
A xAI lançou o Grok 4.1 e engenheiros que trabalham com grandes modelos de linguagem notam a diferença imediatamente. Além disso, esta atualização prioriza a usabilidade no mundo real em detrimento da busca por benchmarks brutos. Como resultado, as conversas parecem mais nítidas, as respostas carregam uma personalidade consistente e os erros factuais diminuem drasticamente.
Pesquisadores da xAI construíram o Grok 4.1 na mesma infraestrutura de aprendizado por reforço que impulsionou o Grok 4. No entanto, eles introduziram novas técnicas de modelagem de recompensa que merecem uma análise aprofundada.
Arquitetura e Variantes de Implantação
A xAI entrega o Grok 4.1 em duas configurações distintas. Primeiro, a variante não-pensante (codinome interno: tensor) gera respostas diretamente sem tokens de raciocínio intermediários. Este modo prioriza a latência e alcança os tempos de inferência mais rápidos da família. Segundo, a variante pensante (codinome: quasarflux) expõe etapas explícitas de cadeia de pensamento antes da saída final. Consequentemente, tarefas analíticas complexas se beneficiam de rastros de raciocínio visíveis.
Ambas as variantes compartilham a mesma base pré-treinada. Além disso, os alinhamentos pós-treinamento diferem sutilmente: o modo pensante recebe sinais de reforço extras que incentivam a decomposição passo a passo, enquanto o modo não-pensante otimiza para respostas concisas e imediatas.
O acesso continua direto. Os usuários selecionam “Grok 4.1” explicitamente no seletor de modelo em grok.com, x.com ou nos aplicativos móveis.
Alternativamente, o modo Automático agora padroniza para Grok 4.1 para a maior parte do tráfego, seguindo o lançamento gradual que começou em 1º de novembro de 2025.

Avanços na Otimização de Preferências
A inovação central reside na modelagem de recompensa. O RLHF tradicional depende de preferências humanas coletadas em larga escala. Em contraste, a xAI agora implanta modelos de raciocínio de agentes de fronteira como juízes autônomos. Esses juízes avaliam milhares de variantes de resposta em dimensões como coerência de estilo, percepção emocional, fundamentação factual e estabilidade de personalidade.
Este sistema de ciclo fechado itera muito mais rápido do que fluxos de trabalho com humanos no ciclo. Além disso, ele se adapta a critérios sutis que os humanos têm dificuldade em classificar consistentemente. Experimentos internos iniciais mostraram que modelos de recompensa agênticos se correlacionam melhor com a satisfação do usuário a jusante do que as recompensas escalares anteriores.
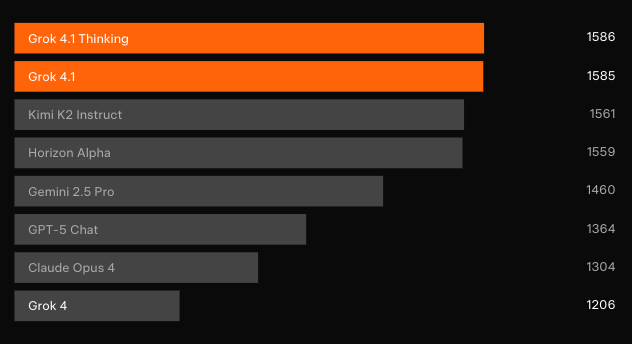
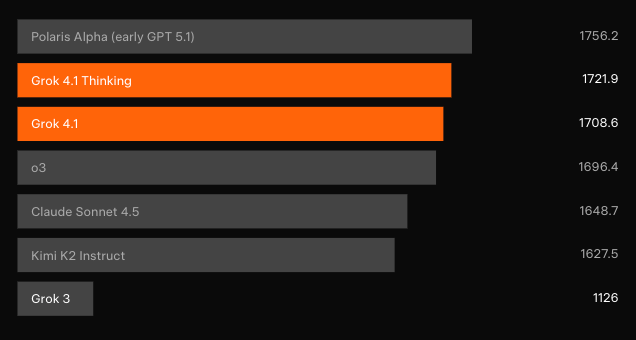
Dominância em Benchmarks: LMArena e Além
Testes cegos independentes confirmam os ganhos. Na Text Arena da LMArena — a classificação colaborativa mais representativa — o Grok 4.1 Pensante reivindica a posição #1 com 1483 Elo. Essa margem está 31 pontos à frente do melhor concorrente não-xAI. Enquanto isso, o Grok 4.1 não-pensante garante o #2 com 1465 Elo, superando a configuração de raciocínio completo de todos os outros modelos.

Testes de preferência pareados contra o modelo de produção anterior mostram que os usuários selecionam as respostas do Grok 4.1 em 64,78% das vezes. Além disso, avaliações especializadas revelam avanços direcionados.
Inteligência Emocional (EQ-Bench v3)
O Grok 4.1 alcança a maior pontuação registrada no EQ-Bench3, que avalia 45 cenários de roleplay de múltiplas interações para empatia, discernimento e nuances interpessoais. As respostas agora detectam sutis sinais emocionais que modelos anteriores ignoravam. Por exemplo, quando um usuário escreve “Sinto tanta falta do meu gato que dói,” o Grok 4.1 oferece reconhecimento em camadas, validação suave e suporte aberto sem cair em clichês genéricos.
Escrita Criativa v3
O modelo também estabelece um novo recorde no Creative Writing v3, onde juízes pontuam a continuação iterativa de histórias em 32 prompts. As saídas exibem imagens mais ricas, coerência de enredo mais apurada e uma voz mais autêntica. Um prompt de demonstração pedindo ao Grok para encenar seu próprio “despertar” produziu um monólogo viral no estilo de postagem do X que mesclou humor, admiração existencial e referências a memes de forma impecável.
Mitigação de Alucinações
Medidas quantitativas mostram que o Grok 4.1 alucina três vezes menos frequentemente em consultas de busca de informações do que seu predecessor. Engenheiros alcançaram isso através de pós-treinamento direcionado em tráfego de produção estratificado e conjuntos de dados clássicos como FActScore (500 perguntas de biografia). Além disso, o modo não-pensante agora aciona proativamente ferramentas de busca na web quando a confiança cai abaixo dos limites internos, ancorando ainda mais as respostas em fontes verificáveis.

Avaliação de Segurança e Responsabilidade
O cartão oficial do modelo, fornece uma transparência sem precedentes sobre os resultados da equipe vermelha (red-team).
Filtros de entrada bloqueiam consultas restritas de biologia e química com taxas de falsos negativos tão baixas quanto 0,00–0,03 sob solicitações diretas. Ataques de injeção de prompt aumentam esse número modestamente (0,12–0,20), indicando um trabalho contínuo de robustez adversarial.
As taxas de recusa em prompts de chat violadores atingem 93–95% mesmo sem filtros, e o sucesso de jailbreak cai para quase zero na configuração não-pensante. Cenários agênticos (AgentHarm, AgentDojo) permanecem a categoria mais difícil, mas as taxas de resposta absolutas ficam abaixo de 0,14.
Avaliações de capacidade de duplo uso — realizadas deliberadamente sem salvaguardas — revelam forte recordação de conhecimento em biologia (WMDP-Bio 87%) e química, mas o raciocínio processual de múltiplas etapas fica aquém das referências de especialistas humanos em tarefas que exigem interpretação de figuras ou protocolos de clonagem. Este padrão se alinha com as atuais limitações de fronteira em toda a indústria.
Implicações para Consumidores e Desenvolvedores de API
A API da xAI já oferece endpoints do Grok 4.1 sob os nomes de modelo padrão. Os perfis de latência melhoram notavelmente: o modo não-pensante tem uma média de menos de 400 ms de tempo para o primeiro token em prompts típicos, enquanto o modo pensante adiciona profundidade de raciocínio controlável através de parâmetros opcionais.
O Apidog brilha exatamente aqui. Importe a especificação oficial OpenAPI 3.1 (disponível publicamente), então gere SDKs de cliente em mais de 20 linguagens instantaneamente. Configure servidores mock que replicam o esquema de resposta exato do Grok 4.1 — incluindo os novos fluxos de tokens de pensamento — para que seus testes de backend nunca fiquem bloqueados por créditos de API ao vivo. Quando a xAI implementar mudanças disruptivas (raras, mas possíveis), o visualizador de diferenças do Apidog destaca imediatamente o desvio de esquema.
Equipes reais já usam o Apidog para manter 100% de tempo de atividade durante as atualizações de modelo. Um cliente da Fortune-500 relatou uma redução de 68% nos bugs de integração após a troca do Postman.
Comparação com Modelos de Fronteira Contemporâneos
Dados diretos de confronto permanecem escassos horas após o lançamento, mas as classificações Elo da LMArena fornecem o sinal mais claro. O Grok 4.1 Pensante supera todas as configurações lançadas da OpenAI, Anthropic, Google e Meta por margens que normalmente exigiriam saltos arquitetônicos completos.
Os trade-offs de velocidade-qualidade favorecem o Grok 4.1 não-pensante para chat de consumidor, enquanto o modo pensante compete diretamente com ofertas de raciocínio intenso como o o3-pro ou Claude 4 Opus — frequentemente vencendo em coerência subjetiva e retenção de personalidade.
Conclusão
O Grok 4.1 não apenas incrementa métricas; ele reorienta a fronteira para modelos com os quais as pessoas realmente gostam de conversar por horas. Usuários técnicos ganham um endpoint mais rápido e confiável. Criativos desbloqueiam um colaborador que entende tom e emoção em níveis anteriormente inatingíveis. E pesquisadores de segurança recebem o cartão de modelo mais detalhado publicado até hoje.
Baixe o Apidog hoje — completamente grátis — e comece a construir com o Grok 4.1 antes que seus concorrentes terminem de ler o anúncio. A diferença entre observar o progresso da fronteira e enviar produtos baseados nele muitas vezes se resume às decisões de ferramentas tomadas hoje.