
Você precisa de ferramentas eficientes para gerar imagens de alta qualidade a partir de prompts de texto em aplicações modernas. A API Z-Image atende a essa demanda diretamente. Desenvolvedores acessam um poderoso modelo de texto para imagem através de uma interface sem custo que entrega resultados fotorrealistas rapidamente. Esta API aproveita o modelo de código aberto Z-Image-Turbo da equipe Tongyi-MAI da Alibaba, que opera sob a licença Apache 2.0. Você se beneficia de inferência em menos de um segundo em hardware adequado, tornando-o ideal para recursos em tempo real em aplicativos da web, ferramentas móveis ou fluxos de trabalho automatizados.
Em seguida, você explora a base de código aberto do Z-Image-Turbo. Depois, obtém insights sobre os métodos de acesso à API e confirma sua estrutura de preços gratuita. Por fim, implementa integrações práticas. Essas etapas o equipam para implantar recursos de geração de imagens de forma eficaz.
Compreendendo o Modelo de Código Aberto Z-Image-Turbo
Você começa com a tecnologia central por trás da API Z-Image: o modelo Z-Image-Turbo. A equipe Tongyi-MAI da Alibaba lança este modelo de 6 bilhões de parâmetros como totalmente de código aberto sob a licença Apache 2.0. Esta licença permite uso comercial, modificações e distribuições sem restrições, o que acelera a adoção em ambientes de produção.
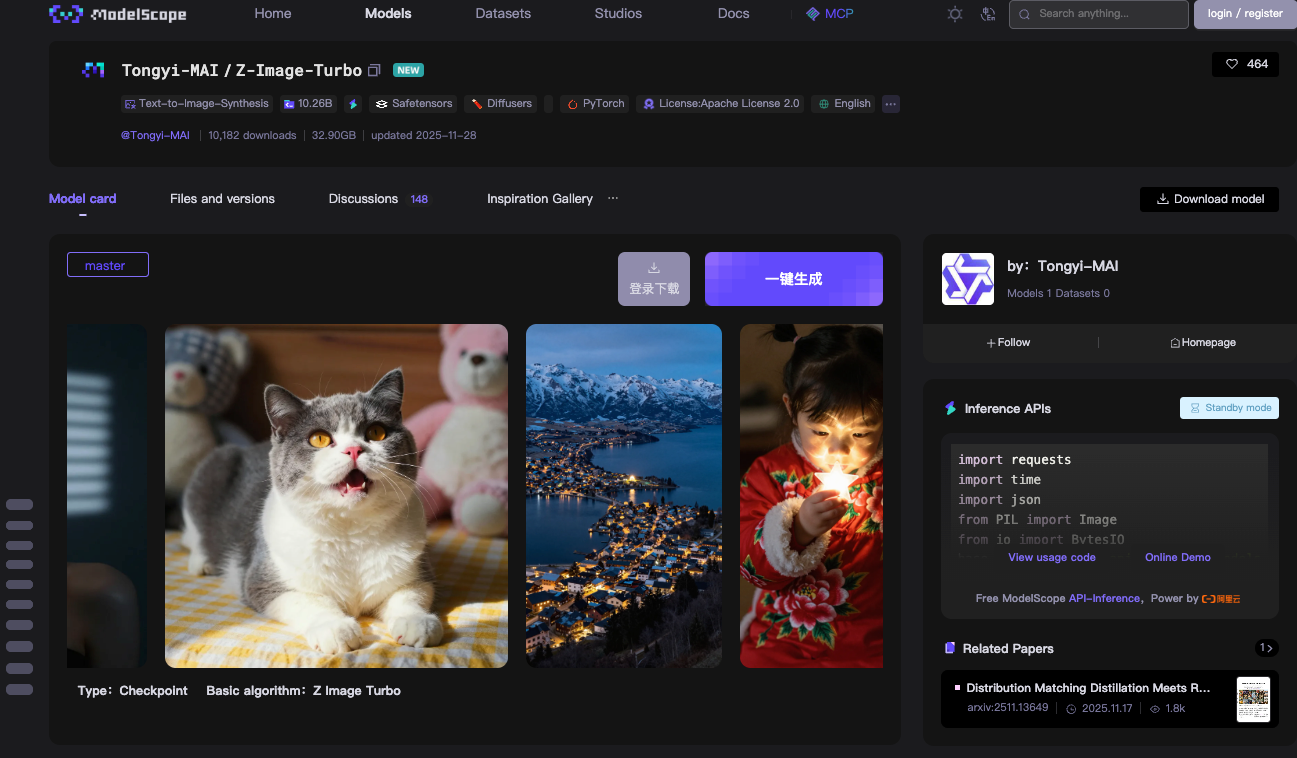
Z-Image-Turbo é construído sobre uma arquitetura de Transformer de Difusão de Fluxo Único Escalável (S3-DiT). Modelos tradicionais de fluxo duplo separam o processamento de texto e imagem, o que desperdiça parâmetros. No entanto, o S3-DiT concatena tokens de texto, tokens semânticos visuais e tokens VAE de imagem em um fluxo unificado. Este design maximiza a eficiência. Como resultado, o modelo se encaixa em 16GB de VRAM em GPUs de consumo como as placas NVIDIA RTX série 40. Você consegue isso sem sacrificar a qualidade da saída.
O modelo se destaca na síntese de imagens fotorrealistas. Ele gera cenas detalhadas, retratos e paisagens a partir de prompts descritivos. Por exemplo, um prompt como "um lago de montanha sereno ao entardecer com sinalização bilíngue em inglês e chinês" produz visuais nítidos e conscientes do contexto. O Z-Image-Turbo lida bem com instruções complexas, graças ao seu Prompt Enhancer integrado. Este componente refina as entradas para melhor aderência, reduzindo artefatos comuns em modelos de difusão anteriores.
A velocidade de inferência define a vantagem do Z-Image-Turbo. Ele requer apenas 8 Avaliações de Número de Funções (NFEs), equivalente a 9 etapas de inferência na prática. Em GPUs empresariais H800, você vê latência sub-segundo — muitas vezes abaixo de 500ms por imagem. Configurações de consumo atingem 2-5 segundos, dependendo do hardware. Esta eficiência deriva de técnicas de destilação como Decoupled-DMD e DMDR, que comprimem o modelo base Z-Image, preservando o desempenho.
Você baixa os pesos do modelo dos repositórios ModelScope ou Hugging Face. O branch master inclui arquivos de checkpoint totalizando cerca de 24GB. A compatibilidade com PyTorch garante ampla integração. Para testes locais, você instala as dependências via pip: torch, torchvision e modelscope>=1.18.0. Um script de pipeline básico carrega o modelo e gera uma imagem em menos de 10 linhas de código.
Considere este exemplo para inferência local:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = pipeline(Tasks.text_to_image_synthesis, model="Tongyi-MAI/Z-Image-Turbo", device=device)
output = pipe({
"text": "A photorealistic golden retriever playing in a sunlit park, 1024x1024",
"width": 1024,
"height": 1024,
"num_inference_steps": 9
})
output["output_imgs"][0].save("generated_image.png")
Este código inicializa o pipeline, processa o prompt e salva o resultado. Você percebe o parâmetro num_inference_steps: 9 — ele aciona a destilação de 8 etapas para velocidade ideal. A escala de guidance permanece em 0.0, pois as variantes Turbo ignoram a guidance livre de classificador para manter a velocidade.
Benchmarks confirmam a competitividade do Z-Image-Turbo. Na AI Arena da Alibaba, ele pontua alto em avaliações de preferência humana baseadas em Elo, superando muitos pares de código aberto em fotorrealismo e fidelidade de texto. Comparado a modelos como o Stable Diffusion 3, ele usa menos etapas e menos memória, mas oferece detalhes comparáveis.
No entanto, existem limitações. O modelo prioriza a velocidade em detrimento de resoluções extremas; ultrapassar 1536x1536 pode introduzir desfoque sem ajuste fino. Ele também não possui edição nativa de imagem para imagem na variante Turbo — isso fica para o próximo lançamento do Z-Image-Edit. Ainda assim, para tarefas de texto para imagem, o Z-Image-Turbo fornece uma base sólida e acessível.
Você estende este modelo via API Z-Image, que o hospeda na infraestrutura do ModelScope. Essa mudança do local para a nuvem elimina as dificuldades de configuração. Consequentemente, você se concentra na lógica do aplicativo em vez da otimização de hardware.
Acessando a API Z-Image Gratuita: Configuração Passo a Passo
Você faz uma transição suave para a integração da API. A API Z-Image opera através do serviço de inferência do ModelScope, que hospeda o Z-Image-Turbo para chamadas remotas. Esta configuração requer o mínimo de configuração, mas oferece confiabilidade de nível empresarial.
Primeiro, registre-se na plataforma ModelScope. Crie uma conta com seu e-mail ou credenciais do GitHub. Uma vez logado, navegue até a seção API em seu perfil. Gere um Token ModelScope — este atua como sua chave de autenticação Bearer. Armazene-o com segurança, pois todas as requisições o exigem no cabeçalho Authorization.
O endpoint da API foca no processamento assíncrono, o que se adequa a necessidades de alto rendimento. Você envia tarefas de geração via POST para https://api-inference.modelscope.cn/v1/images/generations. As respostas retornam um task_id imediatamente. Em seguida, você consulta https://api-inference.modelscope.cn/v1/tasks/{task_id} a cada 5-10 segundos até a conclusão. Este design previne timeouts em gerações longas, embora a velocidade do Z-Image-Turbo mantenha as esperas breves — tipicamente de 5 a 15 segundos de ponta a ponta.
Os cabeçalhos principais incluem:
Authorization: Bearer {your_token}Content-Type: application/jsonX-ModelScope-Async-Mode: true(para envio)X-ModelScope-Task-Type: image_generation(para verificações de status)
O corpo da requisição especifica parâmetros como ID do modelo, prompt, dimensões e etapas. Você define "model": "Tongyi-MAI/Z-Image-Turbo" para direcionar esta variante. As dimensões padrão são 1024x1024, mas você ajusta height e width para proporções personalizadas. Mantenha guidance_scale: 0.0 e num_inference_steps: 9 para melhores resultados.
Um exemplo completo de curl ilustra o processo:
# Etapa 1: Enviar tarefa
curl -X POST "https://api-inference.modelscope.cn/v1/images/generations" \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "Content-Type: application/json" \
-H "X-ModelScope-Async-Mode: true" \
-d '{
"model": "Tongyi-MAI/Z-Image-Turbo",
"prompt": "A futuristic cityscape at night with neon signs in Chinese and English",
"height": 1024,
"width": 1024,
"num_inference_steps": 9,
"guidance_scale": 0.0
}'
# Extrair task_id da resposta, ex: {"task_id": "abc123"}
# Etapa 2: Consultar status
curl -X GET "https://api-inference.modelscope.cn/v1/tasks/abc123" \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "X-ModelScope-Task-Type: image_generation"
Em caso de sucesso, a resposta de status inclui "task_status": "SUCCEED" e um array output_images com um URL para download. Você busca a imagem via GET, salvando-a como PNG ou JPEG.
Para alternativas síncronas, o ModelScope oferece uma demonstração online em modelscope.cn/aigc/imageGeneration. Selecione Z-Image-Turbo como o modelo padrão. O Modo Rápido gera imagens sem parâmetros, enquanto o Modo Avançado expõe controles completos. Esta interface serve para prototipagem, mas você prefere a API para automação.
O tratamento de erros é essencial. Códigos comuns incluem 401 (token inválido), 429 (limites de taxa) e 500 (problemas no servidor). Implemente retentativas com backoff exponencial no código de produção. Os limites de taxa giram em torno de 10-20 requisições por minuto para camadas gratuitas, embora as cotas exatas variem por conta.
Você integra esta API em diversos ambientes. Desenvolvedores Python usam requests para chamadas HTTP, como mostrado anteriormente. Usuários Node.js aproveitam axios para polling baseado em promises. Mesmo funções serverless em AWS Lambda ou Vercel são facilmente implantadas, dados os payloads leves.
O Apidog aprimora esta fase de acesso. Importe a especificação da API para o Apidog, que gera automaticamente documentação e casos de teste. Você simula respostas, encadeia requisições para polling e exporta coleções para compartilhamento em equipe. Esta plataforma reduz o tempo de depuração, permitindo que você se concentre na engenharia de prompts.
Através dessas etapas, você estabelece uma conexão confiável com a API Z-Image. Agora, você examina seus preços para confirmar a relação custo-benefício.
Preços e Cotas para a API Z-Image
Você confirma a acessibilidade em seguida. A API Z-Image não incorre em cobranças por inferência. O ModelScope fornece computação gratuita ilimitada para chamadas Z-Image-Turbo, conforme anunciado em sua postagem oficial no X. Este modelo de custo zero inclui hospedagem, largura de banda e recursos de GPU — uma raridade entre os serviços de IA.
No entanto, cotas se aplicam para evitar abusos. Contas gratuitas enfrentam limites flexíveis: aproximadamente 50-100 gerações por hora, redefinindo periodicamente. Você monitora o uso através do painel do ModelScope. Exceder os limites aciona um estrangulamento temporário, mas você pode fazer upgrade para planos pro para volumes maiores, se necessário. Os planos pro começam com taxas baixas, mas a camada gratuita é suficiente para a maioria dos desenvolvedores e entusiastas.
Melhores Práticas para Otimizar o Desempenho da API Z-Image
Você aprimora seu uso com estratégias direcionadas. Primeiro, selecione parâmetros ideais. Mantenha 1024x1024 para equilíbrio; faça upscale pós-geração se necessário. Limite as etapas a 9 — valores mais altos atrasam a inferência sem ganhos.
A aceleração de hardware impulsiona híbridos locais. Habilite o Flash Attention em Diffusers: pipe.transformer.set_attention_backend("flash"). Isso reduz a memória em 20-30% em GPUs Ampere.
A engenharia de prompts eleva a qualidade. Estruture as entradas como "assunto + ação + ambiente + estilo". Teste variações no modo de simulação do Apidog para iterar rapidamente.
Práticas de segurança protegem as integrações. Nunca exponha tokens em código client-side; use proxies de servidor. Valide as entradas para prevenir ataques de injeção.
Ferramentas de monitoramento rastreiam métricas. Registre tempos de geração, taxas de sucesso e uso de tokens. Ferramentas como Prometheus se integram facilmente para painéis.
Conclusão
Agora você domina completamente a API Z-Image. Desde a compreensão da arquitetura de código aberto do Z-Image-Turbo até a execução de chamadas de API e otimização de fluxos de trabalho, este guia o prepara para o sucesso. O modelo de precificação gratuito democratiza a geração avançada de imagens, enquanto ferramentas como o Apidog agilizam o desenvolvimento.
Implemente essas técnicas em seu próximo projeto. Experimente com prompts, escale integrações e contribua para o ecossistema. À medida que a IA evolui, o Z-Image-Turbo o posiciona na vanguarda de ferramentas eficientes e criativas.