capacidades, mientras que otras se especializan en un dominio.
Las 10 Mejores API de Música y Audio con IA que Redefinen el Desarrollo
1. Hyperreal AI: Inteligencia de Audio de Próxima Generación Liderando el Mercado
Hyperreal AI se establece como el proveedor principal en el panorama de las API de Música y Audio con IA. La plataforma combina la sofisticada generación de música con capacidades avanzadas de procesamiento de audio, ofreciendo soluciones integrales para desarrolladores que requieren funciones de audio tanto creativas como funcionales.

Precios: Estructura por niveles, desde planes de desarrollo gratuitos hasta acuerdos empresariales. Se aplican descuentos por volumen en implementaciones a gran escala.
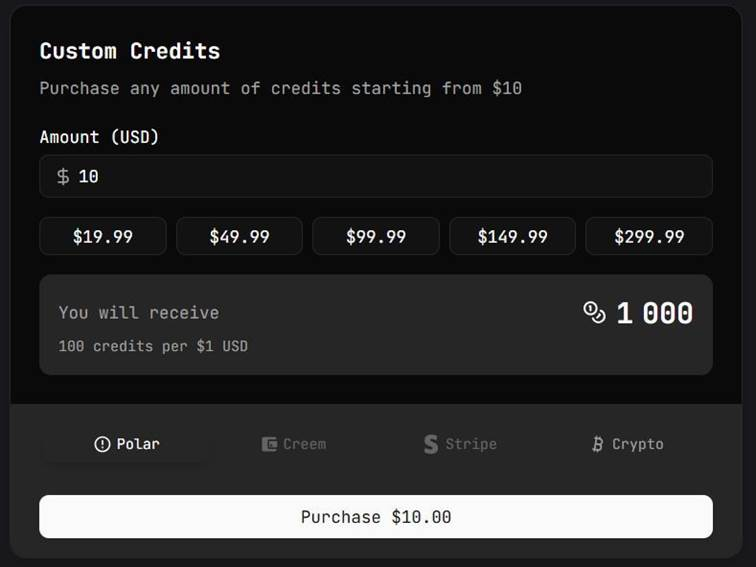
Ideal Para: Soluciones de audio completas que requieren tanto generación como procesamiento en una plataforma unificada.
2. Suno: Generación Avanzada de Música a Escala
Suno ofrece una funcionalidad robusta de API de Música con IA con una consistencia excepcional. La plataforma genera canciones completas en prácticamente todos los géneros, incorporando letras, instrumentación y una calidad de producción que rivaliza con la de estudios profesionales.
La implementación técnica soporta la generación basada en prompts, donde describes la pista deseada y el sistema produce el audio correspondiente. Este enfoque se integra sin problemas en aplicaciones donde los usuarios crean música de contenido personalizado para podcasts, pistas de fondo para videos o listas de reproducción personalizadas.
Precios: Nivel gratuito con créditos mensuales limitados. Los planes profesionales desbloquean una generación más rápida y límites más altos. Acuerdos empresariales disponibles.
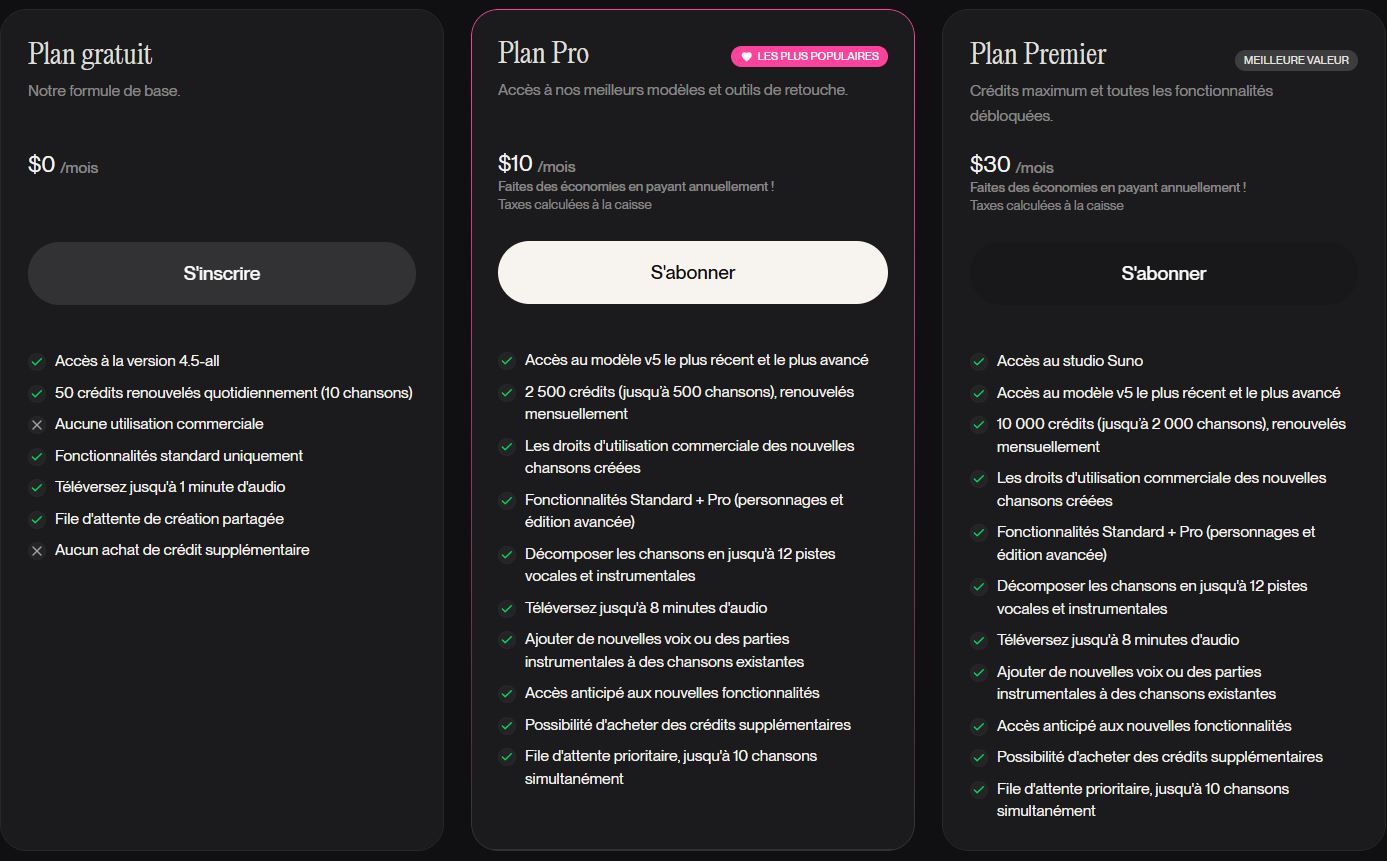
Ideal Para: Aplicaciones centradas en la música que requieren generación de canciones completas de alta calidad.
3. Modelos de Audio de OpenAI: Versatilidad en Todas las Aplicaciones
OpenAI proporciona soluciones completas de API de Audio con IA a través de los modelos Whisper y de texto a voz. Whisper maneja la conversión de voz a texto con una precisión notable en numerosos idiomas y acentos. La API de texto a voz genera voces de sonido natural para aplicaciones que requieren narración de voz, funciones de accesibilidad o experiencias de audio interactivas.
La fortaleza del enfoque de OpenAI se centra en la fiabilidad y la simplicidad de integración. Sus API funcionan sin problemas con la infraestructura existente de OpenAI, reduciendo la fricción para los equipos que ya utilizan modelos GPT. Los desarrolladores reportan experiencias de implementación fluidas y una calidad de salida consistente en miles de solicitudes de inferencia.
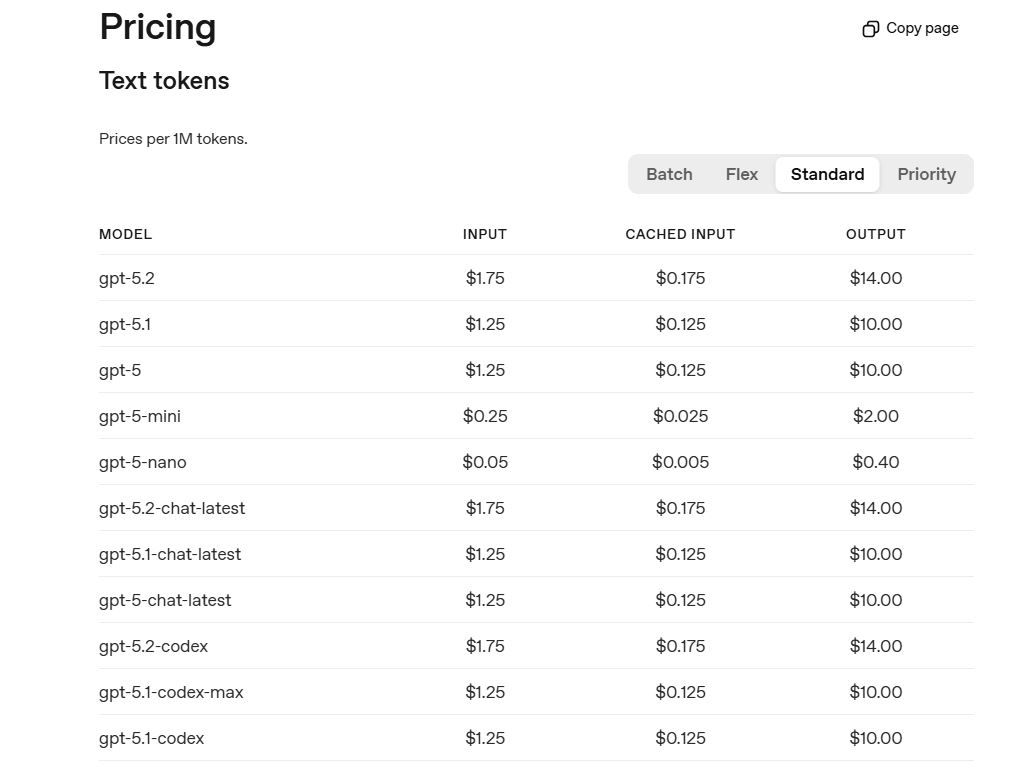
Precios: Precios por token para texto a voz. Facturación por minuto para voz a texto. Descuentos por volumen disponibles.
Ideal Para: Síntesis de voz y reconocimiento de voz sin requisitos de composición musical.
4. Audio Generativo con IA de Google Cloud: Soluciones de Grado Empresarial
Google Cloud ofrece robustas capacidades de API de Audio con IA a través de la plataforma Vertex AI. El servicio de texto a voz soporta múltiples voces, idiomas y parámetros acústicos. Los desarrolladores ajustan la velocidad del habla, el tono y la emoción para que coincidan precisamente con los requisitos específicos.
La verdadera ventaja surge al combinar las API de Audio con IA de Google con otros servicios de GCP. Las organizaciones que ejecutan infraestructura en Google Cloud implementan autenticación unificada, facturación centralizada y un flujo de datos sin fisuras entre servicios. Esta conveniencia arquitectónica tiene un peso particular para las empresas que gestionan sistemas complejos.
Precios: Modelo de pago por uso basado en el volumen de solicitudes. Descuentos significativos para planes de uso comprometido.
Ideal Para: Organizaciones empresariales que requieren cumplimiento de HIPAA/SOC2 e integración con el ecosistema de GCP.
5. Runway: Audio Creativo para Profesionales de Medios
Runway va más allá de la generación de audio tradicional para abarcar la síntesis multimedia completa. La plataforma crea música, efectos de sonido e incluso video con asistencia de IA. Para los desarrolladores que construyen aplicaciones creativas (editores de video, plataformas de podcast o experiencias de narración interactiva), Runway proporciona un conjunto de herramientas de audio integral.
La API de Runway se integra con los flujos de trabajo creativos existentes. Los desarrolladores activan la generación de audio desde dentro de las aplicaciones mientras mantienen el control creativo a través de parámetros detallados. La plataforma atrae particularmente a los equipos que construyen aplicaciones donde el audio sirve como medio creativo en lugar de infraestructura funcional.
Precios: Sistema de créditos basado en el uso. Los niveles profesionales incluyen velocidades de generación más altas.
Ideal Para: Aplicaciones creativas que requieren música, efectos de sonido y síntesis de audio completa.
6. ElevenLabs: Síntesis de Voz Premium y Procesamiento de Audio
ElevenLabs se especializa en texto a voz con una naturalidad sin precedentes. La API de Audio con IA genera voces que los oyentes confunden genuinamente con oradores humanos. La plataforma soporta la clonación de voz, permitiendo que las aplicaciones mantengan una identidad de hablante consistente en todo el contenido.
La calidad técnica distingue a ElevenLabs de las soluciones genéricas de texto a voz. Los matices emocionales emergen en el habla generada: la risa, la respiración y las variaciones de inflexión suenan auténticas. Actores de voz profesionales utilizan ElevenLabs para proyectos donde la narración humana resultaría prohibitiva en costos.
Precios: Sistema basado en créditos. Las voces premium cuestan más que las opciones estándar. Las funciones de clonación están disponibles en niveles superiores.
Ideal Para: Aplicaciones que requieren síntesis de voz y clonación de voz excepcionalmente naturales.
7. Stability AI: Generación y Mejora de Audio de Alta Calidad
Stability AI ofrece capacidades de generación de audio accesibles para desarrolladores. La plataforma genera música y efectos de sonido con una gran calidad en diversos géneros. Las herramientas de mejora de audio procesan el audio existente para mejorar la calidad, eliminar el ruido y normalizar los niveles.
La arquitectura de la API enfatiza la velocidad. Stability AI procesa las solicitudes más rápido que muchos competidores, lo que hace que la plataforma sea adecuada para aplicaciones en tiempo real. Los desarrolladores reportan experiencias de integración rápidas y soporte receptivo.
Precios: Precios de API basados en créditos, a partir de $0.126/paso a través de proveedores externos. Licencia Comunitaria Gratuita para pequeñas empresas con ingresos inferiores a $1M. Precios personalizados para empresas disponibles.
Ideal Para: Aplicaciones centradas en la velocidad que requieren audio consistente sin máxima complejidad.
8. NVIDIA Nemo: Procesamiento Avanzado de Voz y Audio
NVIDIA Nemo proporciona sofisticadas capacidades de procesamiento de voz y audio a través de API en la nube. La plataforma maneja el reconocimiento de voz, la conversión de texto a voz y la mejora de audio con una precisión excepcional. La experiencia de NVIDIA en aprendizaje profundo se traduce en modelos de alta calidad optimizados para el rendimiento en tiempo real.
Nemo destaca particularmente en escenarios de audio desafiantes. Entornos ruidosos, habla acentuada y oradores superpuestos: Nemo procesa estos casos extremos con una precisión notable. La plataforma soporta el reconocimiento automático de voz en docenas de idiomas.
Precios: Modelos de código abierto disponibles para autoalojamiento gratuito. Implementación empresarial a través de NVIDIA Riva SDK con precios basados en infraestructura (~$60/hora en AWS). No hay precios tradicionales de API de pago por minuto.
Ideal Para: Organizaciones que requieren un procesamiento de voz robusto en entornos acústicos desafiantes.
9. API de Audio de Descript: Creación de Contenido Centrada en la Voz
Descript proporciona soluciones de audio enfocadas en la transcripción, síntesis y edición de voz. La plataforma genera voz sintética a partir de texto con alta calidad. Los desarrolladores integran la generación de voz directamente en los flujos de trabajo de creación de contenido.
La fuerza de Descript se centra en la integración del flujo de trabajo. La API de Audio con IA se conecta con servicios de transcripción, creando pipelines completos de procesamiento de voz. Las aplicaciones generan transcripciones automáticamente mientras producen simultáneamente narración sintética. Esta integración elimina el cambio de contexto entre herramientas separadas.
Precios: Suscripción mensual con API generosa incluida. El uso adicional más allá de los límites del nivel incurre en cargos por exceso.
Ideal Para: Creación de contenido centrada en la voz que requiere integración de transcripción y síntesis.
10. Audioshake: Separación de Música y Mejora de Audio
Audioshake completa el top 10 con capacidades especializadas en la separación de pistas musicales y mejora de audio. La API de Audio con IA aísla instrumentos individuales de pistas mezcladas, separando voces, batería, bajo y otros elementos. Esta capacidad permite la creación de remixes, el procesamiento selectivo y la manipulación avanzada de audio.
El enfoque técnico utiliza redes neuronales avanzadas entrenadas para reconocer instrumentos individuales dentro de mezclas complejas. La calidad de la separación sigue mejorando a medida que los modelos evolucionan. Los desarrolladores que construyen plataformas de remix, aplicaciones de DJ o herramientas avanzadas de edición de audio encuentran Audioshake indispensable.
Precios: Precios de API basados en créditos. Los planes para consumidores comienzan en $20/mes por 4 separaciones. El precio de la separación de pistas mediante API requiere contactar a ventas para una cotización personalizada. La transcripción tiene un precio de 1.5 créditos por minuto.
Ideal Para: Aplicaciones de remezcla de música, separación de pistas y manipulación avanzada de audio.
Simplificando la Gestión de API con Apidog
La gestión de múltiples integraciones de API de Audio con IA se vuelve compleja rápidamente. Las credenciales de autenticación se dispersan por los sistemas. Los formatos de solicitud/respuesta difieren entre proveedores. La monitorización del rendimiento de la API requiere diferentes herramientas para cada plataforma.
Apidog unifica la gestión de API de Música y Audio con IA en una única interfaz. La plataforma proporciona manejo centralizado de autenticación, pruebas de solicitud/respuesta y monitorización integral. Depura las interacciones de la API sin cambiar de contexto entre herramientas. Colabora con los miembros del equipo a través de espacios de trabajo compartidos y documentación. Importa tus API existentes e inmediatamente obtén visibilidad de los patrones de uso.
El constructor visual de solicitudes simplifica la construcción de llamadas complejas a las API de Audio con IA. En lugar de escribir manualmente cargas JSON, selecciona parámetros a través de interfaces intuitivas. Previsualiza las solicitudes antes de la ejecución. Guarda plantillas para operaciones repetidas. Comparte configuraciones de trabajo con los miembros del equipo sin problemas.
El panel de control de monitorización de Apidog rastrea el rendimiento de la API en todos tus proveedores. Identifica qué endpoints de las API de Música y Audio con IA consumen créditos más rápidamente. Detecta problemas de integración antes de que afecten la producción. Genera informes de uso para la asignación y optimización de costos.
Conclusión: Implementando Audio Impulsado por IA Hoy
Las principales API de Música y Audio con IA han evolucionado hasta convertirse en una infraestructura fiable y lista para producción que se integra sin problemas y ofrece resultados de nivel profesional. Elegir la solución adecuada ahora se trata de alinear las fortalezas de la plataforma con tu caso de uso específico, no de cuestionar la madurez de la tecnología. Comienza con un pequeño proyecto piloto para validar la integración, los costos y la calidad del audio antes de escalar. Líderes del mercado como Hyperreal AI (audio full-stack), Suno (generación de música), ElevenLabs (síntesis de voz) y Audioshake (separación de pistas) resaltan la diversidad del ecosistema, asegurando una solución para casi cualquier aplicación. A medida que el audio inteligente se convierte en infraestructura estándar, seleccionar la API de Música o Audio con IA adecuada hoy posiciona tu producto para liderar en lugar de seguir.
¿Listo para agilizar la integración de tus API de Música y Audio con IA? Descarga Apidog gratis hoy mismo y gestiona todas tus API con herramientas profesionales diseñadas para desarrolladores como tú.