
DeepSeek continua a avançar modelos de linguagem grandes com lançamentos que priorizam raciocínio e eficiência. Engenheiros e pesquisadores agora têm acesso ao DeepSeek-V3.2 e DeepSeek-V3.2-Speciale, modelos que se destacam na resolução de problemas complexos e em fluxos de trabalho agentic. Essas ferramentas se integram perfeitamente em aplicações, mas os desenvolvedores frequentemente enfrentam desafios na configuração, autenticação e otimização. Este artigo fornece um guia técnico passo a passo para aproveitar esses modelos de forma eficaz.
Compreendendo o DeepSeek-V3.2: A Base de Código Aberto para Raciocínio Avançado
Desenvolvedores constroem sistemas de IA robustos com base em modelos de código aberto porque eles oferecem transparência, personalização e melhorias impulsionadas pela comunidade. O DeepSeek-V3.2 se destaca como o sucessor oficial da variante experimental V3.2-Exp, que a DeepSeek lançou anteriormente para testar mecanismos de atenção esparsa. Este modelo ativa 37 bilhões de parâmetros de um total de 671 bilhões em sua arquitetura Mixture-of-Experts (MoE), treinado em 14,8 trilhões de tokens de alta qualidade. Tal escala permite que o DeepSeek-V3.2 lide com diversas tarefas, desde geração de linguagem natural até complexas provas matemáticas.
A inovação central do modelo reside na DeepSeek Sparse Attention (DSA), um mecanismo granular que reduz a sobrecarga computacional durante a inferência, especialmente para contextos longos de até 128.000 tokens. Engenheiros apreciam isso porque mantém a qualidade da saída enquanto reduz a latência — crítico para aplicações em tempo real como chatbots ou assistentes de código. Além disso, o DeepSeek-V3.2 integra modos de "pensamento", onde o modelo gera etapas de raciocínio intermediárias antes das saídas finais, aumentando a precisão em benchmarks como AIME 2025 e HMMT 2025.
Acesse a versão de código aberto no Hugging Face em deepseek-ai/DeepSeek-V3.2. Desenvolvedores baixam pesos e configurações diretamente, permitindo a implantação local em clusters de GPU. Por exemplo, use a biblioteca Transformers para carregar o modelo:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "deepseek-ai/DeepSeek-V3.2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "Solve this equation: x^2 + 3x - 4 = 0"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200, do_sample=False)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
Este trecho de código inicializa o modelo com precisão bfloat16 para eficiência em GPUs NVIDIA modernas. No entanto, execuções locais exigem hardware substancial — recomenda-se pelo menos 8 GPUs A100 para precisão total. Consequentemente, muitas equipes optam por versões quantizadas via bibliotecas como bitsandbytes para caber em hardware de consumo.
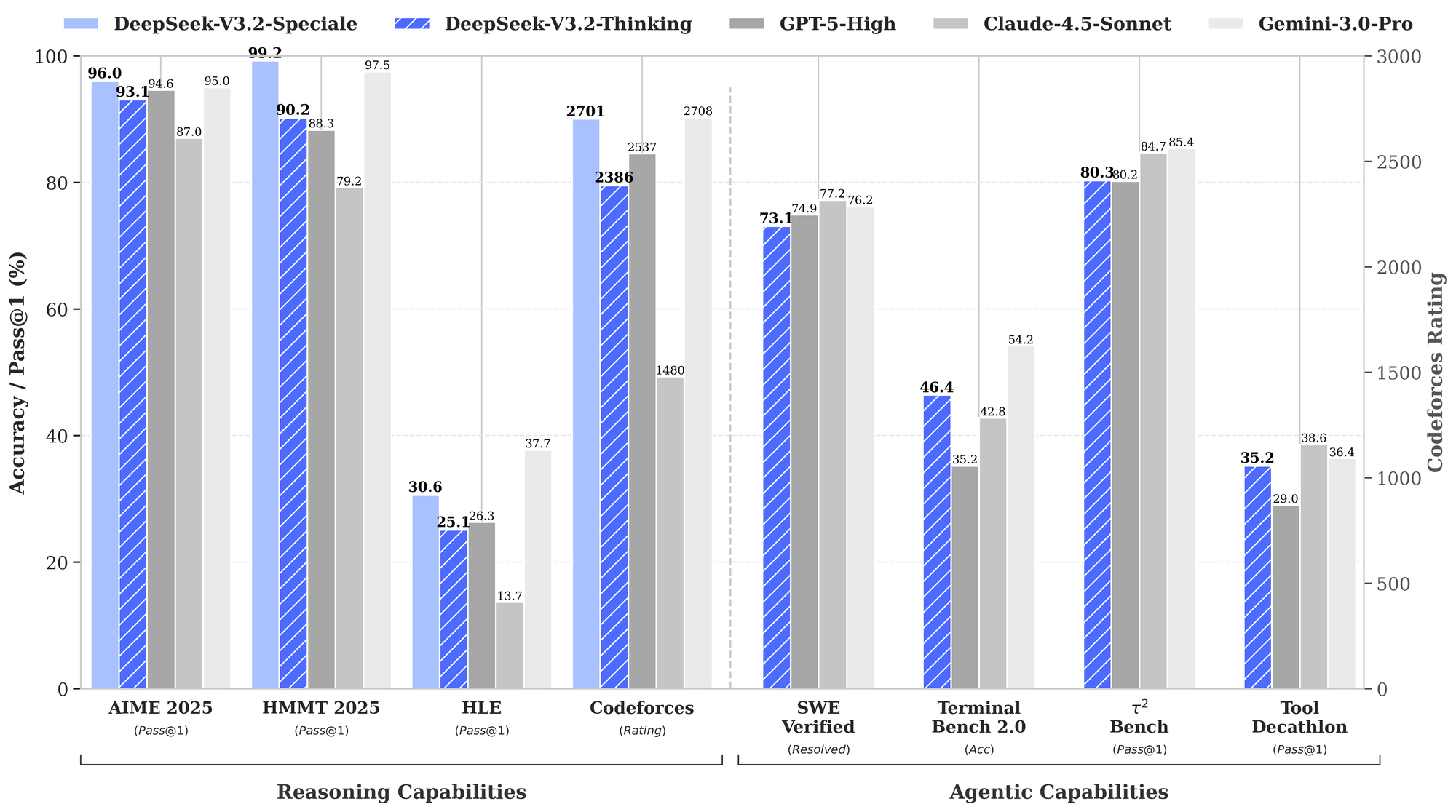
Benchmarks ressaltam os pontos fortes do DeepSeek-V3.2. Em tarefas de raciocínio, ele alcança 93,1% no AIME 2025 (pass@1), superando os 90,2% do GPT-5-High. Para capacidades agentic, ele resolve 2.537 problemas no SWE-Bench Verified, superando o Claude-4.5-Sonnet com 2.536. Essas métricas posicionam o DeepSeek-V3.2 como um "driver diário" equilibrado para ambientes de produção, onde a velocidade de inferência importa tanto quanto a inteligência bruta.
Além disso, o modelo suporta extensões multimodais em futuras atualizações, mas os lançamentos atuais focam no raciocínio baseado em texto. Engenheiros o ajustam (fine-tune) em conjuntos de dados específicos de domínio usando adaptadores LoRA, preservando as capacidades base enquanto se adaptam a nichos como análise legal ou simulação científica. Como resultado, o acesso de código aberto capacita a prototipagem rápida sem dependência de fornecedor (vendor lock-in).
Explorando o DeepSeek-V3.2-Speciale: Otimizado para Desempenho Máximo de Raciocínio
Enquanto o DeepSeek-V3.2 oferece ampla utilidade, o DeepSeek-V3.2-Speciale visa cenários que exigem profundidade cognitiva máxima. Esta variante ultrapassa os limites do raciocínio, rivalizando com o Gemini-3.0-Pro em competições de elite. Ele alcança resultados de medalha de ouro na IMO 2025, CMO, ICPC World Finals e IOI 2025 — feitos que exigem encadeamento lógico diferenciado e resolução criativa de problemas.
O DeepSeek-V3.2-Speciale é construído sobre a mesma base MoE, mas incorpora estágios aprimorados de aprendizado por reforço a partir de feedback humano (RLHF), enfatizando comportamentos agentic. Ao contrário do modelo base, ele gera processos de pensamento internos mais longos, que consomem mais tokens, mas produzem uma precisão superior em tarefas como o uso de ferramentas em ambientes de múltiplas etapas. Por exemplo, ele sintetiza dados de treinamento em mais de 1.800 mundos simulados e mais de 85.000 instruções, permitindo um tratamento robusto de cenários nunca antes vistos.
Visualize o cartão do modelo no Hugging Face em deepseek-ai/DeepSeek-V3.2-Speciale. O download segue um processo semelhante:
model_name = "deepseek-ai/DeepSeek-V3.2-Speciale"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto"
)
prompt = "Prove that the sum of angles in a triangle is 180 degrees."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=500, temperature=0.1)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
Note o sinalizador trust_remote_code=True, pois o Speciale emprega implementações de atenção personalizadas. Essa configuração exige ainda mais VRAM — até 1TB para inferência não quantizada — tornando-o ideal para laboratórios de pesquisa em vez de dispositivos de borda.
Dados de desempenho destacam sua vantagem. O gráfico de benchmark fornecido ilustra o DeepSeek-V3.2-Speciale (barras azuis) liderando em raciocínio: 99,0% no HMMT 2025 (pass@1) contra 97,5% do GPT-5-High, e 84,8% de precisão no Codeforces (rating) contra 84,7% do Claude-4.5-Sonnet. Em domínios agentic, ele se destaca no Terminal-Bench v0.2 (84,3% de precisão) e no Tool-Use (pass@1), frequentemente por margens estreitas que se acumulam em operações encadeadas. No entanto, o maior uso de tokens — até 50% a mais que o V3.2 — exige uma engenharia de prompt cuidadosa para controlar os custos.
Como o Speciale não possui uso nativo de ferramentas em seu lançamento inicial, os desenvolvedores o encadeiam com APIs externas para agentes híbridos. Essa abordagem se destaca em avaliações, onde supera os pares em mais de 85 mil benchmarks de instruções. No geral, o DeepSeek-V3.2-Speciale é adequado para aplicações de alto risco, como prova de teoremas automatizada ou simulações de planejamento estratégico.
Transição do Código Aberto para API: Por Que o Acesso Hospedado Importa
Implantações locais oferecem controle, mas a escala introduz complexidades como provisionamento e manutenção de hardware. Desenvolvedores recorrem a APIs para acesso instantâneo, economia de pagamento por uso e infraestrutura gerenciada. A DeepSeek fornece endpoints hospedados para o V3.2 e o V3.2-Speciale, garantindo compatibilidade com interfaces estilo OpenAI. Essa mudança acelera a prototipagem, pois as equipes contornam os obstáculos de configuração e se concentram na integração.
Além disso, o acesso à API desbloqueia recursos corporativos, como limitação de taxa (rate limiting) e cache, que otimizam para cargas de produção. Por exemplo, acertos de cache (cache hits) reduzem drasticamente os custos de entrada, tornando as consultas repetidas econômicas. Como resultado, startups e empresas adotam esses endpoints para implantações sensíveis a custos.
Acessando a API DeepSeek: Configuração Passo a Passo
Engenheiros acessam a API DeepSeek através da plataforma oficial. Primeiro, crie uma conta e gere uma chave de API na seção "API Keys". Esta chave autentica as requisições via cabeçalho Authorization: Bearer YOUR_API_KEY.
A URL base é https://api.deepseek.com/v1. Para o DeepSeek-V3.2, use o identificador de modelo deepseek-v3.2. O DeepSeek-V3.2-Speciale opera em um endpoint temporário: https://api.deepseek.com/v3.2_speciale_expires_on_20251215, disponível até 15 de dezembro de 2025, UTC 15:59. Após esta data, ele será integrado às ofertas padrão.
Instale o SDK da OpenAI para simplificar:
pip install openai
Então, configure um cliente:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.deepseek.com/v1"
)
Envie uma requisição de conclusão para o DeepSeek-V3.2:
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant focused on reasoning."},
{"role": "user", "content": "Explain quantum entanglement in simple terms."}
],
max_tokens=300,
temperature=0.7
)
print(response.choices[0].message.content)
Para o DeepSeek-V3.2-Speciale, ajuste a base_url e o modelo:
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.deepseek.com/v3.2_speciale_expires_on_20251215"
)
response = client.chat.completions.create(
model="deepseek-v3.2-speciale",
messages=[{"role": "user", "content": "Solve: Integrate e^x sin(x) dx."}],
max_tokens=500
)
Essas chamadas retornam respostas JSON com estatísticas de uso, incluindo tokens de prompt e de conclusão. Lide com erros via blocos try-except, verificando limites de taxa (por exemplo, 10.000 RPM para V3.2).
Além disso, habilite os modos de pensamento anexando /thinking ao nome do modelo, por exemplo, deepseek-v3.2/thinking. Isso aciona o raciocínio passo a passo, ideal para depurar consultas complexas.
Preços da API: Escalabilidade Custo-Efetiva para DeepSeek-V3.2 e Speciale
Os preços são um pilar da adoção de APIs, e a DeepSeek os estrutura de forma transparente por milhão de tokens. Ambos os modelos seguem as mesmas taxas, cobradas pelo input (acerto/erro de cache) e output. Acertos de cache se aplicam a prefixos repetidos dentro das sessões, reduzindo custos para fluxos de trabalho iterativos.
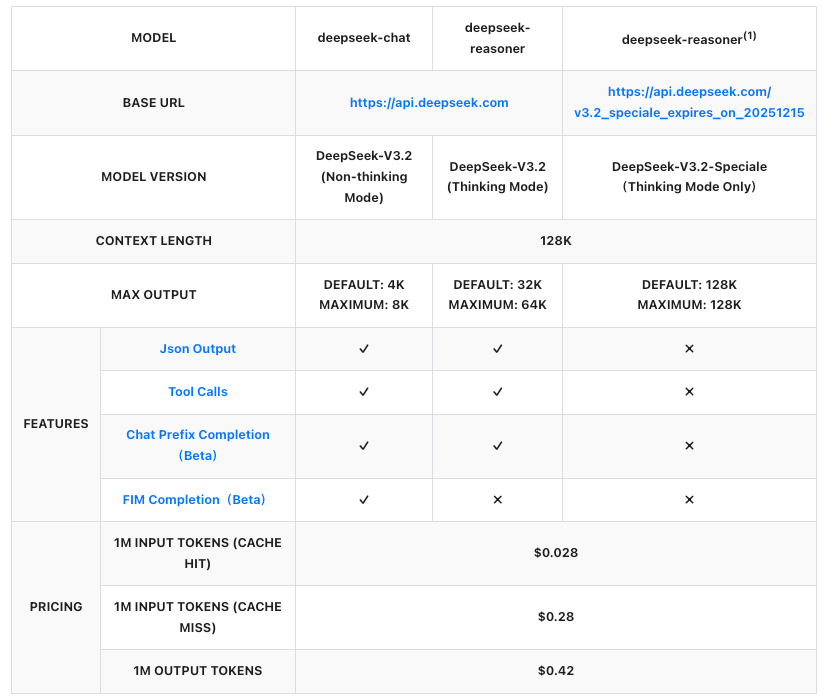
Esses valores representam reduções de mais de 50% em relação às versões anteriores, tornando o DeepSeek competitivo com APIs proprietárias. Por exemplo, gerar uma resposta de 1.000 tokens a partir de um prompt de 500 tokens (erro de cache) custa aproximadamente US$0,00035 — insignificante para a maioria dos casos de uso. Empresas negociam planos personalizados para volumes maiores, mas o pagamento conforme o uso (pay-as-you-go) é adequado para desenvolvedores.
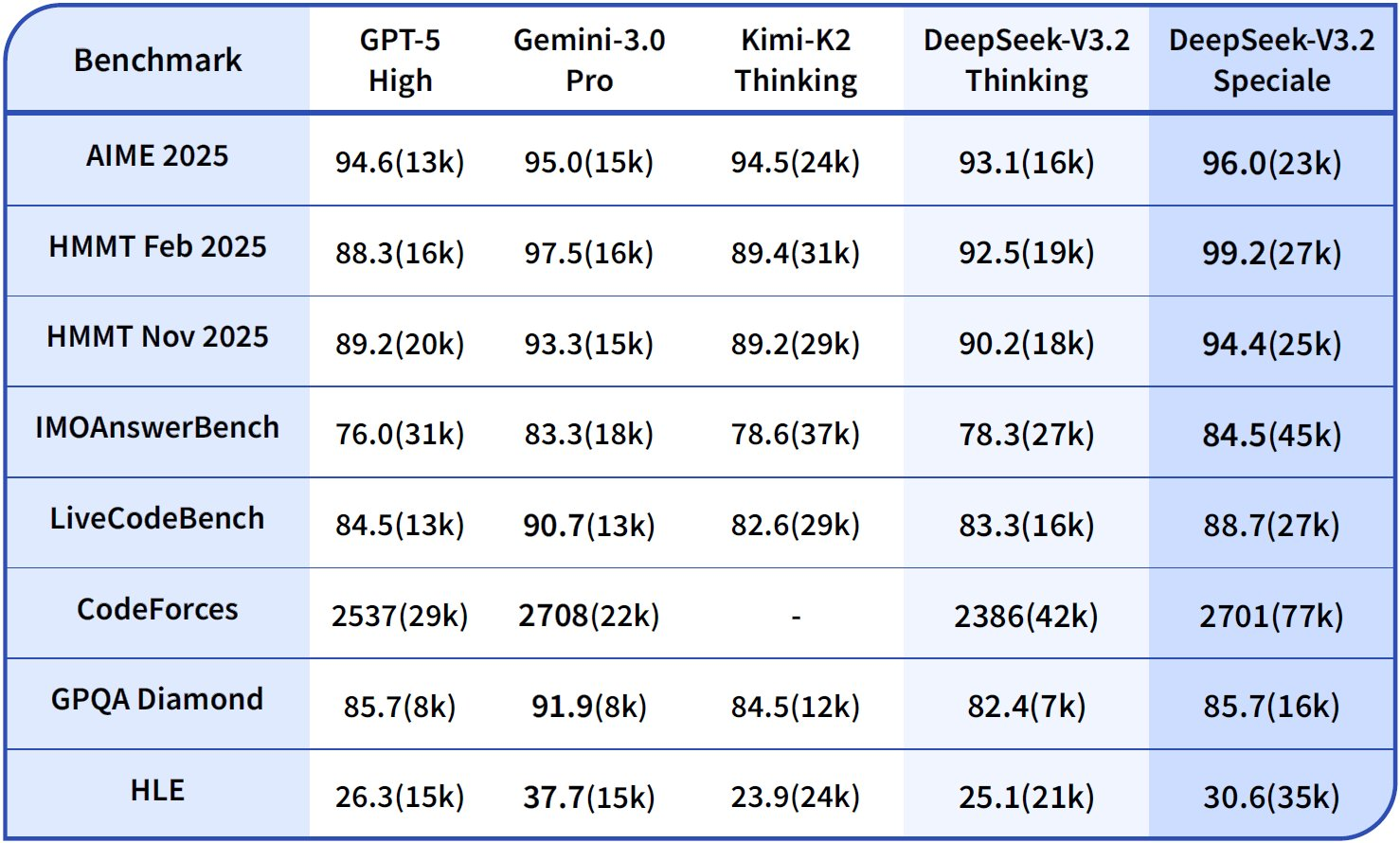
Consequentemente, as equipes preveem despesas usando estimadores de tokens no painel do DeepSeek. Considere o maior consumo de tokens do Speciale; uma consulta que exige muito raciocínio pode dobrar os custos, mas quadruplicar a precisão em benchmarks como Tau² (29,0% pass@1 para Speciale vs. 25,1% para V3.2).
Integrando com Apidog: Teste e Documentação Eficientes de API
Desenvolvedores otimizam fluxos de trabalho com ferramentas como Apidog, que projeta, testa e documenta APIs sem código. Importe sua chave de API DeepSeek para as variáveis de ambiente do Apidog e, em seguida, crie uma nova coleção de requisições para os endpoints V3.2 e Speciale.
Construa uma requisição POST para /chat/completions:
- Cabeçalhos:
Authorization: Bearer {{api_key}},Content-Type: application/json - Corpo: Payload JSON com modelo, mensagens e parâmetros.
Execute testes na interface do Apidog, que gera automaticamente respostas e asserções. Por exemplo, valide se a saída do Speciale excede 200 tokens em prompts de matemática. Além disso, o Apidog exporta especificações OpenAPI, facilitando as transições entre equipes.
Essa integração reduz o tempo de depuração em 40%, pois as diferenças visuais destacam as discrepâncias. As equipes também simulam (mock) respostas para desenvolvimento offline, garantindo robustez antes de implantações em produção (live deploys).
Técnicas Avançadas: Uso de Ferramentas e Fluxos de Trabalho Agentic
O DeepSeek-V3.2 introduz o pensamento no uso de ferramentas, mesclando raciocínio interno com chamadas externas. Especifique as ferramentas no payload da API:
tools = [
{
"type": "function",
"function": {
"name": "calculator",
"description": "Perform basic math",
"parameters": {
"type": "object",
"properties": {"expression": {"type": "string"}}
}
}
}
]
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[{"role": "user", "content": "What is 15% of 250?"}],
tools=tools,
tool_choice="auto"
)
O modelo raciocina passo a passo e, em seguida, invoca a ferramenta, se necessário. O Speciale, atualmente sem ferramentas, funciona bem como um oráculo de raciocínio em cadeias multi-modelo.
Para agentes, orquestre via LangChain: envolva chamadas DeepSeek em agentes que direcionam tarefas dinamicamente. Esta configuração resolve 73,1% dos problemas verificados do SWE-Bench, de acordo com os benchmarks.
Melhores Práticas para Implantação em Produção
Otimize prompts com templates de cadeia de pensamento para aproveitar os modos de raciocínio. Monitore o uso de tokens via metadados da API, implementando alternativas para limites de orçamento. Escale com clientes assíncronos em Python para aplicações de alto desempenho.
A segurança exige rotação de chaves e whitelisting de IPs. Por fim, avalie iterativamente contra benchmarks como os do relatório técnico, ajustando hiperparâmetros para adequação ao domínio.
Conclusão: Aproveite o Poder do DeepSeek Hoje
DeepSeek-V3.2 e DeepSeek-V3.2-Speciale redefinem o raciocínio de IA acessível. Da flexibilidade de código aberto à eficiência da API, esses modelos capacitam os desenvolvedores a construir agentes mais inteligentes. Comece com experimentos locais, migre para endpoints hospedados e integre o Apidog para testes sem interrupções. À medida que os benchmarks evoluem, a trajetória do DeepSeek promete capacidades ainda maiores — posicione seus projetos na vanguarda.