
Introduction to Llama 3.1 Instruct 405B
Meta's Llama 3.1 Instruct 405B represents a significant leap forward in the realm of large language models (LLMs). As the name suggests, this behemoth boasts an impressive 405 billion parameters, making it one of the largest publicly available AI models to date. This massive scale translates into enhanced capabilities across a wide range of tasks, from natural language understanding and generation to complex reasoning and problem-solving.
One of the standout features of Llama 3.1 405B is its expanded context window of 128,000 tokens. This substantial increase from previous versions allows the model to process and generate much longer pieces of text, opening up new possibilities for applications such as long-form content creation, in-depth document analysis, and extended conversational interactions.
The model excels in areas such as:
- Text summarization and accuracy
- Nuanced reasoning and analysis
- Multilingual capabilities (supporting 8 languages)
- Code generation and understanding
- Task-specific fine-tuning potential
With its open-source nature, Llama 3.1 405B is poised to democratize access to cutting-edge AI technology, enabling researchers, developers, and businesses to harness its power for a wide array of applications.
Llama 3.1 API Providers Comparison
Several cloud providers offer access to Llama 3.1 models through their APIs. Let's compare some of the most prominent options:
| Provider | Pricing (per million tokens) | Output Speed | Latency | Key Features |
|---|---|---|---|---|
| Together.ai | $7.50 (blended rate) | 70 tokens/second | Moderate | Impressive output speed |
| Fireworks | $3.00 (blended rate) | Good | 0.57 seconds (very low) | Most competitive pricing |
| Microsoft Azure | Varies based on usage tier | Moderate | 0.00 seconds (near-instantaneous) | Lowest latency |
| Replicate | $9.50 (output tokens) | 29 tokens/second | Higher than some competitors | Straightforward pricing model |
| Anakin AI | $9.90/month (Freemium model) | Not specified | Not specified | No-code AI app builder |
- Together.ai: Offers an impressive output speed of 70 tokens/second, making it ideal for applications requiring quick responses. Its pricing is competitive at $7.50 per million tokens, striking a balance between performance and cost.
- Fireworks: Stands out with the most competitive pricing at $3.00 per million tokens and very low latency (0.57 seconds). This makes it an excellent choice for cost-sensitive projects that also require quick response times.
- Microsoft Azure: Boasts the lowest latency (near-instantaneous) among the providers, which is crucial for real-time applications. However, its pricing structure varies based on usage tiers, potentially making it more complex to estimate costs.
- Replicate: Offers a straightforward pricing model at $9.50 per million output tokens. While its output speed (29 tokens/second) is lower than Together.ai, it still provides decent performance for many use cases.
- Anakin AI: Anakin AI's approach differs significantly from the other providers, focusing on accessibility and customization rather than raw performance metrics. It supports multiple AI models, including GPT-3.5, GPT-4, and Claude 2 & 3, offering flexibility across various AI tasks. It starts at a freemium model with plans starting at $9.90/month.
How to Make API Calls to Llama 3.1 Models Using Apidog
To harness the power of Llama 3.1, you'll need to make API calls to your chosen provider. While the exact process may vary slightly between providers, the general principles remain the same.
Here's a step-by-step guide on how to make API calls using Apidog:
- Open Apidog: Launch Apidog and create a new request.
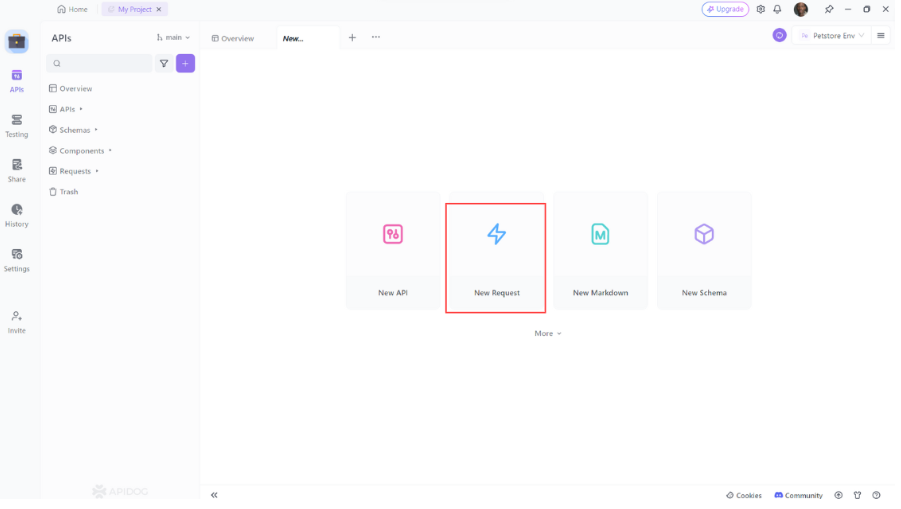
2. Select the HTTP Method: Choose "GET" as the request method or "Post"
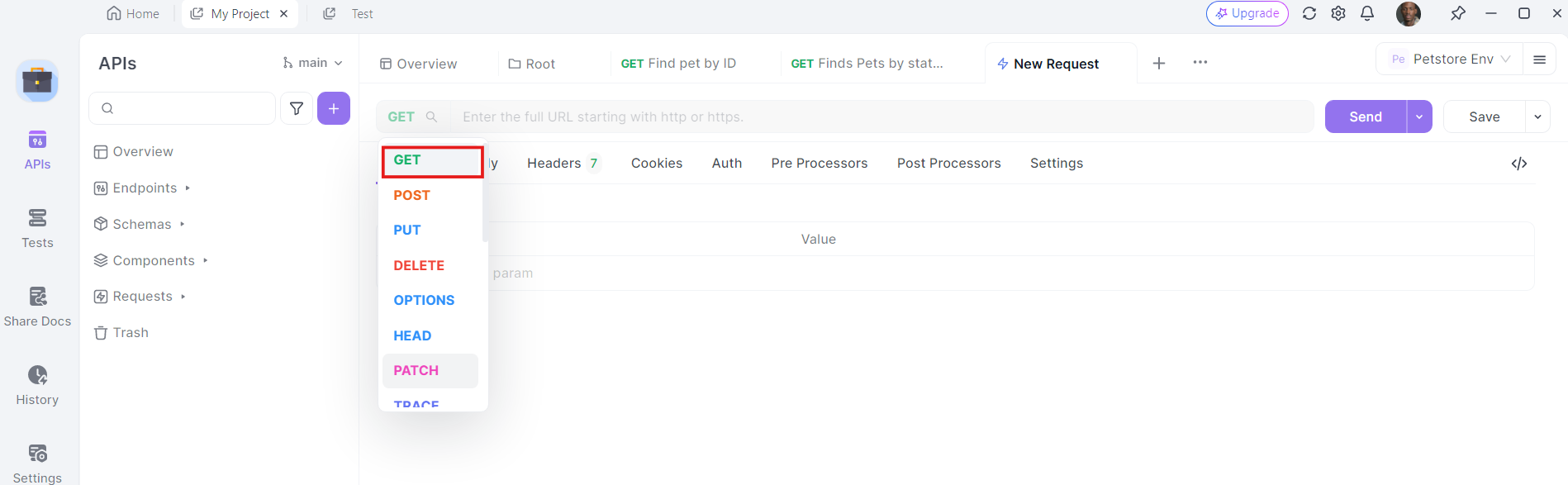
3. Enter the URL: In the URL field, enter the endpoint you want to send the GET request to.
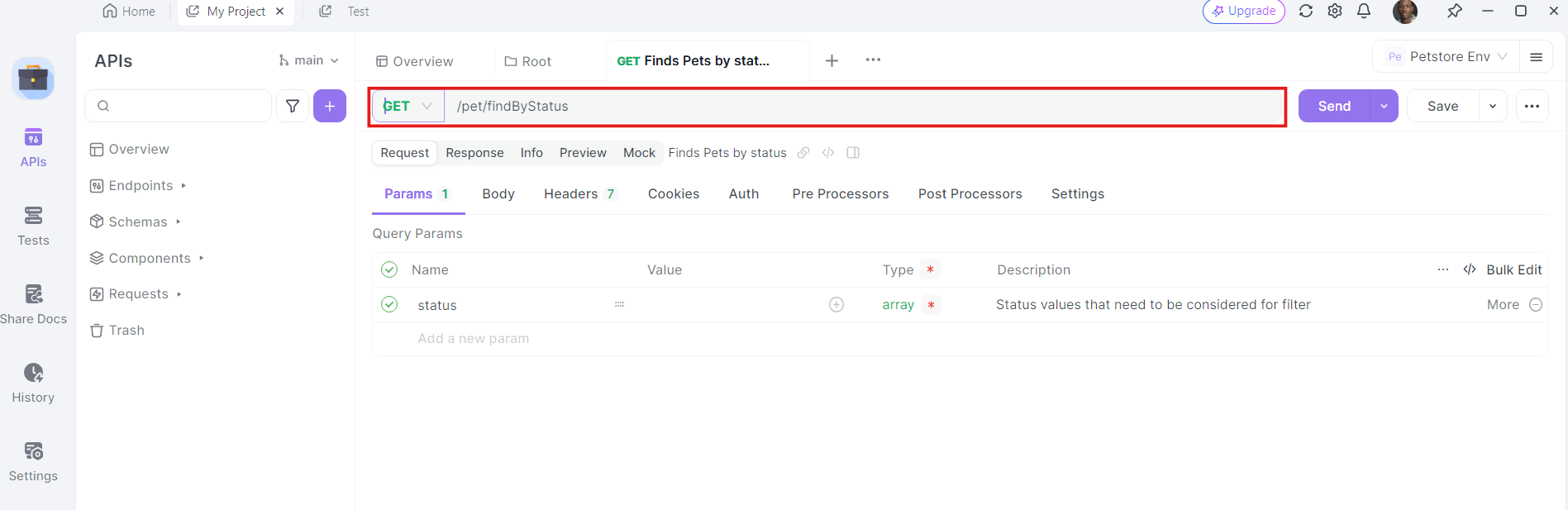
4. Add Headers: Now, it's time to add the necessary headers. Click on the "Headers" tab in apidog. Here, you can specify any headers required by the API. Common headers for GET requests might include Authorization, Accept, and User-Agent.
For example:
- Authorization:
Bearer YOUR_ACCESS_TOKEN - Accept:
application/json
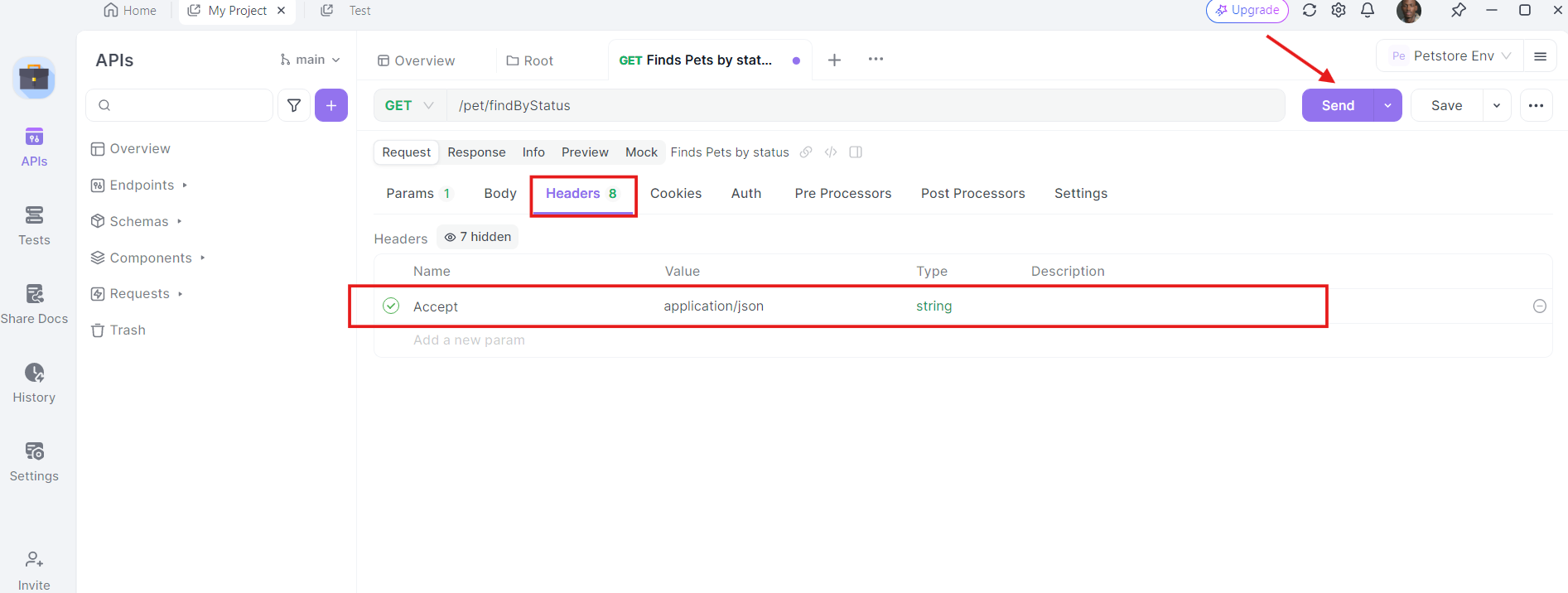
5. Send the Request and Inspect the Response: With the URL, query parameters, and headers in place, you can now send the API request. Click the "Send" button and apidog will execute the request. You'll see the response displayed in the response section.
Once the request is sent, Apidog will display the response from the server. You can view the status code, headers, and body of the response. This is invaluable for debugging and verifying that your API calls are working as expected.
Best Practices for Using Llama 3.1 API
When working with the Llama 3.1 API, keep these best practices in mind:
- Implement Streaming: For longer responses, you might want to implement streaming to receive the generated text in real-time chunks. This can improve the user experience for applications that require immediate feedback.
- Respect Rate Limits: Be aware of and adhere to the rate limits set by your API provider to avoid service interruptions.
- Implement Caching: For frequently used prompts or queries, implement a caching system to reduce API calls and improve response times.
- Monitor Usage: Keep track of your API usage to manage costs and ensure you're within your allocated quota.
- Security: Never expose your API key in client-side code. Always make API calls from a secure server environment.
- Content Filtering: Implement content filtering on both the input prompts and the generated outputs to ensure appropriate use of the model.
- Fine-tuning: Consider fine-tuning the model on domain-specific data if you're working on specialized applications.
- Versioning: Keep track of the specific Llama 3.1 model version you're using, as updates may affect the model's behavior and outputs.
Real-World Use Cases
Let's look at some real-world use cases where integrating Llama 3.1 with an API can be a game-changer:
1. Sentiment Analysis
If you're running a sentiment analysis project, Llama 3.1 can help you classify text as positive, negative, or neutral. By integrating it with an API, you can automate the analysis of large volumes of data, such as customer reviews or social media posts.
2. Chatbots
Building a chatbot? Llama 3.1's natural language processing capabilities can enhance your chatbot's understanding and responses. By using an API, you can seamlessly integrate it with your chatbot framework and provide real-time interactions.
3. Image Recognition
For computer vision projects, Llama 3.1 can perform image recognition tasks. By leveraging an API, you can upload images, get real-time classifications, and integrate the results into your application.
Troubleshooting Common Issues
Sometimes things don't go as planned. Here are some common issues you might encounter and how to troubleshoot them:
1. Authentication Errors
If you're getting authentication errors, double-check your API key and ensure it's correctly configured in Apidog.
2. Network Issues
Network issues can cause API calls to fail. Make sure your internet connection is stable and try again. If the problem persists, check the API provider's status page for any outages.
3. Rate Limiting
API providers often enforce rate limits to prevent abuse. If you exceed the limit, you'll need to wait before making more requests. Consider implementing retry logic with exponential backoff to handle rate limiting gracefully.
Prompt Engineering with Llama 3.1 405B
To get the best results from Llama 3.1 405B, you'll need to experiment with different prompts and parameters. Consider factors like:
- Prompt engineering: Craft clear and specific prompts to guide the model's output.
- Temperature: Adjust this parameter to control the randomness of the output.
- Max tokens: Set an appropriate limit for the length of the generated text.
Conclusion
Llama 3.1 405B represents a significant advancement in the field of large language models, offering unprecedented capabilities in an open-source package. By leveraging the power of this model through APIs provided by various cloud providers, developers and businesses can unlock new possibilities in AI-driven applications.
The future of AI is open, and with tools like Llama 3.1 at our disposal, the possibilities are limited only by our imagination and ingenuity. As you explore and experiment with this powerful model, you're not just using a tool – you're participating in the ongoing revolution of artificial intelligence, helping to shape the future of how we interact with and leverage machine intelligence.


