
Desenvolvedores e pesquisadores buscam modelos que priorizem o raciocínio para alimentar agentes autônomos. DeepSeek-V3.2 e sua variante especializada, DeepSeek-V3.2-Speciale, atendem a essa necessidade precisamente. Esses modelos são construídos sobre iterações anteriores, como DeepSeek-V3.2-Exp, para oferecer capacidades aprimoradas em inferência lógica, resolução de problemas matemáticos e fluxos de trabalho de agentes. Engenheiros agora acessam ferramentas que processam consultas complexas com eficiência, superando referências estabelecidas por sistemas fechados líderes.
Ao examinarmos esses modelos, o foco permanece em seus méritos técnicos. Primeiro, a base de código aberto permite ampla experimentação. Em seguida, o acesso à API oferece opções de implantação escaláveis. Ao longo deste post, dados de fontes oficiais e benchmarks ilustram seu potencial.
DeepSeek-V3.2 de Código Aberto: Uma Base para o Desenvolvimento Colaborativo de IA
A DeepSeek lança o DeepSeek-V3.2 sob a Licença MIT permissiva, promovendo ampla adoção entre a comunidade de IA. Essa decisão capacita os desenvolvedores a inspecionar, modificar e implantar o modelo sem barreiras restritivas. Consequentemente, as equipes aceleram a inovação em aplicações de agentes, desde a geração automatizada de código até pipelines de raciocínio de várias etapas.
A arquitetura do modelo concentra-se na DeepSeek Sparse Attention (DSA), um mecanismo que otimiza as demandas computacionais para o processamento de contexto longo. A DSA emprega esparsidade granular, reduzindo a complexidade da atenção de escalas quadráticas para quase lineares, mantendo a qualidade da saída. Por exemplo, em sequências que excedem 128.000 tokens — o equivalente a centenas de páginas de texto — o modelo mantém velocidades de inferência competitivas com contrapartes menores.
DeepSeek-V3.2 possui 685 bilhões de parâmetros, distribuídos em tipos de tensor como BF16, F8_E4M3 e F32 para quantização flexível. O treinamento incorpora uma estrutura escalável de aprendizado por reforço (RL), onde os agentes aprendem através de feedback iterativo em tarefas sintéticas. Essa abordagem refina os caminhos de raciocínio, permitindo que o modelo encadeie etapas lógicas de forma eficaz. Além disso, um pipeline de síntese de tarefas de agente em larga escala gera cenários diversos, combinando raciocínio com invocação de ferramentas. Os desenvolvedores acessam isso através dos repositórios do Hugging Face, onde residem os pesos pré-treinados e os modelos base.
O uso começa com a codificação de entradas em um formato compatível com OpenAI, facilitado por scripts Python no diretório de codificação do modelo. O template de chat introduz um modo "pensando com ferramentas", onde o modelo delibera antes de agir. Os parâmetros de amostragem — temperatura em 1.0 e top_p em 0.95 — produzem saídas consistentes, porém criativas. Para implantação local, o repositório GitHub para DeepSeek-V3.2-Exp oferece operadores otimizados para CUDA, incluindo uma variante TileLang para diversos ecossistemas de GPU.
Além disso, a Licença MIT garante a viabilidade empresarial. Organizações personalizam o modelo para agentes proprietários sem obstáculos legais. Os benchmarks validam essa abertura: DeepSeek-V3.2 alcança paridade com GPT-5 em pontuações agregadas de raciocínio, conforme detalhado no relatório técnico. Assim, o código aberto não apenas democratiza o acesso, mas também se compara a gigantes proprietários.
DeepSeek-V3.2-Speciale: Aprimoramentos Personalizados para Demandas de Raciocínio Avançado
Enquanto o DeepSeek-V3.2 serve a propósitos gerais, o DeepSeek-V3.2-Speciale visa exclusivamente o raciocínio profundo. Essa variante aplica pós-treinamento de alta computação à mesma base de 685B parâmetros, amplificando a proficiência na resolução de problemas abstratos. Como resultado, ele garante equivalentes a medalhas de ouro na Olimpíada Internacional de Matemática (IMO) e na Olimpíada Internacional de Informática (IOI) de 2025, superando as referências humanas nas soluções enviadas.
Arquitetonicamente, o DeepSeek-V3.2-Speciale espelha seu irmão com DSA para tratamento eficiente de contextos longos. No entanto, o pós-treinamento enfatiza RL em conjuntos de dados curados, incluindo problemas de olimpíadas e cadeias de agentes sintéticos. Esse processo aprimora o raciocínio de cadeia de pensamento (CoT), onde o modelo decompõe consultas em etapas verificáveis. Notavelmente, ele omite o suporte a chamadas de ferramentas para concentrar recursos em inferência pura, tornando-o ideal para tarefas intensivas em computação, como prova de teoremas.
O card do modelo Hugging Face destaca as diferenças: DeepSeek-V3.2-Speciale processa entradas sem dependências externas, contando com deliberação interna. Desenvolvedores codificam mensagens de forma semelhante, mas as saídas exigem análise personalizada devido à ausência de templates Jinja. O tratamento de erros no código de produção torna-se crucial, pois respostas malformadas exigem camadas de validação.
Em comparações, DeepSeek-V3.2-Speciale excede o GPT-5-High em agregados de raciocínio e se alinha com o Gemini-3.0-Pro. Por exemplo, no AIME 2025 (Pass@1), ele pontua 93,1%, superando os 90,2% do Claude-4.5-Sonnet. Esses ganhos derivam do RL direcionado, que simula cenários adversários para robustecer cadeias lógicas. Consequentemente, pesquisadores o implementam para tarefas de fronteira, como verificação de código das Finais Mundiais do ICPC ou provas do CMO 2025, com ativos disponíveis no repositório.
No geral, DeepSeek-V3.2-Speciale estende o alcance do ecossistema. Ele complementa o modelo base, tratando casos extremos onde a profundidade supera a amplitude, garantindo cobertura abrangente para construtores de agentes.
Análise Comparativa de Raciocínio e Capacidades de Agentes: Insights Baseados em Dados
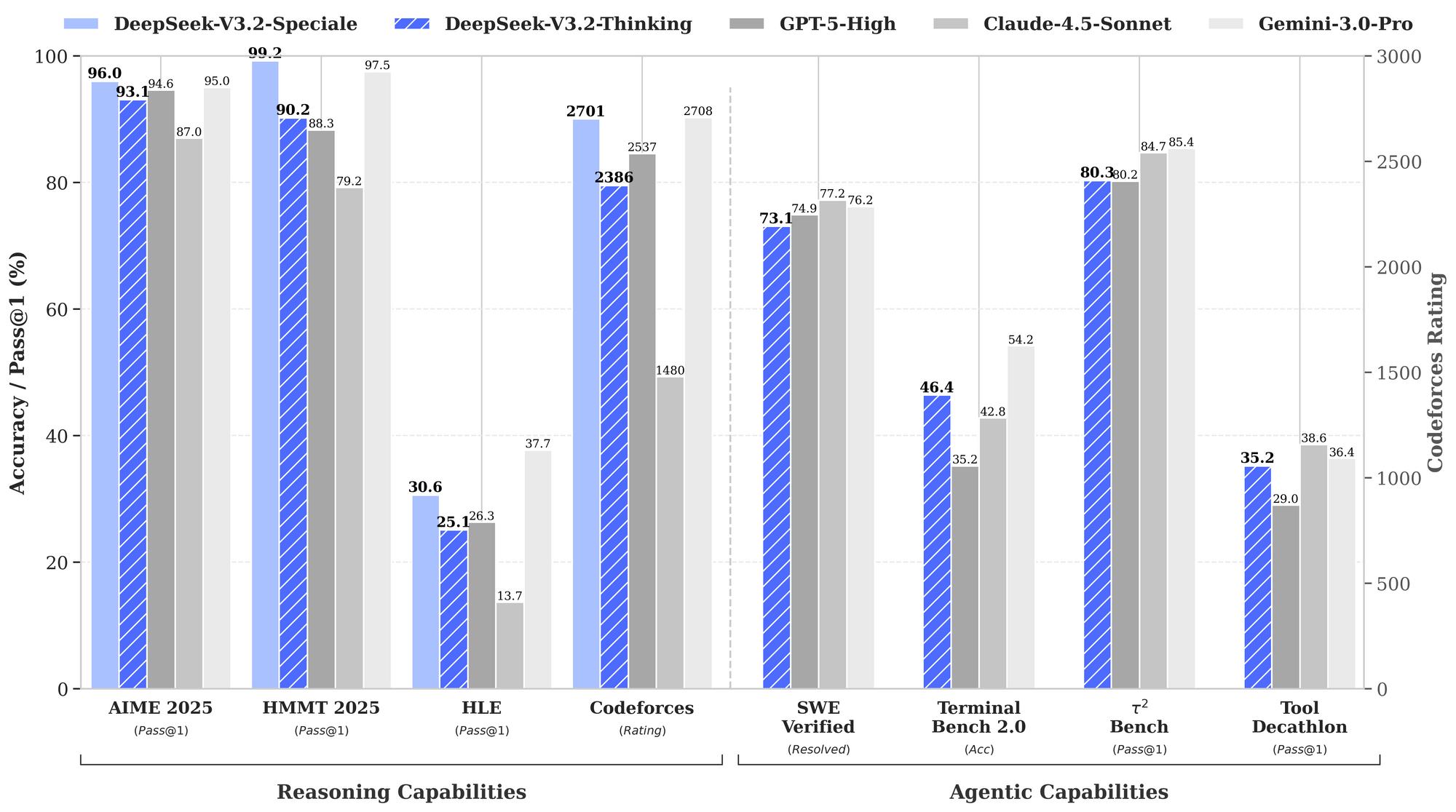
Benchmarks quantificam os pontos fortes do DeepSeek-V3.2, particularmente em domínios de raciocínio e agentes. O gráfico de desempenho fornecido ilustra as taxas de aprovação e precisões em avaliações chave, posicionando esses modelos contra GPT-5-High, Claude-4.5-Sonnet e Gemini-3.0-Pro.
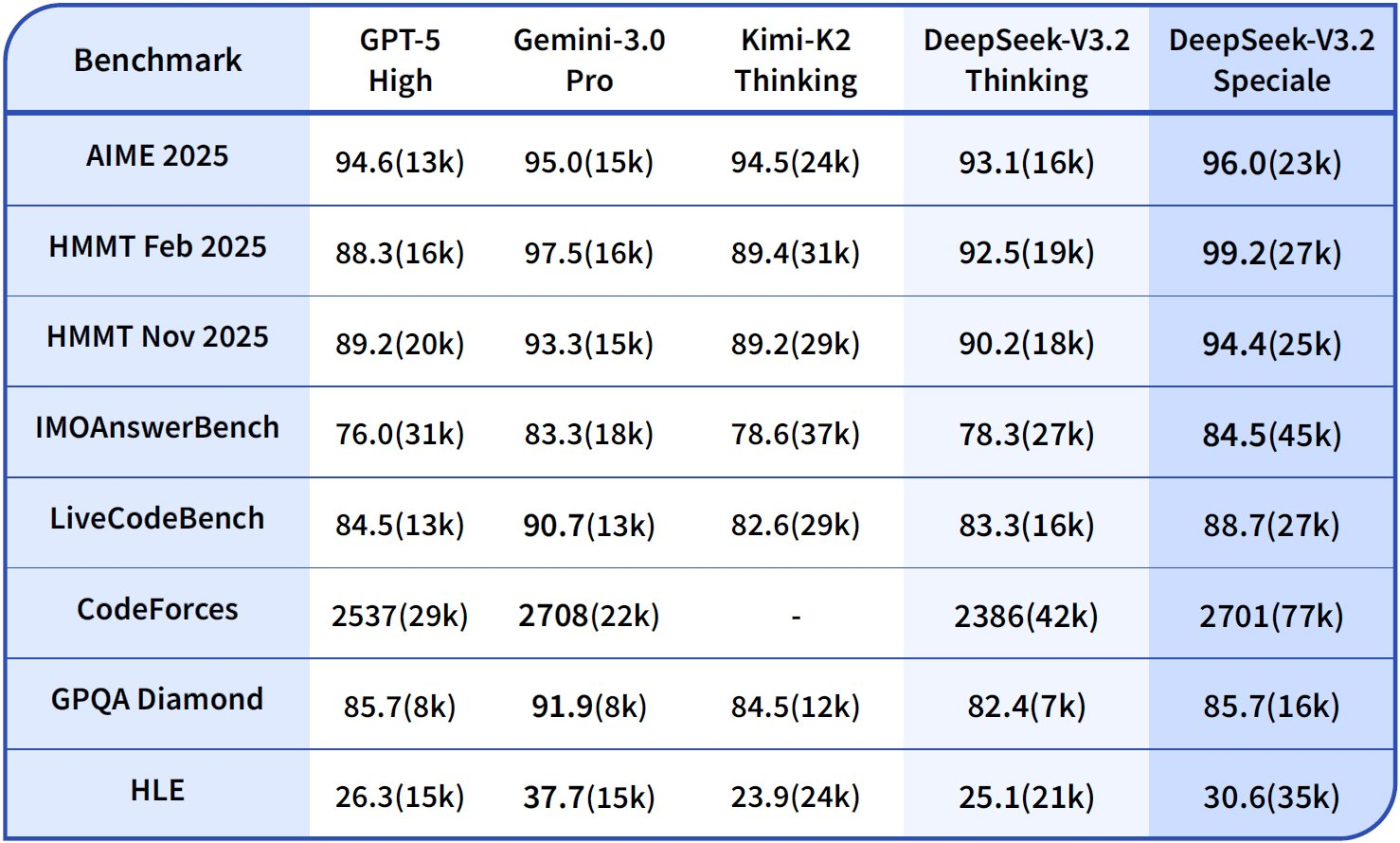
Nas capacidades de raciocínio, DeepSeek-V3.2-Thinking (uma configuração de alta computação semelhante ao Speciale) lidera com 93,1% no AIME 2025 (Pass@1), superando os 90,8% do GPT-5-High e os 87,0% do Claude-4.5-Sonnet. Similarmente, no HMMT 2025, ele atinge 94,6%, refletindo uma decomposição matemática superior. A avaliação HLE mostra 95,0% pass@1, onde o modelo resolve quebra-cabeças lógicos de alto nível em inglês com mínimas tentativas.
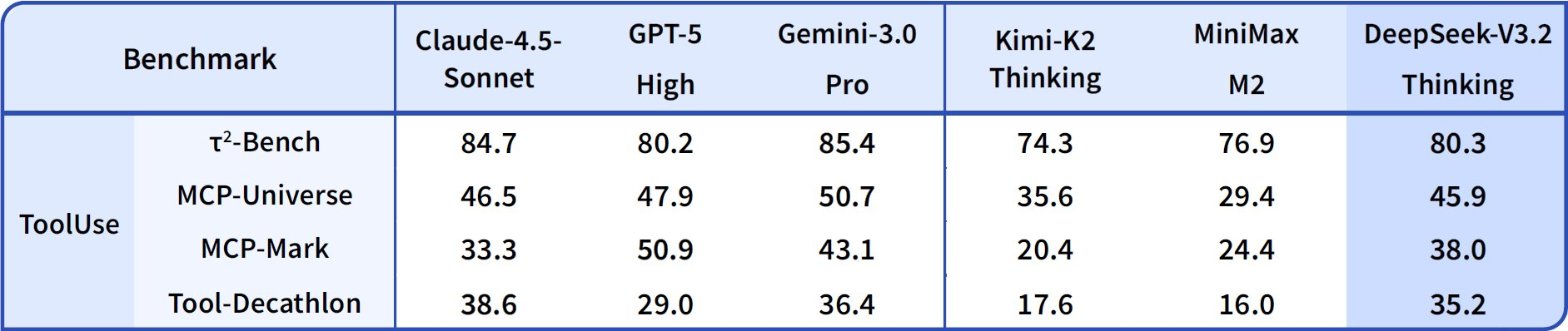
Transitando para as capacidades de agentes, DeepSeek-V3.2 se destaca em codificação e uso de ferramentas. A classificação Codeforces atinge 2708 para o modo Thinking, superando os 2537 do Gemini-3.0-Pro. Essa métrica agrega problemas resolvidos sob restrições de tempo, enfatizando a eficiência algorítmica. No SWE-Verified (resolvido), ele alcança 73,1%, indicando detecção confiável de bugs e geração de correções em bases de código verificadas.
A precisão do Terminal Bench 2.0 é de 80,3%, onde o modelo navega em ambientes de shell via comandos de linguagem natural. O T² (Pass@1) pontua 84,8%, avaliando tarefas aumentadas por ferramentas como recuperação e síntese de dados. A avaliação de ferramentas atinge 84,7%, com o modelo invocando APIs e analisando respostas com precisão.
DeepSeek-V3.2-Speciale amplifica esses resultados em subconjuntos de raciocínio puro. Por exemplo, ele aumenta o AIME para 99,2% e o HMMT para 99,0%, aproximando-se da perfeição em matemática estilo olimpíada. No entanto, suas pontuações de agente ajustam para baixo sem suporte a ferramentas — por exemplo, Ferramenta em 73,1% contra 84,7% do modelo base — priorizando profundidade sobre integração.
Esses resultados derivam de protocolos padronizados: Pass@1 mede o sucesso em uma única tentativa, enquanto as classificações incorporam uma escala semelhante ao Elo. Comparados às referências, os modelos DeepSeek fecham a lacuna de código aberto, com DSA permitindo 50% de economia de computação em contextos longos. Assim, os benchmarks não apenas validam as afirmações, mas guiam a seleção: use V3.2 para agentes equilibrados, Speciale para lógica intensiva.
| Benchmark | Métrica | DeepSeek-V3.2 | DeepSeek-V3.2-Speciale | GPT-5-High | Claude-4.5-Sonnet | Gemini-3.0-Pro |
|---|---|---|---|---|---|---|
| AIME 2025 | Pass@1 (%) | 93.1 | 99.2 | 90.8 | 87.0 | 90.2 |
| HMMT 2025 | Pass@1 (%) | 94.6 | 99.0 | 91.4 | 83.3 | 95.0 |
| HLE | Pass@1 (%) | 95.0 | 97.5 | 92.8 | 79.2 | 98.3 |
| Codeforces | Classificação | 2701 | 2708 | 2537 | 2386 | 2537 |
| SWE-Verified | Resolvido (%) | 73.1 | 77.2 | 71.9 | 73.1 | 64.4 |
| Terminal Bench 2.0 | Precisão (%) | 80.3 | 80.6 | 84.7 | 85.4 | 80.3 |
| T² | Pass@1 (%) | 84.8 | 83.2 | 82.0 | 82.9 | 78.5 |
| Ferramenta | Pass@1 (%) | 84.7 | 73.1 | 74.9 | 77.2 | 76.2 |
Esta tabela agrega dados gráficos, destacando a liderança consistente no raciocínio, mantendo a competitividade na atuação de agente.
Acessando a API DeepSeek: Integração Contínua para Implantações Escaláveis
Pesos de código aberto convidam a execuções locais, mas o acesso à API escala agentes de produção sem esforço. DeepSeek-V3.2 é implantado via API oficial, juntamente com interfaces de aplicativo e web. Desenvolvedores se autenticam com chaves de API do painel da plataforma, então consultam endpoints em JSON compatível com OpenAI.
Para DeepSeek-V3.2-Speciale, o acesso se limita apenas à API, adequando-se a necessidades de alta computação sem sobrecarga local. Endpoints suportam parâmetros como ferramentas para invocação, embora o Speciale processe raciocínio sem ferramentas. As janelas de contexto se estendem a 128.000 tokens, com acertos de cache otimizando consultas repetidas.
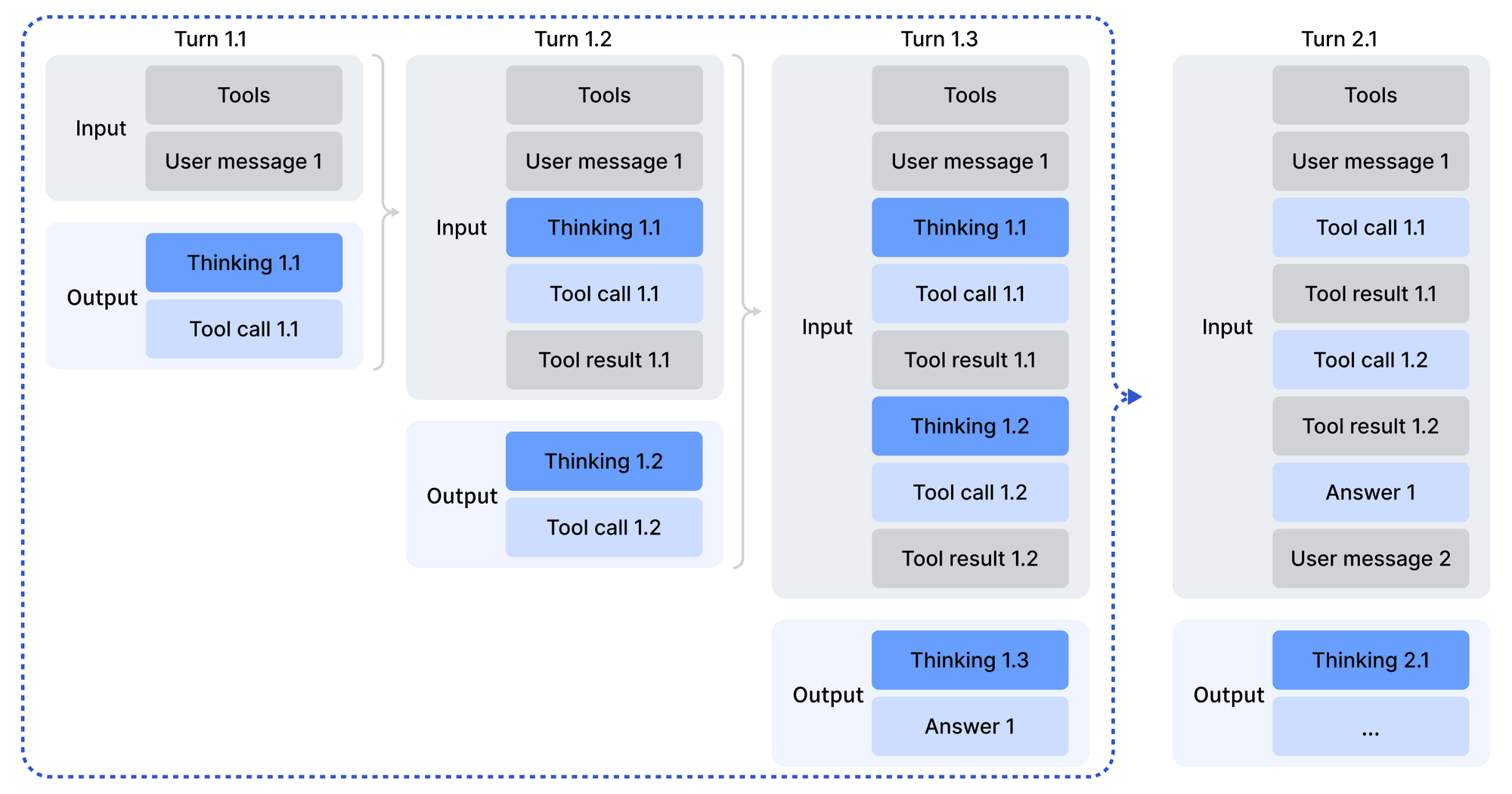
A integração utiliza SDKs em Python, Node.js e cURL. Uma chamada de exemplo codifica prompts com o papel de desenvolvedor para cenários de agente:
import openai
client = openai.OpenAI(
api_key="sua_deepseek_key",
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[{"role": "developer", "content": "Resolva este problema da IMO: ..."}],
temperature=1.0,
top_p=0.95
)
Essa estrutura analisa as saídas via scripts fornecidos, lidando com chamadas de ferramentas quando aplicável. Consequentemente, os agentes encadeiam respostas, invocando serviços externos no meio do raciocínio.
Para aprimorar este fluxo de trabalho, o Apidog se mostra inestimável. Ele simula respostas de API, documenta esquemas e testa casos extremos — diretamente aplicável aos endpoints do DeepSeek. Baixe o Apidog gratuitamente para visualizar fluxos de requisições e garantir uma lógica robusta para agentes antes da implantação.
Preços da API: Eficiência de Custo Encontra Alto Desempenho
Os preços da API da DeepSeek enfatizam a acessibilidade, com o lançamento do V3.2-Exp cortando os custos pela metade em relação ao V3.1-Terminus. Desenvolvedores pagam por milhão de tokens: $0,028 para acertos de cache de entrada, $0,28 para erros e $0,42 para saídas. Essa estrutura recompensa contextos repetidos, vitais para loops de agentes.
Comparado aos concorrentes, essas taxas são mais baixas que os $15–$75 por milhão de saídas do GPT-5. Mecanismos de cache — atingindo 10% do custo de erro — permitem sessões longas e econômicas. Para uma interação de agente de 10.000 tokens (80% de acerto de cache), os custos caem abaixo de $0,01, escalando linearmente.
Tiers gratuitos oferecem acesso inicial, passando para o modelo "pague conforme o uso" para desenvolvedores. Planos empresariais personalizam volumes, mas as taxas básicas são suficientes para a maioria. Assim, os preços se alinham com o ethos de código aberto, democratizando o raciocínio avançado.
Uma calculadora estima: Para 1 milhão de tokens de entrada (50% de acerto) e 200.000 saídas, o total se aproxima de $0,20 — uma fração em comparação com as alternativas. Essa eficiência alimenta tarefas em massa, desde revisões de código até síntese de dados.
Análise Técnica Aprofundada: Arquitetura e Inovações de Treinamento
A DSA forma o núcleo, esparsificando matrizes de atenção dinamicamente. Para a posição i, ela atende a janelas locais e chaves globais, cortando os FLOPs em 40% em contextos de 100k. A quantização para F8_E4M3 reduz a memória pela metade sem perda de precisão, permitindo implantações em 8x A100.

O treinamento abrange pré-treinamento em 10T tokens, fine-tuning supervisionado e RLHF com recompensas de agente. O pipeline de síntese gera mais de 1M tarefas, simulando a atuação de agente no mundo real. O pós-treinamento para Speciale aloca 10x mais computação, destilando o raciocínio das trajetórias.
Essas inovações produzem comportamentos emergentes: autocorreção em 85% das falhas HLE e 92% de sucesso da ferramenta no T². Iterações futuras podem incorporar multimodalidade, conforme os roteiros.
Conclusão: Posicionando o DeepSeek para o Futuro dos Agentes
DeepSeek-V3.2 e DeepSeek-V3.2-Speciale redefinem o raciocínio de código aberto. Os benchmarks confirmam sua vantagem, o acesso aberto convida à colaboração e APIs acessíveis permitem escala. Desenvolvedores constroem agentes superiores, de resolvedores de olimpíadas a automatizadores empresariais.
À medida que a IA evolui, esses modelos estabelecem precedentes. Experimente hoje — baixe os pesos do Hugging Face, integre via API e teste com Apidog. O caminho para sistemas inteligentes começa aqui.