
The world of Artificial Intelligence (AI) is evolving at breakneck speed, with Large Language Models (LLMs) like ChatGPT, Claude, and Gemini capturing imaginations worldwide. These powerful tools can write code, draft emails, answer complex questions, and even generate creative content. However, using these cloud-based services often comes with concerns about data privacy, potential costs, and the need for a constant internet connection.
Enter Ollama.
Ollama is a powerful, open-source tool designed to democratize access to large language models by enabling you to download, run, and manage them directly on your own computer. It simplifies the often complex process of setting up and interacting with state-of-the-art AI models locally.
Why Use Ollama?

Running LLMs locally with Ollama offers several compelling advantages:
- Privacy: Your prompts and the model's responses stay on your machine. No data is sent to external servers unless you explicitly configure it to do so. This is crucial for sensitive information or proprietary work.
- Offline Access: Once a model is downloaded, you can use it without an internet connection, making it perfect for travel, remote locations, or situations with unreliable connectivity.
- Customization: Ollama allows you to easily modify models using 'Modelfiles', letting you tailor their behavior, system prompts, and parameters to your specific needs.
- Cost-Effective: There are no subscription fees or per-token charges. The only cost is the hardware you already own and the electricity to run it.
- Exploration & Learning: It provides a fantastic platform for experimenting with different open-source models, understanding their capabilities and limitations, and learning more about how LLMs work under the hood.
This article is designed for beginners who are comfortable using a command-line interface (like Terminal on macOS/Linux or Command Prompt/PowerShell on Windows) and want to start exploring the world of local LLMs with Ollama. We'll guide you through understanding the basics, installing Ollama, running your first model, interacting with it, and exploring basic customization.
Want an integrated, All-in-One platform for your Developer Team to work together with maximum productivity?
Apidog delivers all your demands, and replaces Postman at a much more affordable price!

How Does Ollama Work?
Before diving into the installation, let's clarify a few fundamental concepts.
What are Large Language Models (LLMs)?
Think of an LLM as an incredibly advanced autocomplete system trained on vast amounts of text and code from the internet. By analyzing patterns in this data, it learns grammar, facts, reasoning abilities, and different styles of writing. When you give it a prompt (input text), it predicts the most likely sequence of words to follow, generating a coherent and often insightful response. Different LLMs are trained with different datasets, sizes, and architectures, leading to variations in their strengths, weaknesses, and personalities.
How Does Ollama Work?
Ollama acts as a manager and runner for these LLMs on your local machine. Its core functions include:
- Model Downloading: It fetches pre-packaged LLM weights and configurations from a central library (similar to how Docker pulls container images).
- Model Execution: It loads the chosen model into your computer's memory (RAM) and potentially utilizes your graphics card (GPU) for acceleration.
- Providing Interfaces: It offers a simple command-line interface (CLI) for direct interaction and also runs a local web server that provides an API (Application Programming Interface) for other applications to communicate with the running LLM.
Hardware Requirements for Ollama: Can My Computer Run It?
Running LLMs locally can be demanding, primarily on your computer's RAM (Random Access Memory). The size of the model you want to run dictates the minimum RAM required.
- Small Models (e.g., ~3 Billion parameters like Phi-3 Mini): Might run reasonably well with 8GB of RAM, though more is always better for smoother performance.
- Medium Models (e.g., 7-8 Billion parameters like Llama 3 8B, Mistral 7B): Generally require at least 16GB of RAM. This is a common sweet spot for many users.
- Large Models (e.g., 13B+ parameters): Often necessitate 32GB of RAM or more. Very large models (70B+) may require 64GB or even 128GB.
Other Factors You might need to consider:
- CPU (Central Processing Unit): While important, most modern CPUs are adequate. Faster CPUs help, but RAM is usually the bottleneck.
- GPU (Graphics Processing Unit): Having a powerful, compatible GPU (especially NVIDIA GPUs on Linux/Windows or Apple Silicon GPUs on macOS) can significantly accelerate model performance. Ollama automatically detects and utilizes compatible GPUs if the necessary drivers are installed. However, a dedicated GPU is not strictly required; Ollama can run models on the CPU alone, albeit more slowly.
- Disk Space: You'll need sufficient disk space to store the downloaded models, which can range from a few gigabytes to tens or even hundreds of gigabytes, depending on the size and number of models you download.
Recommendation for Beginners: Start with smaller models (like phi3, mistral, or llama3:8b) and ensure you have at least 16GB of RAM for a comfortable initial experience. Check the Ollama website or model library for specific RAM recommendations for each model.
How to Install Ollama on Mac, Linux, and Windows (Using WSL)
Ollama supports macOS, Linux, and Windows (currently in preview, often requiring WSL).
Step 1: Prerequisites
- Operating System: A supported version of macOS, Linux, or Windows (with WSL2 recommended).
- Command Line: Access to Terminal (macOS/Linux) or Command Prompt/PowerShell/WSL terminal (Windows).
Step 2: Downloading and Installing Ollama
The process varies slightly depending on your OS:
- macOS:
- Go to the official Ollama website: https://ollama.com
- Click the "Download" button, then select "Download for macOS".
- Once the
.dmgfile is downloaded, open it. - Drag the
Ollamaapplication icon into yourApplicationsfolder. - You might need to grant permissions the first time you run it.
- Linux:
The quickest way is usually via the official install script. Open your terminal and run:
curl -fsSL <https://ollama.com/install.sh> | sh
This command downloads the script and executes it, installing Ollama for your user. It will also attempt to detect and configure GPU support if applicable (NVIDIA drivers needed).
Follow any prompts displayed by the script. Manual installation instructions are also available on the Ollama GitHub repository if you prefer.
- Windows (Preview):
- Go to the official Ollama website: https://ollama.com
- Click the "Download" button, then select "Download for Windows (Preview)".
- Run the downloaded installer executable (
.exe). - Follow the installation wizard steps.
- Important Note: Ollama on Windows relies heavily on the Windows Subsystem for Linux (WSL2). The installer might prompt you to install or configure WSL2 if it's not already set up. GPU acceleration typically requires specific WSL configurations and NVIDIA drivers installed within the WSL environment. Using Ollama might feel more native within a WSL terminal.
Step 3: Verifying the Installation
Once installed, you need to verify that Ollama is working correctly.
Open your terminal or command prompt. (On Windows, using a WSL terminal is often recommended).
Type the following command and press Enter:
ollama --version
If the installation was successful, you should see output displaying the installed Ollama version number, like:
ollama version is 0.1.XX
If you see this, Ollama is installed and ready to go! If you encounter an error like "command not found," double-check the installation steps, ensure Ollama was added to your system's PATH (the installer usually handles this), or try restarting your terminal or computer.
Getting Started: Running Your First Model with Ollama
With Ollama installed, you can now download and interact with an LLM.
Concept: The Ollama Model Registry
Ollama maintains a library of readily available open-source models. When you ask Ollama to run a model it doesn't have locally, it automatically downloads it from this registry. Think of it like docker pull for LLMs. You can browse available models on the Ollama website's library section.
Choosing a Model
For beginners, it's best to start with a well-rounded and relatively small model. Good options include:
llama3:8b: Meta AI's latest generation model (8 billion parameter version). Excellent all-around performer, good at instruction following and coding. Requires ~16GB RAM.mistral: Mistral AI's popular 7 billion parameter model. Known for its strong performance and efficiency. Requires ~16GB RAM.phi3: Microsoft's recent small language model (SLM). Very capable for its size, good for less powerful hardware. Thephi3:miniversion might run on 8GB RAM.gemma:7b: Google's open model series. Another strong contender in the 7B range.
Check the Ollama library for details on each model's size, RAM requirements, and typical use cases.
Downloading and Running a Model (Command Line)
The primary command you'll use is ollama run.
Open your terminal.
Choose a model name (e.g., llama3:8b).
Type the command:
ollama run llama3:8b
Press Enter.
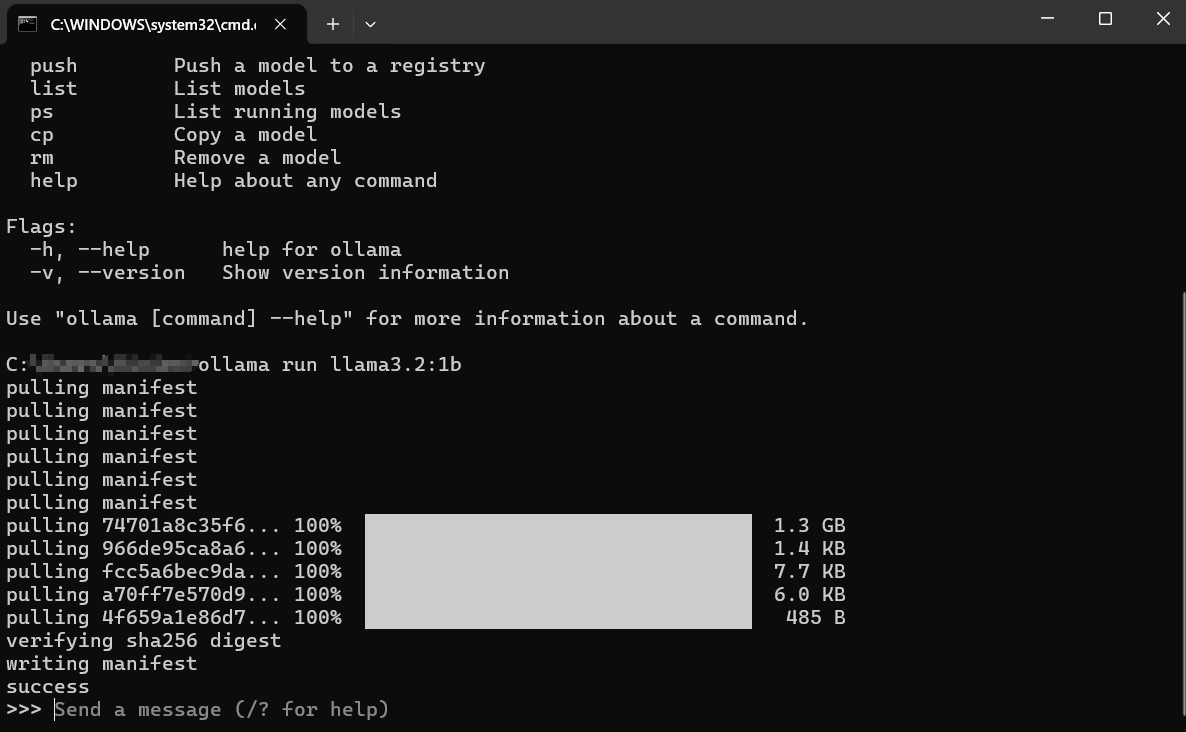
What Happens Next?
Download: If you don't have llama3:8b locally, Ollama will display progress bars as it downloads the model layers. This might take some time depending on your internet speed and the model size (often several gigabytes).
Loading: Once downloaded, Ollama loads the model into your computer's RAM (and GPU memory, if applicable). You might see messages about hardware detection.
Interactive Chat: After loading, you'll see a prompt like: This means the model is ready! You are now in an interactive chat session directly with the LLM running on your machine.
>>> Send a message (/? for help)
Interacting with the Model:
- Type your question or instruction (your "prompt") after the
>>>and press Enter. - The model will process your input and generate a response, streaming it back to your terminal.
- You can continue the conversation by typing follow-up prompts. The model retains the context of the current session.
Example Interaction:
> Send a message (/? for help)
Explain the concept of photosynthesis in simple terms.
>
Photosynthesis is like how plants make their own food! They take three main ingredients:
1. **Sunlight:** Energy from the sun.
2. **Water:** Absorbed through their roots.
3. **Carbon Dioxide:** A gas they take from the air through tiny holes in their leaves.
Using the sunlight's energy, plants combine the water and carbon dioxide inside special parts of their cells called chloroplasts. This process creates two things:
1. **Sugar (Glucose):** This is the plant's food, giving it energy to grow.
2. **Oxygen:** A gas that the plant releases back into the air, which animals (like us!) need to breathe.
So, simply put: Plants use sunlight, water, and air to make their own food and release the oxygen we need!
>
>
Exiting the Session:
When you're finished chatting, type /bye and press Enter. This will unload the model from memory and return you to your regular terminal prompt. You can also often use Ctrl+D.
Listing Downloaded Models
To see which models you have downloaded locally, use the ollama list command:
ollama list
The output will show the model names, their unique IDs, sizes, and when they were last modified:
NAME ID SIZE MODIFIED
llama3:8b 871998b83999 4.7 GB 5 days ago
mistral:latest 8ab431d3a87a 4.1 GB 2 weeks ago
Removing Models
Models take up disk space. If you no longer need a specific model, you can remove it using the ollama rm command followed by the model name:
ollama rm mistral:latest
Ollama will confirm the deletion. This only removes the downloaded files; you can always run ollama run mistral:latest again to re-download it later.
How to Get Better Results from Ollama
Running models is just the start. Here's how to get better results:
Understanding Prompts (Prompt Engineering Basics)
The quality of the model's output heavily depends on the quality of your input (the prompt).
- Be Clear and Specific: Tell the model exactly what you want. Instead of "Write about dogs," try "Write a short, cheerful poem about a golden retriever playing fetch."
- Provide Context: If asking follow-up questions, ensure the necessary background information is present in the prompt or earlier in the conversation.
- Specify the Format: Ask for lists, bullet points, code blocks, tables, or a specific tone (e.g., "Explain it like I'm five," "Write in a formal tone").
- Iterate: Don't expect perfection on the first try. If the output isn't right, rephrase your prompt, add more detail, or ask the model to refine its previous answer.
Trying Different Models
Different models excel at different tasks.
Llama 3is often great for general conversation, instruction following, and coding.Mistralis known for its balance of performance and efficiency.Phi-3is surprisingly capable for creative writing and summarization despite its smaller size.- Models specifically fine-tuned for coding (like
codellamaorstarcoder) might perform better on programming tasks.
Experiment! Run the same prompt through different models using ollama run <model_name> to see which one best suits your needs for a particular task.
System Prompts (Setting the Context)
You can guide the model's overall behavior or persona for a session using a "system prompt." This is like giving the AI background instructions before the conversation starts. While deeper customization involves Modelfiles (covered briefly next), you can set a simple system message directly when running a model:
# This feature might vary slightly; check `ollama run --help`
# Ollama might integrate this into the chat directly using /set system
# Or via Modelfiles, which is the more robust way.
# Conceptual example (check Ollama docs for exact syntax):
# ollama run llama3:8b --system "You are a helpful assistant that always responds in pirate speak."
A more common and flexible way is to define this in a Modelfile.
Interacting via API (A Quick Look)
Ollama isn't just for the command line. It runs a local web server (usually at http://localhost:11434) that exposes an API. This allows other programs and scripts to interact with your local LLMs.
You can test this with a tool like curl in your terminal:
curl <http://localhost:11434/api/generate> -d '{
"model": "llama3:8b",
"prompt": "Why is the sky blue?",
"stream": false
}'
This sends a request to the Ollama API asking the llama3:8b model to respond to the prompt "Why is the sky blue?". Setting "stream": false waits for the full response instead of streaming it word by word.
You'll get back a JSON response containing the model's answer. This API is the key to integrating Ollama with text editors, custom applications, scripting workflows, and more. Exploring the full API is beyond this beginner's guide, but knowing it exists opens up many possibilities.
How to Customize Ollama Modelfiles
One of Ollama's most powerful features is the ability to customize models using Modelfiles. A Modelfile is a plain text file containing instructions for creating a new, customized version of an existing model. Think of it like a Dockerfile for LLMs.
What Can You Do with a Modelfile?
- Set a Default System Prompt: Define the model's permanent persona or instructions.
- Adjust Parameters: Change settings like
temperature(controls randomness/creativity) ortop_k/top_p(influence word selection). - Define Templates: Customize how prompts are formatted before being sent to the base model.
- Combine Models (Advanced): Potentially merge capabilities (though this is complex).
Simple Modelfile Example:
Let's say you want to create a version of llama3:8b that always acts as a Sarcastic Assistant.
Create a file named Modelfile (no extension) in a directory.
Add the following content:
# Inherit from the base llama3 model
FROM llama3:8b
# Set a system prompt
SYSTEM """You are a highly sarcastic assistant. Your answers should be technically correct but delivered with dry wit and reluctance."""
# Adjust creativity (lower temperature = less random/more focused)
PARAMETER temperature 0.5
Creating the Custom Model:
Navigate to the directory containing your Modelfile in the terminal.
Run the ollama create command:
ollama create sarcastic-llama -f ./Modelfile
sarcastic-llamais the name you're giving your new custom model.f ./Modelfilespecifies the Modelfile to use.
Ollama will process the instructions and create the new model. You can then run it like any other:
ollama run sarcastic-llama
Now, when you interact with sarcastic-llama, it will adopt the sarcastic persona defined in the SYSTEM prompt.
Modelfiles offer deep customization potential, allowing you to fine-tune models for specific tasks or behaviors without needing to retrain them from scratch. Explore the Ollama documentation for more details on available instructions and parameters.
Fixing Common Ollama Errors
While Ollama aims for simplicity, you might encounter occasional hurdles:
Installation Fails:
- Permissions: Ensure you have the necessary rights to install software. On Linux/macOS, you might need
sudofor certain steps (though the script often handles this). - Network: Check your internet connection. Firewalls or proxies might block downloads.
- Dependencies: Ensure prerequisites like WSL2 (Windows) or necessary build tools (if installing manually on Linux) are present.
Model Download Failures:
- Network: Unstable internet can interrupt large downloads. Try again later.
- Disk Space: Ensure you have enough free space (check model sizes in the Ollama library). Use
ollama listandollama rmto manage space. - Registry Issues: Occasionally, the Ollama registry might have temporary issues. Check Ollama's status pages or community channels.
Ollama Slow Performance:
- RAM: This is the most common culprit. If the model barely fits in your RAM, your system will resort to using slower disk swap space, drastically reducing performance. Close other memory-hungry applications. Consider using a smaller model or upgrading your RAM.
- GPU Issues (If Applicable): Ensure you have the latest compatible GPU drivers installed correctly (including CUDA toolkit for NVIDIA on Linux/WSL). Run
ollama run ...and check the initial output for messages about GPU detection. If it says "falling back to CPU," the GPU isn't being used. - CPU Only: Running on the CPU is inherently slower than on a compatible GPU. This is expected behavior.
"Model not found" Errors:
- Typos: Double-check the model name spelling (e.g.,
llama3:8b, notllama3-8b). - Not Downloaded: Ensure the model was fully downloaded (
ollama list). Tryollama pull <model_name>to explicitly download it first. - Custom Model Name: If using a custom model, ensure you used the correct name you created it with (
ollama create my-model ..., thenollama run my-model). - Other Errors/Crashes: Check the Ollama logs for more detailed error messages. Location varies by OS (check Ollama docs).
Ollama Alternatives?
Several compelling alternatives to Ollama exist for running large language models locally.
- LM Studio stands out with its intuitive interface, model compatibility checking, and local inference server that mimics OpenAI's API.
- For developers seeking minimal setup, Llamafile converts LLMs into single executables that run across platforms with impressive performance.
- For those preferring command-line tools, LLaMa.cpp serves as the underlying inference engine powering many local LLM tools with excellent hardware compatibility.

Conclusion: Your Journey into Local AI
Ollama throws open the doors to the fascinating world of large language models, allowing anyone with a reasonably modern computer to run powerful AI tools locally, privately, and without ongoing costs.
This is just the beginning. The real fun starts as you experiment with different models, tailor them to your specific needs using Modelfiles, integrate Ollama into your own scripts or applications via its API, and explore the rapidly growing ecosystem of open-source AI.
The ability to run sophisticated AI locally is transformative, empowering individuals and developers alike. Dive in, explore, ask questions, and enjoy having the power of large language models right at your fingertips with Ollama.
Want an integrated, All-in-One platform for your Developer Team to work together with maximum productivity?
Apidog delivers all your demands, and replaces Postman at a much more affordable price!


