
Enquanto o Google lança discretamente o Gemini 3.0 através de implantações 'sombra' e endpoints de prévia, os desenvolvedores obtêm oportunidades antecipadas para testar seu raciocínio aprimorado e desempenho multimodal.
Pesquisadores e engenheiros do Google DeepMind posicionaram o Gemini 3.0 como a família de modelos mais capaz da empresa até o momento. Além disso, ele avança além das atualizações incrementais ao introduzir comportamentos agentivos nativos e uma integração mais profunda de ferramentas.
Linha do Tempo de Lançamento e Estratégia de Implementação do Gemini 3.0
O Google adota uma abordagem de implantação em fases para grandes atualizações de modelos. Consequentemente, o Gemini 3.0 apareceu pela primeira vez em ambientes controlados sem um anúncio tradicional em evento principal.
O modelo surgiu inicialmente no AI Studio sob o identificador "gemini-3-pro-preview" por volta de meados de novembro de 2025. Além disso, alguns assinantes do Gemini Advanced receberam notificações no aplicativo declarando: "Nós o atualizamos do modelo anterior para o 3.0 Pro, nosso modelo mais inteligente até agora." Este lançamento "sombra" permite ao Google coletar telemetria de produção enquanto mantém a continuidade da interface.
O Vertex AI e o changelog da API Gemini agora listam endpoints de prévia como gemini-3-pro-preview-11-2025. Além disso, codinomes internos como "lithiumflow" e "orionmist" que dominaram as tabelas de classificação do LM Arena em outubro de 2025 foram confirmados como checkpoints iniciais do Gemini 3.0.
O Google DeepMind reconheceu publicamente a família em uma thread de novembro de 2025, descrevendo o Gemini 3 como oferecendo "capacidades de raciocínio de última geração, compreensão multimodal líder mundial e novas experiências de codificação agentiva." O lançamento estável completo, incluindo maior disponibilidade da API Gemini 3, é esperado antes do final de 2025.
Avanços Arquitetônicos Essenciais no Gemini 3.0
O Gemini 3.0 se baseia na fundação de mistura de especialistas (MoE) estabelecida em gerações anteriores. No entanto, ele incorpora várias melhorias críticas que impactam diretamente a qualidade e eficiência da inferência.
Primeiro, o modelo expande o suporte à janela de contexto além dos 2 milhões de tokens disponíveis no Gemini 2.5 Pro, com instâncias de prévia lidando com sessões estendidas de forma mais coerente. Segundo, o treinamento em conjuntos de dados multimodais vastamente maiores melhora o alinhamento entre modalidades – o modelo agora processa texto, código, imagens e dados estruturados intercalados com perda de modalidade reduzida.
Pesquisadores introduziram mecanismos de atenção refinados que priorizam dependências de longo alcance durante cadeias de raciocínio. Como resultado, o Gemini 3.0 apresenta menos problemas de desvio de contexto em interações de várias voltas que excedem 100 trocas.
A família inclui pelo menos duas variantes primárias em prévia:
- Gemini 3.0 Pro: O modelo carro-chefe otimizado para máxima inteligência e resolução de problemas complexos.
- Gemini 3.0 Flash: Uma versão destilada, focada em latência, que mantém alta capacidade enquanto alcança tempos de resposta abaixo de um segundo na infraestrutura TPU.
A instrumentação inicial revela que o Pro opera com temperatura 1.0 por padrão, com a documentação alertando que valores mais baixos podem degradar o desempenho da cadeia de pensamento – uma mudança em relação aos modelos anteriores onde a temperatura 0.7 frequentemente produzia resultados ótimos.
Capacidades de Compreensão e Geração Multimodal
O Gemini 3.0 fortalece significativamente o processamento multimodal nativo. Engenheiros treinam o modelo de ponta a ponta em diversos tipos de dados, permitindo-lhe raciocinar através de visão, áudio e texto sem codificadores separados.
Por exemplo, o modelo analisa capturas de tela de interfaces de usuário, extrai especificações funcionais e gera código React ou Flutter completo com animações incorporadas em uma única passagem. Além disso, ele interpreta diagramas científicos, deriva equações subjacentes e simula resultados usando conhecimento de física integrado.
Usuários da prévia relatam desempenho inovador em tarefas de raciocínio visual:
- Interpretação precisa de gráficos complexos contendo anotações sobrepostas
- Geração de código SVG que respeita restrições matemáticas (ex: círculos perfeitos, escala proporcional)
- Criação de experiências interativas em Canvas combinando prosa, execução de código e saída visual
Além disso, extensões agentivas permitem que o modelo orquestre chamadas de ferramentas autonomamente. Desenvolvedores observam o Gemini 3.0 Pro planejando interações de navegador multi-etapas ou sequências de API sem prompt explícito, uma capacidade anteriormente limitada a modos experimentais.
Melhorias no Raciocínio e Comportamento Agentivo
O Google enfatiza o "Pensamento Profundo" (Deep Think) como um paradigma central no Gemini 3.0. O modelo decompõe internamente os problemas em subproblemas, avalia múltiplos caminhos de solução e se autocorrigiria antes da saída final.
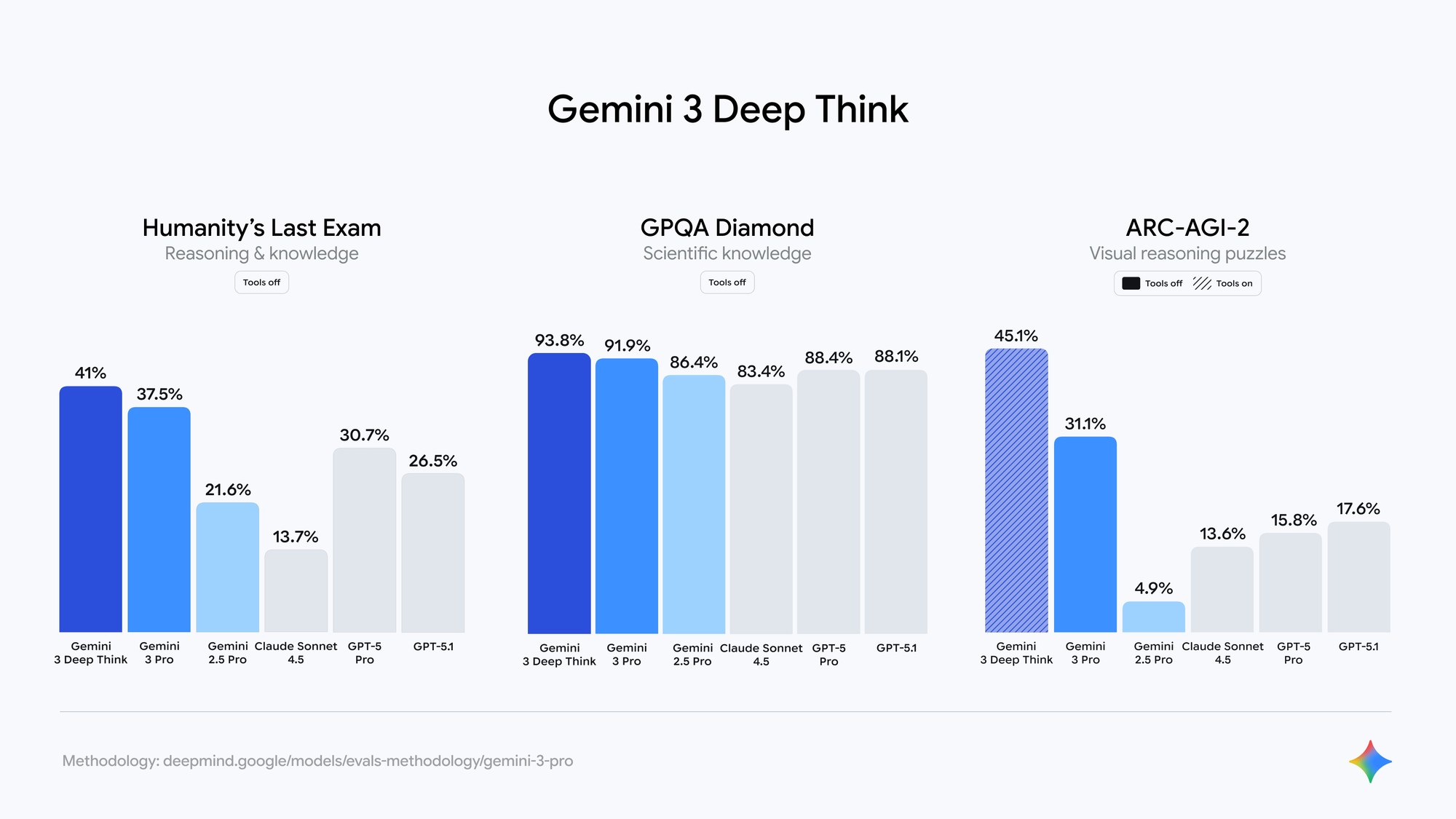
Avaliações independentes em checkpoints fechados do LM Arena (amplamente aceitos como variantes do Gemini 3.0) mostram:
- Pontuações do SimpleBench aproximando-se de 90–100% (versus 62.4% para Gemini 2.5 Pro)
- Ganhos substanciais em GPQA Diamond, AIME 2024 e SWE-bench Verified
- Consistência factual aprimorada na geração de formato longo
Além disso, o modelo demonstra habilidades de planejamento emergentes. Quando encarregado do design de sistemas, ele produz diagramas arquitetônicos completos, contratos de API e scripts de implantação, antecipando casos de borda.
Acessando a API Gemini 3 em Prévia
Desenvolvedores atualmente acessam o Gemini 3.0 através dos endpoints de prévia da API Gemini. O Google mantém compatibilidade retroativa com SDKs existentes, exigindo apenas uma atualização do nome do modelo.
As principais mudanças nos endpoints incluem:
# O código existente do Gemini 2.5 continua a funcionar
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
# Mudar para o modelo de prévia
model = genai.GenerativeModel("gemini-3-pro-preview-11-2025")
response = model.generate_content(
"Explain quantum entanglement with a working Python simulation",
generation_config=genai.types.GenerationConfig(
temperature=1.0,
max_output_tokens=8192
)
)
A API Gemini 3 suporta as mesmas configurações de segurança, chamada de função e recursos de aterramento que as versões anteriores. No entanto, as cotas da prévia permanecem conservadoras e os limites de taxa se aplicam por projeto.
Para testes de nível de produção, ferramentas como o Apidog provam ser inestimáveis. O Apidog importa automaticamente especificações OpenAPI do Gemini, permite a simulação de requisições para desenvolvimento offline e fornece validação detalhada de respostas – essencial ao experimentar novos comportamentos de raciocínio que podem produzir comprimentos de saída variáveis.
Desempenho em Benchmarks e Posicionamento Competitivo
Embora o Google ainda não tenha publicado cartões oficiais, resultados verificados pela comunidade a partir do acesso de prévia e implantações 'sombra' indicam que o Gemini 3.0 Pro lidera os modelos públicos atuais em várias frentes:
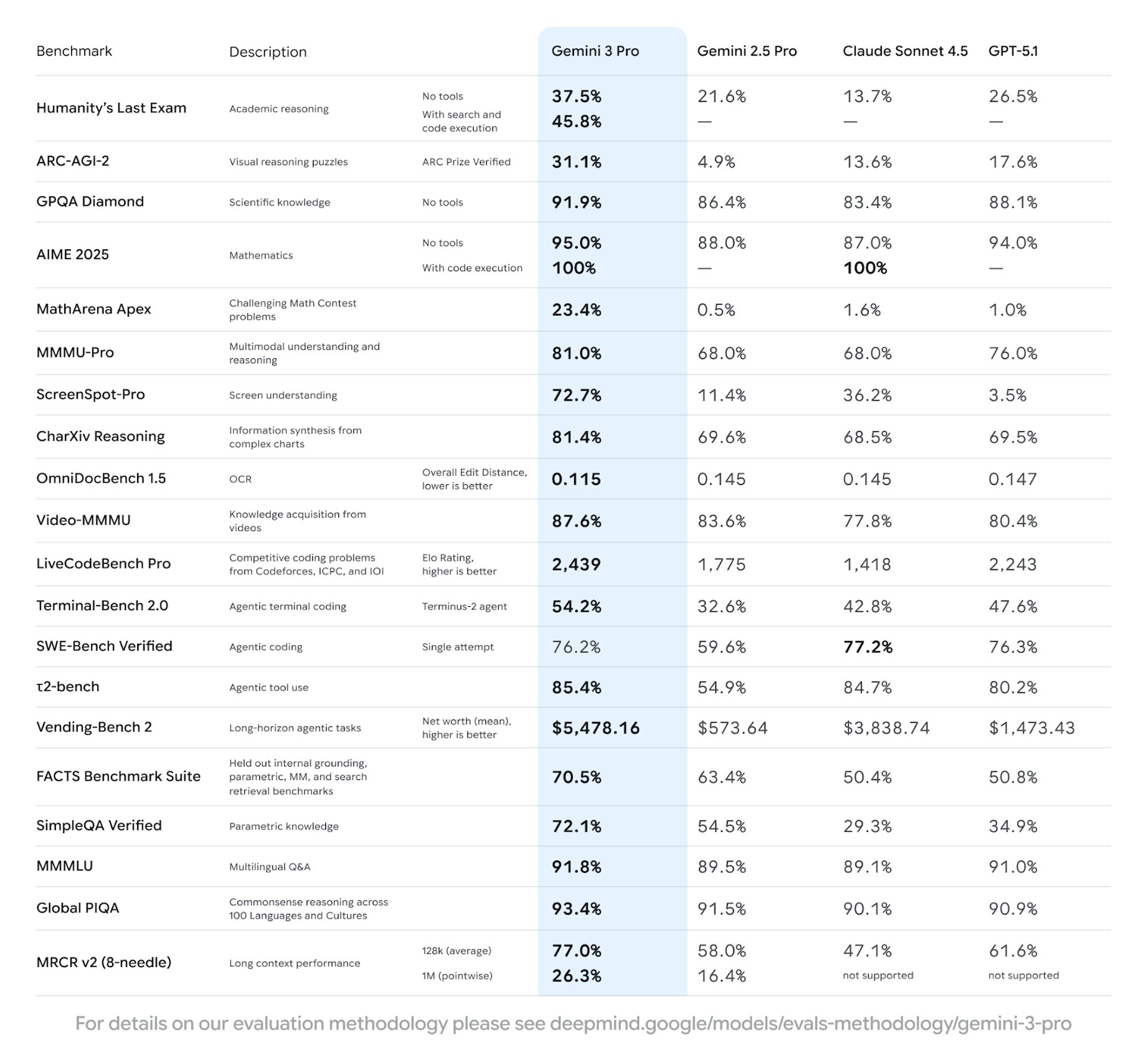
Esses números posicionam o Gemini 3.0 à frente dos equivalentes contemporâneos Claude 4 Opus e GPT-4.1 em densidade de raciocínio e qualidade de código.
Padrões de Integração Prática com a API Gemini 3
A adoção bem-sucedida requer a compreensão de novas características comportamentais. Os desenvolvedores devem considerar tempos de pensamento mais longos em prompts complexos – o modelo frequentemente gasta tokens adicionais em deliberação interna antes de responder.
Melhores práticas emergentes do uso da prévia:
- Defina a temperatura para 1.0 para tarefas que exigem muito raciocínio
- Use instruções do sistema para impor saída estruturada (JSON, YAML)
- Aproveite o contexto expandido para uploads completos de bases de código
- Encadeie chamadas de ferramentas explicitamente quando um comportamento determinístico for necessário
Além disso, combine a API Gemini 3 com camadas de orquestração externas para loops de agente confiáveis. O Apidog se destaca aqui ao fornecer coleções específicas de ambiente que alternam perfeitamente entre os endpoints gemini-2.5-pro e gemini-3-pro-preview.
Limitações e Problemas Conhecidos na Prévia
As versões de prévia exibem instabilidade ocasional. Usuários encontram perda de contexto em sessões extremamente longas (>150k tokens) e alucinações raras em domínios de nicho. Além disso, a geração de imagens permanece ligada a endpoints separados do Imagen/Nano Banana, em vez de uma integração nativa.
O Google itera ativamente com base na telemetria. A maioria dos problemas relatados é resolvida em dias após a descoberta, refletindo as vantagens da implantação 'sombra'.
Perspectivas Futuras e Impacto no Ecossistema
O Gemini 3.0 estabelece uma nova linha de base para agentes multimodais. À medida que a API Gemini 3 avança para o status estável, espere uma integração rápida em todo o Google Workspace, Android e agentes Vertex AI.
Empresas se beneficiarão de instâncias privadas com alinhamento personalizado, enquanto desenvolvedores obtêm acesso a uma profundidade de raciocínio que anteriormente exigia múltiplas chamadas de modelo.
A combinação de inteligência bruta, compreensão nativa de ferramentas e implantação eficiente posiciona o Gemini 3.0 como a base para aplicativos de IA de próxima geração.
Desenvolvedores prontos para experimentar essas capacidades devem começar a migrar suítes de teste para a prévia da API Gemini 3 imediatamente. Ferramentas como o Apidog reduzem drasticamente o atrito durante esta transição, oferecendo troca de endpoint com um clique e depuração abrangente.
A implantação controlada do Google demonstra maturidade na implementação de modelos grandes. Consequentemente, quando o Gemini 3.0 alcançar a disponibilidade geral, o ecossistema estará preparado para uso produtivo imediato.